






ES的分布式架构原理概述
这是一道面试题
一、ES的基本概念
这里先做一个和mysql的类比(只是类比,有助理解而已):索引index=mysql的Database,类型type=mysql的table,文档document=mysql的row,域field=mysql的Column。
索引在创建的时候就已经确定了主分片primary shard的数量,并且主分片数量是不能更改的,还有确定了副分片replica shard的数量(这是可以更改的,因此可以做水平扩容)。
一个索引可以有多个主分片来分别存储索引的数据,因此每个主分片只是存储了索引的部分数据,而副分片就是主分片的一个副本,那为什么要有如此多的主分片和副分片呢?主要是为了增强集群的吞吐量以及实现高可用。
倒排索引
用一句话概括何为倒排索引:用属性值来确定记录的位置,而不是用记录确定属性值。
打个比方:
Java是最好的语言
php是最垃圾的语言
python是最好学的语言
(只是打个比方,并没有恶意)
那么经过分词创建的倒排索引:
关键词 文章所在ID
Java 1
php 2
python 3
是 1、2、3
最好 1
最垃圾 2
最好学 3
的 1、2、3
语言 1、2、3
那么就可以搜索关键词来获取文章所在的位置,这就叫做倒排索引
二、ES的分布式实现
ES的分布式实现说白了就是在多台机器上启动多个ES进程,从而行程ES的集群。
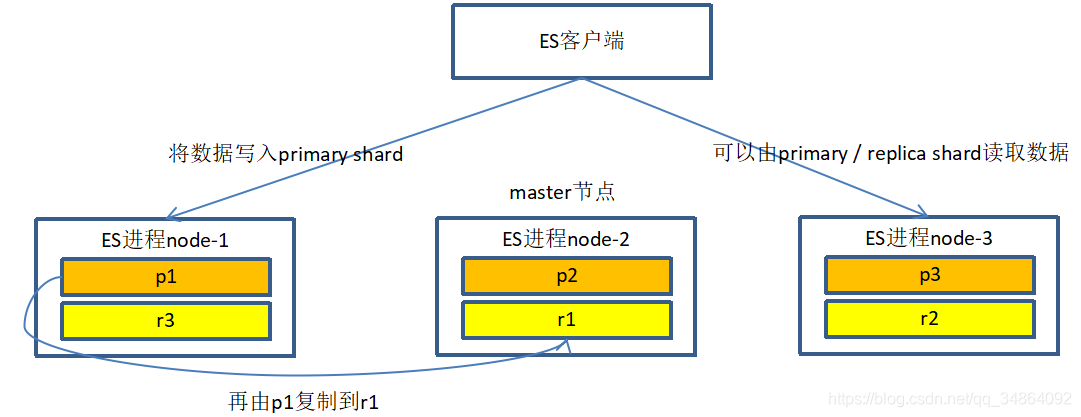
请注意上面的细节,主分片和副分片不能在同一个节点中(除非你只有一台机器咯),这个分配是集群自动分配的,不需要管。
集群多个节点会自动选举master节点,主要负责索引元数据维护、primary shard和replica shard身份的切换等等。若是master宕机了,那集群就重新选举新的master。
如果其中一个节点宕机了,上面的主分片不就是没了吗?那么就由master来将其对应的副分片提升到主分片的级别,从而实现高可用,等故障的节点修复过来了,其上的分片就继续作为副分片存在,现在是不是理解为什么主分片和副分片不能在同一节点上了吧?同理,如果master宕机了,那么有新的master进行主副切换。
读写操作流程也说一下吧:
写操作:
1、客户端选取任意一个节点称之为协调节点,发起写操作
2、协调节点根据文档id,计算路由,将请求转发到具体的处理节点
3、处理节点的primary shard执行写请求,成功后并将请求分发到各个replica shard执行,等所有的replica shard都成功处理后,再通知协调节点,通知客户端
当然可以设置参数,等primary shard成功后就通知客户端,不过没必要,因为ES本身就非常快
读操作:
1、客户端任意选取一个节点称之为协调节点,发起读操作
2、协调节点计算路由,将请求转发到具体的处理节点
3、处理节点通过负载均衡,轮询所有的分片,返回结果给协调节点,最后返回给客户端
搜索的读操作:
1、客户端任意选取一个节点称之为协调节点,发起读操作
2、协调节点将搜索请求发给所有的节点对应的primary和replica
3、所有分片将自身查到的id返回给协调节点,由协调节点进行合并、排序、分页等
4、最后由协调节点根据id到具体的节点拉取数据,返回给客户端














 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









