







Abstract
基于图像的序列识别一直是计算机视觉中长期存在的研究课题。在本文中,我们研究了场景文本识别的问题,这是基于图像的序列识别中最重要和最具挑战性的任务之一。我们一种新颖的神经网络架构,集成了特征提取,序列建模和转换的统一框架。与以前的场景文本识别系统相比,所提出的架构具有四个独特的属性:(1)它是端到端可训练的,与大多数现有算法相反,其中的组件是单独训练和调整的。(2)它自然地处理任意长度的序列,不涉及字符分割或水平缩放归一化。(3)它不局限于任何预定义的词典,并且在无词典和词典的场景文本识别任务中都取得了显着的表现。(4)它生成一个有效但小得多的模型,这对于实际应用场景更为实用。在标准基准上的实验,包括IIIT-5K,街景文本和ICDAR数据集,证明了所提出的算法优于现有技术的优越性。此外,该算法在基于图像的乐谱识别任务中表现良好,显然验证了它的通用性。
1. Introduction
最近,会议中已经看到神经网络的复兴,这主要受到深度神经网络模型,特别是深度卷积神经网络(DCNN)在各种视觉任务中的巨大成功的刺激。然而,最近与深度神经网络相关的大多数工作都致力于对象类别的检测或分类[12,25]。在本文中,我们关注计算机视觉中的一个经典问题:基于图像的序列识别。在现实世界中,稳定的视觉对象(例如场景文本,手写和乐谱)倾向于以序列的形式出现,而不是孤立地出现。与一般对象识别不同,识别这种类似序列的对象通常需要系统预测一系列对象标签,而不是单个标签。因此,对这些对象的识别可以自然地作为序列识别问题。序列式对象的另一个独特属性是它们的长度可能会发生很大变化。例如,英语单词‘OK’可以由2个字符组成,例如“OK”或15个字符,例如“congratulations”。因此,最流行的深度模型如DCNN [25,26]不能直接应用于序列预测,因为DCNN模型通常在具有固定维度的输入和输出上操作,因此不能产生可变长度标签序列。
已经进行了一些尝试来针对特定的类序列对象(例如场景文本)解决该问题。例如,[35,8]中的算法首先检测单个字符,然后用DCNN模型识别这些检测到的字符,DCNN模型使用标记的字符图像进行训练。这种方法通常需要训练强字符检测器,以便从原始字图像中精确地检测和裁剪每个字符。其他一些方法(如[22])将场景文本识别视为图像分类问题,并为每个英文单词(总共90K个单词)分配一个类别标签。事实证明,一个训练好的模型具有大量的类,很难推广到其他类型的序列式对象,如中文文本,乐谱等,因为这类基本组合的数量很多,序列可以大于100万。总之,基于DCNN的当前系统不能直接使用基于图像的序列识别。
递归神经网络(RNN)模型是深度神经网络家族的另一个重要分支,主要用于处理序列。RNN的一个优点是它在训练和测试中都不需要序列对象图像中每个元素的位置。但是,将输入对象图像转换为图像特征序列的预处理步骤通常是必不可少的。例如,Graves等。 [16]从手写文本中提取一组几何或图像特征,而Su和Lu [33]将单词图像转换为连续的HOG特征。预处理步骤独立于pipeline中的后续组件,因此基于RNN的现有系统不能以端到端的方式进行训练和优化。
几种不基于神经网络的传统场景文本识别方法也为该领域带来了令人瞩目表现。例如,Almazàn等人。 [5]和Rodriguez-Serrano等人 [30]提出将单词图像和文本字符串嵌入到共同的矢量子空间中,并将单词识别转换为检索问题。姚等人 [36]和戈多等人 [14]使用中级特征进行场景文本识别。虽然在标准基准测试中取得了很好的表现,但这些方法通常优于以前的基于神经网络的算法[8,22]。
本文的主要贡献是一种新颖的神经网络模型,其网络结构专门用于识别图像中的序列式对象。所提出的神经网络模型被称为卷积递归神经网络(CRNN),因为它是DCNN和RNN的组合。对于序列式象,CRNN具有优于传统神经网络模型的几个独特优势:1)它可以直接从序列标签(例如,单词)中学习,不需要详细的注释(例如,字符);2)DCNN具有直接从图像数据学习信息表示的相同属性,既不需要手工工艺特征也不需要预处理步骤,包括二值化/分割,组件定位等。3)它具有相同的RNN特性,能够产生一系列标签;4)它不受序列状物体长度的限制,只需要在训练和测试阶段进行高度归一化;5)它比现有技术[23,8]在场景文本(文字识别)上获得更好或更具竞争力的表现;6)它包含的参数比标准DCNN模型少得多,占用的存储空间更少。
2. The Proposed Network Architecture
如图1所示,CRNN的网络结构由三个部分组成,包括卷积层,循环层和转录层,来自从下到上。
在CRNN的底部,卷积层自动从每个输入图像中提取特征序列。在卷积网络之上,建立循环网络,用于对由卷积层输出的特征序列的每个帧进行预测。采用CRNN顶部的transcription将recurrent层的每帧预测转换为标签序列。虽然CRNN由不同类型的网络架构(例如CNN和RNN)组成,但它可以通过一个损失函数联合训练。
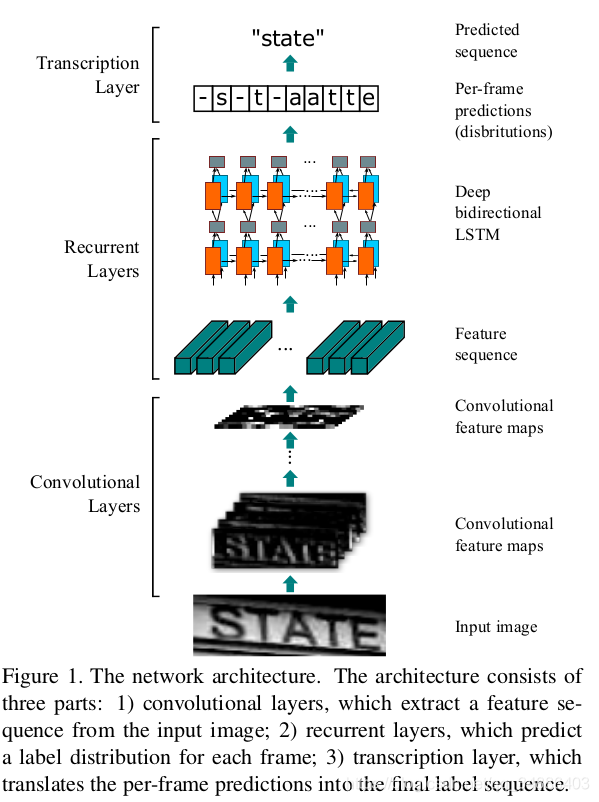
2.1. Feature Sequence Extraction
在CRNN模型中,卷积层的分量是通过从标准CNN模型中取出卷积和最大池层来构建的(完全连接的层被移除)。这种组件用于从输入图像中提取顺序特征表示。在进入网络之前,所有图像都需要缩放到相同的高度。 然后,从卷积层分量产生的特征映射中提取一系列特征向量,这是rnn的输入。具体地,特征序列的每个特征向量在特征图上按列从左到右生成。这意味着第i个特征向量是所有映射的第i列的串联。 我们设置中每列的宽度固定为单个像素。
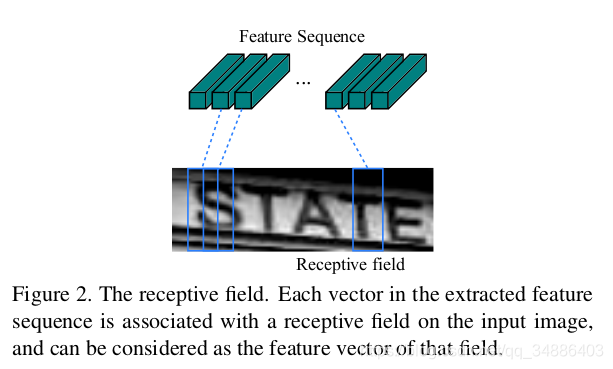
由于卷积层,最大池和元素激活函数在局部区域上运行,它们是平移不变的。因此,每列特征图对应于原始图像的矩形区域(称为感受野),并且这样的矩形区域与从左到右的特征图上的对应列的顺序相同。如图2所示,特征序列中的每个矢量与感受野相关联,并且可以被认为是该区域的图像描述符。
 由于强大,丰富和可训练,深度卷积特征已被广泛用于不同类型的视觉识别任务[25,12]。一些先前的方法已经采用CNN来学习类似序列的对象的强大表示,例如场景文本[22]。然而,这些方法通常通过CNN提取整个图像的整体表示,然后收集局部深度特征以识别类序列对象的每个分量。由于CNN要求将输入图像缩放到固定大小以满足其固定输入维度,因此由于它们的长度变化大而不适合于类序列对象。在CRNN中,我们将深度特征传递到顺序表示中,以便对类序列对象的长度变化保持不变。
由于强大,丰富和可训练,深度卷积特征已被广泛用于不同类型的视觉识别任务[25,12]。一些先前的方法已经采用CNN来学习类似序列的对象的强大表示,例如场景文本[22]。然而,这些方法通常通过CNN提取整个图像的整体表示,然后收集局部深度特征以识别类序列对象的每个分量。由于CNN要求将输入图像缩放到固定大小以满足其固定输入维度,因此由于它们的长度变化大而不适合于类序列对象。在CRNN中,我们将深度特征传递到顺序表示中,以便对类序列对象的长度变化保持不变。
2.2. Sequence Labeling
深度双向递归神经网络建立在卷积层的顶部,作为循环层。循环层对每个 x t x_t xt预测一个label y t y_t yt</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3296
3296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









