







目录
论文解读
这是一篇2015年的iccv,论文地址:https://arxiv.org/abs/1504.06852
摘要
卷积神经网络虽然在计算机视觉的各项任务中取得成功,但是光流计算还没有在其中。这篇paper,我们提出了一种能够解决光流计算问题的模型,采用监督学习。我们提出了并且比较了两种模型:一种是generic的,称为FlowNet-S,另一种加入了corelation layer的FlowNet-C,另外还做了足够大的数据集 Flying Chairs 来支持训练。最后结果在一些已有的数据集测试,效果不错,有5-10的fps。
网络结构
先看第一种,FlowNet-S (FlowNet Simple)

注意输入的数据的channel为6,是由相邻的两帧图像在channel维度上concat形成的。之后就是传统的方式了,一层一层的卷积。不过大家肯定也注意到了灰色的箭头通向绿色的refinement,而那个refinement的形状是个径口增大的圆台。
那么可能有人猜到了,灰色箭头是把对应的卷积特征送到refinement部分,另外从形状上看,refinement是有反卷积操作的。
再看看Flownet-C的结构。
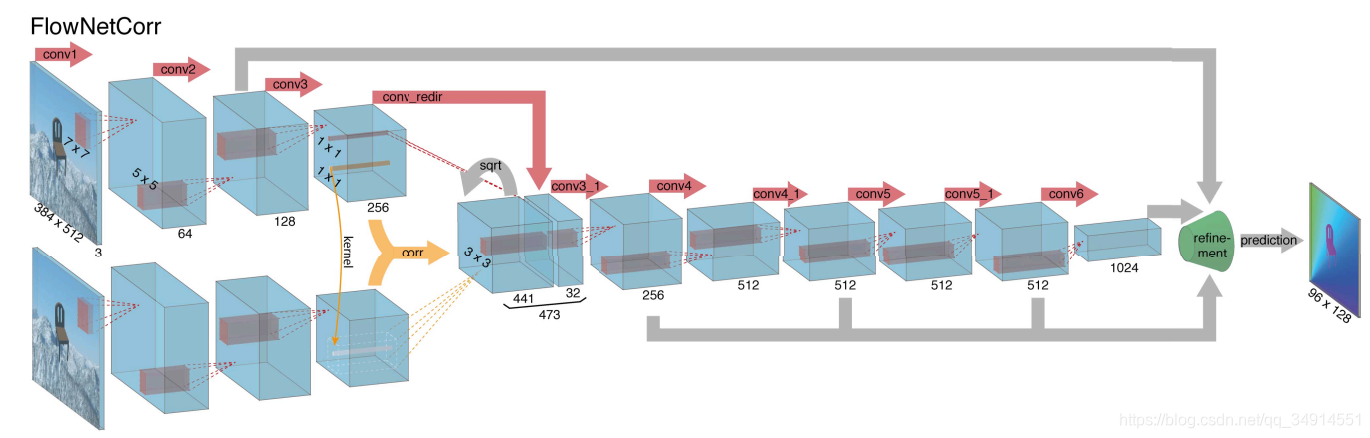
这里的输入有两条线路,前后相邻的两帧分别送入模型。在经过三个卷积层之后,得到高级特征(high -level),计算出相关性的特征图表示,再把他们拼在一起。这里面有几点值得注意。
黄色部分就是前面提到的correlation layer,黄色箭头代表了一种计算相关联性的操作。按照原文的说法,两张图像送进网络分别得到两个特征图f1,f2, 以每一个位置为中心,上下左右都距离k个单位,构造一个patch,patch的大小为K=2k+1,设来自f1的patch的中心为x1, 来自f2的patch的1中心为x2。计算这两个patch的相关性的办法是:
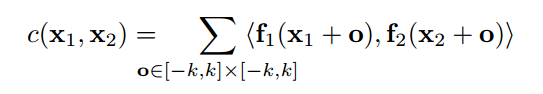
其实就是两个patch的卷积操作,获得了一个值。因为是数据和数据的卷积,所以这里没有训练参数。
但是一个patch中有K*K个值,patch之间的卷积就有K*K*C次乘法运算。如果要计算所有patch的卷积运算,乘法有W*W*H*H*K*K*C次。非常大且不好反向求导。所以设置了一个最大的displacement=D=2*d+1,还有在高度和宽度方向移动的步长s1,s2,用来减少计算量。记以x1为中心的patch1对应在另一个特征图f2中对应的位置为X_wise,那么patch1仅仅和f2中以距离X_wise d个单位长度的点为中心的patch卷积。换言之,可以用以下伪代码解释:
for i in range(x_wise-d,x_wise+d+1):
for j in range(x_wise-d,x_wise+d+1):
patch2=get_patch(f2,i,j)
value=calculate_corr(patch1,patch2)那么得到的结果就是?*?*D^2 的。?指的是未知的特征图尺寸,取决于d的大小。
这里我就有疑惑了,为啥输出特征图的channel为D*D。我看了论文没明白,我就去看了很多博主的文章,他们也是对原文的翻译,并没有去思考如果这一部分要用程序写出来,究竟是个啥过程。于是我就去github搜源码,当然我找的是tf源码,只找到了flowNet-S的源码。作者提供的是caffe,但是我不懂caffe。哈哈。以后如果知道这个corr layer到底怎么工作的,我会重新加上。
另外一个值得注意的地方是 黄色箭头后面有个sqrt的灰色箭头,论文没有对这个操作的任何解释。
以上就是两个网络的第一部分,第二部分是个上采样的过程。即把特征图放大。这两个模型的refinement部分是一致的。
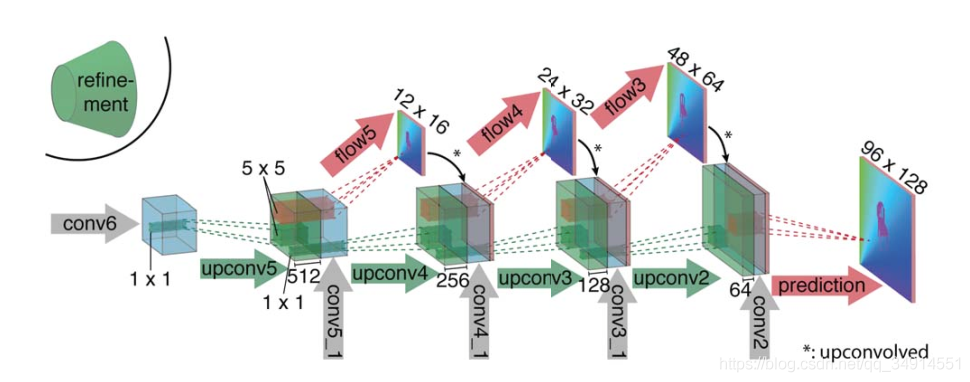
这一部分是很好理解的。conv6得到的特征图反卷积得到绿色的特征图,再把conv5_1得到的特征图拼接上去,接着注意到红色箭头,这是个卷积操作,卷积核为1x1(论文中提到,源码上这个flow箭头的卷及操作所用的核是1x1),作为对光流信息的预测。这个预测又指向特征图的最后一部分,注意到那个箭头有个*号,意思是进行一次反卷积,这样尺寸才能匹配的上嘛。论文种这么说,这样做的目的是:

虽然反卷积放大了特征图,但最后得到的结果尺寸仍然不够原图大小,差4倍,(因为反卷积次数没有卷积次数多嘛),可以label是和原图尺寸一样的,论文中提到,即便多加两个反卷积操作,对效果提升不大,所以直接采用双线性插值放小label。这一点从接下来的源码解读中可以看出。
数据集
训练模型的数据集不是一个真实的数据集(unrealistic),因为现有的数据集都不够大,于是作者做了一个叫Flying chairs的数据集。作者从Flick中取出964张图片,每张图片分为4块作为背景,每块大小为512x384;又从一个3d chair model数据集中取出不相似的809张椅子,呈现出62种的不同视角。
为了生成运动,我们随机抽取背景和椅子的二维仿射变换参数。椅子的变换是相对于背景变换的,背景变换可以解释为摄像机和运动的物体。利用变换参数生成第二幅图像,即地面真光流和遮挡区域。使用这些变换参数,可以生成下一帧的图像、光流label、和遮挡区域。
每一个图像对(image pair):椅子数目,类型,尺寸,初始位置。最后生成了22872 个 image pairs。
另外训练的时候加入了数据增强,都是常规的操作,而且可以在下面的源码中看到。
实验结果

为了验证模型是否受益于自己做的Flying chairs数据集,作者还仅仅在Sintel上做训练,发现效果也可以。
作者发现flownet-c在Sintel-final的测试比flowNet-s上差,在Flying Chairs上比flowNet-s好,说明flownet-c过拟合了。但是作者认为,因为Sintel Final里面有运动模糊或者雾,这些因素没有在Flying chairs中,所以仅仅说明FlowNet-c更加适应不带这两个因素的样本。因此如果用情况更加丰富的样本,性能结果可能会更加好。(所以在flownet2.0中作者又做了更加复杂的Flying Things)
TensorFlow源码解读
我所用的源码地址:https://github.com/studian/flownetS_tensorflow
这个工程主要的代码存放在{root}/src/flownetS中,训练过程中所涉及的文件有三个:
flownet_s.py flownet_train_on_gpu.py flownet_input.py
第一个文件是网络模型,只有flownet_S的模型代码,第三个是导入数据。我们来仅仅来下前两个代码的关键的地方。
flownet_s.py
def loss(logits, flos):
x = logits[0]
y = tf.image.resize_images(flos, get_size(x))
flow6_loss = tf.scalar_mul(0.32, tf.reduce_mean(compute_euclidean_distance(x,y)))
x = logits[1]
y = tf.image.resize_images(flos, get_size(x))
flow5_loss = tf.scalar_mul(0.08, tf.reduce_mean(compute_euclidean_distance(x,y)))
x = logits[2]
y = tf.image.resize_images(flos, get_size(x))
flow4_loss = tf.scalar_mul(0.02, tf.reduce_mean(compute_euclidean_distance(x,y)))
x = logits[3]
y = tf.image.resize_images(flos, get_size(x))
flow3_loss = tf.scalar_mul(0.01, tf.reduce_mean(compute_euclidean_distance(x,y)))
x = logits[4]
y = tf.image.resize_images(flos, get_size(x))
flow2_loss = tf.scalar_mul(0.005, tf.reduce_mean(compute_euclidean_distance(x,y)))
tf.add_to_collection('losses', tf.add_n([flow6_loss, flow5_loss, flow4_loss, flow3_loss, flow2_loss]))
return tf.add_n(tf.get_collection('losses'), name='total_loss')这个函数是用来计算损失的。输入的logits是个列表,里面有四个元素,分别是第一部分网络结构refinement中flow箭头的那四个输出。flos是label,shape是[batch_size,height,width,channels],channels为2。loss是square loss。每个flow计算出的损失函数都要乘上一个标量,为啥呢?
首先排出weight balance(样本类别不均衡时采用),论文中没提到,我猜是希望模型更加看重高级特征(high level information),所以这些损失的权重值是递减的。
模型的infernece部分实在是太常规了,只要懂tf的人肯定能看得懂。这里就不再说了。
flownet_train_on_gpu.py
学习率的设置比较新颖
boundaries = [400000, 600000, 800000, 1000000]
values = [0.0001, 0.00005, 0.000025, 0.0000125, 0.00000625]#Sl
learning_rate = tf.train.piecewise_constant(global_step, boundaries, values)代表这学习率在40w, 60w, 80w 100w变化成对应的value中的值。另外一种可以使用指数衰减,不过要计算decay-step。
tower_grads = []
with tf.variable_scope(tf.get_variable_scope()):
for i in xrange(FLAGS.num_gpus):
with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (flowNet.TOWER_NAME, i)) as scope:
# Calculate the loss for one tower of the model. This function
# constructs the entire CIFAR model but shares the variables across
# all towers.
loss = tower_loss(scope)
# Reuse variables for the next tower.
tf.get_variable_scope().reuse_variables()
# Retain the summaries from the final tower.
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
# Calculate the gradients for the batch of data on this tower.
grads = opt.compute_gradients(loss,var_list=tf.trainable_variables())
# Keep track of the gradients across all towers.
tower_grads.append(grads)代码采用分布式设计,for循环遍历单个gpu,tower-loss里面有inference和计算los部分,因为是分布氏,所以梯度采用平均梯度。一般来说我们是用不到的。这里不做解释。














 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









