




来源:http://www.yiibai.com/scala/scala_arrays.html
Scala中提供了一种数据结构-数组,其中存储相同类型的元素的固定大小的连续集合。数组用于存储数据的集合,但它往往是更加有用认为数组作为相同类型的变量的集合。
取替声明单个变量,如number0, number1, ..., 和number99,声明一个数组变量,如号码和使用numbers[0],numbers[1],...,numbers[99]表示单个变量。本教程介绍了如何声明数组变量,创建数组和使用索引的过程变量数组。数组的第一个元素的索引是数字0和最后一个元素的索引为元素的总数减去1。
声明数组变量:
要使用的程序的数组,必须声明一个变量来引用数组,必须指定数组变量可以引用的类型。下面是语法声明数组变量:
var z:Array[String] = new Array[String](3) or var z = new Array[String](3)
在这里,z被声明为字符串数组,最多可容纳三个元素。可以将值分配给独立的元素或可以访问单个元素,这是可以做到通过使用类似于以下命令:
z(0) = "Zara"; z(1) = "Nuha"; z(4/2) = "Ayan"
在这里,最后一个例子表明,在一般的索引可以是产生一个全数字的表达式。定义数组还有另一种方式:
var z = Array("Zara", "Nuha", "Ayan")
下图展示了数组myList。在这里,myList中拥有10个double值,索引是从0到9。

处理数组:
当要处理数组元素,我们经常使用循环,因为所有的数组中的元素具有相同的类型,并且数组的大小是已知的。这里是展示如何创建,初始化和处理数组的完整的例子:
object Test { def main(args: Array[String]) { var myList = Array(1.9, 2.9, 3.4, 3.5) // Print all the array elements for ( x <- myList ) { println( x ) } // Summing all elements var total = 0.0; for ( i <- 0 to (myList.length - 1)) { total += myList(i); } println("Total is " + total); // Finding the largest element var max = myList(0); for ( i <- 1 to (myList.length - 1) ) { if (myList(i) > max) max = myList(i); } println("Max is " + max); } }
让我们编译和运行上面的程序,这将产生以下结果:
C:/>scalac Test.scala C:/>scala Test 1.9 2.9 3.4 3.5 Total is 11.7 Max is 3.5 C:/>
多维数组:
有很多情况下,需要定义和使用多维数组(即数组的元素数组)。例如,矩阵和表格结构的实例可以实现为二维数组。
Scala不直接支持多维数组,并提供各种方法来处理任何尺寸数组。以下是定义的二维数组的实例:
var myMatrix = ofDim[Int](3,3)
这是一个具有每个都是整数,它有三个元素数组3元素的数组。下面的代码展示了如何处理多维数组:
import Array._ object Test { def main(args: Array[String]) { var myMatrix = ofDim[Int](3,3) // build a matrix for (i <- 0 to 2) { for ( j <- 0 to 2) { myMatrix(i)(j) = j; } } // Print two dimensional array for (i <- 0 to 2) { for ( j <- 0 to 2) { print(" " + myMatrix(i)(j)); } println(); } } }
让我们编译和运行上面的程序,这将产生以下结果:
C:/>scalac Test.scala C:/>scala Test 0 1 2 0 1 2 0 1 2 C:/>
联接数组:
以下是使用concat()方法来连接两个数组的例子。可以通过多个阵列作为参数传递给concat()方法。
import Array._ object Test { def main(args: Array[String]) { var myList1 = Array(1.9, 2.9, 3.4, 3.5) var myList2 = Array(8.9, 7.9, 0.4, 1.5) var myList3 = concat( myList1, myList2) // Print all the array elements for ( x <- myList3 ) { println( x ) } } }
让我们编译和运行上面的程序,这将产生以下结果:
C:/>scalac Test.scala C:/>scala Test 1.9 2.9 3.4 3.5 8.9 7.9 0.4 1.5 C:/>
创建具有范围数组:
下面是示例,这使得使用range() 方法来产生包含在给定的范围内增加整数序列的数组。可以使用最后一个参数创建序列; 如果不使用最后一个参数,然后一步将被假定为1。
import Array._ object Test { def main(args: Array[String]) { var myList1 = range(10, 20, 2) var myList2 = range(10,20) // Print all the array elements for ( x <- myList1 ) { print( " " + x ) } println() for ( x <- myList2 ) { print( " " + x ) } } }
C:/>scalac Test.scala C:/>scala Test 10 12 14 16 18 10 11 12 13 14 15 16 17 18 19 C:/>
Scala中数组方法:
以下是重要的方法,可以同时使用数组。如上所示,则必须使用任何提及的方法之前,要导入Array._包。有关可用方法的完整列表,请Scala中的官方文件。
| SN | 方法及描述 |
|---|---|
| 1 | def apply( x: T, xs: T* ): Array[T] 创建T对象,其中T可以是Unit, Double, Float, Long, Int, Char, Short, Byte, Boolean数组。 |
| 2 | def concat[T]( xss: Array[T]* ): Array[T] 连接所有阵列成一个数组。 |
| 3 | def copy( src: AnyRef, srcPos: Int, dest: AnyRef, destPos: Int, length: Int ): Unit 复制一个数组到另一个。相当于Java的System.arraycopy(src, srcPos, dest, destPos, length). |
| 4 | def empty[T]: Array[T] 返回长度为0的数组 |
| 5 | def iterate[T]( start: T, len: Int )( f: (T) => T ): Array[T] 返回一个包含一个函数的重复应用到初始值的数组。 |
| 6 | def fill[T]( n: Int )(elem: => T): Array[T] 返回包含某些元素的计算的结果的次数的数组。 |
| 7 | def fill[T]( n1: Int, n2: Int )( elem: => T ): Array[Array[T]] 返回一个二维数组,其中包含某些元素的计算的结果的次数。 |
| 8 | def iterate[T]( start: T, len: Int)( f: (T) => T ): Array[T] 返回一个包含一个函数的重复应用到初始值的数组。 |
| 9 | def ofDim[T]( n1: Int ): Array[T] 创建数组给出的尺寸。 |
| 10 | def ofDim[T]( n1: Int, n2: Int ): Array[Array[T]] 创建了一个2维数组 |
| 11 | def ofDim[T]( n1: Int, n2: Int, n3: Int ): Array[Array[Array[T]]] 创建3维数组 |
| 12 | def range( start: Int, end: Int, step: Int ): Array[Int] 返回包含一些整数间隔等间隔值的数组。 |
| 13 | def range( start: Int, end: Int ): Array[Int] 返回包含的范围内增加整数序列的数组。 |
| 14 | def tabulate[T]( n: Int )(f: (Int)=> T): Array[T] 返回包含一个给定的函数的值超过从0开始的范围内的整数值的数组。 |
| 15 | def tabulate[T]( n1: Int, n2: Int )( f: (Int, Int ) => T): Array[Array[T]] 返回一个包含给定函数的值超过整数值从0开始范围的二维数组。 |
数组是一种可变的、可索引的数据集合。在Scala中用Array[T]的形式来表示Java中的数组形式 T[]。
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
Scala提供了大量的集合操作:
- def ++[B](that: GenTraversableOnce[B]): Array[B]
合并集合,并返回一个新的数组,新数组包含左右两个集合对象的内容。
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- def ++:[B >: A, That](that: collection.Traversable[B])(implicit bf: CanBuildFrom[Array[T], B, That]): That
这个方法同上一个方法类似,两个加号后面多了一个冒号,但是不同的是右边操纵数的类型决定着返回结果的类型。下面代码中List和LinkedList结合,返回结果是LinkedList类型
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- def +:(elem: A): Array[A]
在数组前面添加一个元素,并返回新的对象,下面添加一个元素 0
- 1
- 2
- 1
- 2
-
def :+(elem: A): Array[A]
同上面的方法想法,在数组末尾添加一个元素,并返回新对象 -
def /:[B](z: B)(op: (B, T) ⇒ B): B
对数组中所有的元素进行相同的操作 ,foldLeft的简写
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
-
def :\[B](z: B)(op: (T, B) ⇒ B): B
foldRight的简写 -
def addString(b: StringBuilder): StringBuilder
将数组中的元素逐个添加到b中
- 1
- 2
- 3
- 1
- 2
- 3
- def addString(b: StringBuilder, sep: String): StringBuilder
同上,每个元素用sep分隔符分开
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- def addString(b: StringBuilder, start: String, sep: String, end: String): StringBuilder
同上,在首尾各加一个字符串,并指定sep分隔符
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- def aggregate[B](z: ⇒ B)(seqop: (B, T) ⇒ B, combop: (B, B) ⇒ B): B
聚合计算,aggregate是柯里化方法,参数是两个方法,为了方便理解,我们把aggregate的两个参数,分别封装成两个方法,并把计算过程打印出来。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
上面过程可以简写为
- 1
- 1
- def apply(i: Int): T
同下面代码,取出指定索引处的元素
- 1
- 1
-
def canEqual(that: Any): Boolean
判断两个对象是否可以进行比较 -
def charAt(index: Int): Char
获取index索引处的字符,这个方法会执行一个隐式的转换,将Array[T]转换为 ArrayCharSequence,只有当T为char类型时,这个转换才会发生。
- 1
- 2
- 1
- 2
- def clone(): Array[T]
创建一个副本
- 1
- 2
- 3
- 1
- 2
- 3
- def collect[B](pf: PartialFunction[A, B]): Array[B]
通过执行一个并行计算(偏函数),得到一个新的数组对象
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- def collectFirst[B](pf: PartialFunction[T, B]): Option[B]
在序列中查找第一个符合偏函数定义的元素,并执行偏函数计算
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- def combinations(n: Int): collection.Iterator[Array[T]]
排列组合,这个排列组合会选出所有包含字符不一样的组合,对于 “abc”、“cba”,只选择一个,参数n表示序列长度,就是几个字符为一组
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
def contains[A1 >: A](elem: A1): Boolean
序列中是否包含指定对象 -
def containsSlice[B](that: GenSeq[B]): Boolean
判断当前序列中是否包含另一个序列
- 1
- 2
- 3
- 1
- 2
- 3
- def copyToArray(xs: Array[A]): Unit
此方法还有两个类似的方法
copyToArray(xs: Array[A], start: Int): Unit
copyToArray(xs: Array[A], start: Int, len: Int): Unit
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
- def copyToBuffer[B >: A](dest: Buffer[B]): Unit
将数组中的内容拷贝到Buffer中
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- def corresponds[B](that: GenSeq[B])(p: (T, B) ⇒ Boolean): Boolean
判断两个序列长度以及对应位置元素是否符合某个条件。如果两个序列具有相同的元素数量并且p(x, y)=true,返回结果为true
下面代码检查a和b长度是否相等,并且a中元素是否小于b中对应位置的元素
- 1
- 2
- 3
- 1
- 2
- 3
- def count(p: (T) ⇒ Boolean): Int
统计符合条件的元素个数,下面统计大于 2 的元素个数
- 1
- 2
- 1
- 2
- def diff(that: collection.Seq[T]): Array[T]
计算当前数组与另一个数组的不同。将当前数组中没有在另一个数组中出现的元素返回
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- def distinct: Array[T]
去除当前集合中重复的元素,只保留一个
- 1
- 2
- 3
- 1
- 2
- 3
- def drop(n: Int): Array[T]
将当前序列中前 n 个元素去除后,作为一个新序列返回
- 1
- 2
- 3
- 1
- 2
- 3
- def dropRight(n: Int): Array[T]
-
功能同 drop,去掉尾部的 n 个元素
-
def dropWhile(p: (T) ⇒ Boolean): Array[T]
去除当前数组中符合条件的元素,这个需要一个条件,就是从当前数组的第一个元素起,就要满足条件,直到碰到第一个不满足条件的元素结束(即使后面还有符合条件的元素),否则返回整个数组
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- def endsWith[B](that: GenSeq[B]): Boolean
判断是否以某个序列结尾
- 1
- 2
- 3
- 1
- 2
- 3
- def exists(p: (T) ⇒ Boolean): Boolean
判断当前数组是否包含符合条件的元素
- 1
- 2
- 3
- 1
- 2
- 3
- def filter(p: (T) ⇒ Boolean): Array[T]
取得当前数组中符合条件的元素,组成新的数组返回
- 1
- 2
- 3
- 1
- 2
- 3
-
def filterNot(p: (T) ⇒ Boolean): Array[T]
与上面的 filter 作用相反 -
def find(p: (T) ⇒ Boolean): Option[T]
查找第一个符合条件的元素
- 1
- 2
- 3
- 1
- 2
- 3
- def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): Array[B]
对当前序列的每个元素进行操作,结果放入新序列返回,参数要求是GenTraversableOnce及其子类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- def flatten[U](implicit asTrav: (T) ⇒ collection.Traversable[U], m: ClassTag[U]): Array[U]
将二维数组的所有元素联合在一起,形成一个一维数组返回
- 1
- 2
- 3
- 1
- 2
- 3
-def fold[A1 >: A](z: A1)(op: (A1, A1) ⇒ A1): A1
对序列中的每个元素进行二元运算,和aggregate有类似的语义,但执行过程有所不同,我们来对比一下他们的执行过程。
因为aggregate需要两个处理方法,所以我们定义一个combine方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
看上面的运算过程发现,fold中,seqno是把初始值顺序和每个元素相加,把得到的结果与下一个元素进行运算
而aggregate中,seqno是把初始值与每个元素相加,但结果不参与下一步运算,而是放到另一个序列中,由第二个方法combine进行处理
-def foldLeft[B](z: B)(op: (B, T) ⇒ B): B
从左到右计算,简写方式:def /:[B](z: B)(op: (B, T) ⇒ B): B
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-def foldRight[B](z: B)(op: (B, T) ⇒ B): B
从右到左计算,简写方式:def :\[B](z: B)(op: (T, B) ⇒ B): B
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-def forall(p: (T) ⇒ Boolean): Boolean
检测序列中的元素是否都满足条件 p,如果序列为空,返回true
- 1
- 2
- 3
- 1
- 2
- 3
-def foreach(f: (A) ⇒ Unit): Unit
检测序列中的元素是否都满足条件 p,如果序列为空,返回true
- 1
- 2
- 3
- 1
- 2
- 3
-def foreach(f: (A) ⇒ Unit): Unit
遍历序列中的元素,进行 f 操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
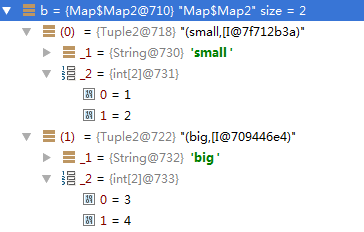
-def groupBy[K](f: (T) ⇒ K): Map[K, Array[T]]
按条件分组,条件由 f 匹配,返回值是Map类型,每个key对应一个序列,下面代码实现的是,把小于3的数字放到一组,大于3的放到一组,返回Map[String,Array[Int]]
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
-def grouped(size: Int): collection.Iterator[Array[T]]
按指定数量分组,每组有 size 数量个元素,返回一个集合
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-def hasDefiniteSize: Boolean
检测序列是否存在有限的长度,对应Stream这样的流数据,返回false
- 1
- 2
- 1
- 2
-def head: T
返回序列的第一个元素,如果序列为空,将引发错误
- 1
- 2
- 1
- 2
-def headOption: Option[T]
返回Option类型对象,就是scala.Some 或者 None,如果序列是空,返回None
- 1
- 2
- 1
- 2
-def indexOf(elem: T): Int
返回elem在序列中的索引,找到第一个就返回
- 1
- 2
- 1
- 2
-def indexOf(elem: T, from: Int): Int
返回elem在序列中的索引,可以指定从某个索引处(from)开始查找,找到第一个就返回
- 1
- 2
- 1
- 2
-def indexOfSlice[B >: A](that: GenSeq[B]): Int
检测当前序列中是否包含另一个序列(that),并返回第一个匹配出现的元素的索引
- 1
- 2
- 3
- 1
- 2
- 3
-def indexOfSlice[B >: A](that: GenSeq[B], from: Int): Int
检测当前序列中是否包含另一个序列(that),并返回第一个匹配出现的元素的索引,指定从 from 索引处开始
- 1
- 2
- 3
- 1
- 2
- 3
-def indexWhere(p: (T) ⇒ Boolean): Int
返回当前序列中第一个满足 p 条件的元素的索引
- 1
- 2
- 1
- 2
-def indexWhere(p: (T) ⇒ Boolean, from: Int): Int
返回当前序列中第一个满足 p 条件的元素的索引,可以指定从 from 索引处开始
- 1
- 2
- 1
- 2
-def indices: collection.immutable.Range
返回当前序列索引集合
- 1
- 2
- 3
- 1
- 2
- 3
-def init: Array[T]
返回当前序列中不包含最后一个元素的序列
- 1
- 2
- 3
- 1
- 2
- 3
-def inits: collection.Iterator[Array[T]]
对集合中的元素进行 init 操作,该操作的返回值中, 第一个值是当前序列的副本,包含当前序列所有的元素,最后一个值是空的,对头尾之间的值进行init操作,上一步的结果作为下一步的操作对象
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-def intersect(that: collection.Seq[T]): Array[T]
取两个集合的交集
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def isDefinedAt(idx: Int): Boolean
判断序列中是否存在指定索引
- 1
- 2
- 3
- 1
- 2
- 3
-def isEmpty: Boolean
判断当前序列是否为空
-def isTraversableAgain: Boolean
判断序列是否可以反复遍历,该方法是GenTraversableOnce中的方法,对于 Traversables 一般返回true,对于 Iterators 返回 false,除非被复写
-def iterator: collection.Iterator[T]
对序列中的每个元素产生一个 iterator
- 1
- 2
- 1
- 2
-def last: T
取得序列中最后一个元素
- 1
- 2
- 1
- 2
-def lastIndexOf(elem: T): Int
取得序列中最后一个等于 elem 的元素的位置
- 1
- 2
- 1
- 2
-def lastIndexOf(elem: T, end: Int): Int
取得序列中最后一个等于 elem 的元素的位置,可以指定在 end 之前(包括)的元素中查找
- 1
- 2
- 1
- 2
-def lastIndexOfSlice[B >: A](that: GenSeq[B]): Int
判断当前序列中是否包含序列 that,并返回最后一次出现该序列的位置处的索引
- 1
- 2
- 3
- 1
- 2
- 3
-def lastIndexOfSlice[B >: A](that: GenSeq[B], end: Int): Int
判断当前序列中是否包含序列 that,并返回最后一次出现该序列的位置处的索引,可以指定在 end 之前(包括)的元素中查找
- 1
- 2
- 3
- 1
- 2
- 3
-def lastIndexWhere(p: (T) ⇒ Boolean): Int
返回当前序列中最后一个满足条件 p 的元素的索引
- 1
- 2
- 3
- 1
- 2
- 3
-def lastIndexWhere(p: (T) ⇒ Boolean, end: Int): Int
返回当前序列中最后一个满足条件 p 的元素的索引,可以指定在 end 之前(包括)的元素中查找
- 1
- 2
- 3
- 1
- 2
- 3
-def lastOption: Option[T]
返回当前序列中最后一个对象
- 1
- 2
- 1
- 2
-def length: Int
返回当前序列中元素个数
- 1
- 2
- 1
- 2
-def lengthCompare(len: Int): Int
比较序列的长度和参数 len,根据二者的关系返回不同的值,比较规则是
- 1
- 2
- 3
- 1
- 2
- 3
-def map[B](f: (A) ⇒ B): Array[B]
对序列中的元素进行 f 操作
- 1
- 2
- 3
- 1
- 2
- 3
-def max: A
返回序列中最大的元素
- 1
- 2
- 1
- 2
-def minBy[B](f: (A) ⇒ B): A
返回序列中第一个符合条件的最大的元素
- 1
- 2
- 1
- 2
-def mkString: String
将所有元素组合成一个字符串
- 1
- 2
- 1
- 2
-def mkString(sep: String): String
将所有元素组合成一个字符串,以 sep 作为元素间的分隔符
- 1
- 2
- 1
- 2
-def mkString(start: String, sep: String, end: String): String
将所有元素组合成一个字符串,以 start 开头,以 sep 作为元素间的分隔符,以 end 结尾
- 1
- 2
- 1
- 2
-def nonEmpty: Boolean
判断序列不是空
-def padTo(len: Int, elem: A): Array[A]
后补齐序列,如果当前序列长度小于 len,那么新产生的序列长度是 len,多出的几个位值填充 elem,如果当前序列大于等于 len ,则返回当前序列
- 1
- 2
- 3
- 1
- 2
- 3
-def par: ParArray[T]
返回一个并行实现,产生的并行序列,不能被修改
- 1
- 2
- 1
- 2
-def partition(p: (T) ⇒ Boolean): (Array[T], Array[T])
按条件将序列拆分成两个新的序列,满足条件的放到第一个序列中,其余的放到第二个序列,下面以序列元素是否是 2 的倍数来拆分
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def patch(from: Int, that: GenSeq[A], replaced: Int): Array[A]
批量替换,从原序列的 from 处开始,后面的 replaced 数量个元素,将被替换成序列 that
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
-def permutations: collection.Iterator[Array[T]]
排列组合,他与combinations不同的是,组合中的内容可以相同,但是顺序不能相同,combinations不允许包含的内容相同,即使顺序不一样
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def prefixLength(p: (T) ⇒ Boolean): Int
给定一个条件 p,返回一个前置数列的长度,这个数列中的元素都满足 p
- 1
- 2
- 1
- 2
-def product: A
返回所有元素乘积的值
- 1
- 2
- 1
- 2
-def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1
同 fold,不需要初始值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-def reduceLeft[B >: A](op: (B, T) ⇒ B): B
从左向右计算
-def reduceRight[B >: A](op: (T, B) ⇒ B): B
从右向左计算
-def reduceLeftOption[B >: A](op: (B, T) ⇒ B): Option[B]
计算Option,参考reduceLeft
-def reduceRightOption[B >: A](op: (T, B) ⇒ B): Option[B]
计算Option,参考reduceRight
-def reverse: Array[T]
反转序列
- 1
- 2
- 3
- 1
- 2
- 3
-def reverseIterator: collection.Iterator[T]
反向生成迭代
-def reverseMap[B](f: (A) ⇒ B): Array[B]
同 map 方向相反
- 1
- 2
- 3
- 1
- 2
- 3
-def sameElements(that: GenIterable[A]): Boolean
判断两个序列是否顺序和对应位置上的元素都一样
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
-def scan[B >: A, That](z: B)(op: (B, B) ⇒ B)(implicit cbf: CanBuildFrom[Array[T], B, That]): That
用法同 fold,scan会把每一步的计算结果放到一个新的集合中返回,而 fold 返回的是单一的值
- 1
- 2
- 3
- 1
- 2
- 3
-def scanLeft[B, That](z: B)(op: (B, T) ⇒ B)(implicit bf: CanBuildFrom[Array[T], B, That]): That
从左向右计算
-def scanRight[B, That](z: B)(op: (T, B) ⇒ B)(implicit bf: CanBuildFrom[Array[T], B, That]): That
从右向左计算
-def segmentLength(p: (T) ⇒ Boolean, from: Int): Int
从序列的 from 处开始向后查找,所有满足 p 的连续元素的长度
- 1
- 2
- 1
- 2
-def seq: collection.mutable.IndexedSeq[T]
产生一个引用当前序列的 sequential 视图
-def size: Int
序列元素个数,同 length
-def slice(from: Int, until: Int): Array[T]
取出当前序列中,from 到 until 之间的片段
- 1
- 2
- 3
- 1
- 2
- 3
-def sliding(size: Int): collection.Iterator[Array[T]]
从第一个元素开始,每个元素和它后面的 size - 1 个元素组成一个数组,最终组成一个新的集合返回,当剩余元素不够 size 数,则停止
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-def sliding(size: Int, step: Int): collection.Iterator[Array[T]]
从第一个元素开始,每个元素和它后面的 size - 1 个元素组成一个数组,最终组成一个新的集合返回,当剩余元素不够 size 数,则停止
该方法,可以设置步进 step,第一个元素组合完后,下一个从 上一个元素位置+step后的位置处的元素开始
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-def sortBy[B](f: (T) ⇒ B)(implicit ord: math.Ordering[B]): Array[T]
按指定的排序规则排序
- 1
- 2
- 3
- 1
- 2
- 3
-def sortWith(lt: (T, T) ⇒ Boolean): Array[T]
自定义排序方法 lt
- 1
- 2
- 3
- 1
- 2
- 3
-def sorted[B >: A](implicit ord: math.Ordering[B]): Array[T]
使用默认的排序规则对序列排序
- 1
- 2
- 3
- 1
- 2
- 3
-def span(p: (T) ⇒ Boolean): (Array[T], Array[T])
分割序列为两个集合,从第一个元素开始,直到找到第一个不满足条件的元素止,之前的元素放到第一个集合,其它的放到第二个集合
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def splitAt(n: Int): (Array[T], Array[T])
从指定位置开始,把序列拆分成两个集合
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def startsWith[B](that: GenSeq[B], offset: Int): Boolean
从指定偏移处,是否以某个序列开始
- 1
- 2
- 3
- 1
- 2
- 3
-def startsWith[B](that: GenSeq[B]): Boolean
是否以某个序列开始
- 1
- 2
- 3
- 1
- 2
- 3
-def stringPrefix: String
返回 toString 结果的前缀
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def subSequence(start: Int, end: Int): CharSequence
返回 start 和 end 间的字符序列
- 1
- 2
- 3
- 1
- 2
- 3
-def sum: A
序列求和,元素需为Numeric[T]类型
- 1
- 2
- 1
- 2
-def tail: Array[T]
返回除了当前序列第一个元素的其它元素组成的序列
- 1
- 2
- 1
- 2
-def take(n: Int): Array[T]
返回当前序列中前 n 个元素组成的序列
- 1
- 2
- 1
- 2
-def takeRight(n: Int): Array[T]
返回当前序列中,从右边开始,选择 n 个元素组成的序列
- 1
- 2
- 1
- 2
-def takeWhile(p: (T) ⇒ Boolean): Array[T]
返回当前序列中,从第一个元素开始,满足条件的连续元素组成的序列
- 1
- 2
- 1
- 2
-def toArray: Array[A]
转换成 Array 类型
-def toBuffer[A1 >: A]: Buffer[A1]
转换成 Buffer 类型
-def toIndexedSeq: collection.immutable.IndexedSeq[T]
转换成 IndexedSeq 类型
-def toIterable: collection.Iterable[T]
转换成可迭代的类型
-def toIterator: collection.Iterator[T]
同 iterator 方法
-def toList: List[T]
同 List 类型
-def toMap[T, U]: Map[T, U]
同 Map 类型,需要被转化序列中包含的元素时 Tuple2 类型数据
- 1
- 2
- 3
- 1
- 2
- 3
-def toSeq: collection.Seq[T]
同 Seq 类型
-def toSet[B >: A]: Set[B]
同 Set 类型
-def toStream: collection.immutable.Stream[T]
同 Stream 类型
-def toVector: Vector[T]
同 Vector 类型
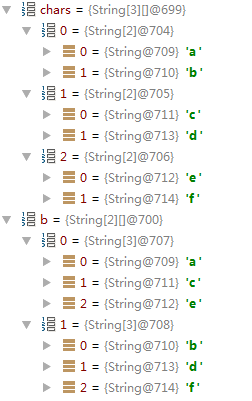
-def transpose[U](implicit asArray: (T) ⇒ Array[U]): Array[Array[U]]
矩阵转换,二维数组行列转换
- 1
- 2
- 3
- 1
- 2
- 3
-def union(that: collection.Seq[T]): Array[T]
联合两个序列,同操作符 ++
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def unzip[T1, T2](implicit asPair: (T) ⇒ (T1, T2), ct1: ClassTag[T1], ct2: ClassTag[T2]): (Array[T1], Array[T2])
将含有两个元素的数组,第一个元素取出组成一个序列,第二个元素组成一个序列
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def unzip3[T1, T2, T3](implicit asTriple: (T) ⇒ (T1, T2, T3), ct1: ClassTag[T1], ct2: ClassTag[T2], ct3: ClassTag[T3]): (Array[T1], Array[T2], Array[T3])
将含有三个元素的三个数组,第一个元素取出组成一个序列,第二个元素组成一个序列,第三个元素组成一个序列
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
-def update(i: Int, x: T): Unit
将序列中 i 索引处的元素更新为 x
- 1
- 2
- 3
- 1
- 2
- 3
-def updated(index: Int, elem: A): Array[A]
将序列中 i 索引处的元素更新为 x ,并返回替换后的数组
- 1
- 2
- 3
- 1
- 2
- 3
-def view(from: Int, until: Int): IndexedSeqView[T, Array[T]]
返回 from 到 until 间的序列,不包括 until 处的元素
- 1
- 2
- 3
- 1
- 2
- 3
-def withFilter(p: (T) ⇒ Boolean): FilterMonadic[T, Array[T]]
根据条件 p 过滤元素
- 1
- 2
- 3
- 1
- 2
- 3
-def zip[B](that: GenIterable[B]): Array[(A, B)]
将两个序列对应位置上的元素组成一个pair序列
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
-def zipAll[B](that: collection.Iterable[B], thisElem: A, thatElem: B): Array[(A, B)]
同 zip ,但是允许两个序列长度不一样,不足的自动填充,如果当前序列端,空出的填充为 thisElem,如果 that 短,填充为 thatElem
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-def zipWithIndex: Array[(A, Int)]
序列中的每个元素和它的索引组成一个序列
- 1
- 2
- 3

















 1497
1497




 到【灌水乐园】发言
到【灌水乐园】发言







