






摘要:2017云栖大会阿里云大数据计算服务(MaxCompute)专场,阿里云高级专家戴谢宁带来MaxCompute的索引与优化实践分享。本文主要从MaxCompute数据模型开始谈起,接着分享了哈希分片和区域分片,着重分析了索引优化和join优化,并且列出了应用实例,最好作出了简要总结。
以下是精彩内容整理:
MaxCompute 除了是计算引擎之外,它也是个存储引擎,阿里巴巴99%数据都在这个平台上。那么,怎么去优化存储效率,从而提高计算效率是我们一直努力的目标。

MaxCompute的数据模型
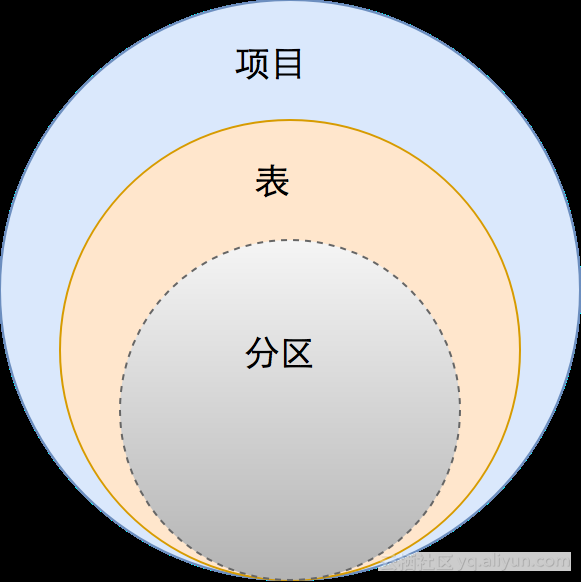
目前MaxCompute的数据模型包括:项目,表,分区。在分区下,分区下没有定义数据组织方式,数据无序存放。
那么,在分区下能否通过定义数据分片、排序和索引提高效率?答案是肯定的。
在MaxCompute2.0中,我们提供了两种切片方式,哈希分片和区域分片。
哈希分片 – Hash Clustering
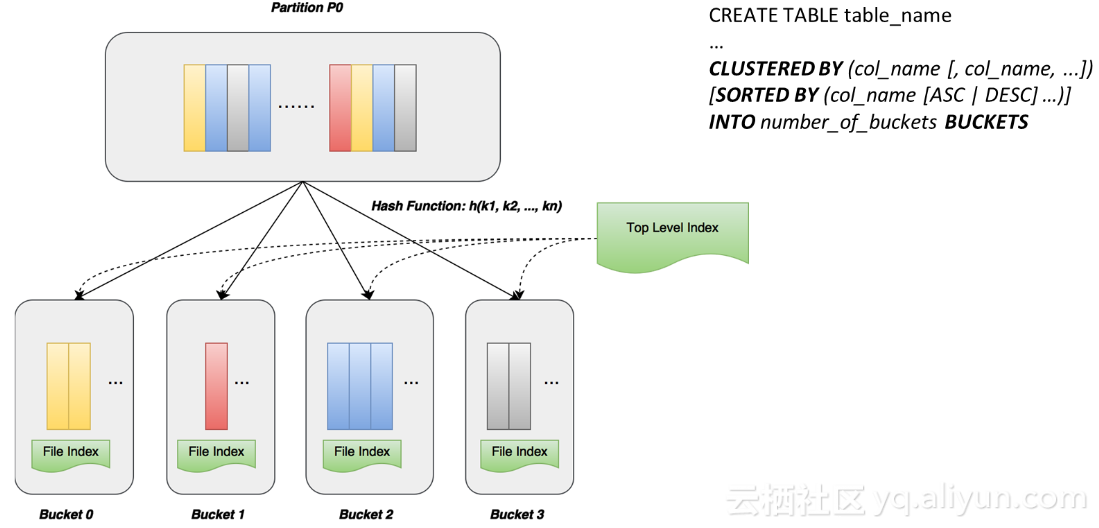
哈希分片是指用户在创建table时,可以指定几个column作键值的链,MaxCompute可以按照这几个column做hash function,将hash value相同的record记录放到同一个分片中去,不同的颜色代表不同的record出来相同的hash值。同时,我们通过语法定义每一个切片数据是不是要有序存放,如果指定sorted by 子句,就会要求数据排序存放。这样就会呈现出两个效果,一是在每个file里建立index,一是在分片以上还有top level index,上层索引信息规定了表有多少个分片、哈希方式是什么、依据哪几个列,这些都可以帮助到我们后面的查询。
区域分片 – Range Clustering
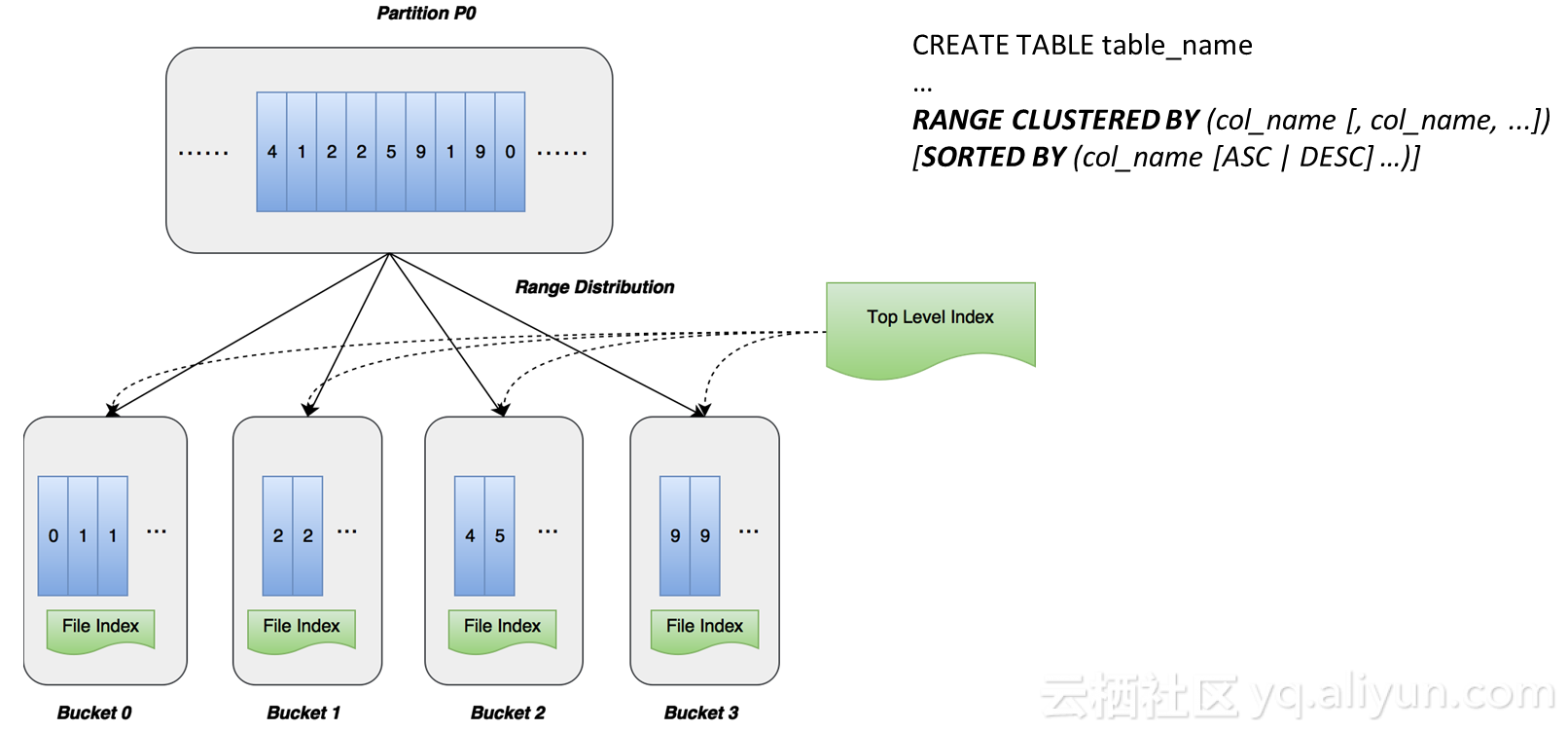
区域分片比哈希分片更加灵活高级,它的基本思想是指定区域分片的column后,语法为range clustered by ,MaxCompute根据column值域分布作全排序,根据值域分布按照合理方式进行切分,切分的原则包括分片大小、分片差异合理化,减少并行处理时遇到的种种数据问题。图中9个record,我们对其进行全排序,把它切到四个片上,同样也有个sorted by 的子句指定每个分片数据如何存放,有序存放会建立两个级别的索引,一是文件级别索引,一是上层索引,上层索引维护了每个分片,每个分片对应某个range和区间。
基于索引的查询优化
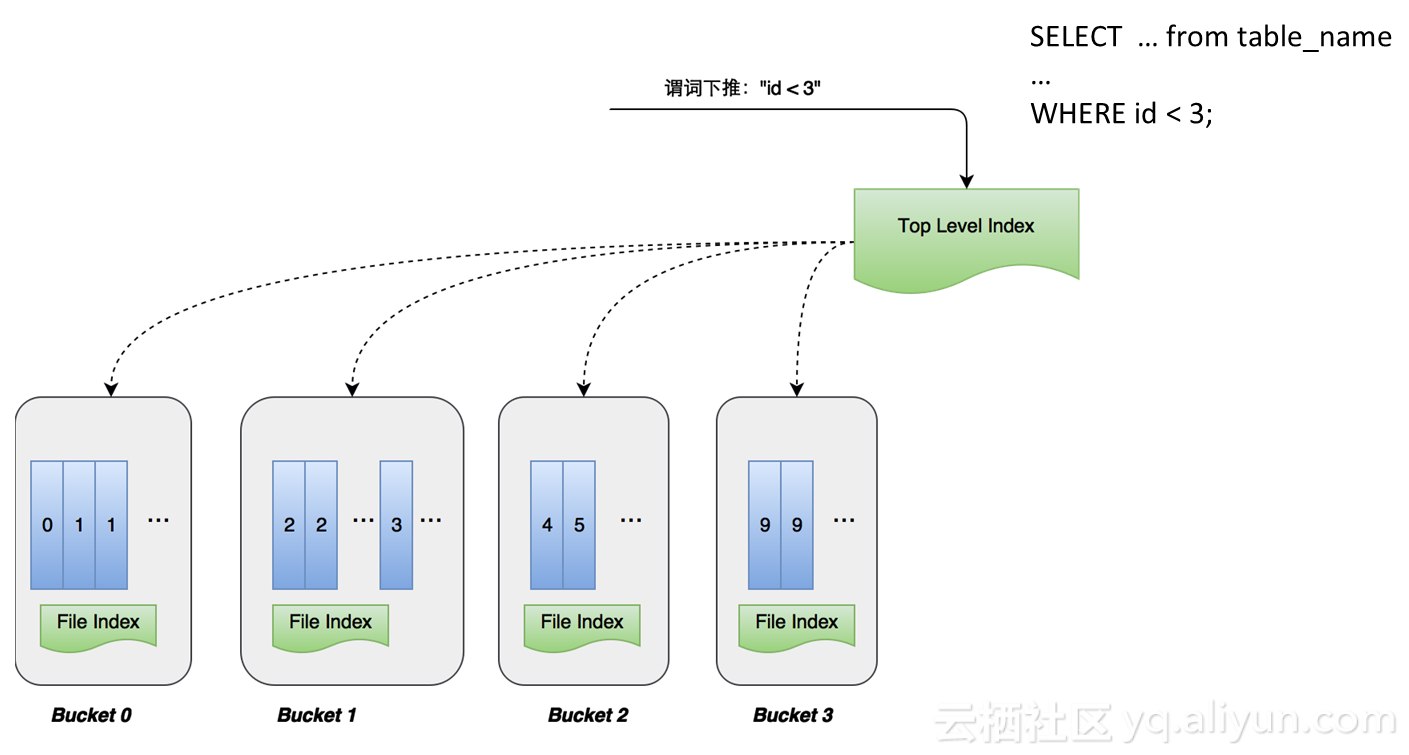
那么如何进行优化呢?例如id<3,如果id列刚好是我做的数据分片和排序索引,谓词会下推到存储层,利用谓词信息去做过滤信息,首先会到上层索引做一级索引,一级索引拥有所有分片的信息,id<3查询条件很快可以确定把bucket2和bucket3两个分片去掉;同时,我们还可以将谓词推到文件下面去,bucket1中有小于3和等于3的,还可以在文件内部进一步过滤,将数据量再减少,如果没有做数据分片index之前,对于id<3 懂得查询,需要去扫整个表,把所有数据全部读一遍,现在不需要读整个表,直接可以通过index把一大堆数直接去掉,效率也是非常可观的。
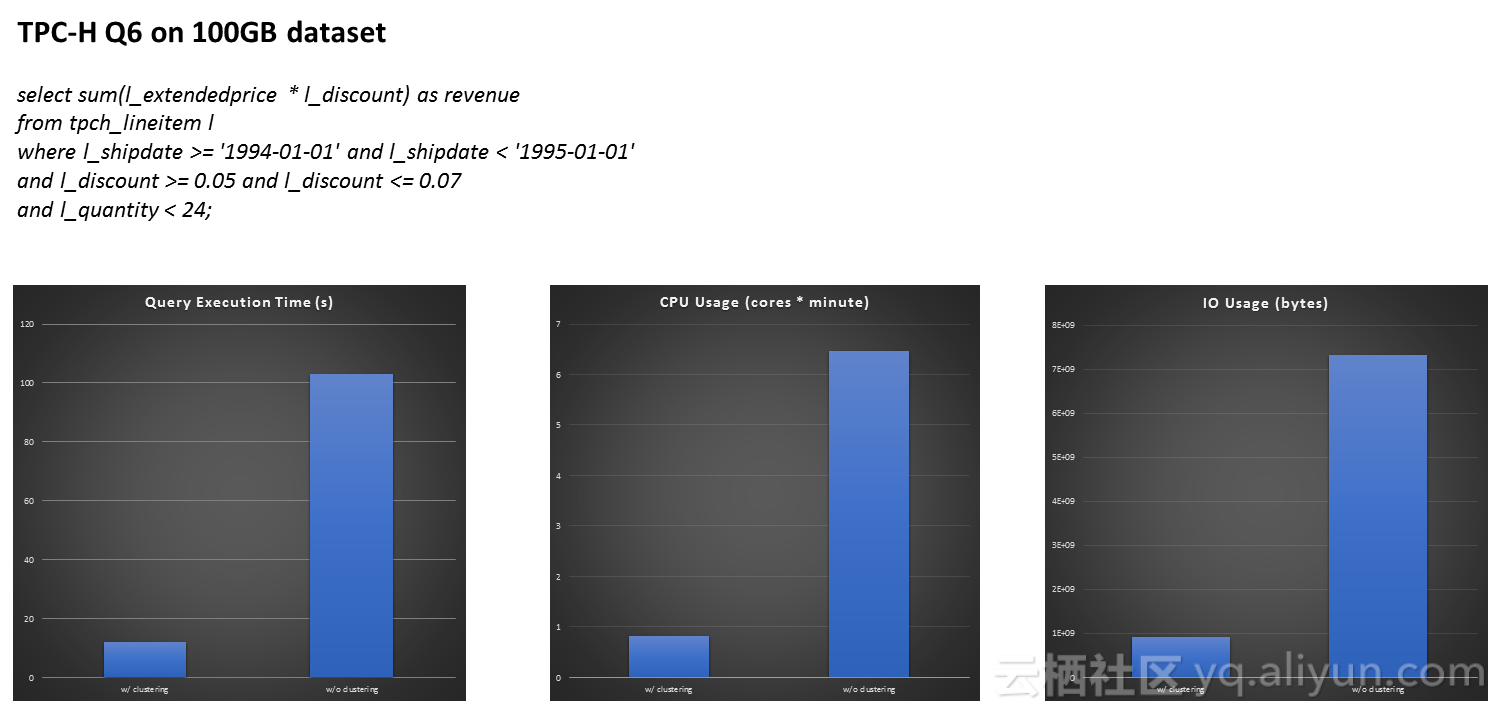
图为TPC-H Q6查询,TPC-H是数据库和大数据领域的标准测试集,我们在100GB的测试数据集上拿到了数据,左边时间是使用index的时间,右边是没有使用index的时间,可以看到提升了10倍左右,无论是query的执行时间,还是CPU的使用时间和IO的使用时间,都会大大减少,通过index减少了很多IO操作,减少了很多数据装载。
Join优化
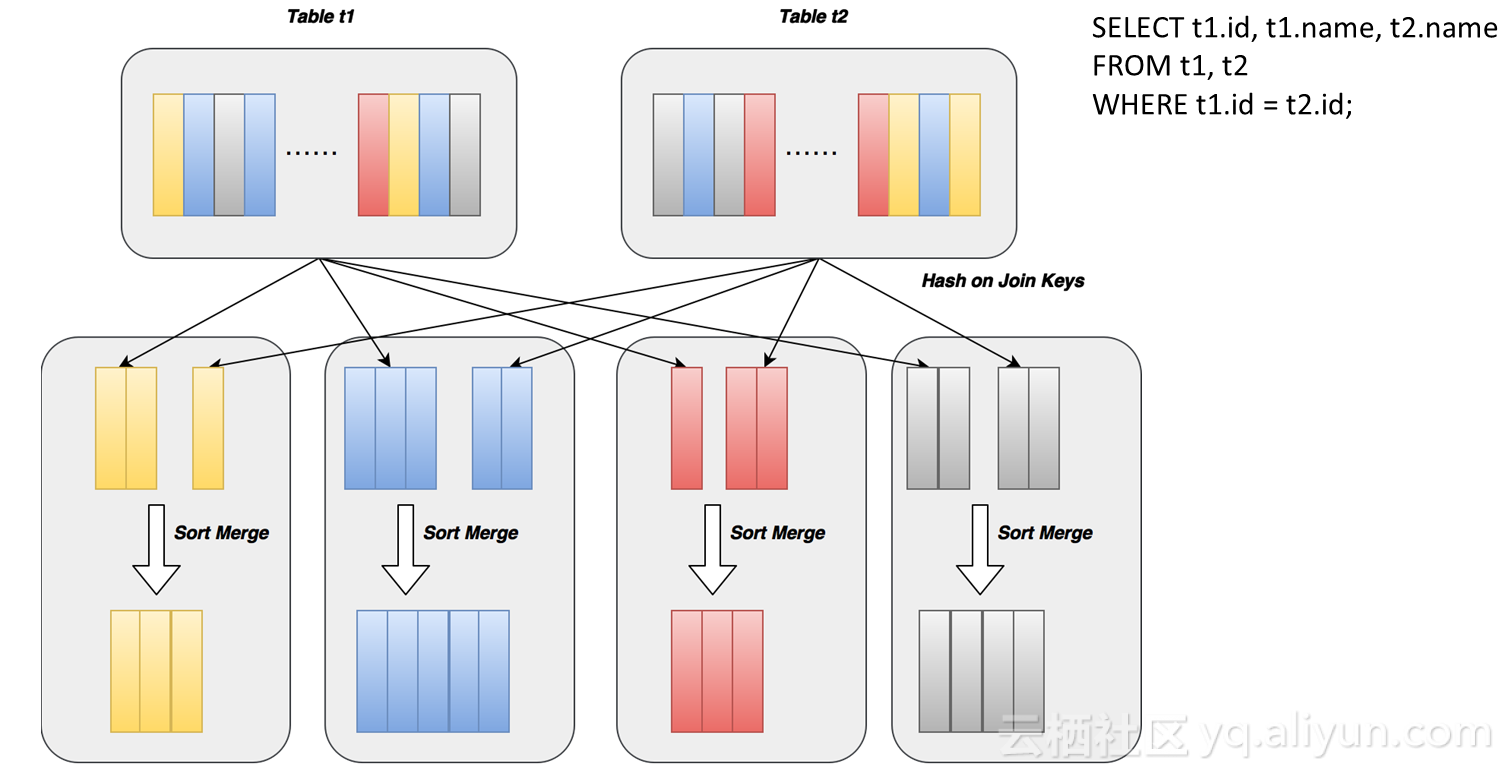
除了在filter上应用index,还有对join的优化。Sort merge join是指有两个数据源在一个机器上将数据join完,一般是将数据源用哈希方式分到N个分片中去,保证join key相同的record会落到相同的分片上,每个分片内部对两个数据源进行排序,排序后再做merge join,就可以把key值相同的找出来,这个过程很复杂,也非常耗时,需要将数据进行哈希运算,再把数据传到另外一个机器上去,你需要先写在一个机器上,另外一个机器再从机器上读取,需要二次磁盘IO,这个过程叫做data shuffle。
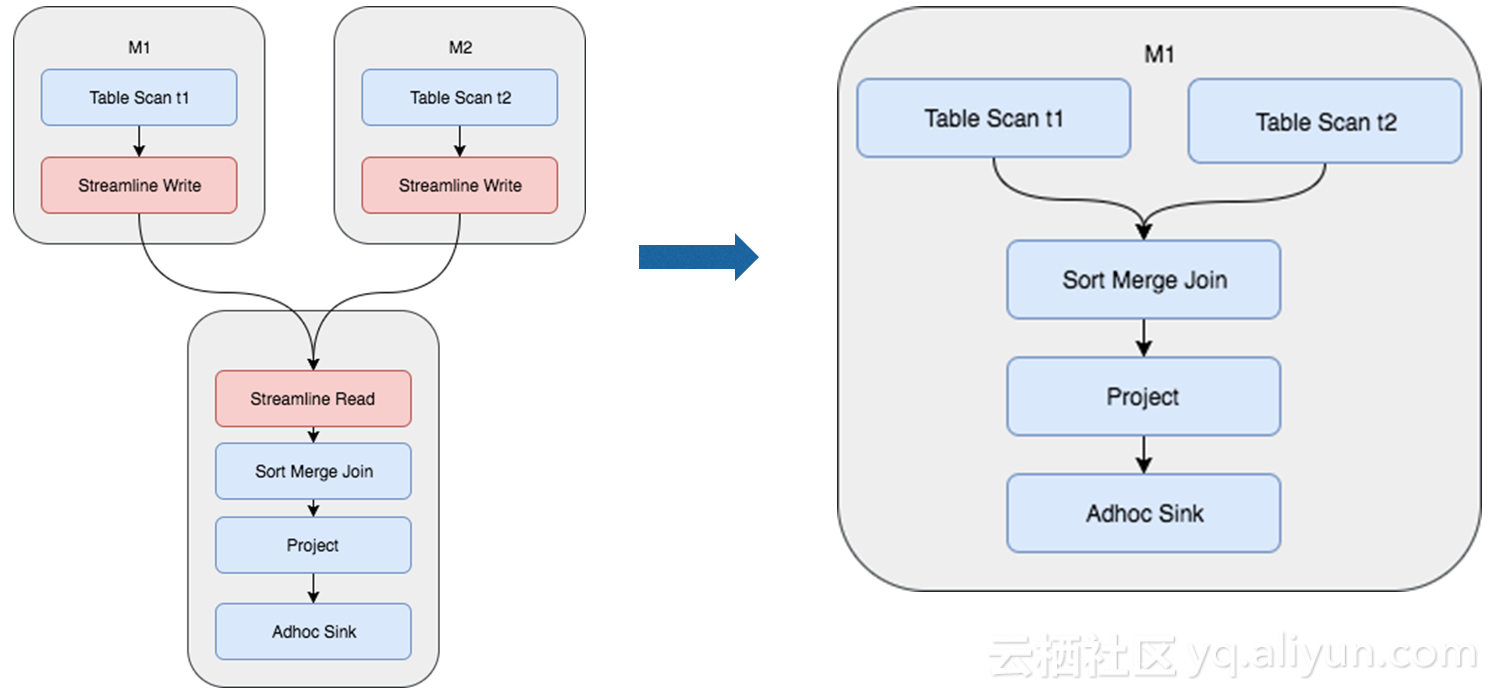
如图,两个table scan从数据磁盘加载进来,streaming read和streaming write来做data shuffle,如果数据已经做完分片和排序,并且把组织结构都存放在磁盘上面,在做join时就不需要再进行shuffle和排序过程,这就是join优化。演化如右图,如果M1和M2已经做了哈希分片排序,可以直接做如图执行计划。
TPC-H Q4
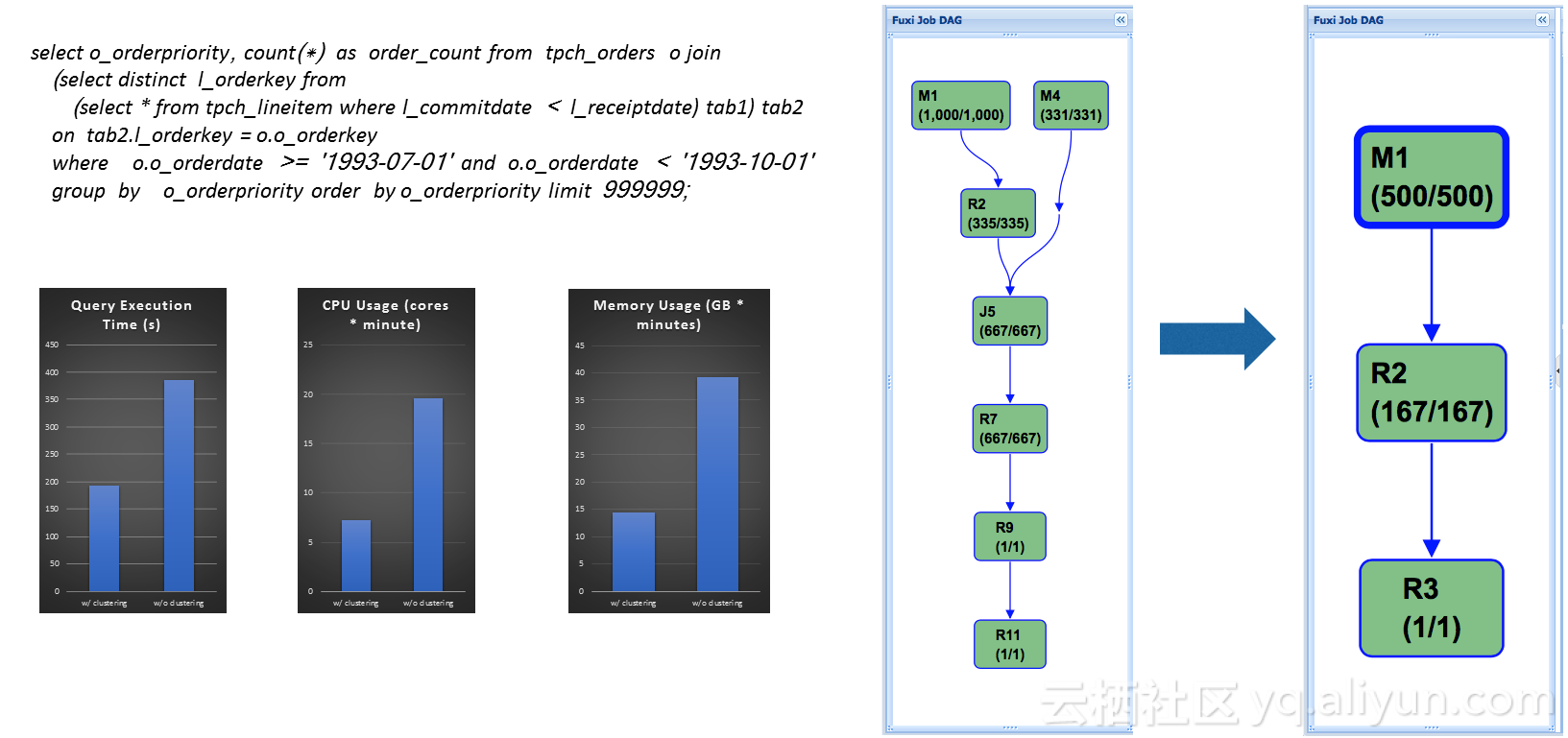
没有哈希分片之前,执行计划如右边图中所示,共有7个stage,多个join和shuffle过程,如果把表改成哈希分片表,并且在join key上做哈希分片,只需要3个stage即可完成,简化了执行计划,基本上都提升了2倍效率。
应用实例
淘宝交易记录查询
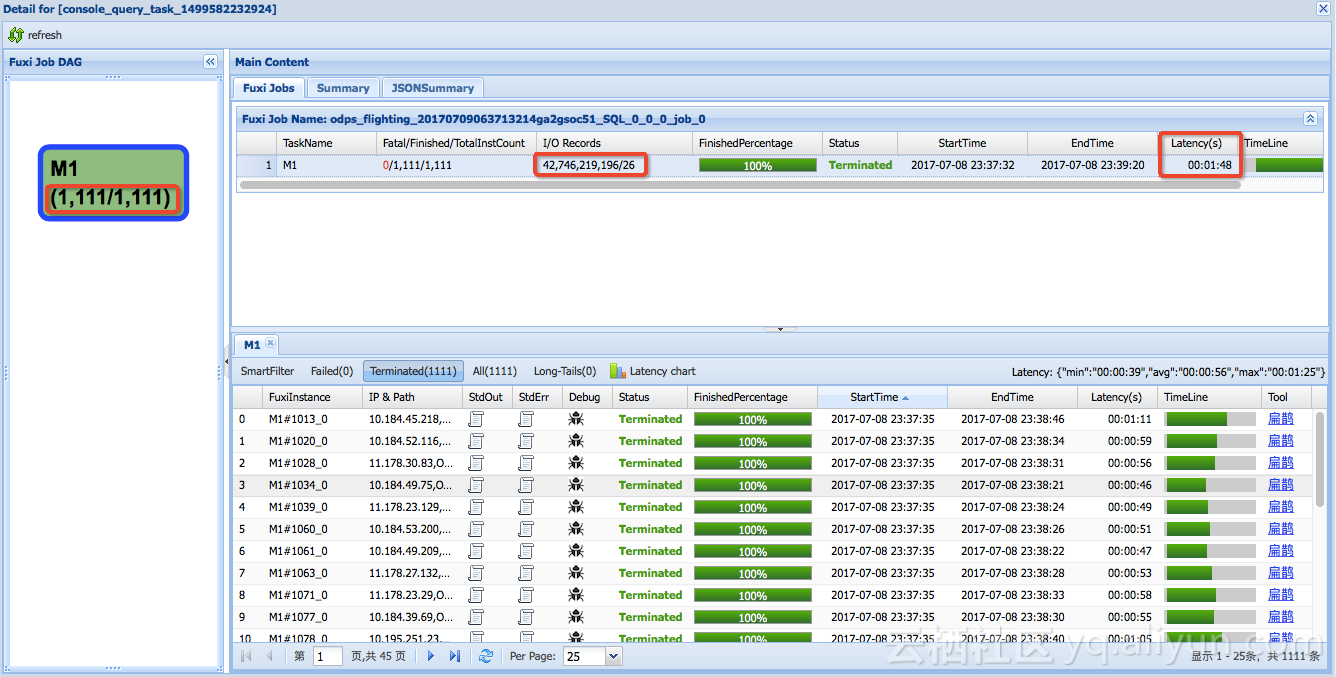
淘宝交易量巨大,百亿级甚至千亿级的数据,查找单笔订单信息,这是一个大海捞针的操作。原有系统在改造以前执行如图,共有一千多个worker去扫描表,400多亿条记录,最后找到26条记录,共用1分48秒。
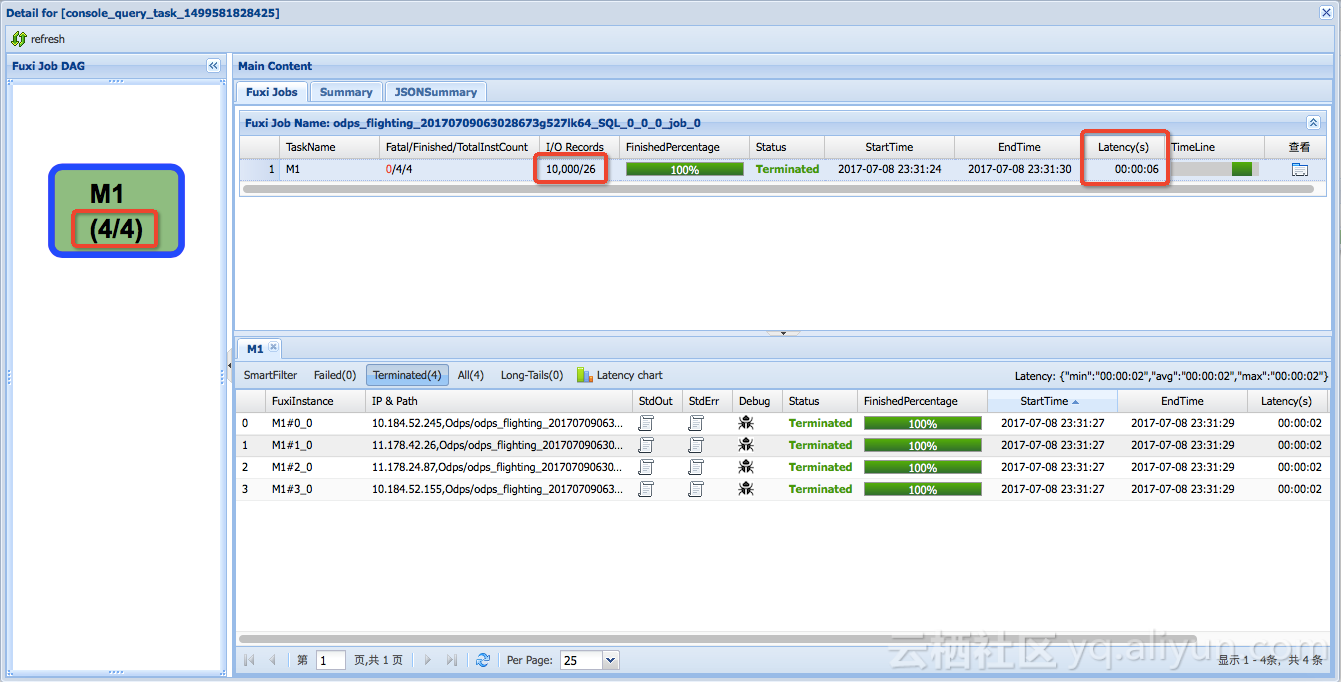
以id为主键,对表进行数据哈希切片排序,同样查询只需要4个mapper,扫描一万条记录6秒钟即可。
淘系交易表增量更新
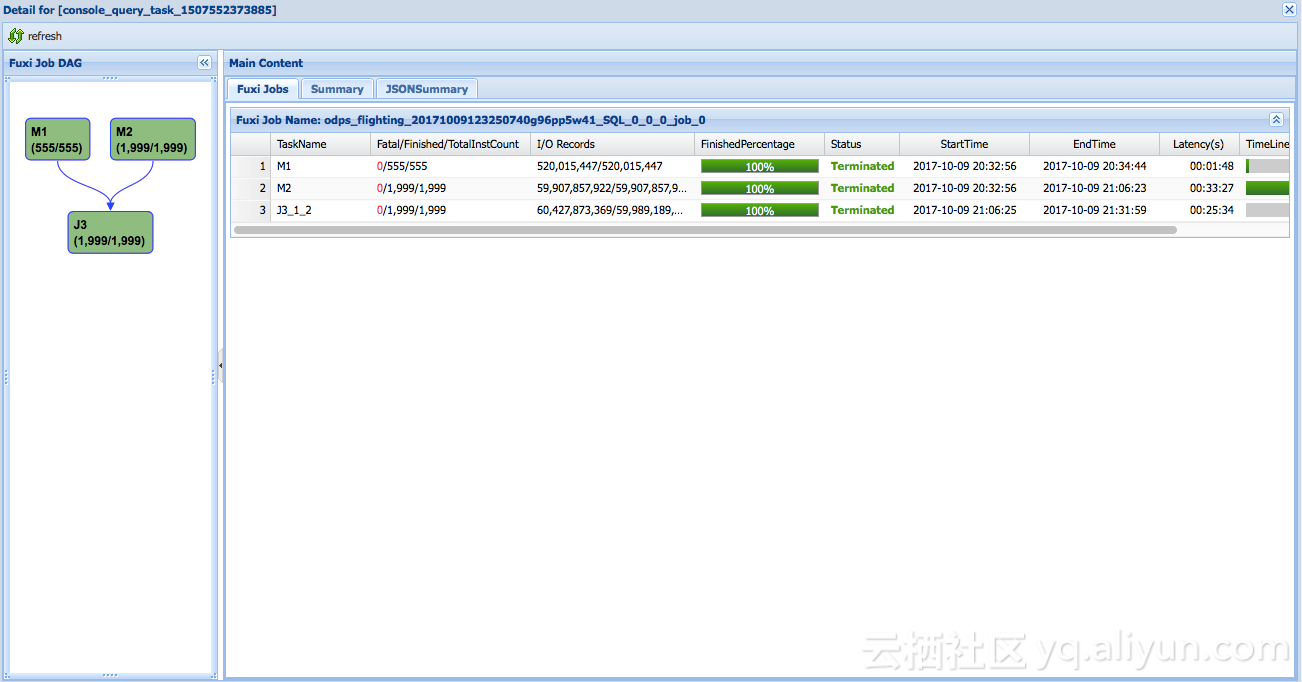
淘宝中有核心交易表,这是集团内部很多BU都会引用的数据来源,对它的正确性要求非常高。我们经常会有增量更新的操作,按周期性以增量表数据插入或者更新到原来表中,全量表数据量巨大,记录数在百亿、千亿,增量表可能是十分之一甚至百分之一,每次更新需要对原表和增量表进行shuffle,非常耗时。图中M1和M2在做增量表的shuffle和全量表的shuffle,增量表需要1分49秒,全量表共用2000个worker做了33分钟。
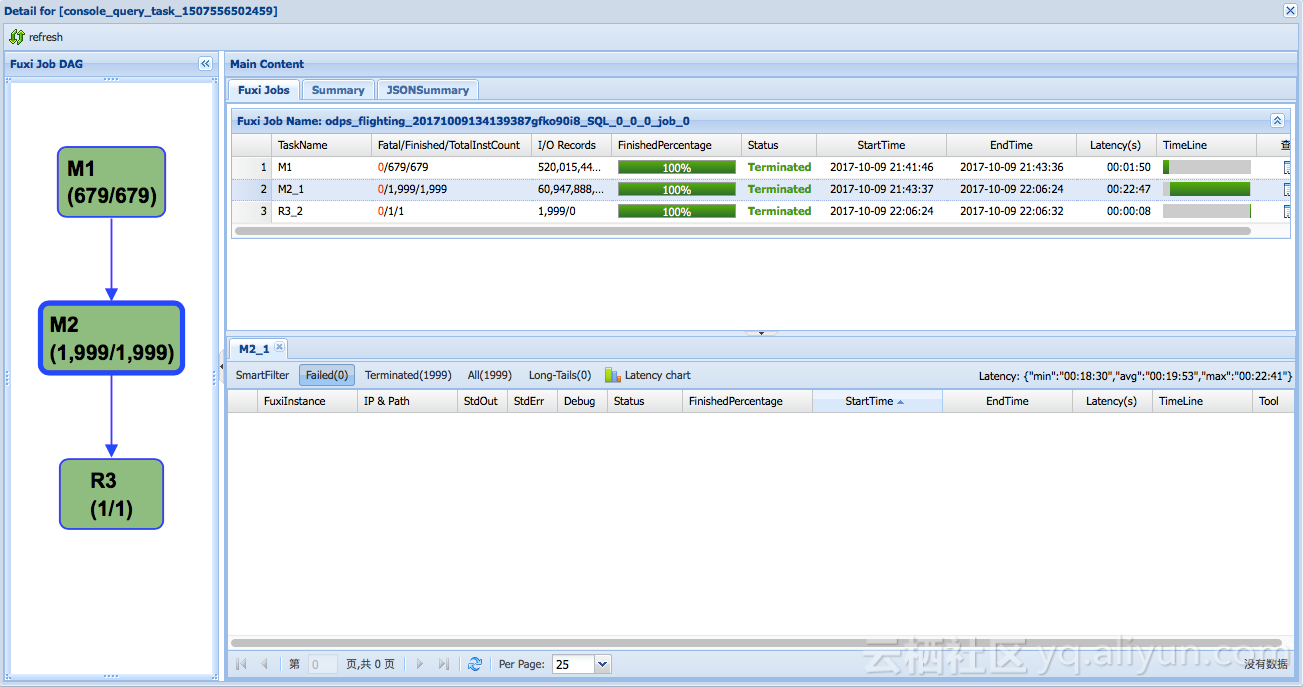
全量表哈希分片后排序存储,更新时只需要按增量表shuffle,避免了对全量表的多次shuffle,整个join执行时间从60分钟降低到22分钟。
总结
我们通过对数据进行分片和排序,并建立索引,MaxCompute可以更好的理解数据。
查询条件谓词下推,减少了表扫描的IO量,以及运行时过滤操作的时间。
利用数据分片和排序特性,直接避免了多次对数据Shuffle的操作,简化了执行计划,节约资源,节省时间。














 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









