







数据科学家的一部分使命是操作大量数据。有时候,这些数据中会包含大量文本语料。我们可以采用人工方式,亲自阅读,但我们也可以利用 Python 的力量。毕竟,代码存在的意义就是自动执行任务。
即便如此,从头开始写一个脚本也需要大量时间和精力。这就是正则表达式的用武之地。正则表达式(regular expression)也被称为 RE、regex 和 regular pattern,这是一种让我们能快速筛查和分析文本的紧凑型语言。正则表达式始于 1956 年——Stephen Cole Kleene 创造了它并将其用于描述人类神经系统的 McCulloch-Pitts 模型。到了 60 年代,Ken Thompson 将这种标记方法添加到了一个类似 Windows 记事本的文本编辑器中,自那以后,正则表达式不断发展壮大。
正则表达式的一大关键特征是其经济实用的脚本。你甚至可以将其看作是代码中的捷径。没有它,我们就要码更多代码才能实现相同的功能。正则也方便爬虫的使用。这里你需要一个代码编辑器,比如 Visual Code Studio、PyCharm 或 Atom,推荐使用anaconda3。此外,了解一点 pandas 的基本知识会很有帮助,这样在我们解读每一行代码时你才不会迷失方向。如果你需要学学 pandas,可以参考这个教程:pandas教程
介绍我们的数据集
我们将使用来自 Kaggle 的 Fraudulent Email Corpus(欺诈电子邮件语料库)。其中包含 1998 年到 2007 年之间发送的数千封钓鱼邮件。这些邮件读起来很有意思。我们首先将使用单封邮件学习基本的正则表达式命令,然后我们会对整个语料库进行处理,地址。介绍 Python 的正则表达式模块
首先,准备数据集:打开那个文本文件,将其设置成「只读」,然后读取它。我们也为其分配了一个变量 fh,表示文件句柄(file handle)。
fh = open(r"test_emails.txt", "r").read()现在,假设我们想知道这些电子邮件的发件人。我们可以试试只用原始的 Python 来实现:
for line in fh.split("\n"):
if "From:" in line:
print(line)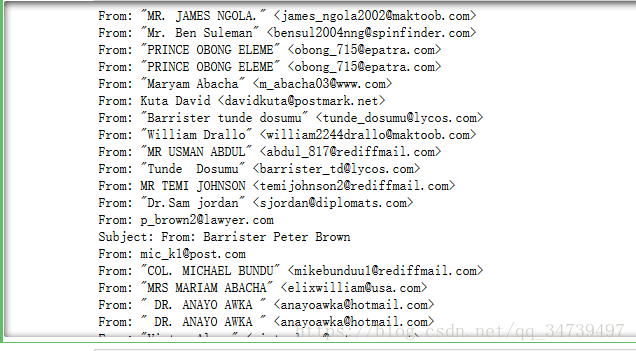
也可以使用正则表达式:
import re
for line in re.findall("From:.*", fh):
print(line)结果是一样的。
我们来解读一下这段代码。我们首先导入了 Python 的 re 模块。然后我们写了操作代码。在这个简单的示例中,这段代码只比原始 Python 少一行。但是,随着任务的增加,正则表达式可以让你的脚本继续保持简单经济。
re.findall() 返回字符串中满足其模式的所有实例的列表。这是 Python 内置的 re 模块中最常用的函数之一。分解看看。该函数的形式是 re.findall(pattern, string),有两个参数。其中,pattern 表示我们希望寻找的子字符串,string 表示我们要在其中查找的主字符串。主字符串可以包含很多行。
.* 是字符串模式的简写。我们马上就会详细解释。现在只需知道它们的作用是匹配 From: 字段中的名称和电子邮箱地址。
常见的正则表达式模式
我们在上面的 re.findall() 中使用的模式中包含一个完全拼写出来的字符串 From:。这在我们知道我们所要寻找的东西是什么时非常有用,可以确定到实际的字母以及大小写。如果我们不知道我们所想要的字符串的确切格式,我们将难以为继。幸运的是,正则表达式有解决这类情况的基本模式。我们看看本教程中会使用的一些模式:\w 匹配字母数字字符,即 a-z、A-Z 和 0-9,也会匹配下划线 _ 和连接号 –
- \d 匹配数字,即 0-9
- \s 匹配空白字符,包括制表符、换行符、回车符和空格符
- \S 匹配非空白字符
.匹配除换行符 \n 之外的任意字符
有了这些正则表达式模式,你就能在我们继续解释代码时很快理解。
- 使用正则表达式模式
.* 匹配 0 个或更多个其左侧的模式的实例。也就是说它会查找重复的模式。当我们查找重复模式时,我们说我们的搜索是「贪婪匹配」。如果我们没有查找重复模式,我们可以说我们的搜索是「非贪婪匹配」或「懒惰匹配」。
for line in re.findall("From:.*", fh):
print(line)因为 * 匹配 0 个或多个其左侧模式的实例且 . 在其左侧,所以我们可以获取 From: 字段中的所有字符,直到该行结束。这样就用美丽而简洁的代码输出显示了一整行。
我们甚至可以更进一步只取出其中的名称。
match = re.findall("From:.*", fh)
for line in match:
print(re.findall("\".*\"", line))
在第一个引号匹配后,.* 会获取这一行中下一个引号前的所有字符。当然,该模式中的下一个引号也经过了转义。这让我们可以得到引号之中的名称。每个名称都输出显示在方括号中,因为 re.findall 以列表形式返回匹配结果。
如果我们想得到电子邮箱地址呢?
match = re.findall("From:.*", fh)
for line in match:
print(re.findall("\w\S*@.*\w", line))电子邮箱地址中总会包含一个 @ 符号,所以我们从它开始入手。电子邮箱地址中 @ 符号前面的部分可能包含字母数字字符,这意味着需要 \w。但是,由于某些电子邮箱地址包含句号或连接号,所以这还不够。我们增加了 \S 来查找非空白字符。但 \w\S 只能得到两个字符,所以增加 * 来重复查找。所以 @ 符号之前部分的模式是 \w\S*@。接下来看 @ 符号之后的部分。
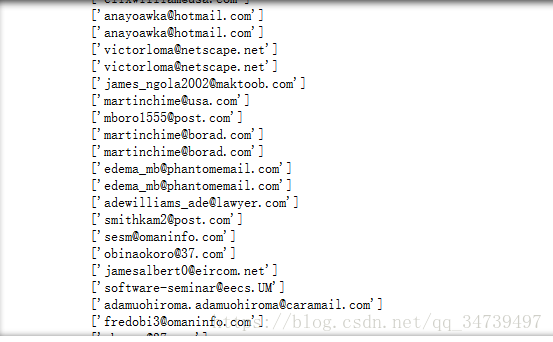
电子邮箱地址是以字母数字字符结尾的,所以我们用 \w 作为这一模式的结尾。因此,@ 符号之后的部分是 .\w,也就是说我们想要的模式是一组以字母数字字符结尾的任意类型的字符。这样就排除了 >。因此,完整的电子邮箱地址模式就为 \w\S@.*\w
- 常见的正则表达式函数
re.findall() 毫无疑问非常有用,re 模块还提供了一些同样方便的函数,其中包括:
- re.search()
re.findall() 匹配的是一个模式在一个字符串中的所有实例然后以列表的形式返回它们,而 re.search() 匹配的是一个模式在一个字符串中的第一个实例,然后以 re 匹配对象的形式返回它。 - re.split()
假设我们需要一种获取电子邮箱地址域名的快速方式。我们可以用 3 个正则表达式操作来完成。如下:
- re.search()
address = re.findall("From:.*", fh)
for item in address:
for line in re.findall("\w\S*@.*\w", item):
username, domain_name = re.split("@", line)
print("{}, {}".format(username, domain_name))
第一行我们很熟悉。我们返回一个字符串列表并为其分配一个变量,其中每个字符串都包含了 From: 字段的内容。接下来我们遍历整个列表,寻找电子邮箱地址。与此同时,我们遍历这些电子邮箱地址并使用 re 模块的 split() 函数以 @ 符号为分割符将每个电子邮件一分为二。最后,我们将其显示出来。
- re.sub()
re.sub() 是另一个很好用的 re 函数。顾名思义,它的功能是替换一个字符串的一部分。举个例子:
sender = re.search("From:.*", fh)
address = sender.group()
email = re.sub("From", "Email", address)
print(address)
print(email)其中第一行和第二行的任务我们之前已经见过。第三行我们在 address 上应用 re.sub(); address 是电子邮件标头中的完整的 From: 字段。
re.sub() 有三个参数。第一个是所要替换的子字符串,第二个是用来替换前者的字符串,第三个是主字符串本身。
- pandas 的正则表达式
现在我们已经有了正则表达式的基础,我们可以试试一些更高级的功能。但是,我们需要将正则表达式与 pandas Python 数据分析库结合起来。在将数据整理成整洁的表格(也称为 dataframe)方面,pandas 非常有用,而且还能让我们从不同的角度理解数据。与正则表达式那经济简练的代码结合到一起,就好像是用快刀切黄油——简单利落。 使用正则表达式和 pandas 整理电子邮件
我们的语料库是包含了数千封电子邮件的单个文本文件。我们将使用正则表达式和 pandas 将每封电子邮件的各部分整理到合适的类别中,以便对该语料库的读取和分析更简单。- sender_name(发件人名称)
- sender_address(发件人地址)
- recipient_address(收件人地址)
- recipient_name(收件人名称)
- date_sent(发送时间)
- subject(主题)
- email_body(邮件正文)
其中每个类别都会成为我们的 pandas dataframe 或表格中的一列。这会很有用,因为这让我们可以操作每一列本身。比如,这让我们可以编写代码来查找这些电子邮件来自哪些域名,而无需先编写代码将电子邮箱地址与其它部分隔开。本质上讲,将我们的数据集中的重要部分分门别类让我们可以之后用简练得多的代码获取细粒度的信息。反过来,简洁的代码也能减少我们的机器必须执行的运算的数量,这能加速我们的分析过程,尤其是当操作大规模数据集时。
首先在脚本最上面,我们按照标准惯例导入 re 和 pandas。我们也导入了 Python 的 email 包,电子邮件正文的处理尤其需要这个包。如果只使用正则表达式,那么电子邮件正文处理起来会相当复杂,甚至可能还需要一篇单独的教程才能说请。所以我们使用开发优良的 email 包来节省时间,让我们专注学习正则表达式。
接下来我们创建一个空列表 emails,用来存储字典。每个字典都将包含每封电子邮件的细节。
我们经常把代码的结果显示在屏幕上,以了解代码正确或出错的位置。但是,因为数据集中存在数千封电子邮件,所以这会在屏幕上打印出数千行,从而让本教程臃肿不堪。我们肯定不想不断滚动数千行结果。因此,正如我们在本教程开始时做的那样,我们打开并阅读一个语料库的缩短版。我们是通过人工的方式专为本教程准备的。但你自己练习的时候可以使用实际的数据集。每当你运行 print() 函数时,你都能在几秒之内在屏幕上看到数千行结果。
现在,开始使用正则表达式。
if date_field is not None:
date = re.search(r"\d+\s\w+\s\d+", date_field.group())
else:
date = None
print(date_field.group())日期是以一个数字开始的。因此我们使用 \d 表示它。但是,DD 部分的日期可能是一个数字,也可能是两个数字。因此这里的 + 号就很重要了。在正则表达式中,+ 匹配 1 个或多个其左侧模式的实例。因此 \d+ 可以匹配 DD 部分,不管是一个数字还是两个数字。
在那之后,有一个空格。用 \s 代表,可以查找空白字符。月份由三个字母组成,因此用 \w+。然后是另一个空格 \s。年份由数字组成,所以再次使用 \d+。
完整的模式 \d+\s\w+\s\d+ 是有效的,因为它是两边都有空白字符的精确模式。
接下来,我们想之前一样检查 None 值。
full_email = email.message_from_string(item)
body = full_email.get_payload()
emails_dict["email_body"] = body将邮件标头与正文分开是一项很复杂的任务,尤其是当很多标头都不一样时。在原始的未整理的数据中,一致的情况很少见。幸运的是,这项工作已经被完成了。Python 的 email 包非常适合这项任务。我们之前已经导入了这个包。现在我们将 message_from_string() 应用在 item 上,将整封电子邮件变成一个 email 消息对象。消息对象包含一个标头和一个 payload,分别对应电子邮件的标头和正文。
接下来,我们在这个消息对象上应用 get_payload() 函数。这个函数可以分离出电子邮件的主体。我们将其分配给变量 body,然后插入到我们的 emails_dict 字典中的 “email_body” 下。
完整代码:
import re
import pandas as pd
import email
emails = []
fh = open(r"./fraudulent-email-corpus/fradulent_emails.txt","r",errors='ignore').read()
contents = re.split(r"From r",fh)
contents.pop(0)
for item in contents:
emails_dict = {}
sender = re.search(r"From:.*", item)
if sender is not None:
s_email = re.search(r"\w\S*@.*\w", sender.group())
s_name = re.search(r":.*<", sender.group())
else:
s_email = None
s_name = None
if s_email is not None:
sender_email = s_email.group()
else:
sender_email = None
emails_dict["sender_email"] = sender_email
if s_name is not None:
sender_name = re.sub("\s*<", "", re.sub(":\s*", "", s_name.group()))
else:
sender_name = None
emails_dict["sender_name"] = sender_name
recipient = re.search(r"To:.*", item)
if recipient is not None:
r_email = re.search(r"\w\S*@.*\w", recipient.group())
r_name = re.search(r":.*<", recipient.group())
else:
r_email = None
r_name = None
if r_email is not None:
recipient_email = r_email.group()
else:
recipient_email = None
emails_dict["recipient_email"] = recipient_email
if r_name is not None:
recipient_name = re.sub("\s*<", "", re.sub(":\s*", "", r_name.group()))
else:
recipient_name = None
emails_dict["recipient_name"] = recipient_name
date_field = re.search(r"Date:.*", item)
if date_field is not None:
date = re.search(r"\d+\s\w+\s\d+", date_field.group())
else:
date = None
if date is not None:
date_sent = date.group()
else:
date_sent = None
emails_dict["date_sent"] = date_sent
subject_field = re.search(r"Subject: .*", item)
if subject_field is not None:
subject = re.sub(r"Subject: ", "", subject_field.group())
else:
subject = None
emails_dict["subject"] = subject
# "item" substituted with "email content here" so full email not displayed.
full_email = email.message_from_string(item)
body = full_email.get_payload()
emails_dict["email_body"] = "email body here"
emails.append(emails_dict)
# Print number of dictionaries, and hence, emails, in the list.
print("Number of emails: " + str(len(emails_dict)))
print("\n")
# Print first item in the emails list to see how it looks.
for key, value in emails[2].items():
print(str(key) + ": " + str(emails[0][key]))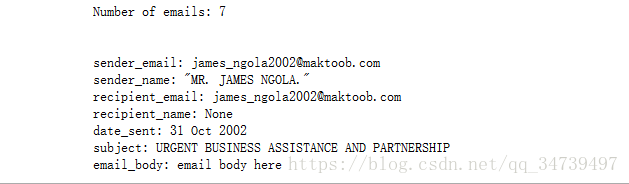
emails_df[emails_df["sender_email"].str.contains("maktoob|spinfinder")]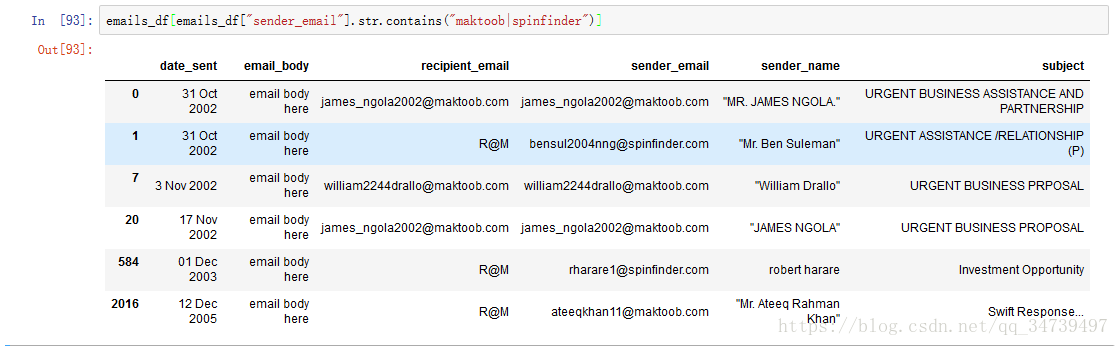
竖线符号 | 会查找其两边的字符,比如 a|b 会查找 a 或 b。
| 看起来似乎和 [ ] 一样,但实际并不一样。假如我们要查找 crab 或 lobster 或 isopod,那么使用 crab|lobster|isopod 会比使用 [crablobsterisopod] 要合理得多。前者是查找其中每个词,而后者是搜索其中每个字母。














 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









