




 本文介绍了一种利用Office软件批量处理文本数据的方法,通过Word和Excel的配合使用,实现了对采集到的语句进行自动换行、筛选和格式调整,以满足特定长度和格式要求。
本文介绍了一种利用Office软件批量处理文本数据的方法,通过Word和Excel的配合使用,实现了对采集到的语句进行自动换行、筛选和格式调整,以满足特定长度和格式要求。
记录一次工作记录,里面涉及到一些Office操作,一个常见的工作流程
前言
一个语料采集的项目需求,要求采集各类主题的语句,词汇要求10-35之间,具体要求如下:
- 一句只能一个句号,不要其他特殊符号,*,(),不要数字
- 引号的存在要有意义,有的被拆开了
- 句子长度的限制
解决方法
首先肯定是爬取需要的消息,要求的尼日利亚的网站文章正文,拆分成所需的格式
最好的方式肯定是Python爬取数据,使用Python解析文档,最技术流的方式,可惜我技术还不到家,而且数据采集项目转瞬即逝。找到了以下的折中解决办法
- 首先使用后羿采集器采集文章正文,然后导出为Excel格式,只保留文章正文
- 复制到WORD文档中,使用替换,实现按照句号自动换行
- 然后换行后,再复制到EXCEL表格中处理
实际操作
- 使用WORD按照英文句号分行,使数据都是单独以.结尾单独成行的
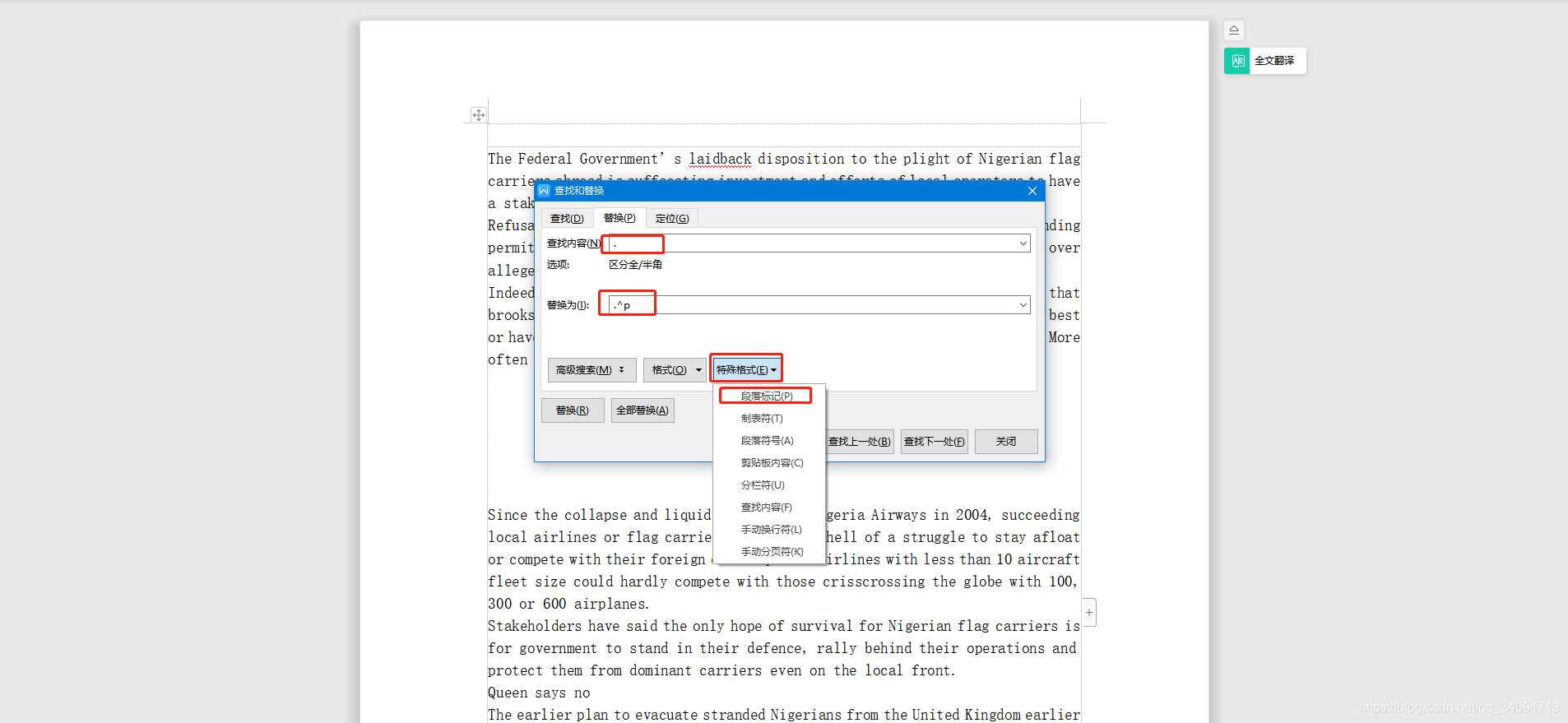
把需要分行的数据复制到WORD,然后Ctrl+F,选择替换,查找填.,被替换填.,然后选择特殊格式,选择段落标记,会发现被替换区关键字变成了.^p,然后选择全部替换,就会发现文档根据英文句号.换行了
-
分行后复制到Excel进行后续修改,首先是复制到A列,查看是否是一行一条数据,然后在B列输入以下函数
=LEN(A1)-LEN(SUBSTITUTE(A1," ",))+1
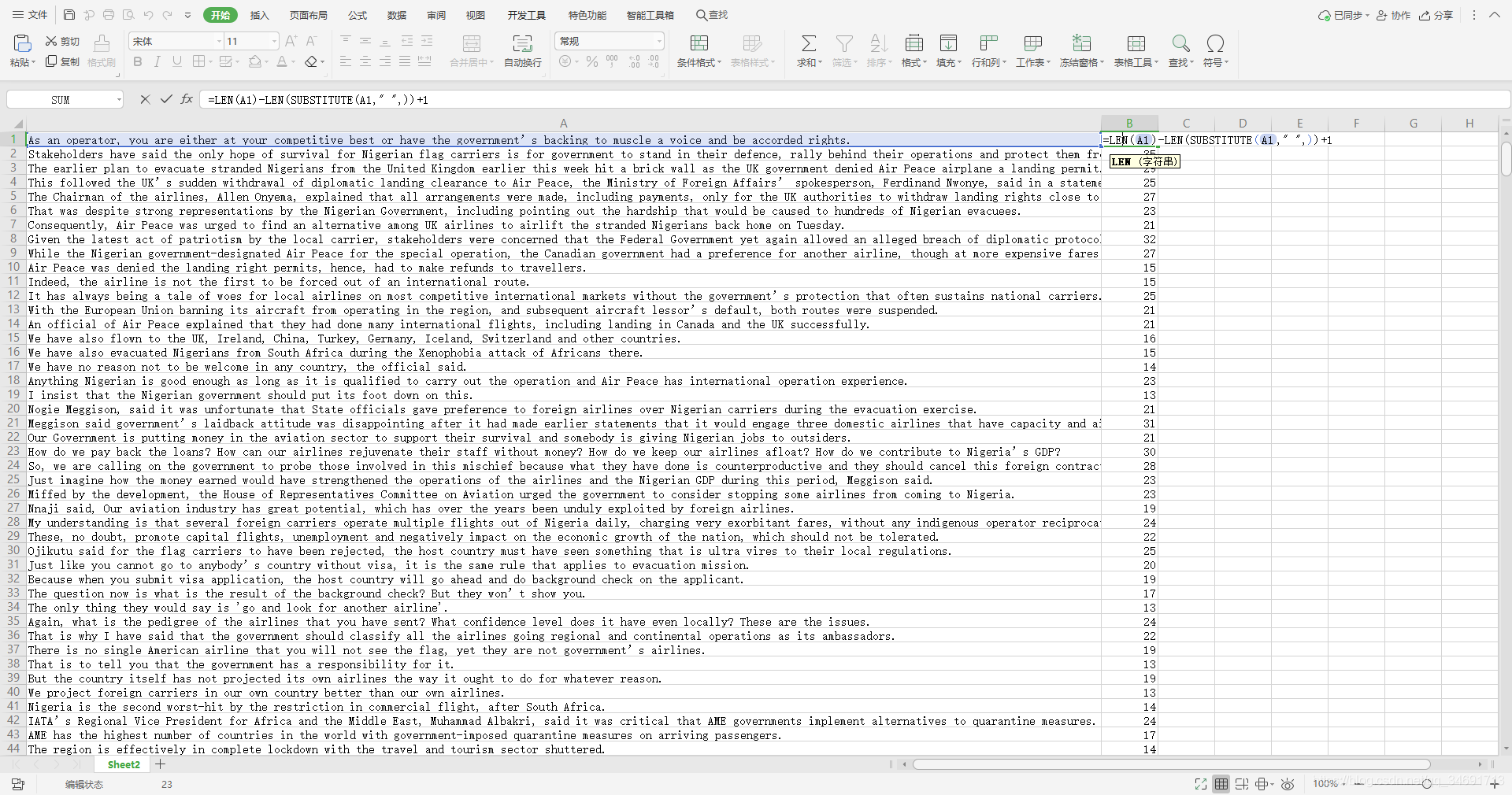
其原理就是调用函数,统计一句话里的空格个数,英语语句是词与词之间用空格隔开的,统计空格个数+1就是英语单词个数,但是要求是英文格式要对
然后就是点击筛选,按照字数筛选,筛选出小于长度10和大于长度35的数据删掉,长度这个条件解决了
查询*的时候,*属于特殊符号,是个正则表达式里的通配符,代表无限大的字符串,所以查询文本里的**~***
筛选数字的话,EXCEL里条件格式功能,开始->条件格式->突出显示单元格规则->文本包含,然后依次输入,0~9的数字,然后按颜色筛选再删除掉
后记
显然,这不是最优解,但是在紧急的情况下,这些小技巧也让我们的工作效率提高了很多

















 5116
5116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









