







配置mysql
sudo vi /etc/my.cnf
[mysqld]
log-bin=/var/lib/mysql/mysql-bin #开启日志监控
binlog-format=ROW #监控模式为ROW
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复创建canal用户
添加canal用户,修改权限
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;重启mysql
sudo service mysqld restart查看log_bin
show variables like '%log_bin%';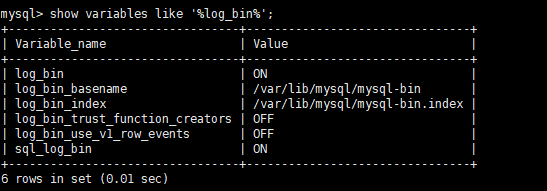
canal安装
下载:
[hdfs@node1 software]$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
解压:
mkdir /opt/module/canal //创建一个目录
tar -zxvf /opt/software/canal.deployer-1.1.4.tar.gz -C /opt/module/canal//解压
修改canal的配置文件
主要修改instance.properties和canal.properties这两个配置文件
下面只展示部分配置信息:
vi /opt/module/canal/conf/example/instance.properties
#################################################
# mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false //是否是GTID模式
# position info
canal.instance.master.address=127.0.0.1:3306 //mysql主库链接地址
canal.instance.master.journal.name= //mysql主库链接时起始的binlog文件
canal.instance.master.position= //mysql主库链接时起始的binlog偏移量
canal.instance.master.timestamp= //mysql主库链接时起始的binlog的时间戳
canal.instance.master.gtid= //gtid的值
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal //mysql数据库帐号
canal.instance.dbPassword=canal //mysql数据库密码
canal.instance.connectionCharset = UTF-8 mysql解析编码
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=canaltest
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
...............................vi /opt/module/canal/conf/canal.properties
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ #############
##################################################
canal.mq.servers = node1:9092,node2:9092,node3:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"
................创建测试表并插入数据
CREATE TABLE Test.users(
id INT(10) PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(256),
create_time BIGINT,
modified_time BIGINT
);
INSERT INTO Test.users VALUES(1,'zhangsan',UNIX_TIMESTAMP(),UNIX_TIMESTAMP());开启canel
/opt/module/canel/bin/startup.sh
查看kakfa topic
/opt/module/kafka_2.11-0.11.0.3/bin/kafka-topics.sh --list --zookeeper node1:2181
canaltest已经创建

消费数据
/opt/module/kafka_2.11-0.11.0.3/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic canaltest --from-beginning
mysql插入新数据
INSERT INTO Test.users VALUES(2,'lisi',UNIX_TIMESTAMP(),UNIX_TIMESTAMP());kafka消费insert数据
{"data":[{"id":"2","name":"lisi","create_time":"1590308068","modified_time":"1590308068"}],"database":"Test","es":1590308068000,"id":9,"isDdl":false,"mysqlType":{"id":"int(10)","name":"varchar(256)","create_time":"bigint","modified_time":"bigint"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":4,"name":12,"create_time":-5,"modified_time":-5},"table":"users","ts":1590308068312,"type":"INSERT"}

mysql修改数据
UPDATE Test.users SET NAME='lisi_1',modified_time=UNIX_TIMESTAMP() WHERE NAME='lisi'kafka消费update数据
{"data":[{"id":"2","name":"lisi_1","create_time":"1590308068","modified_time":"1590308148"}],"database":"Test","es":1590308148000,"id":10,"isDdl":false,"mysqlType":{"id":"int(10)","name":"varchar(256)","create_time":"bigint","modified_time":"bigint"},"old":[{"name":"lisi","modified_time":"1590308068"}],"pkNames":["id"],"sql":"","sqlType":{"id":4,"name":12,"create_time":-5,"modified_time":-5},"table":"users","ts":1590308148207,"type":"UPDATE"}
mysql删除数据
delete from Test.users where name='lisi_1'kafka消费delete数据
{"data":[{"id":"2","name":"lisi_1","create_time":"1590308068","modified_time":"1590308148"}],"database":"Test","es":1590308267000,"id":11,"isDdl":false,"mysqlType":{"id":"int(10)","name":"varchar(256)","create_time":"bigint","modified_time":"bigint"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":4,"name":12,"create_time":-5,"modified_time":-5},"table":"users","ts":1590308267592,"type":"DELETE"}
总结
在生产环境中,用sqoop或者datax将数据从同步到数据仓库中,我们往往通过modified_time,create_time或者主键这些索引这些时间来限制条件,导入T-1天一整天的离线数据。但是实际生产过程中会有一些表会没有这些字段来判断哪些是增量数据,这时候就可以通过读取binlog中的logtime的来获取增量数据。在一些复杂的业务场景,由于服务器压力或者网络延迟的问题往往会导致有些数据写入延迟,会使凌晨12点数据产生数据漂移,及前一天的数据由于写入过慢致使其漂移到后一天,这时候需要同时利用modified_time和binlog 的log_time获取两张表然后全表关联获取当时完整数据。















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









