







Mayor's posters
Description
The citizens of Bytetown, AB, could not stand that the candidates in the mayoral election campaign have been placing their electoral posters at all places at their whim. The city council has finally decided to build an electoral wall for placing the posters and introduce the following rules:
- Every candidate can place exactly one poster on the wall.
- All posters are of the same height equal to the height of the wall; the width of a poster can be any integer number of bytes (byte is the unit of length in Bytetown).
- The wall is divided into segments and the width of each segment is one byte.
- Each poster must completely cover a contiguous number of wall segments.
They have built a wall 10000000 bytes long (such that there is enough place for all candidates). When the electoral campaign was restarted, the candidates were placing their posters on the wall and their posters differed widely in width. Moreover, the candidates started placing their posters on wall segments already occupied by other posters. Everyone in Bytetown was curious whose posters will be visible (entirely or in part) on the last day before elections.
Your task is to find the number of visible posters when all the posters are placed given the information about posters' size, their place and order of placement on the electoral wall.
Input
The first line of input contains a number c giving the number of cases that follow. The first line of data for a single case contains number 1 <= n <= 10000. The subsequent n lines describe the posters in the order in which they were placed. The i-th line among the n lines contains two integer numbers li and ri which are the number of the wall segment occupied by the left end and the right end of the i-th poster, respectively. We know that for each 1 <= i <= n, 1 <= li <= ri <= 10000000. After the i-th poster is placed, it entirely covers all wall segments numbered li, li+1 ,... , ri.
Output
For each input data set print the number of visible posters after all the posters are placed.
The picture below illustrates the case of the sample input.
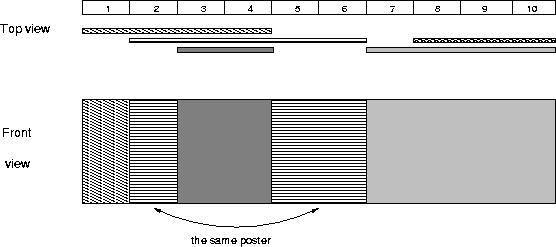
Sample Input
1
5
1 4
2 6
8 10
3 4
7 10
Sample Output
4
这是一道很经典的线段树离散化问题,题目中给出的区间[li,ri]的数据都很大,直接用线段树做的话至少需要10000000*4的空间,因此,我们首先要对数据进行离散化处理
首先,我们要弄清楚离散化的概念,我们根据题目样例进行分析,可以看到[1,4],[2,6],[8,10],[3,4],[7,10]这五个区间,我们将这10个数都拿出来排个序,创建序列a
1 2 3 4 4 6 7 8 10 10
接下来我们对序列a去下重
1 2 3 4 6 7 8 10
然后我们用他们的相对大小(例如:6在这个序列中是第5大,10在这个序列中是第8大)建立另一个序列b
1 2 3 4 5 6 7 8
最后我们用每个数对应的相对大小来替换原来的区间就变成了这样
[1,4],[2,5],[7,8],[3,4],[6,8]
我们用这个区间来计算一下最后能观察到的海报数的话会发现,结果仍然是4
我个人对离散化的理解就是用数字的相对大小来替换他的实际大小从而达到减小其值,却不破坏它的位置关系的目的
这道题我们利用这样的方法就能将li,ri这么大的数缩小到最大只有20000(因为最多有20000个点)
理解题意后我们直接看代码,至于线段树部分就是普通的区间修改而已
#pragma GCC optimize("Ofast") #include <iostream> #include <algorithm> #include <set> using namespace std; #define endl '\n' #define ll long long struct node { int l, r, flag; } tree[800005]; int base[20005], ls[20005]; set<int> s; void tree_build(int i, int l, int r) { tree[i].l = l; tree[i].r = r; tree[i].flag = 0; if (l == r) { return; } int mid = (l + r) >> 1; tree_build(i << 1, l, mid); tree_build(i << 1 | 1, mid + 1, r); } void push_down(int i) { if (tree[i].flag) { tree[i << 1].flag = tree[i].flag; tree[i << 1 | 1].flag = tree[i].flag; tree[i].flag = 0; } } void update(int i, int l, int r, int num) { if (tree[i].l >= l && tree[i].r <= r) { tree[i].flag = num; return; } if (tree[i].r < l || tree[i].l > r) { return; } push_down(i); if (tree[i << 1].r >= l) { update(i << 1, l, r, num); } if (tree[i << 1 | 1].l <= r) { update(i << 1 | 1, l, r, num); } } void search(int i, int l, int r) { if (tree[i].flag) { s.insert(tree[i].flag);//利用set自动去重的性质来记录海报数量 return; } if (l == r) { return; } int mid = (l + r) >> 1; search(i << 1, l, mid); search(i << 1 | 1, mid + 1, r); } int main() { ios::sync_with_stdio(0); cin.tie(0); cout.tie(0); int t; cin >> t; while (t--) { int n, x, y, pos = 1; cin >> n; s.clear(); tree_build(1, 1, 200005); for (int i = 1; i <= n; ++i) { //这地方我们开两个数组,base用与计算每个数的相对位置,ls是离散化后的数组 cin >> x >> y; base[pos] = x; ls[pos++] = x; base[pos] = y; ls[pos++] = y; } //无论是sort还是unique还是lower_bound区间设定都是左闭右开的形式,品,你细细的品 sort(base + 1, base + pos); int num = unique(base + 1, base + pos) - base;//对base排序并去重,必须排序后才能用unique for (int i = 1; i < pos; ++i) { ls[i] = lower_bound(base + 1, base + num, ls[i]) - base; } for (int i = 2; i < pos; i += 2) { update(1, ls[i - 1], ls[i], i); } search(1, 1, 200005); cout << s.size() << endl; } return 0; }
你以为这就完事了?其实这样离散化在这道题中会有一些bug,我们看这组数据[1,10],[1,3],[6,10],很明显答案是3
但是离散化之后为[1,4],[1,2],[3,4],答案变成了2
为解决这种问题,我们可以在更新线段树的时候将区间从[l,r]变成[l,r-1],就将区间转化成了[1,3],[1,1],[3,3]这样的树
但是当我们遇到这样的数据[1,3],[1,1],[2,2],[3,3],就会导致区间更新时出错,我们可以将初始数据的r都加上1,就排除了li和ri相等的情况,如果没有这种情况,离散化后的区间也都是一样的
其实这道题数据很弱,不管这样的情况也能过(逃
#pragma GCC optimize("Ofast") #include <iostream> #include <algorithm> #include <set> using namespace std; #define endl '\n' #define ll long long struct node { int l, r, flag; } tree[100005]; int base[20005], ls[20005]; set<int> s; void tree_build(int i, int l, int r) { tree[i].l = l; tree[i].r = r; tree[i].flag = 0; if (l == r) { return; } int mid = (l + r) >> 1; tree_build(i << 1, l, mid); tree_build(i << 1 | 1, mid + 1, r); } void push_down(int i) { if (tree[i].flag) { tree[i << 1].flag = tree[i].flag; tree[i << 1 | 1].flag = tree[i].flag; tree[i].flag = 0; } } void update(int i, int l, int r, int num) { if (tree[i].l >= l && tree[i].r <= r) { tree[i].flag = num; return; } if (tree[i].r < l || tree[i].l > r) { return; } push_down(i); if (tree[i << 1].r >= l) { update(i << 1, l, r, num); } if (tree[i << 1 | 1].l <= r) { update(i << 1 | 1, l, r, num); } } void search(int i, int l, int r) { //cout << tree[i].flag << " " << tree[i].l << " " << tree[i].r << endl; if (tree[i].flag) { //cout << tree[i].flag << " " << tree[i].l << " " << tree[i].r << endl; s.insert(tree[i].flag); return; } if (l == r) { return; } int mid = (l + r) >> 1; search(i << 1, l, mid); search(i << 1 | 1, mid + 1, r); } int main() { ios::sync_with_stdio(0); cin.tie(0); cout.tie(0); int t; cin >> t; while (t--) { int n, x, y, pos = 1; cin >> n; s.clear(); tree_build(1, 1, 20005); for (int i = 1; i <= n; ++i) { cin >> x >> y; base[pos] = x; ls[pos++] = x; base[pos] = y + 1; ls[pos++] = y + 1; } sort(base + 1, base + pos); int num = unique(base + 1, base + pos) - base; for (int i = 1; i < pos; ++i) { ls[i] = lower_bound(base + 1, base + num, ls[i]) - base; } for (int i = 2; i < pos; i += 2) { update(1, ls[i - 1], ls[i] - 1, i); } search(1, 1, 20005); cout << s.size() << endl; } return 0; }















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









