







Aggregating Sequential Views for 3D Global Feature Learning by CNN with Hierarchical Attention Aggregation
使用分层注意聚合的CNN聚合顺序视图进行三维全局特征学习
关键词:
3D2SeqViews;层次注意力聚合;递归视图集成;视图注意力机制
解决的问题:
在深度学习模型中,视图聚合所带来的内容信息和空间关系的损失,通过更有效地聚合多个视图的内容信息和空间关系来学习三维特征仍然是一个研究挑战。
原理:
3D2SeqViews概述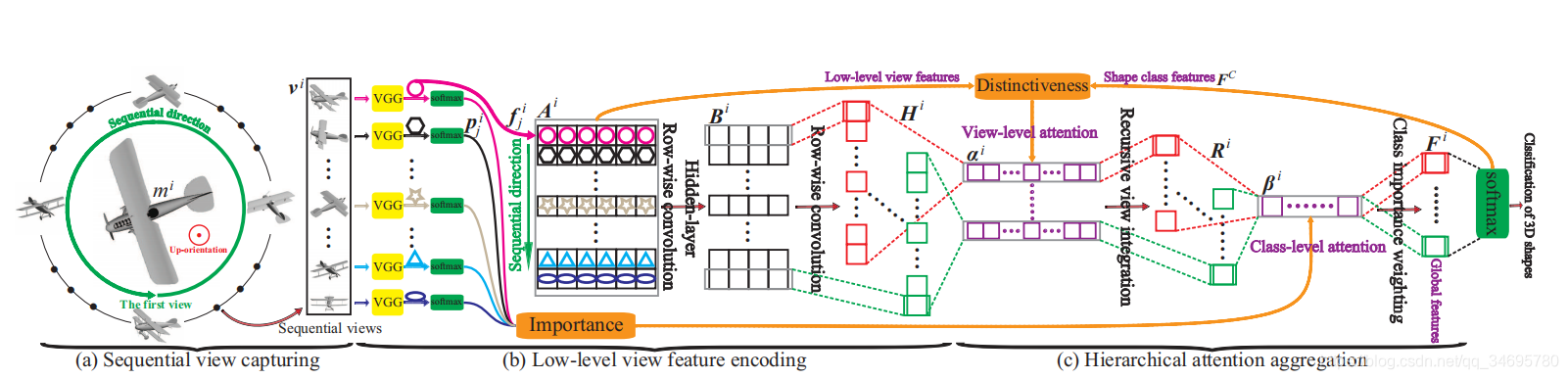 顺序视图首先在(a)中的圆圈上围绕每个向上的三维图形捕捉。然后,通过微调VGG网络提取后,对每个视图的低级特征进行逐行卷积编码,如(b)所示。最后,通过在分层注意聚合中聚合顺序视图来学习全局三维特征。
顺序视图首先在(a)中的圆圈上围绕每个向上的三维图形捕捉。然后,通过微调VGG网络提取后,对每个视图的低级特征进行逐行卷积编码,如(b)所示。最后,通过在分层注意聚合中聚合顺序视图来学习全局三维特征。
(1) 序列视图捕获
与传统的多视图捕获不同,序列视图是在一个圆圈上捕获的,而不是单位球体上捕获的。 虽然序列视图不能完全覆盖三维形状的顶部或底部,但序列视图中的内容信息可以更有效地聚合,同时保持视图之间的顺序空间性,用于三维全局特征学习。
(2) 低级视图特征编码
首先通过微调VGG19提取vi中每个视图vij的低级特征fij。 然后,通过使用逐行卷积降低低层特征的维数,抽象出每个视图中的内容信息。 最后,抽象的内容信息通过逐行卷积将所有Vij进一步编码成一组Hi列式特征映射。 在Hi中的内容信息和vi的顺序空间性随后通过分层注意聚合进行聚合。
(3) 分层注意聚合
是想将编码的内容信息聚合在序列视图中,并将视图之间的序列空间用于学习三维全局特征。 此外,需要注意的是视图级注意αi和类级注意βi对序列视图和形状类进行了分层加权。
视图级注意αi:指示每个形状类c对vi中的每个视图vij的注意程度,其中c∈[1,C]和C是形状类的数目。
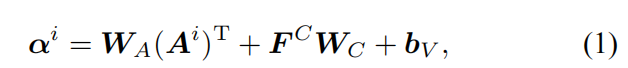
递归视图集成:不仅聚合了编码的内容信息第一个视点的h(j)具有视点级注意αi,也保持了视点间的序列空间性。在带有范数的特征映射上αi递归视图集成定义为,
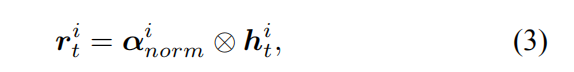
类级注意βi:不仅提取了序列视图的低级特征,而且还学习了序列视图分类的判别信息。 类级注意βi有助于3D2SeqViews采用这重要信息源。计算使用分类概率PIJ的序列视图提供的微调VGG19。
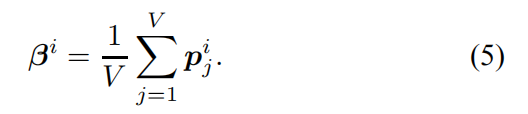
创新点
i)提出了一种新的深度学习模型3D2SeqViews,通过聚合序列视图来学习三维全局特征。它不仅对所有序列视图中的内容信息进行编码,而且保持了视图之间的序列空间性。
不仅有效地聚集了所有顺序视图中的内容信息,而且有效地聚集了视图之间的顺序空间性。
ii)在CNN中提出了一种新的视图聚合方法,称为层次注意力聚合(hierarchicalattention aggregation),用于同时聚合视图序列中的内容信息和序列空间性,其中提出了视图级注意和类级注意的综合结合,显著提高了学习特征的可分辨性。
iii)一种新的递归视图集成所捕获的序列空间性,改善了CNN有限的从序列数据中学习的能力,使3D2SeqViews能够学习对第一视点位置鲁棒的视图序列的语义。
iv)3D2SeqViews在分层注意聚合中,通过类级注意,创造性地利用了精细调整网络在低层视图特征提取中的鉴别能力,这是提高学习特征可分辨性的重要来源,但被现有方法所忽视。
优点
结果表明,分层注意聚合使3D2SeqViews能够通过比其他最先进的方法更有效地聚合顺序视图来学习更多的鉴别特征。
缺点
3D2SeqVIews 只能通过聚合顺序视图而不是任何其他类型的无序视图来学习特征,例如在以3D形状为中心的单元球体上捕获的视图.因此不能通过更详细的3D形状特征进一步提高学习全局特征的可鉴别性。
实验结果
数据集:ModelNet40、ModelNet10和ShapeNetCore55
参数设置:学习率ε 为0.000002;行向内核的数量K从{32, 64, 128, 256, 512, 1024}选择;丢弃率从{0.7, 0.5, 0}选择。准确率如下所示:
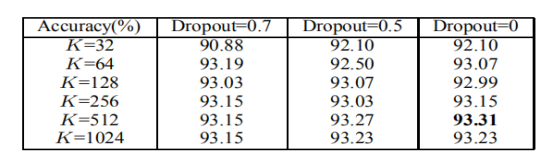
提高K可以提高性能,且丢弃率=0,k=512是最好的结果
K=512,dropout=0,不同的学习率:
ε = 0.000004结果最好。
K=512,dropout=0,顺序视图数V不同:

V=12时效果最好。
隐藏行卷积层的数目N,在隐藏层中增加行卷积来提取底层视图特征是否可以进一步提高3D2SeqViews的性能。ε =0.000004
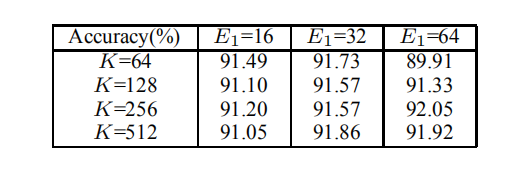
- ModelNet40, K=512, ε = 0.000004.
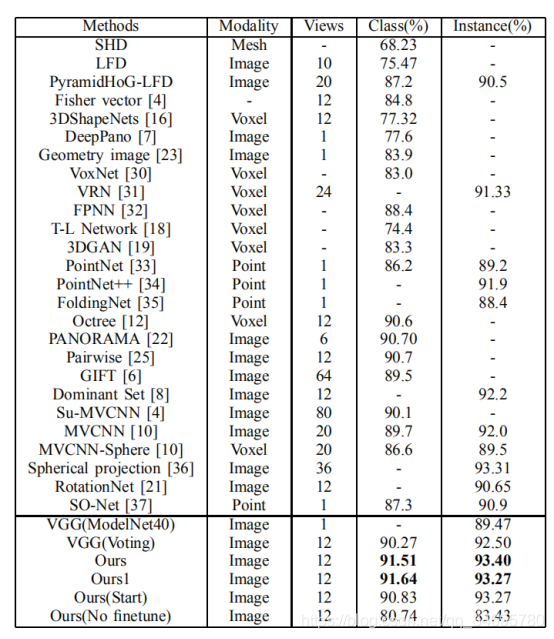
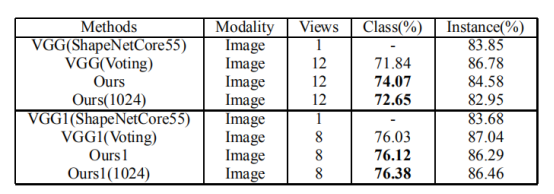
用的C=40微调,VGG(ModelNet40),单视图分类准确率89.47%
VGG(voting)所有序列视图分类准确率92.5%。
所以微调对于VGG提取低级视图特征很重要。这是因为VGG是预先训练的彩色图像,而序列视图是捕获没有颜色。
Ours(No finetune)通过训练3D2SeqViews得到的,这些特征是从预先训练的VGG中提取的低层视图特征,效果较差。
“Ours”和“Ours1”之间的比较,是每个形状类中形状的不平衡数量使得平均类精度和平均实例精度没有正相关。
因为3D2SeqViews是通过使用分层注意聚合序列视图来学习视图序列的语义,这使得3D2SeqViews对第一个视图位置不敏感。故通过训练具有随机第一视图位置的3D2SeqViews,得到了“Ours(Start)”的结果(第一个视图位置不是固定的训练)
2.ModelNet10,K=512, ε = 0.000004.
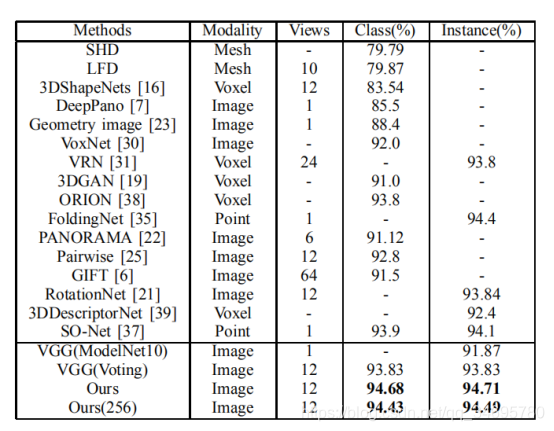
C=10.微调,VGG(ModelNet10),单视图分类准确率是91.87%,VGG(voting)所有序列视图分类准确率93.83%。
Ours(256),将K设置小点变成256,发现结果为94.43%和94.49%,不如大卷积核。
3.ShapeNetCore55,K=512, ε = 0.000004.
评估了形状分类的性能,上--没有颜色的视图得到的结果,下--有颜色的视图微调得到的结果。可以看出颜色在平均类精度方面稍微有助于提高3D2SeqViews的性能
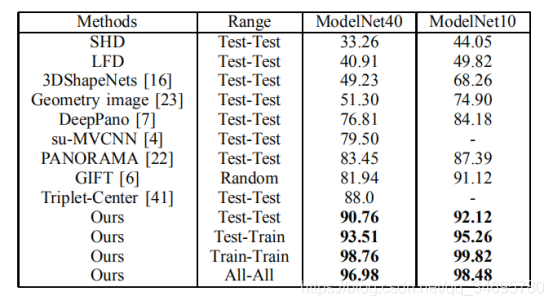
可视化
例如“Test-Train”表示测试集中的形状被用作查询,从训练集中检索形状。
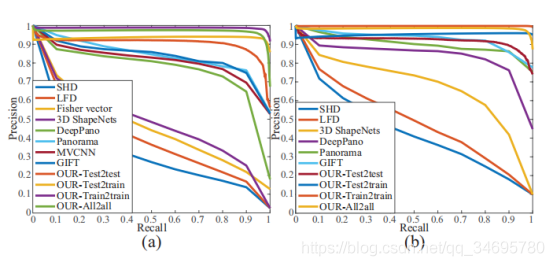
在(a)ModelNet40和(b)ModelNet10下,不同方法获得的精度和召回率之间的比较。














 7211
7211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









