







tf.gather
gather是很有用的函数,它可以按照指定轴(axis),把tensor的子集提取出来。这在NMS中特别有用。下面我们看一个例子。
import tensorflow as tf
import numpy as np
aa = np.diag([1,2,3,4])
print('aa is ',aa)
a = tf.convert_to_tensor(aa)
index = tf.constant([3,2,1,0])
b = tf.gather(a,index,axis=0) # by default axis=0
with tf.Session() as sess:
print(sess.run(b))这里我们使用numpy建了一个对角矩阵aa:
aa is
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]然后gather的axis指定为0,意思就是从第一个维度抽取子集,如何抽取,根据index给的顺序。
index的值为[3,2,1,0],意思就是先把在第一个维度中排在第4位(3+1)的子集拿出来,放在新的tensor里面,排在第一位。
再把a里面排在第3位(2+1)的子集拿出来放在上一个拿出来的tensor的后面,以此类推。
好好观察,即可发现,这个函数的作用不仅仅是拿出我们需要的子集,如果index的长度和指定的axis的维度一样长,还具有重新排序的效果。
tf.reduce_prod
这个函数有一个reduce字眼,说明是有降维的作用的。看一个例子就知道是做啥的。prod往往意味着product(相乘),
import tensorflow as tf
import numpy as np
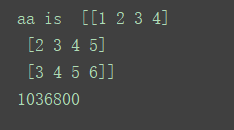
aa = np.array([[1,2,3,4],
[2,3,4,5],
[3,4,5,6]])
print('aa is ',aa)
a = tf.convert_to_tensor(aa)
b = tf.reduce_prod(a) # by default axis=None
with tf.Session() as sess:
print(sess.run(b))输出是:
注意,如果tf.reducea_prod的axis选用默认值None,也则会在全局上,也就是整个tensor上所有元素求积。
现在我们指定axis为1 (-1)试试
b = tf.reduce_prod(a,axis=1) # by default axis=None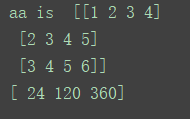
结果就是在第二维度上,整个求积。tensor的shape变化为(3x4)->(3,),大家也可以自行验证axis为0该是输出什么?
tf.boolean_mask
这个函数就更加有用了!在numpy中,我们在一个矩阵中寻找满足某一条件的值得位置的时候,我们可以使用np.where,一种更加有效的方式是:
index = [a==condition]
a[index] = xxxxxx但是tenorflow是不支持这种操作的,因为tensor类型的向量不能作为index。tensor类型的标量是可以的,(文档里面确实提到了)见下面这个错误提示:
TypeError: Only integers, slices (`:`), ellipsis (`...`),
tf.newaxis (`None`) and scalar tf.int32/tf.int64 tensors are valid indices,
got <tf.Tensor 'Const_1:0' shape=(1,) dtype=int32>但是tensorflow提供了tf.boolean_mask来帮助我们实现这种操作。见下面一个例子:
import tensorflow as tf
import numpy as np
aa = np.array([[1,2,3,4],
[2,3,4,5],
[3,4,5,6]])
a = tf.convert_to_tensor(aa)
index = a >= 3
b = tf.boolean_mask(a,index)
with tf.Session() as sess:
print(sess.run(index))
print(sess.run(b))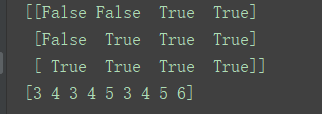
这样就把对应为True的元素提取出来了。注意这个函数也是有axis的,我们可以指定它,这时候,index就必须是向量不能是矩阵了。见下面的例子。
import tensorflow as tf
import numpy as np
aa = np.array([[1,2,3,4],
[2,3,4,5],
[3,4,5,6]])
a = tf.convert_to_tensor(aa)
index = tf.constant([False,True,False],tf.bool)
b = tf.boolean_mask(a,index,axis=0)
with tf.Session() as sess:
print(sess.run(index))
print(sess.run(b))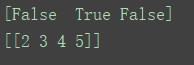
也就是只把为True对应的子集抽取出来,并且没有降低tensor的维度。注意上面是有两对[][]的
tf.logical_or
逻辑或,用法十分简单,保证参数的形状相同即可。四种逻辑运算都是以tf.logical_开头。省略
tf.diag_part
这个函数用来抽取方阵的对角线。假设我们现在有这样一个场景,一个分类网络,输出是[Batch_size,classes_num]这样的张量,我们想知道每一个样本对应的最大的index,可以使用tf.argmax,获得一个[Batch_size,]的张量。下面我们想把每一个样本的概率抽取出来,该怎么做呢?看下面的例子。(当然最直接的方法是tf.reduce_max)
import tensorflow as tf
import numpy as np
aa = np.random.randn(10,5)
a = tf.convert_to_tensor(aa)
index = tf.argmax(a,axis=1)
b = tf.gather(a,index,axis=1) # 这里的b是对称矩阵,不行自己可以观察结果
max_value = tf.diag_part(b)
with tf.Session() as sess:
print(sess.run(max_value))
print(np.max(aa,axis=-1))

tf.where
这个函数和np.where很类似,有两种用法:
- tf.where(condition)
- tf.where(condition,x=a,y=b)
先看第一种用法:
import tensorflow as tf
import numpy as np
aa = np.array([[1,2,3,4],
[2,3,4,5],
[3,4,5,6]])
a = tf.convert_to_tensor(aa)
b = tf.where(a>=3)
with tf.Session() as sess:
print(sess.run(b))
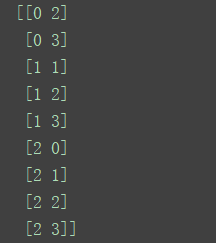
输出的信息中可以发现,双重列表中的每一个元素也是一个列表,这个列表的内容记录了每一个满足condition的元素的位置。比如[0,2],就是说a[0][2]是满足条件的。这个和np.where的输出还有点区别,我记得numpy.where输出的是每一个轴上的index。
再看第二种用法:
import tensorflow as tf
import numpy as np
aa = np.array([[1,2,3,4],
[2,3,4,5],
[3,4,5,6]])
a = tf.convert_to_tensor(aa)
b = tf.where(a>=3,x=a,y=tf.tile([[0]],multiples=[3,4]))
with tf.Session() as sess:
print(sess.run(b))
输出是:
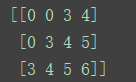
这段代码所要执行的是:如果a>=3的条件满足,则从x中选出对应的值放入新的tensor里面,如果不满足,则从y中选取值放到新tensor对应的位置中。所以x,y的shape必须一致,我这里用了tf.tile生成(3,4)的全0阵。
tf.scatter_nd
这个我还没看懂,暂时记下














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









