一、理论基础
HA 概念以及作用
HA(High Available), 高可用性群集,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。通常把正在执行业务的称为活动节点,而作为活动节点的一个备份的则称为备用节点。当活动节点出现问题,导致正在运行的业务(任务)不能正常运行时,备用节点此时就会侦测到,并立即接续活动节点来执行业务。从而实现业务的不中断或短暂中断。
基础架构
1、NameNode(Master)
1)命名空间管理:命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
2)块存储管理。
NameNode+HA架构
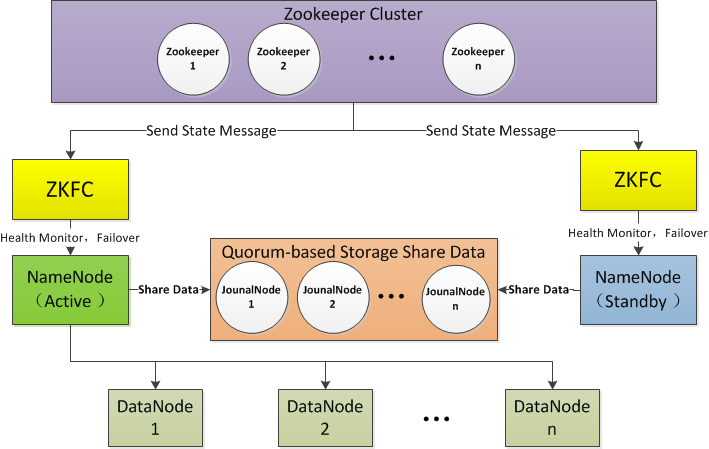
从上面的架构图可以看出,使用Active NameNode,Standby NameNode 两个节点可以解决单点问题,两个节点通过JounalNode共享状态,通过ZKFC 选举Active ,监控状态,自动备份。
1、Active NameNode
接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report, block location updates和heartbeat。
2、Standby NameNode
同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,保持自己NameNode中的元数据(Namespcae information + Block locations map)和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot Standby NameNode),一旦切换成Active模式,马上就可以提供NameNode服务。
3、JounalNode
用于Active NameNode , Standby NameNode 同步数据,本身由一组JounnalNode节点组成,该组节点奇数个。
4、ZKFC
监控NameNode进程,自动备份。
二、集群规划
| 主机名 | IP | 安装的软件 | 运行的进程 |
|---|
| cs0 | 192.168.80.128 | jdk1.7、hadoop | NameNode、ResourceManager、QuorumPeerMain、DFSZKFailoverController(zkfc) |
| cs1 | 192.168.80.129 | jdk1.7、hadoop | NameNode、ResourceManager、QuorumPeerMain、DFSZKFailoverController(zkfc) |
| cs2 | 192.168.80.130 | jdk1.7、hadoop、zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| cs3 | 192.168.80.131 | jdk1.7、hadoop、zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| cs4 | 192.168.80.132 | jdk1.7、hadoop、zookeeper | DataNode、NodeManager、JournalNode、QuorumPeerMain |
备注:Journalnode和ZooKeeper保持奇数个,这点大家要有个概念,最少不少于 3 个节点。
| 名称 | 路径 |
|---|
| 所有软件目录 | /home/hadoop/app/ |
| 所有数据和日志目录 | /home/hadoop/data/ |
三、集群安装前的环境检查
所有节点的系统时间要与当前时间保持一致。
查看当前系统时间
- [root@cs0 ~]# date
- Sun Apr 24 04:52:48 PDT 2016
如果系统时间与当前时间不一致,进行以下操作。
- [root@cs0 ~]# cd /usr/share/zoneinfo/
- [root@cs0 zoneinfo]# ls //找到Asia
- [root@cs0 zoneinfo]# cd Asia/ //进入Asia目录
- [root@cs0 Asia]# ls //找到Shanghai
- [root@cs0 Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime //当前时区替换为上海
我们可以同步当前系统时间和日期与NTP(网络时间协议)一致。
- [root@cs0 Asia]# yum install ntp //如果ntp命令不存在,在线安装ntp
- [root@cs0 Asia]# ntpdate pool.ntp.org //执行此命令同步日期时间
- [root@cs0 Asia]# date //查看当前系统时间
所有节点的hosts文件都要配置静态ip与hostname之间的对应关系。
- [root@cs0 ~]# vi /etc/hosts
- 192.168.80.128 cs0
- 192.168.80.129 cs1
- 192.168.80.130 cs2
- 192.168.80.131 cs3
- 192.168.80.132 cs4
禁用防火墙
所有节点的防火墙都要关闭。
查看防火墙状态
- [root@cs0 ~]# service iptables status
- iptables: Firewall is not running.
如果不是上面的关闭状态,则需要关闭防火墙。
- [root@cs0 ~]# chkconfig iptables off //永久关闭防火墙
- [root@cs0 ~]# service iptables stop
四、 配置SSH免密码通信
- hadoop@cs0 ~]$ mkdir .ssh
- [hadoop@cs0 ~]$ ssh-keygen -t rsa //执行命令一路回车,生成秘钥
- [hadoop@cs0 ~]$cd .ssh
- [hadoop@cs0 .ssh]$ ls
- authorized_keys id_rsa id_rsa.pub known_hosts
- [hadoop@cs0 .ssh]$ cat id_rsa.pub >> authorized_keys //将公钥保存到authorized_keys认证文件中
集群所有节点都要行上面的操作。
将所有节点中的共钥id_ras.pub拷贝到djt11中的authorized_keys文件中。
cat ~/.ssh/id_rsa.pub | ssh hadoop@cs0 'cat >> ~/.ssh/authorized_keys'
所有节点都需要执行这条命令
然后将cs0中的authorized_keys文件分发到所有节点上面。
- scp -r authorized_keys hadoop@cs1:~/.ssh/
-
- scp -r authorized_keys hadoop@cs2:~/.ssh/
-
- scp -r authorized_keys hadoop@cs3:~/.ssh/
-
- scp -r authorized_keys hadoop@cs45:~/.ssh/
六、jdk安装
将本地下载好的jdk1.7,上传至cs0节点下的/home/hadoop/app目录。
- [root@cs0 tools]# su hadoop
- [hadoop@cs0 tools]$ cd /home/hadoop/app/
- [hadoop@cs0 app]$ rz //选择本地的下载好的jdk-7u79-linux-x64.tar.gz
- [hadoop@cs0 app]$ ls
- jdk-7u79-linux-x64.tar.gz
- [hadoop@cs0 app]$ tar -zxvf jdk-7u79-linux-x64.tar.gz //解压
- [hadoop@cs0 app]$ ls
- jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
- [hadoop@cs0 app]$ rm jdk-7u79-linux-x64.tar.gz //删除安装包
添加jdk环境变量。
- [hadoop@cs0 app]$ su root
- Password:
- [root@cs0 app]# vi /etc/profile
- JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
- CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- PATH=$JAVA_HOME/bin:$PATH
- export JAVA_HOME CLASSPATH PATH
- [root@cs0 app]# source /etc/profile //使配置文件生效
查看jdk是否安装成功。
- [root@cs0 app]# java -version
- java version "1.7.0_79"
- Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
- Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
出现以上结果就说明cs0节点上的jdk安装成功。
然后将cs0下的jdk安装包复制到其他节点上。
[hadoop@cs0 app]$ scp jdk1.7.0_79 hadoop@cs1:`pwd` --还有cs2,cs3,cs4节点
记得最后/etc/profile这个文件也需要
七、Zookeeper安装
将本地下载好的zookeeper-3.4.6.tar.gz安装包,上传至cs0节点下的/home/hadoop/app目录下。
- [hadoop@cs0 app]$ ls
- jdk1.7.0_79 zookeeper-3.4.6.tar.gz
- [hadoop@cs0 app]$ tar zxvf zookeeper-3.4.6.tar.gz //解压
- [hadoop@cs0 app]$ ls
- jdk1.7.0_79 zookeeper-3.4.6.tar.gz zookeeper-3.4.6
- [hadoop@cs0 app]$ rm zookeeper-3.4.6.tar.gz //删除zookeeper-3.4.6.tar.gz安装包
- [hadoop@cs0 app]$ mv zookeeper-3.4.6 zookeeper //重命名
修改Zookeeper中的配置文件。
- [hadoop@cs0 app]$ cd /home/hadoop/app/zookeeper/conf/
- [hadoop@cs0 conf]$ ls
- configuration.xsl log4j.properties zoo_sample.cfg
- [hadoop@cs0 conf]$ cp zoo_sample.cfg zoo.cfg //复制一个zoo.cfg文件
- [hadoop@cs0 conf]$ vi zoo.cfg
- dataDir=/home/hadoop/data/zookeeper/zkdata //数据文件目录
- dataLogDir=/home/hadoop/data/zookeeper/zkdatalog //日志目录
- # the port at which the clients will connect
- clientPort=2181
- //server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader)
- server.0=cs2:2888:3888
- server.1=cs3:2888:3888
- server.2=cs4:2888:3888
将Zookeeper安装目录拷贝到其他节点上面。
- [hadoop@cs0 app]$ scp -r zookeeper hadoop@cs2:`pwd`
- [hadoop@cs0 app]$ scp -r zookeeper hadoop@cs3:`pwd`
- [hadoop@cs0 app]$ scp -r zookeeper hadoop@cs4:`pwd`
在所有的节点上面创建目录:
- [hadoop@cs0 app]$ mkdir -p /home/hadoop/data/zookeeper/zkdata //创建数据目录
- [hadoop@cs0 app]$ mkdir -p /home/hadoop/data/zookeeper/zkdatalog //创建日志目录
然后分别在cs0、cs1、cs2、cs3、cs4上面,进入zkdata目录下,创建文件myid,里面的内容分别填充为:0、1、2、3、4, 这里我们以cs0为例。
- [hadoop@cs0 app]$ cd /home/hadoop/data/zookeeper/zkdata
- [hadoop@cs0 zkdata]$ vi myid
- 1 //输入数字1
配置Zookeeper环境变量。
- [hadoop@cs0 zkdata]$ su root
- Password:
- [root@cs0 zkdata]# vi /etc/profile
- JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
- ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
- CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
- export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
- [root@cs0 zkdata]# source /etc/profile //使配置文件生效
在cs0节点上面启动Zookeeper。
- [hadoop@cs0 zkdata]$ cd /home/hadoop/app/zookeeper/
- [hadoop@cs0 zookeeper]$ bin/zkServer.sh start
- [hadoop@cs0 zookeeper]$ jps
- 3633 QuorumPeerMain
- [hadoop@cs0 zookeeper]$ bin/zkServer.sh stop //关闭Zookeeper
启动所有节点上面的Zookeeper。 co
三个全部启动之后!分别查看状态
如果一个节点为leader,另lian'ge个节点为follower,则说明Zookeeper安装成功。
八、hadoop集群环境搭建
将下载好的apache hadoop-2.6.0.tar.gz安装包,上传至cs0节点下的/home/hadoop/app目录下
- [hadoop@cs0 app]$ ls
- hadoop-2.6.0.tar.gz jdk1.7.0_79 zookeeper
- [hadoop@cs0 app]$ tar zxvf hadoop-2.6.0.tar.gz //解压
- [hadoop@cs0 app]$ ls
- hadoop-2.6.0 hadoop-2.6.0.tar.gz jdk1.7.0_79 zookeeper
- [hadoop@cs0 app]$ rm hadoop-2.6.0.tar.gz //删除安装包
- [hadoop@cs0 app]$ mv hadoop-2.6.0 hadoop //重命名
切换到/home/hadoop/app/hadoop/etc/hadoop/目录下,修改配置文件。
- [hadoop@cs0 app]$ cd /home/hadoop/app/hadoop/etc/hadoop/
配置HDFS
配置hadoop-env.sh
- [hadoop@cs0 hadoop]$ vi hadoop-env.sh
- export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
修改core-site.xml
- <configuration>
-
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://ns1/</value>
- </property>
-
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/Hadoop/data/tmp</value>
- </property>
-
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>cs2:2181,cs3:2181,cs4:2181</value>
- </property>
- </configuration>
修改hdfs-site.xml
- <configuration>
-
- <property>
- <name>dfs.nameservices</name>
- <value>ns1</value>
- </property>
-
- <property>
- <name>dfs.ha.namenodes.ns1</name>
- <value>nn1,nn2</value>
- </property>
-
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn1</name>
- <value>cs0:9000</value>
- </property>
-
- <property>
- <name>dfs.namenode.http-address.ns1.nn1</name>
- <value>cs0:50070</value>
- </property>
-
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn2</name>
- <value>cs1:9000</value>
- </property>
-
- <property>
- <name>dfs.namenode.http-address.ns1.nn2</name>
- <value>cs1:50070</value>
- </property>
-
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://cs2:8485;cs3:8485;cs4:8485/ns1</value>
- </property>
-
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/home/Hadoop/data/journaldata</value>
- </property>
-
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
-
- <property>
- <name>dfs.client.failover.proxy.provider.ns1</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
-
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>
- sshfence
- shell(/bin/true)
- </value>
- </property>
-
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>home/hadoop/.ssh/id_rsa</value>
- </property>
-
- <property>
- <name>dfs.ha.fencing.ssh.connect-timeout</name>
- <value>30000</value>
- </property>
- </configuration>
mapred-site.xml.template
需要重命名: mv mapred-site.xml.template mapred-site.xml
- <configuration>
-
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
yarn-site.xml
- <configuration>
-
- <property>
- <name>yarn.resourcemanager.ha.enabled</name>
- <value>true</value>
- </property>
-
- <property>
- <name>yarn.resourcemanager.cluster-id</name>
- <value>yrc</value>
- </property>
-
- <property>
- <name>yarn.resourcemanager.ha.rm-ids</name>
- <value>rm1,rm2</value>
- </property>
-
- <property>
- <name>yarn.resourcemanager.hostname.rm1</name>
- <value>cs0</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname.rm2</name>
- <value>cs1</value>
- </property>
-
- <property>
- <name>yarn.resourcemanager.zk-address</name>
- <value>cs2:2181,cs3:2181,cs4:2181</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
配置 slave
- [hadoop@cs0 hadoop]$ vi slaves
- cs2
- cs3
- cs4
向所有节点分发hadoop安装包。
- [hadoop@cs0 app]$ scp hadoop hadoop@cs1:`pwd`
hdfs配置完毕后启动顺序
1、启动cs2,cs3,cs4节点上面的Zookeeper进程
- [hadoop@cs0 hadoop]$ /home/hadoop/app/zookeeper/bin/zkServer.sh start
2、启动cs2,cs3,cs4节点上面的journalnode进程
- [hadoop@cs2 hadoop]$ /home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode
3、在cs0节点上格式化hdfs
- [hadoop@cs0 hadoop]$ bin/hdfs namenode -format / /namenode 格式化
注意:格式化之后需要把tmp目录拷给cs1(不然cs1的namenode起不来)
- [hadoop@cs0 hadoop]:$ scp -r tmp/ cs1:`pwd`
4、在cs0节点上格式化zkfc
[hadoop@cs0 hadoop]$ bin/hdfs zkfc -formatZK //格式化高可用
5、在cs0上启动hdfs
[hadoop@cs0 sbin]$ ./sbin/start-dfs.sh
6、启动YARN
在cs0上执行./sbin/start-yarn.sh
在cs1上执行./sbin/yarn-daemon.sh start resourcemanager
通过浏览器测试如下:
http://192.168.80.128:50070/
http://192.168.80.129:50070/
可以看出cs0的namenode是处于一种standby状态,那么cs1应该是处于active状态
hdfs haadmin -getServiceState nn1

hdfs haadmin -getServiceState nn2

把cs1(192.168.80.129)的namenode 进程kill掉

hdfs haadmin -getServiceState nn1

hdfs haadmin -getServiceState nn2

可以看出cs0的namenode是处于一种active状态cs1不能访问
重新启动cs1的namenode
./sbin/hadoop-daemon.sh start namenode
cs1会变成acitve状态
查看YARN的状态
http://192.168.80.128:8088/
NN 由standby转化成active
hdfs haadmin -transitionToActive nn1 --forcemanual























 3596
3596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









