






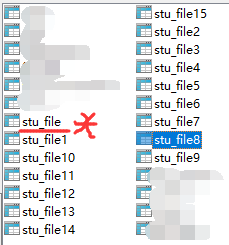
首先创建基础表
创建15个(按需创建)分片表,和一个操作表
接着配置MyCat中相差配置文件
一、server.xml
保存了所有mycat需要的系统配置信息
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<!-- 0 表示是表示使用本地文件方式。
1 表示的是根据数据库来生成
2 表示时间戳的方式 ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) -->
<property name="sequnceHandlerType">1</property>
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--off heap for merge/order/group/limit 1开启 0关闭-->
<property name="useOffHeapForMerge">1</property>
<!--单位为m-->
<property name="memoryPageSize">64k</property>
<!--单位为k-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!-- 单位为m -->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
</system>
<!-- 连接MyCat库的用户名和密码 -->
<user name="root" defaultAccount="true">
<property name="password">Yifan123.</property>
<property name="schemas">catdb</property>
</user>
</mycat:server>二、schema.xml
Schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。弄懂这些配置,是正确使用MyCat的前提。
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- name:逻辑数据库名 checkSQLschema:把schema的字符去掉 sqlMaxLimit:减少过多的数据返回-->
<schema name="catdb" checkSQLschema="false" sqlMaxLimit="100">
<!-- name:逻辑表表名 primaryKey:逻辑表对应真实表的主键 autoIncrement:主键自增长 dataNode:逻辑表所属的dataNode rule:逻辑表使用的规则名字 -->
<table name="stu_file" primaryKey="id" autoIncrement="true" subTables="stu_file$1-15" dataNode="dn1" rule="mod-long"/>
</schema>
<!-- name:数据节点名 dataHost:该分片属于哪个数据库实例 database:定义该分片属性哪个具体数据库实例上的具体库 -->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<!-- name:数据库实例名 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 用于和后端数据库进行心跳检查的语句 -->
<heartbeat>select user()</heartbeat>
<!-- 写实例 -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="Yifan123.">
<!-- 读实例 -->
<readHost host="hostS2" url="localhost:3306" user="root" password="Yifan123." />
</writeHost>
</dataHost>
</mycat:schema>三、rule.xml
rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。这个文件里面主要有tableRule和function这两个标签。在具体使用过程中可以按照需求添加tableRule和function。
<!-- name:定义表规则名 -->
<tableRule name="mod-long">
<rule>
<!-- 指定对物理表中的哪一列进行拆分 -->
<columns>id</columns>
<!-- 使用什么路由算法 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<!-- name 指定算法的名字 class 制定路由算法具体的类名字 -->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- property 为具体算法需要用到的一些属性。 -->
<property name="count">15</property>
</function>四、设置主键自增长
1. 创建Mycat生成唯一主键所需要的函数(用mysql登录后执行)
注意:其中“INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('STU_FILE', 100000, 100);”
插入的是“表名”,“id最小值”及“步长”
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR (50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY (NAME)
) ENGINE = INNODB ;
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('GLOBAL', 100000, 100);
DROP FUNCTION IF EXISTS `mycat_seq_currval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_currval`(seq_name VARCHAR(50))
RETURNS VARCHAR(64) CHARSET utf8
DETERMINISTIC
BEGIN DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR) ) INTO retval
FROM MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval ;
END
;;
DELIMITER ;
DROP FUNCTION IF EXISTS `mycat_seq_nextval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_nextval`(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
CHARSET utf8
DETERMINISTIC
BEGIN UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
DROP FUNCTION IF EXISTS `mycat_seq_setval`;
DELIMITER ;;
CREATE FUNCTION `mycat_seq_setval`(seq_name VARCHAR(50), VALUE INTEGER)
RETURNS VARCHAR(64) CHARSET utf8
DETERMINISTIC
BEGIN UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;2. sequence_db_conf.properties
加入 —— STU_FILE=dn1
#sequence stored in datanode
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
ORDERS=dn1
STU_FILE=dn1最后登录MyCat操作(和登录MySQL方式一样)
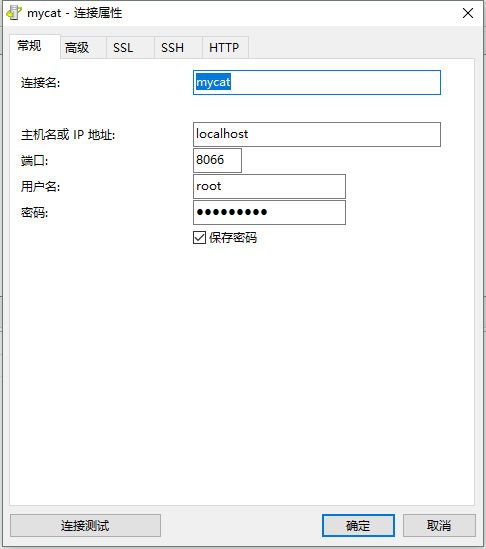
1. Navicat登录MyCat页面
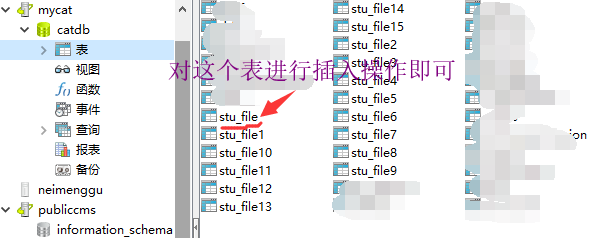
2. MyCat表组成(自动生成并显示,和MySQL一样)
以后对MyCat的操作,就是对MySQL的操作
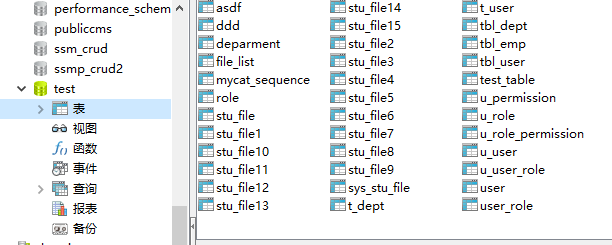
3. 对应MySQL表组成
















 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









