







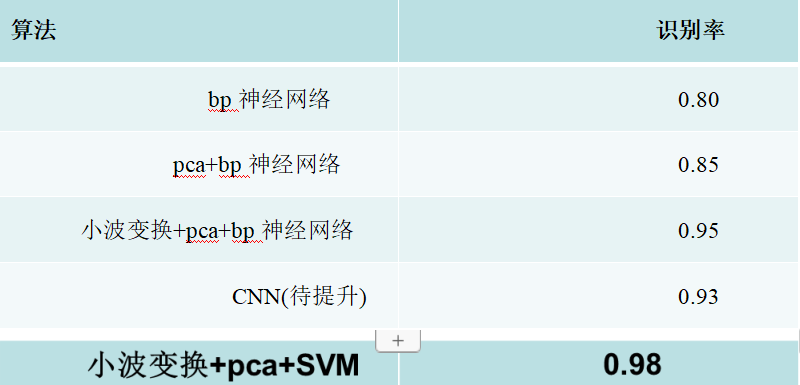
 文章介绍了使用ORL人脸库进行人脸识别的实验,比较了BP神经网络、小波变换结合PCA、以及SVM在不同参数下的识别性能。CNN虽然性能高,但对电脑性能要求较高,小波+PCA+SVM对于资源有限的环境是一个可行选择。
文章介绍了使用ORL人脸库进行人脸识别的实验,比较了BP神经网络、小波变换结合PCA、以及SVM在不同参数下的识别性能。CNN虽然性能高,但对电脑性能要求较高,小波+PCA+SVM对于资源有限的环境是一个可行选择。
一、数据集介绍
ORL人脸库(Olivetti Research Laboratory人脸数据库),诞生于英国剑桥Olivetti实验室。
ORL人脸数据库由该实验室从1992年4月到1994年4月期间拍摄的一系列人脸图像组成,共有40个不同年龄、不同性别和不同种族的对象。每个人10幅图像共计400幅灰度图像组成,图像尺寸是92×112,图像背景为黑色。其中人脸部分表情和细节均有变化,例如笑与不笑、眼睛睁着或闭着,戴或不戴眼镜等,人脸姿态也有变化,其深度旋转和平面旋转可达20度,人脸尺寸也有最多10%的变化。该库是目前使用最广泛的标准人脸数据库,特别是刚从事人脸识别研究的学生和初学者,研究ORL人脸库是个很好的开始(见图一)。

图一、ORL人脸识别
- 1
二、实验
五种方法实现orl人脸识别
1.bp神经网络(未降维)
- pca+bp神经网络
采用ORL人脸数据库,先在400张人脸中选取一部分作为训练样本集(前5张训练,后5张测试),对其进行PCA降维,形成特征脸子空间;再将剩余的人脸作为检测集,将其投影到特征脸子空间;采用BP神经网络对训练样本集进行训练,然后再用检测集进行识别率测试
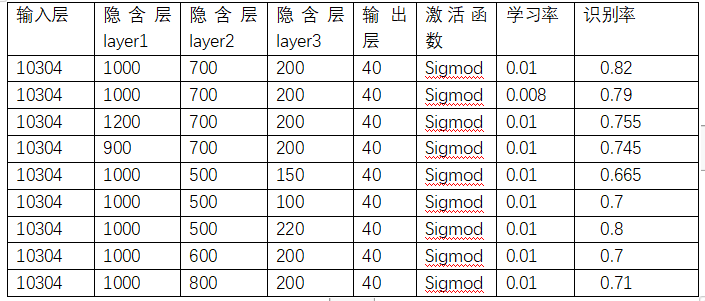
1、BP神经网络识别中存在的问题
在采用BP神经网络进行训练过程中,由于可调参数过多,会对识别率产生一定的影响,故在设计中针对可调参数反复进行测试,对比来寻找最快,最优识别的网络参数。下面列出可能影响网络性能的各个参数:
(1)BP网络训练函数的选取
(2)BP网络学习速率,迭代次数,误差,梯度的设定
(3)PCA主成分比例的选取
(4)BP网络隐层节点数的选取
(5)训练集和测试集容量的选取
2、网络训练函数的选取
当采用一般的基于梯度下降的BP网络进行训练时,由于固定的学习速率,有限的迭代次数,较小的设定误差和截止梯度,致使网路有较长的训练时间,而且还不一定能达到要求的精度,这会大大影响识别率。
经过多次训练函数的尝试,最终选择带有动量相的自适应学习率的训练优化器AdagradOptimizer。下面表格显示出了三种训练函数在训练速度上的对比:
从上表可以看出:
(1)尽管采用添加动量相的BP算法,由于学习速率固定,网络的训练速度仍旧很慢。如果盲目的增加学习速率,又会造成网络在某处的波动。因此,训练函数采用AdagradOptimizer学习速率的算法较为合适。
3、BP网络性能参数的设定
上表中,为了缩短运行时间,通过加大截止误差和设定迭代次数的方法来加快程序运行,这样会在一定程度上降低识别率。当采用AdagradOptimizer的训练函数后,网络运行速度加快,将截止误差设定为0,迭代次数仍设定为10000,发现每次促使训练停止的为默认的截止梯度。此时的网络误差已足够小。
3.小波变换+pca+bp
术语(中英对照):
尺度函数 : scaling function (在一些文档中又称为父函数 father wavelet )
小波函数 : wavelet function(在一些文档中又称为母函数 mother wavelet)
连续的小波变换 :CWT
离散的小波变换 :DWT
小波变换的基本知识
不同的小波基函数,是由同一个基本小波函数经缩放和平移生成的。
小波变换是将原始图像与小波基函数以及尺度函数进行内积运算,所以一个尺度函数和一个小波基函数就可以确定一个小波变换
小波变换后低频分量
pywt.wavedec2(data, wavelet, mode=’symmetric’, level=None, axes=(-2, -1))
data: 输入的数据
wavelet:小波基
level: 尺度(要变换多少层)
return: 返回的值要注意,每一层的高频都是包含在一个tuple中,例如三层的话返回为 [cA3, (cH3, cV3, cD3), (cH2, cV2, cD2), (cH1, cV1, cD1)]
(cA, (cH, cV, cD))要注意返回的值,分别为低频分量,水平高频、垂直高频、对角线高频。高频的值包含在一个tuple中。
PCA降维的目的:
1.减少预测变量的个数
2.确保这些变量是相互独立的
3.提供一个框架来解释结果
降维的方法有:主成分分析、因子分析、用户自定义复合等。
PCA(Principal Component Analysis)不仅仅是对高维数据进行降维,更重要的是经过降维去除了噪声,发现了数据中的模式。
PCA把原先的n个特征用数目更少的m个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的m个特征互不相关。从旧特征到新特征的映射捕获数据中的固有变异性
sklearn.decomposition.PCA(n_components=None,copy=True,whiten=False)
n_components: int, float, None 或 string,PCA算法中所要保留的主成分个数,也即保留下来的特征个数,如果 n_components = 1,将把原始数据降到一维;如果赋值为string,如n_components=‘mle’,将自动选取特征个数,使得满足所要求的方差百分比;如果没有赋值,默认为None,特征个数不会改变(特征数据本身会改变)。copy:True 或False,默认为True,即是否需要将原始训练数据复制。whiten:True 或False,默认为False,即是否白化,使得每个特征具有相同的方差
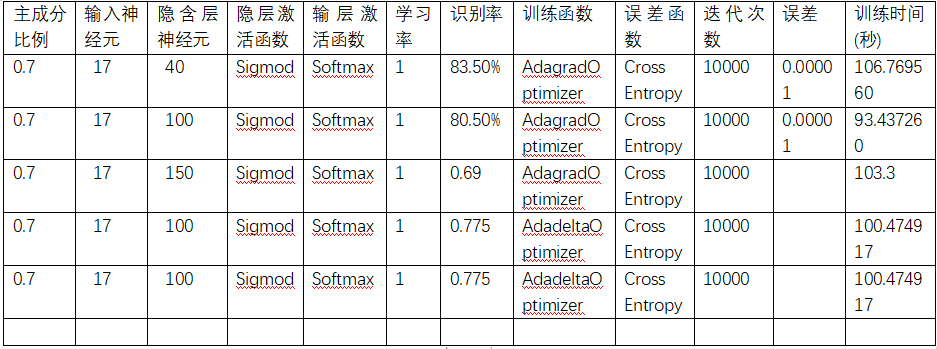
实验过程参数调节,1,3,5,7,9训练,0,2,4,6,8测试。
小波基 Level 主成分比例 输入神经元 隐含层神经元 隐层激活函数 输层激活函数 学习率 识别率 训练函数 误差函数 迭代次数 训练时间
(秒)
db2 3 0.8 15 50 Sigmod Softmax 1 87.50% AdagradOptimizer Cross Entropy 10000 391.498192
haar 3 0.8 13 50 Sigmod Softmax 1 90.50% AdagradOptimizer Cross Entropy 10000 409.169392
haar 20 0.7 17 50 Sigmod Softmax 1 88% AdagradOptimizer Cross Entropy 10000 225.005641
haar 20 0.95 70 100 Sigmod Softmax 1 90.00% AdagradOptimizer Cross Entropy 10000 222.635430
实验完任选5张训练,5张测试,实验截图如下:
小波基 Level 主成分比例 输入神经元 隐含层神经元 隐层激活函数 输层激活函数 学习率 识别率 训练函数 误差函数 迭代次数 训练时间
(秒)
db2 3 0.8 15 50 Sigmod Softmax 1 92.00% AdagradOptimizer Cross Entropy 10000 205.950940
损失曲线
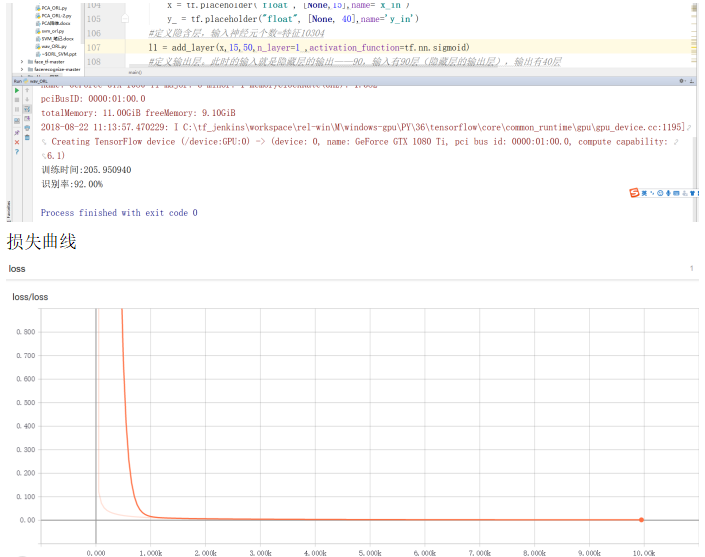
神经网络结构图
权重和偏置分布图
权重和偏置直方图
- CNN
本次实验使用GPU进行加速运算
最后加了一层神经网络,隐含层神经元个数为800
本次识别率如下
- 小波变换+pca+SVM
clf=SVC(C=1000.0, cache_size=200, class_weight=‘balanced’, coef0=0.0,
decision_function_shape=‘ovr’, degree=3, gamma=0.001, kernel=‘rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
•C : float, optional (default=1.0) 误差项的惩罚参数,一般取值为10的n次幂,如10的-5次幂,10的-4次幂。。。。10的0次幂,10,1000,1000,在python中可以使用pow(10,n) n=-5~inf C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很高,但泛化能力弱。 C值小,对误分类的惩罚减小,容错能力增强,泛化能力较强。
•kernel : string, optional (default=’rbf’) svc中指定的kernel类型。 可以是: ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ 或者自己指定。 默认使用‘rbf’ 。
•degree : int, optional (default=3) 当指定kernel为 ‘poly’时,表示选择的多项式的最高次数,默认为三次多项式。 若指定kernel不是‘poly’,则忽略,即该参数只对‘poly’有作用。
•gamma : float, optional (default=’auto’) 当kernel为‘rbf’, ‘poly’或‘sigmoid’时的kernel系数。 如果不设置,默认为 ‘auto’ ,此时,kernel系数设置为:1/n_features
•coef0 : float, optional (default=0.0) kernel函数的常数项。 只有在 kernel为‘poly’或‘sigmoid’时有效,默认为0。
•probability : boolean, optional (default=False) 是否采用概率估计。 必须在fit()方法前使用,该方法的使用会降低运算速度,默认为False。
•shrinking : boolean, optional (default=True) 如果能预知哪些变量对应着支持向量,则只要在这些样本上训练就够了,其他样本可不予考虑,这不影响训练结果,但降低了问题的规模并有助于迅速求解。进一步,如果能预知哪些变量在边界上(即a=C),则这些变量可保持不动,只对其他变量进行优化,从而使问题的规模更小,训练时间大大降低。这就是Shrinking技术。 Shrinking技术基于这样一个事实:支持向量只占训练样本的少部分,并且大多数支持向量的拉格朗日乘子等于C。
•tol : float, optional (default=1e-3) 误差项达到指定值时则停止训练,默认为1e-3,即0.001。
•cache_size : float, optional 指定内核缓存的大小,默认为200M。
•class_weight : {dict, ‘balanced’}, optional 权重设置。如果不设置,则默认所有类权重值相同。 以字典形式传入。
•verbose : bool, default: False 是否启用详细输出。 多线程时可能不会如预期的那样工作。默认为False
•max_iter : int, optional (default=-1) 强制设置最大迭代次数。 默认设置为-1,表示无穷大迭代次数。 Hard limit on iterations within solver, or -1 for no limit
•random_state : int, RandomState instance or None, optional (default=None) 伪随机数使用数据。
本次SVM使用默认参数
参数调节过程中1,3,5,7,9训练,其他五张测试
小波基 Level 主成分比例 识别率
db2 3 0.8 96.00%
db2 4 0.8 95.50%
db2 4 0.7 91.00%
db2 4 0.9 96.50%
sym2 3 0.9 97%
sym2 4 0.9 96.50%
三.总结
CNN对电脑性能要求比价高,我在GPU上进行跑的,如果没有很好的电脑性能,小波变换+pca+svm是不错的选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









