






人工智能算法模型
启发式搜索(有信息搜索)
1.代价函数h(n),评估函数f(n)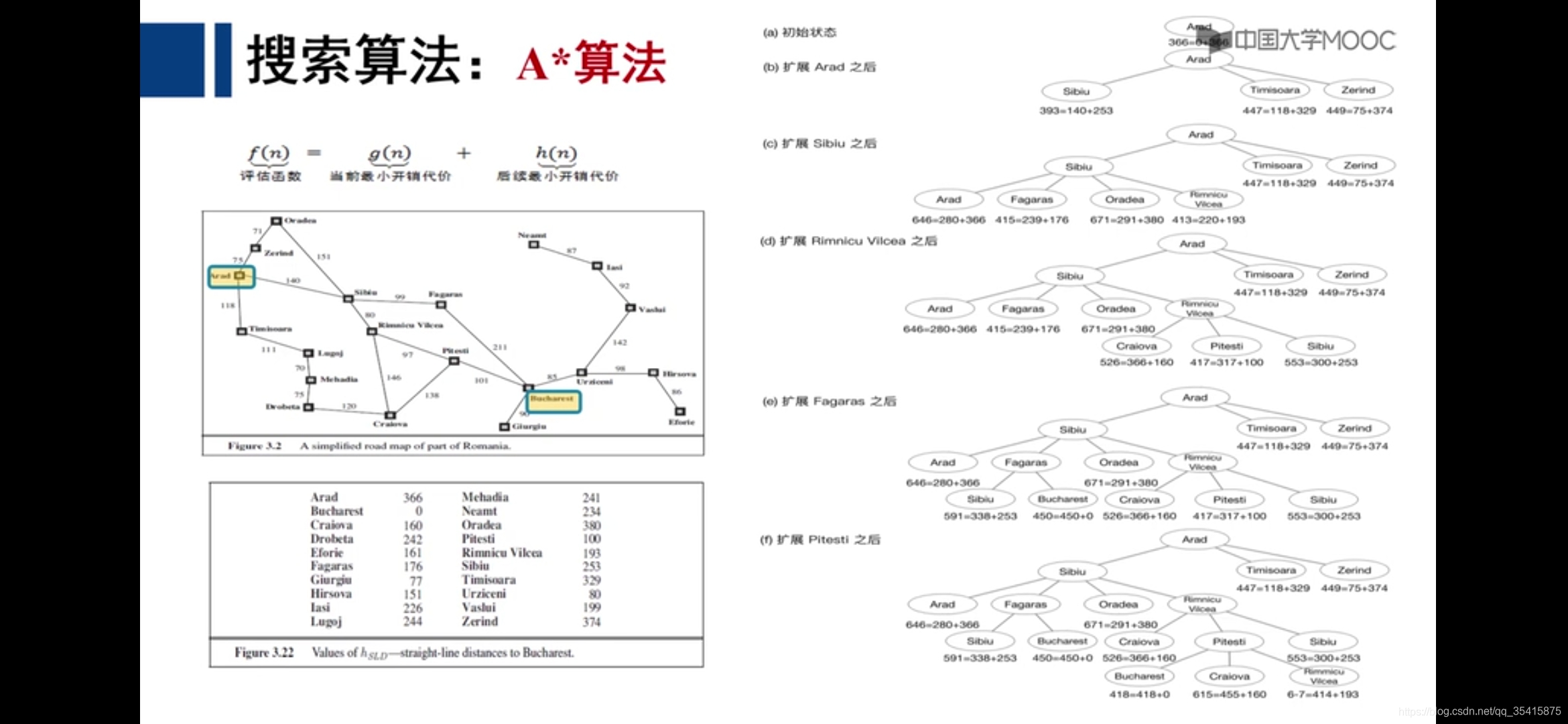
对抗搜索
1.最小最大搜索
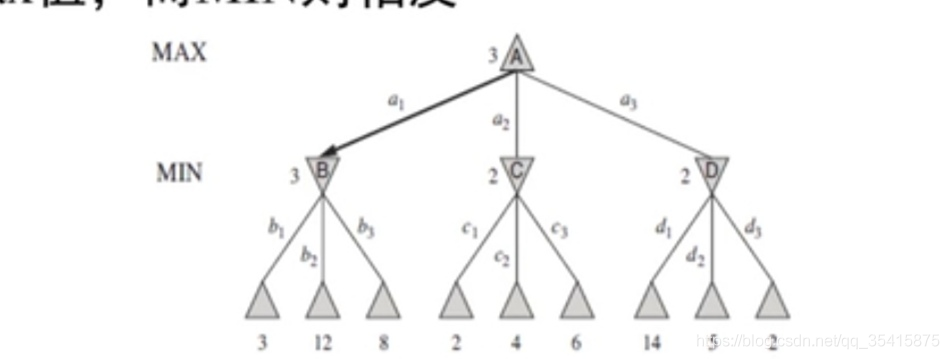
例子:以我赢为目的,我选择最大的节点B,希望对手再选择B下的最小节点3
(双方都尽力让对方的收益最小)
2.αβ剪枝
优化最大最小,将不必要的节点剪掉
3.蒙特卡洛树
(1)多臂赌博机

(2)上限置信区策略(ucb)

(3)蒙特卡洛树搜索(ucb算法实例)
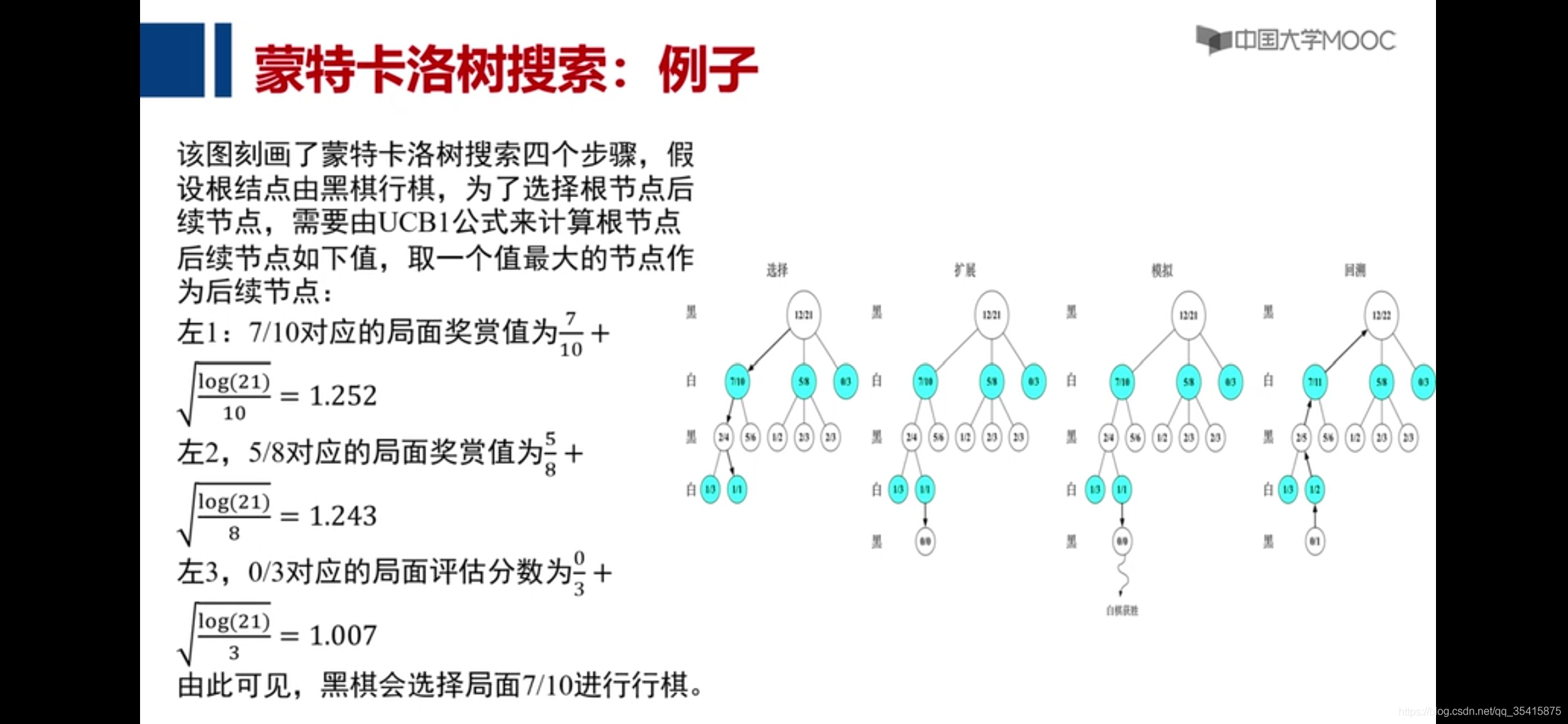
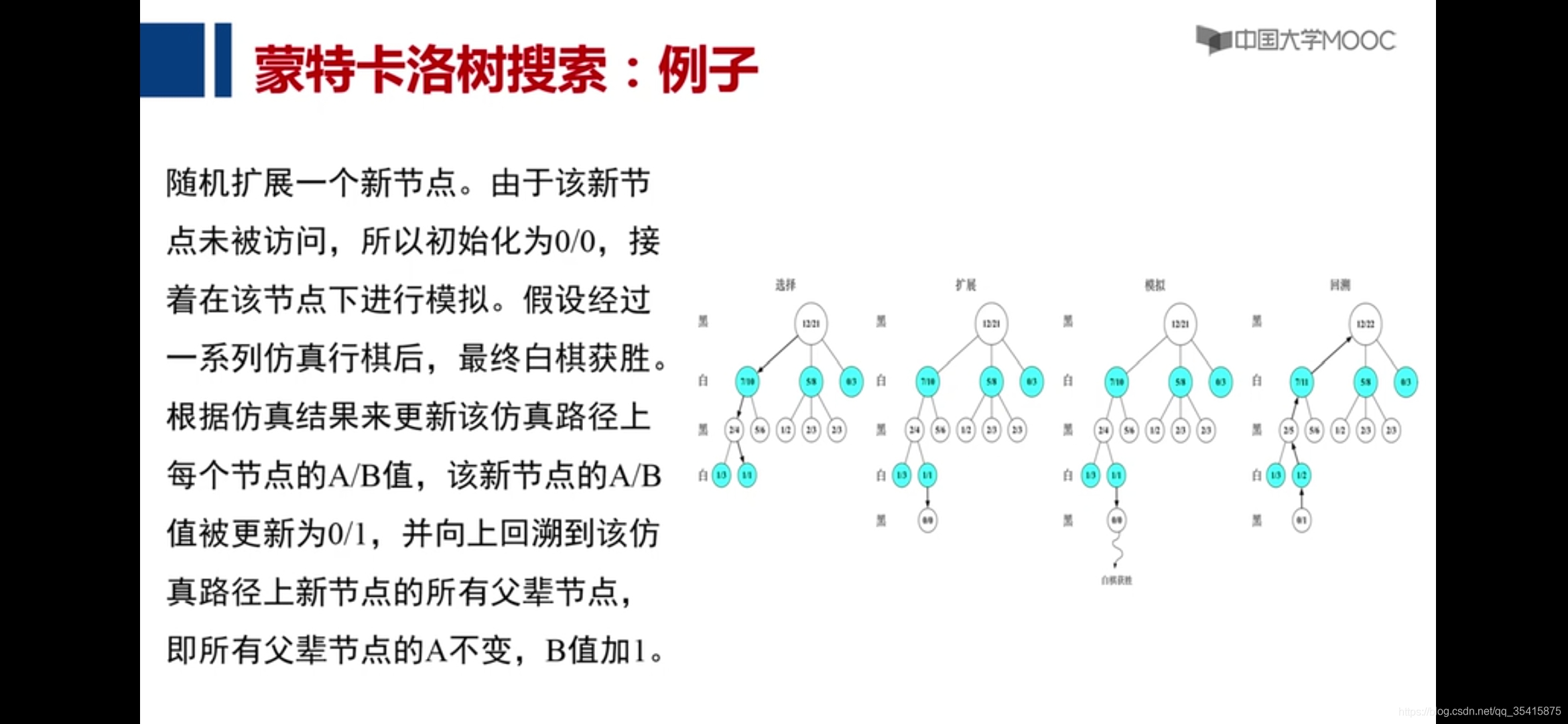
围棋对决,黑棋赢例子
命题逻辑

谓词逻辑
为什么要谓词逻辑

谓词逻辑的知识:

例子:P(x)是谓词,x是小王,小王是个体,∃x是量词,x是谓词变量




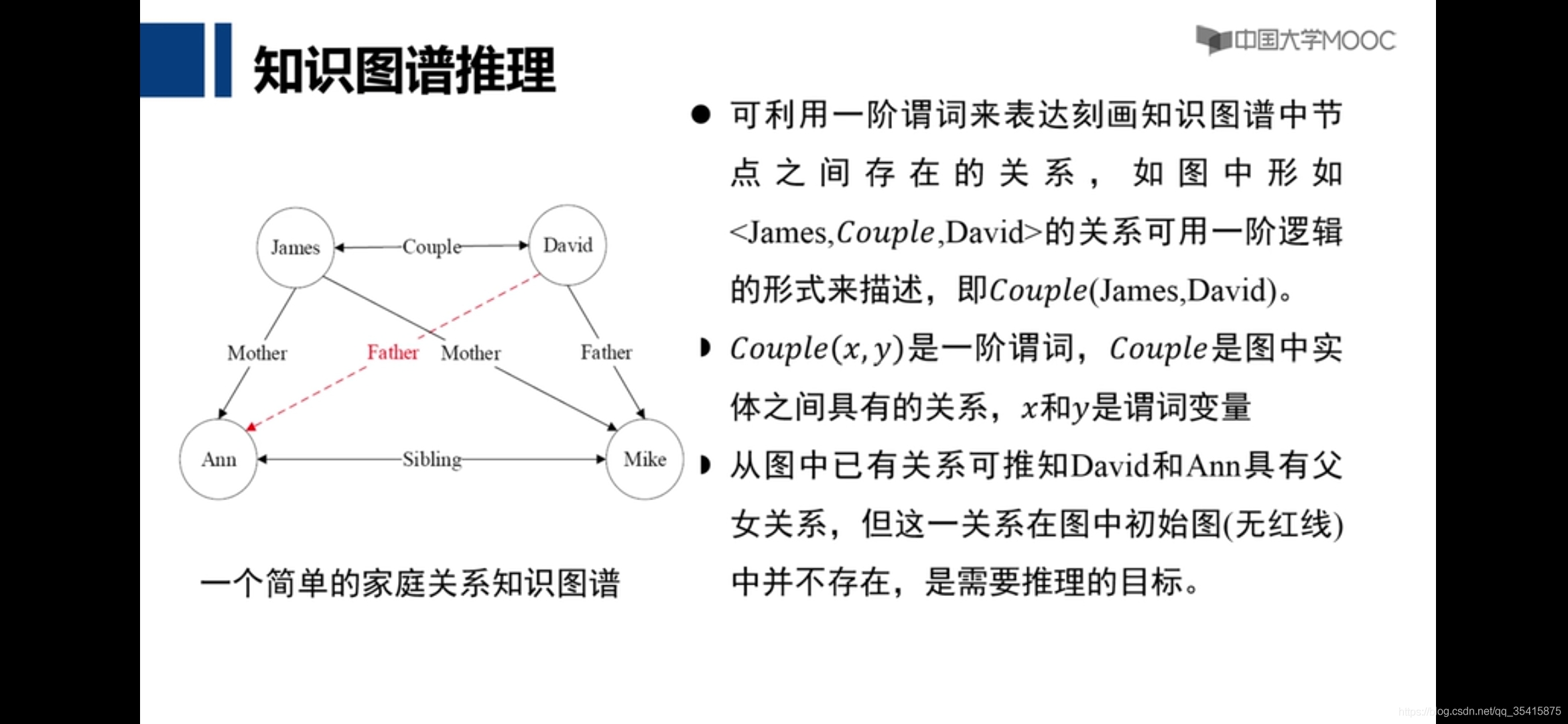
知识图谱
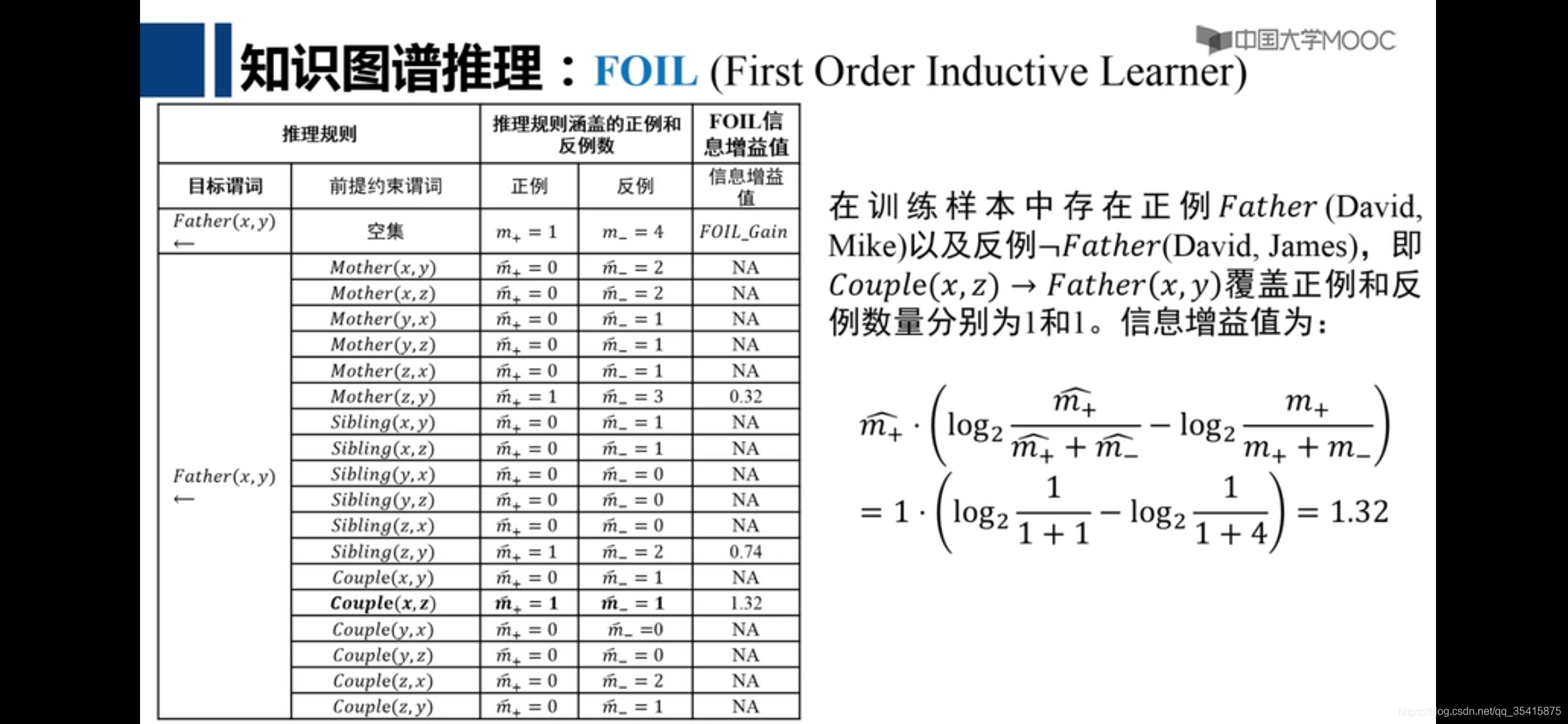
1.一阶归纳
归纳逻辑程序设计,机器自己从数据学习到新规则

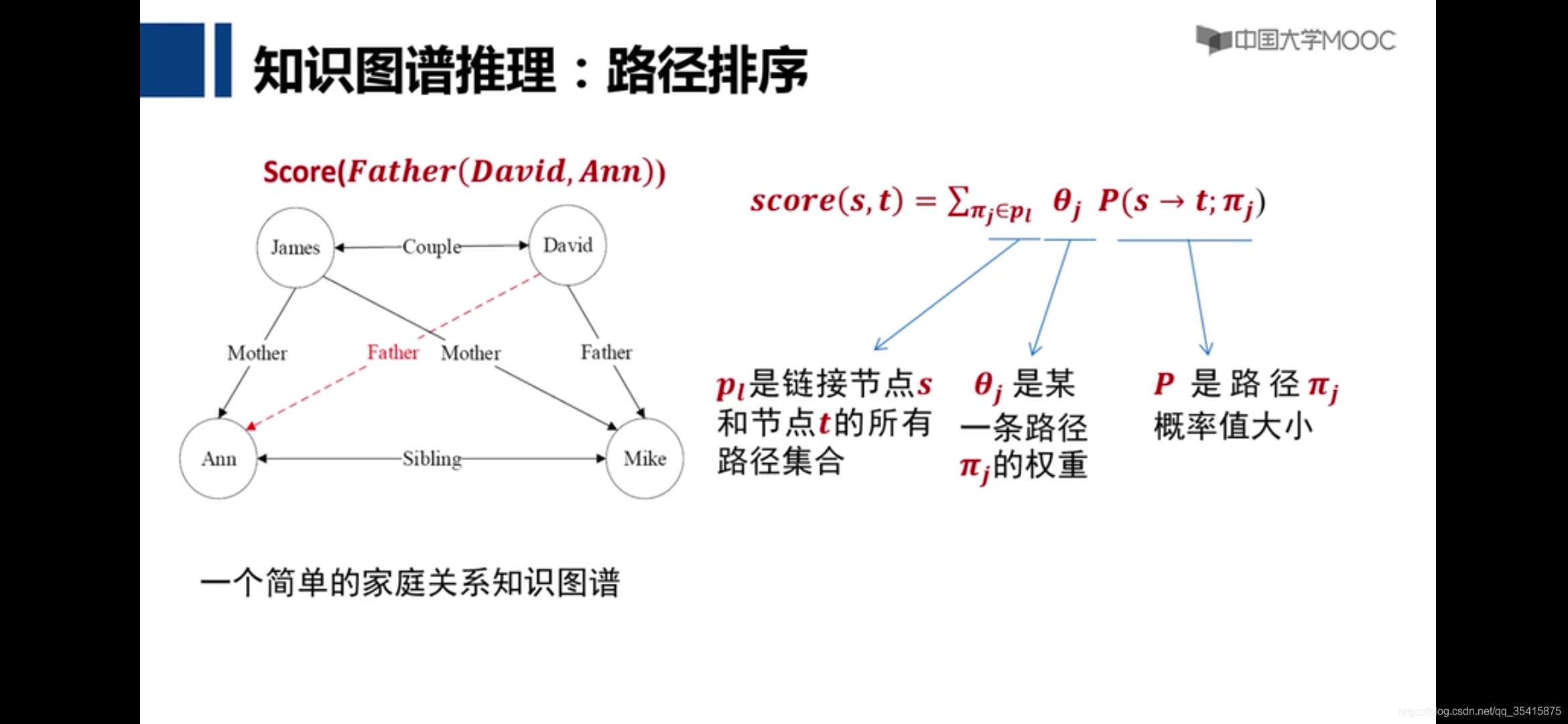
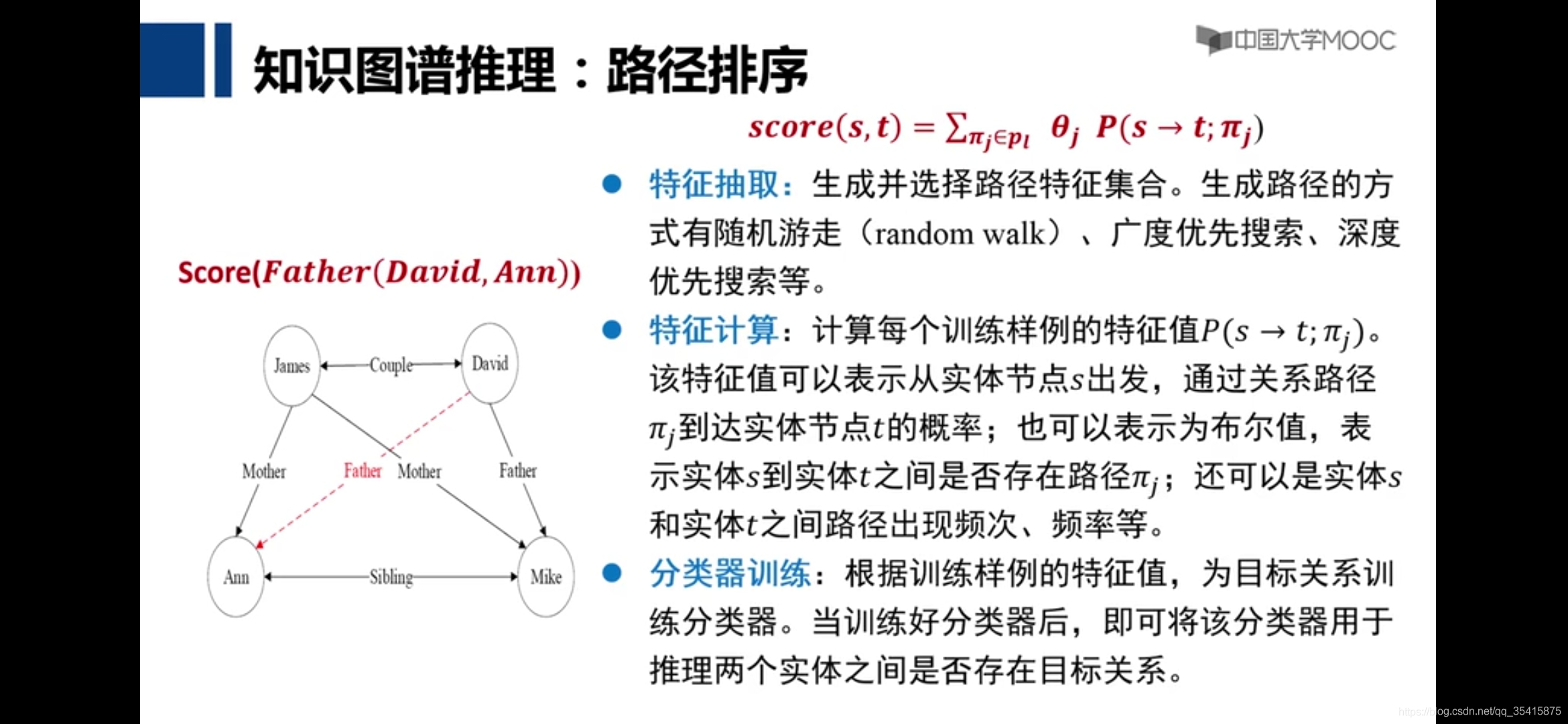
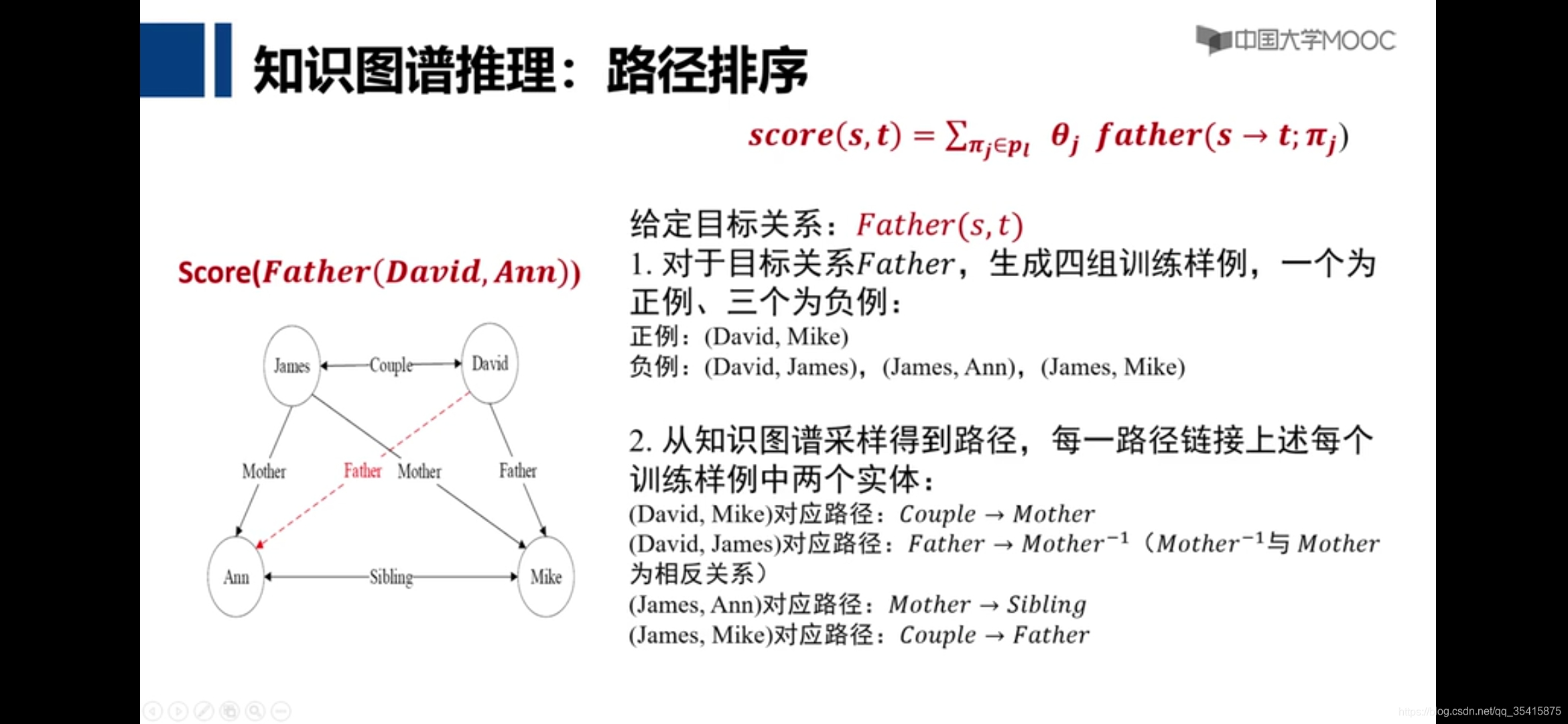
 路径排序
路径排序

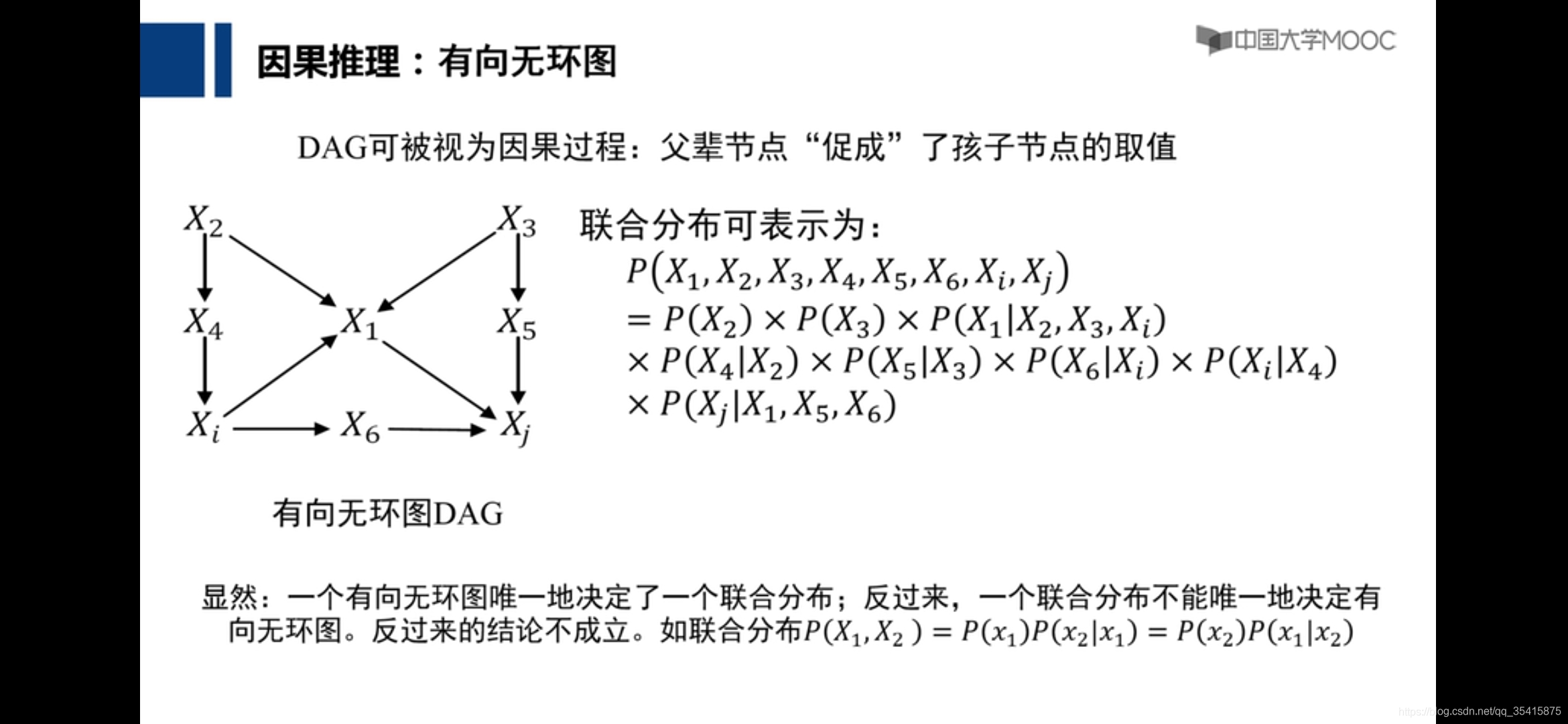
因果推理
有向无环图:

D-分离



可用正常无干预条件下的条件概率来计算干预后的条件概率




反事实推理

线性回归分析


提升算法(Ada boosting)








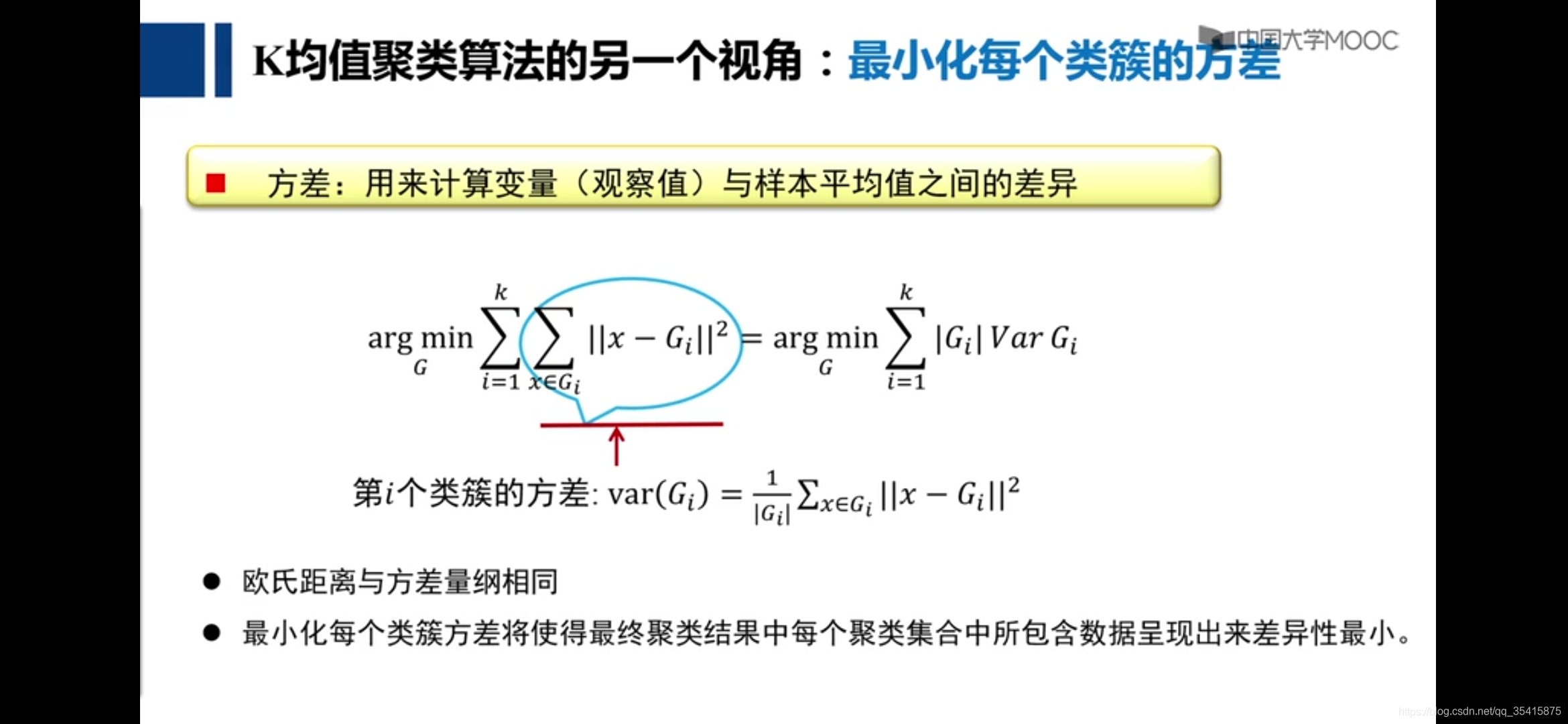
k均值聚类






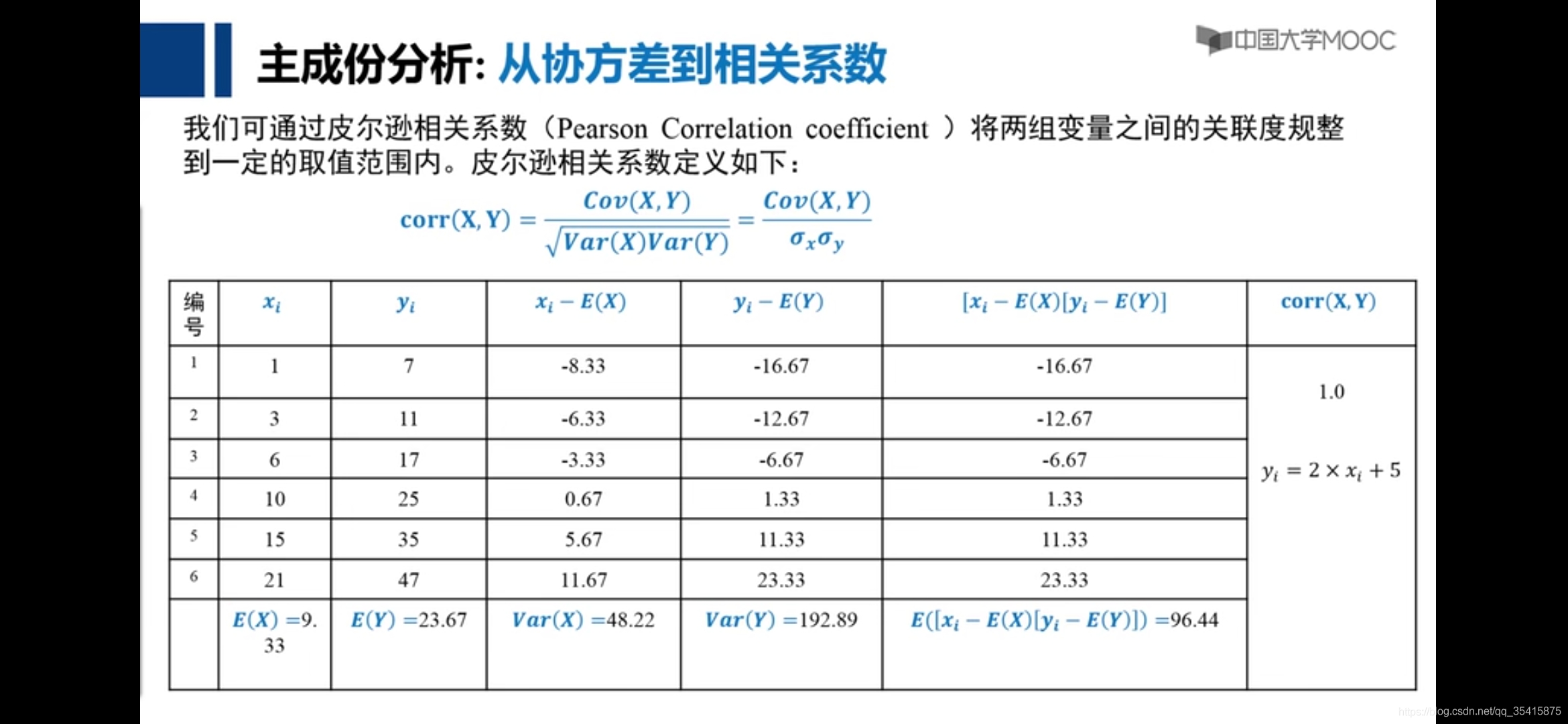
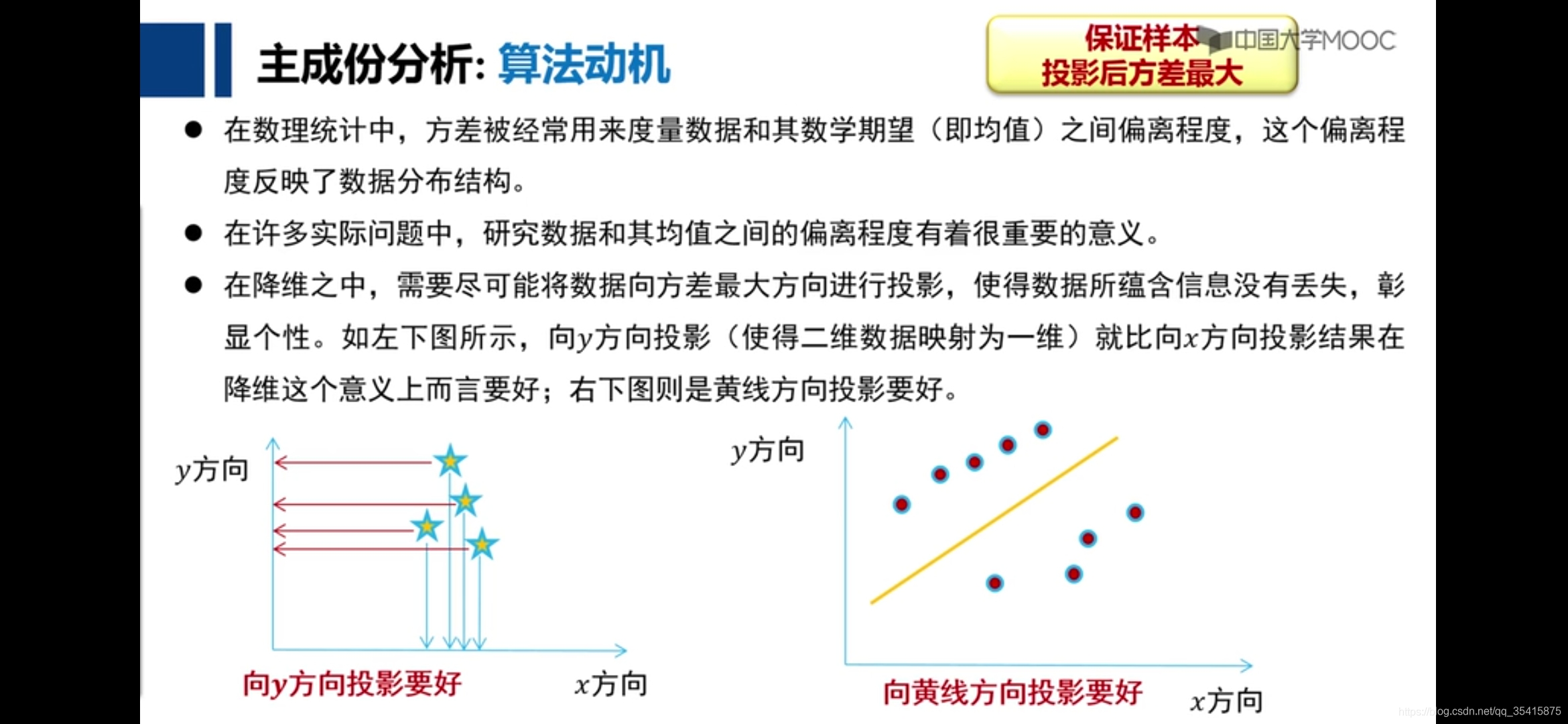
主成分分析(pca特征降维法)

协方差(高维数据的相关性):


皮尔逊系数:
var表示方差


PCA:

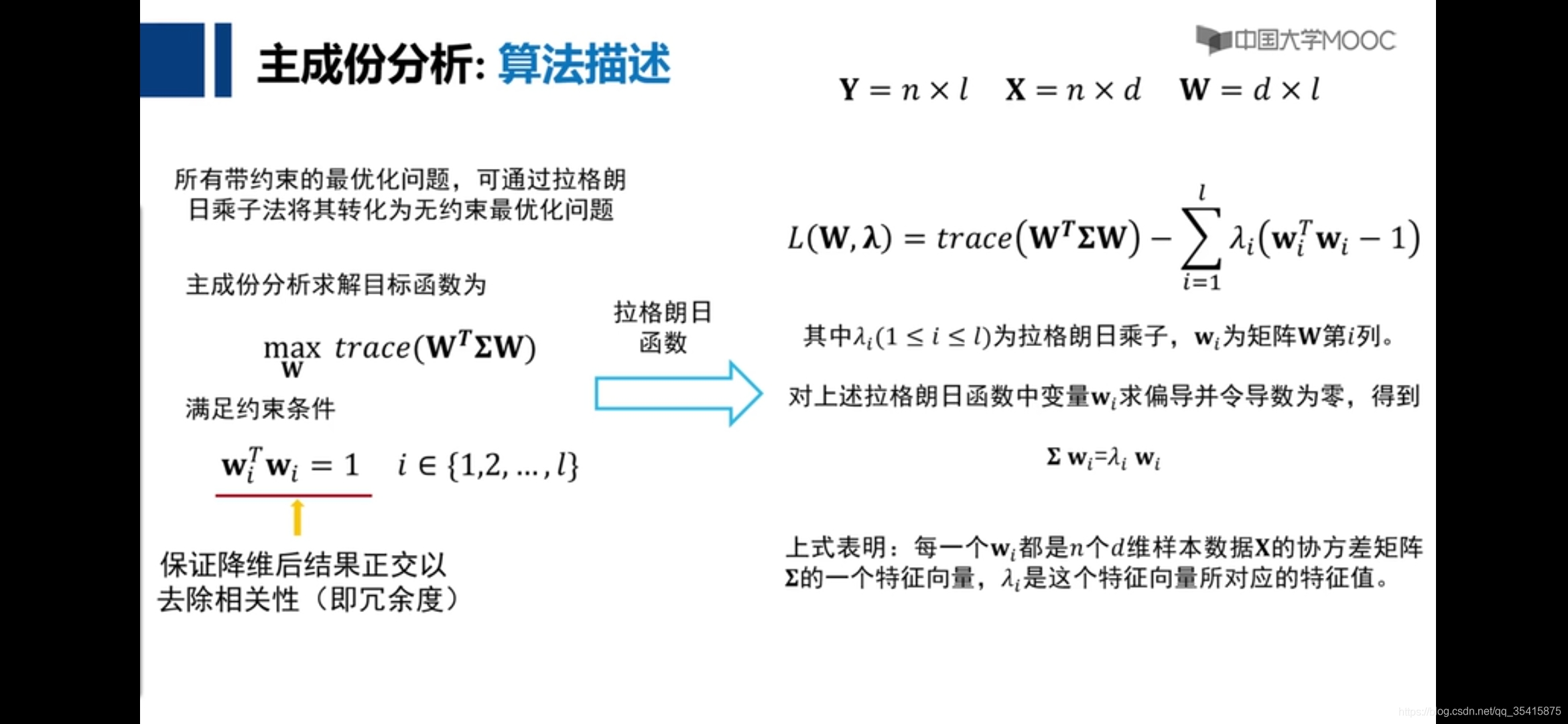
trace是提取对角线这布没懂


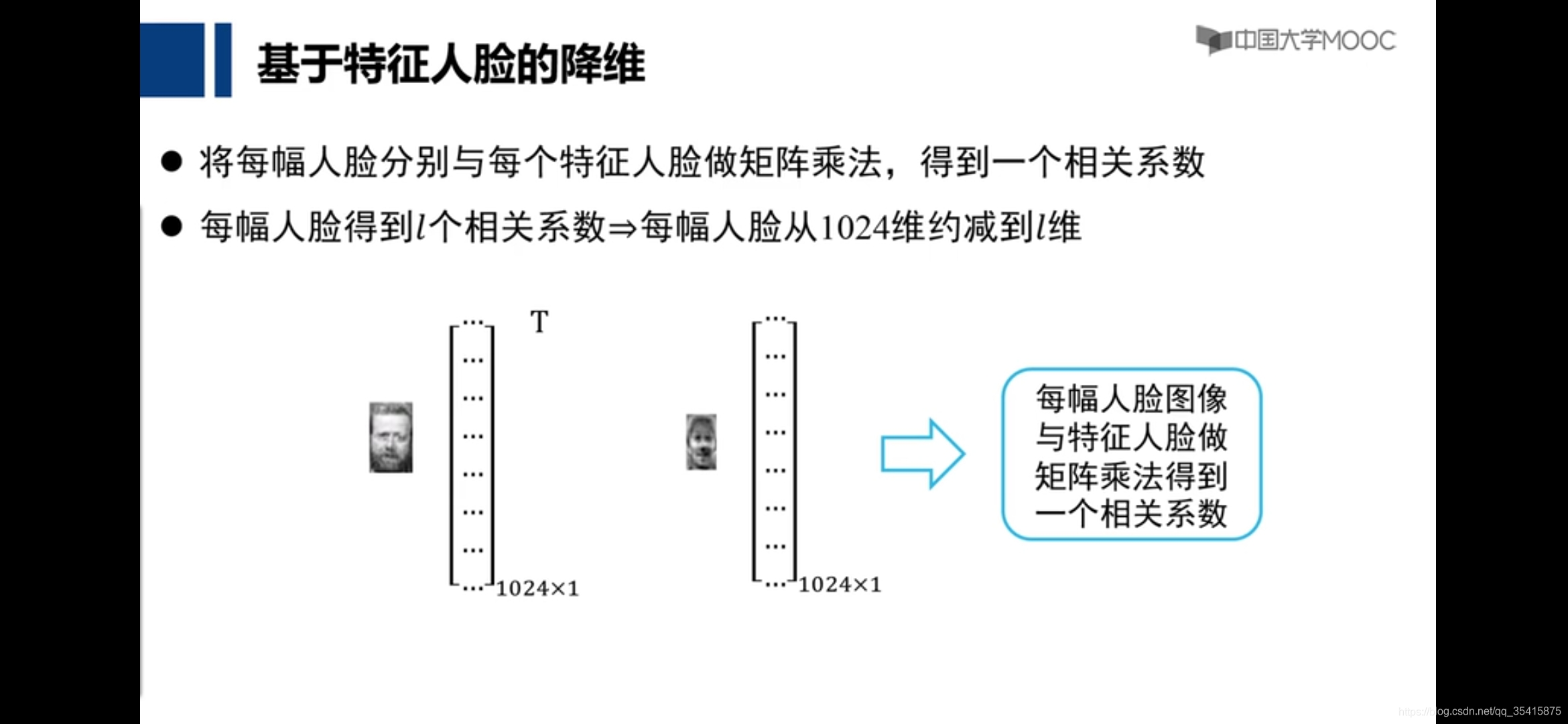
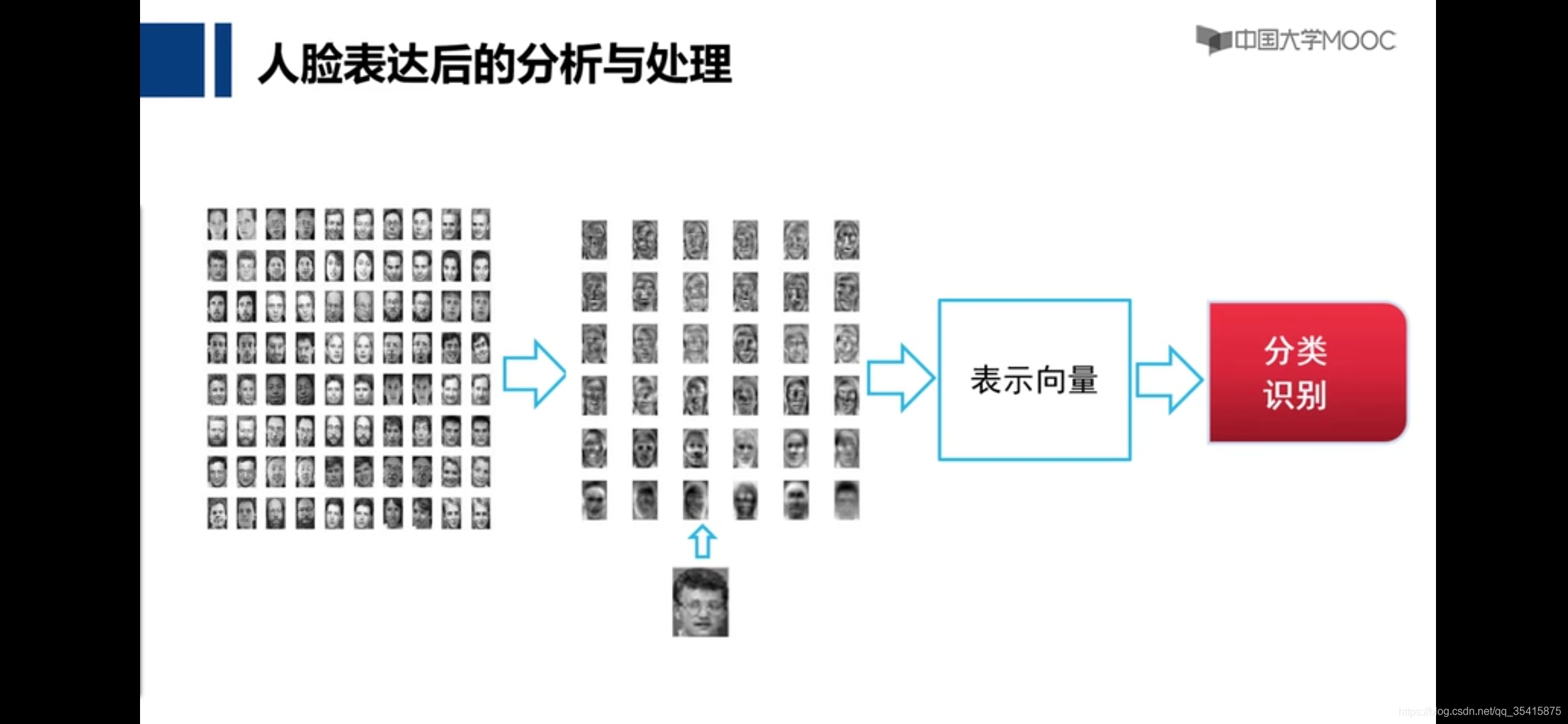
特征人脸算法


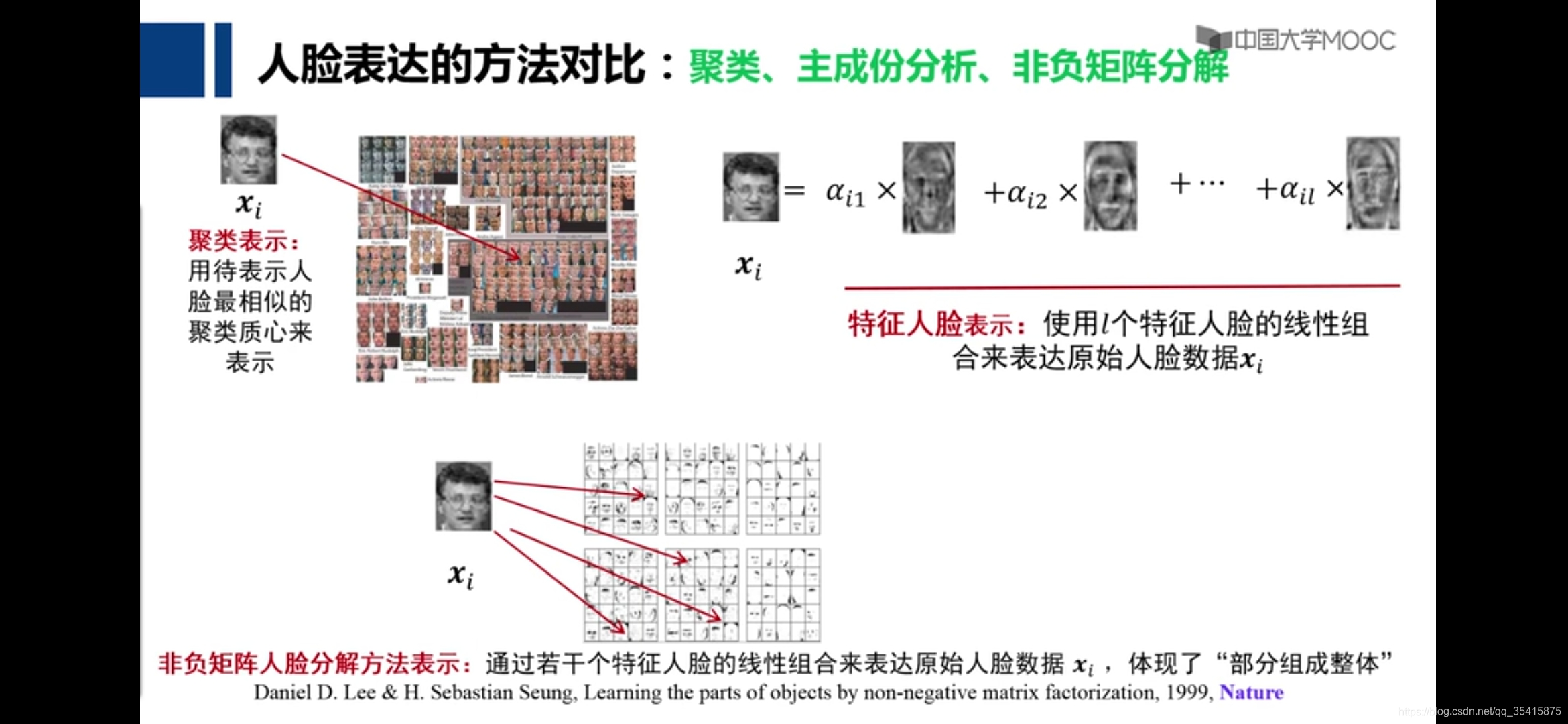
这里用系数α做比较可以理解,但是用其做为系数和特征人脸相乘线性累加变为人脸,似乎不对,不好理解?
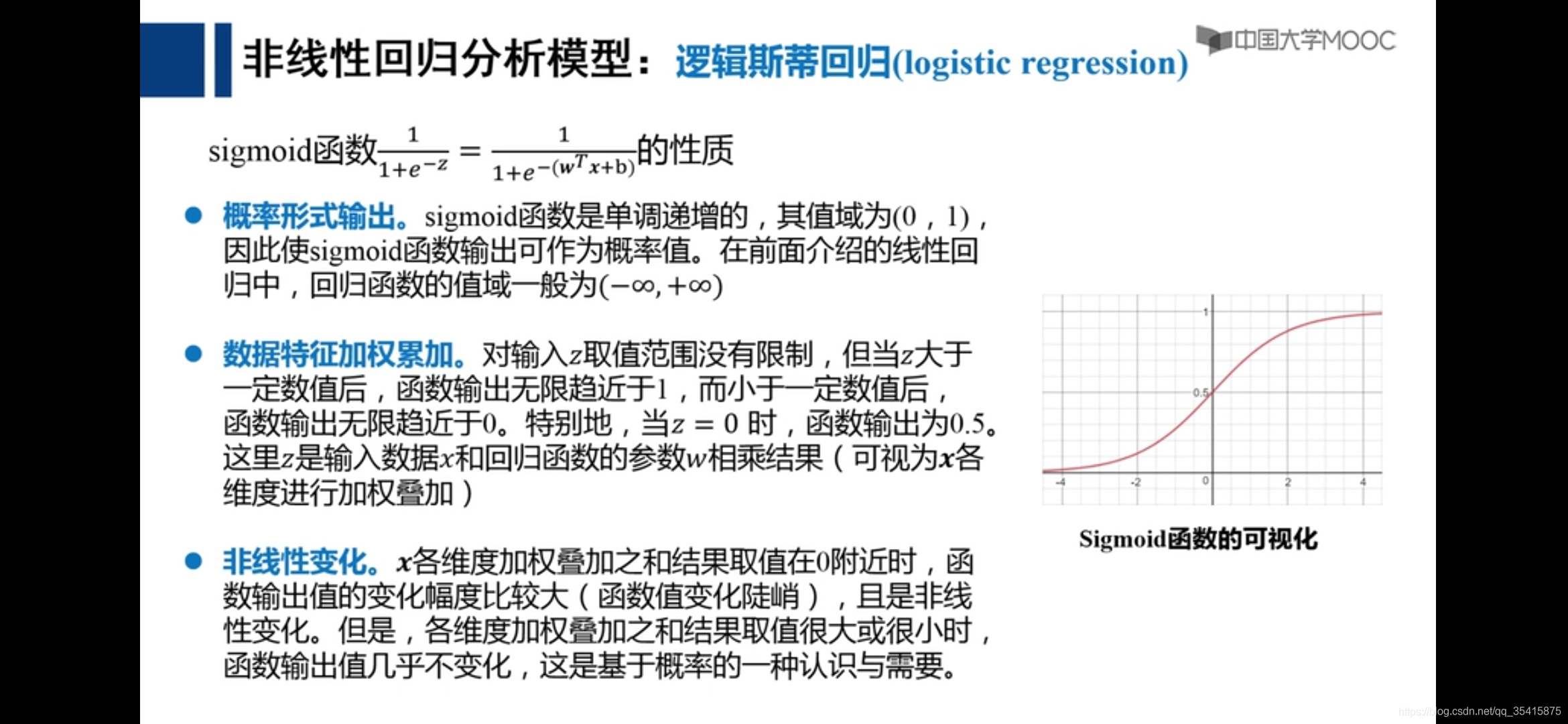
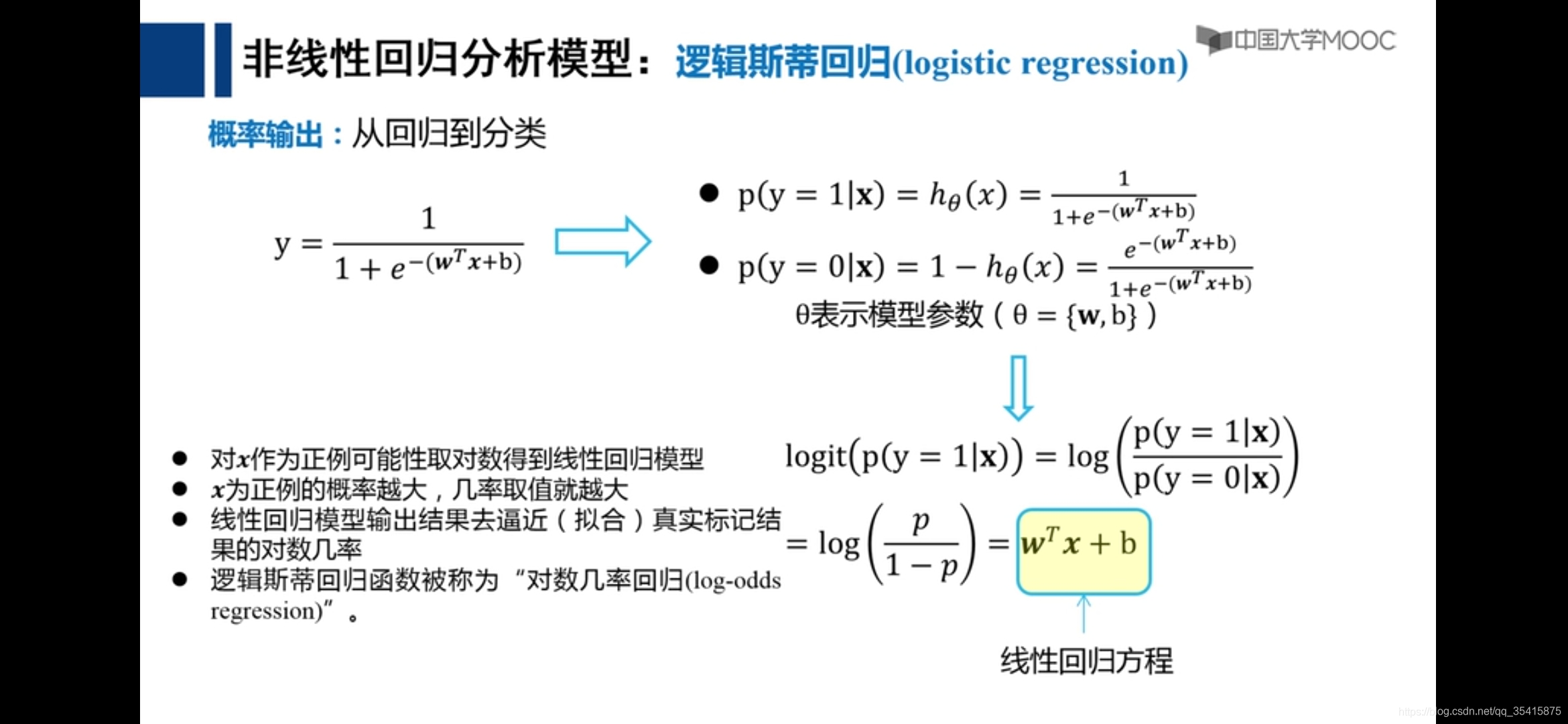
逻辑斯蒂回归与分类
理解交叉熵函数为什么可以做为优化参数权重w和b的损失函数,由下图式子可以得知,当y=1,时即,当输入x为正例时,要想-log(hθ(xi))最小,即hθ(xi)最大,即概率p(y=1|x)最大,符合y=1,x是正例这个事实,训练成功,反之y=0,同理。
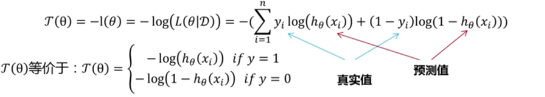

x与w相叉乘是一个实数,且w相当于权重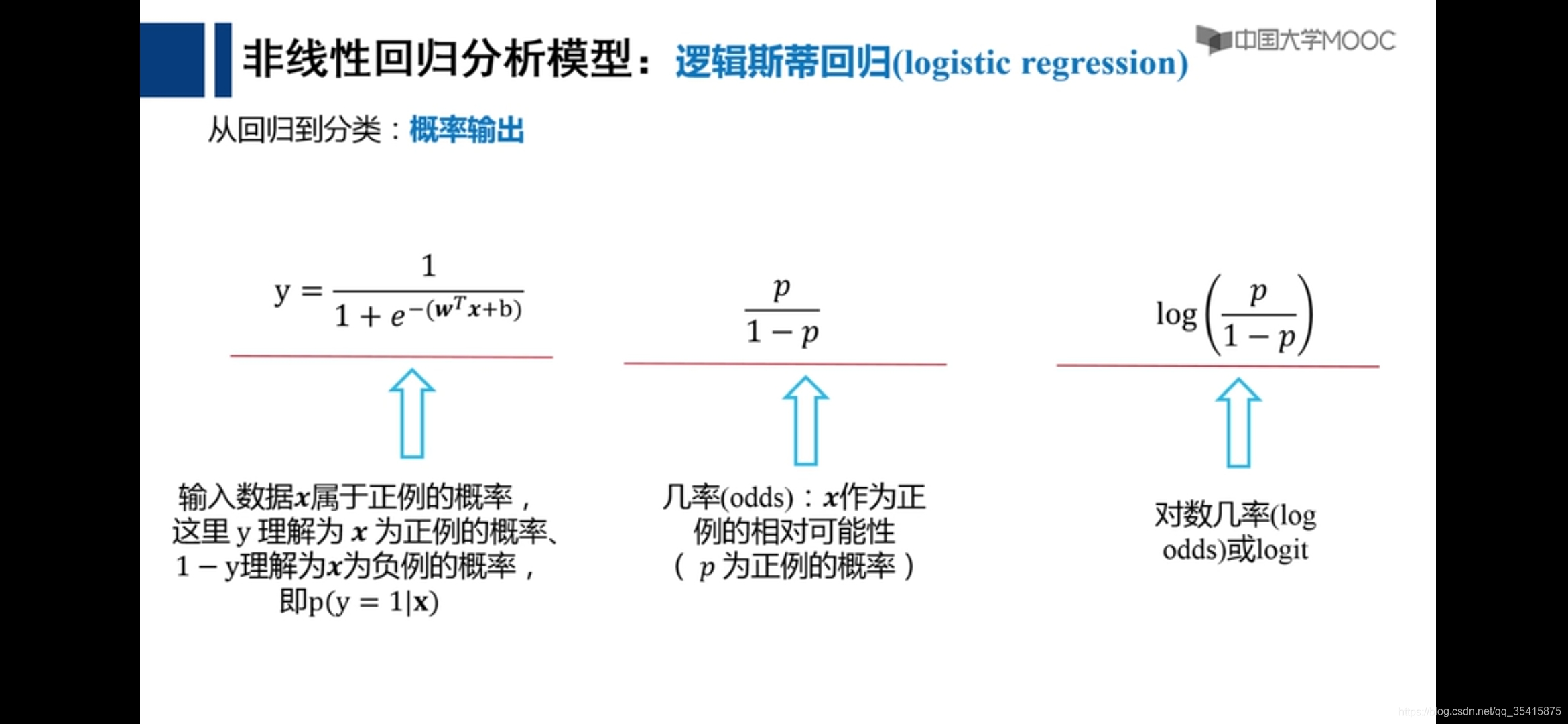



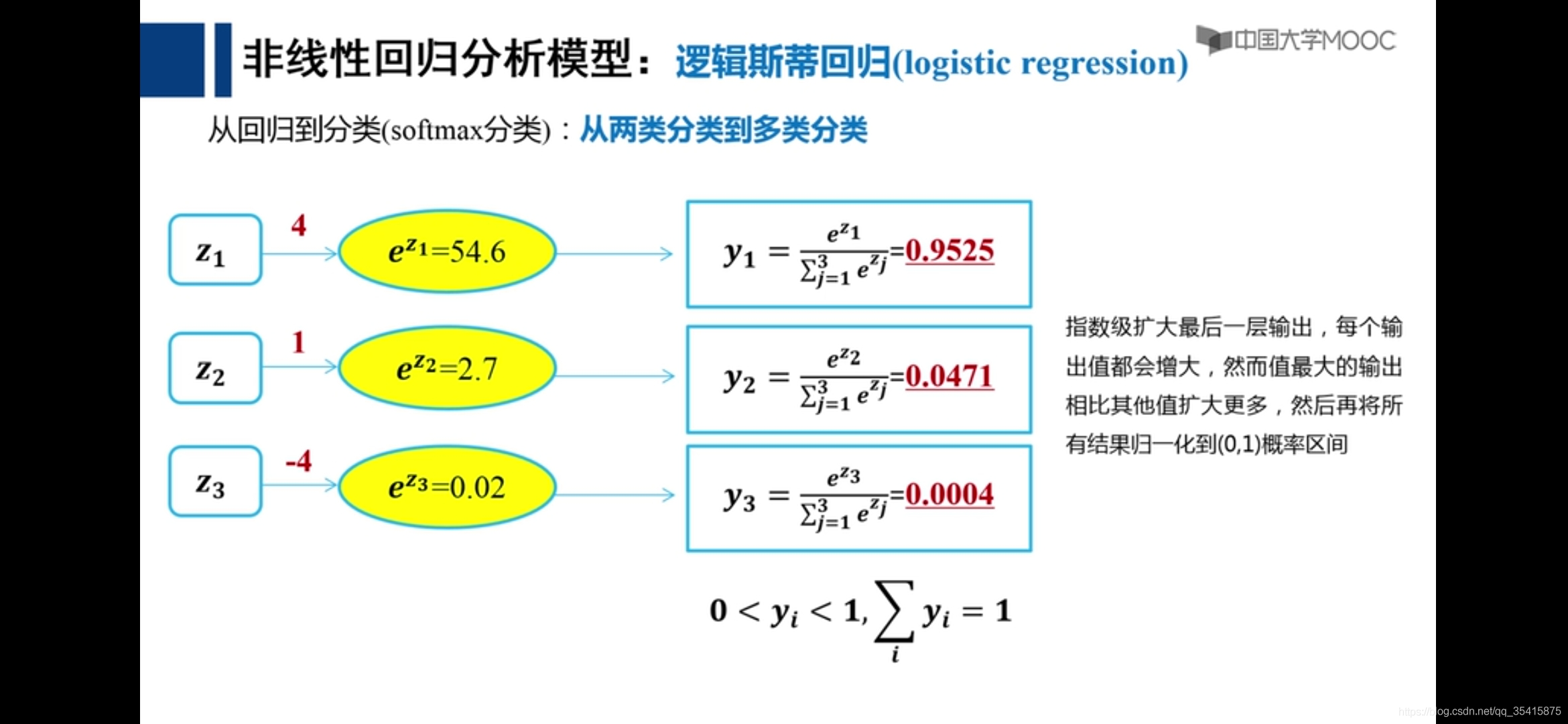
潜在语义分析
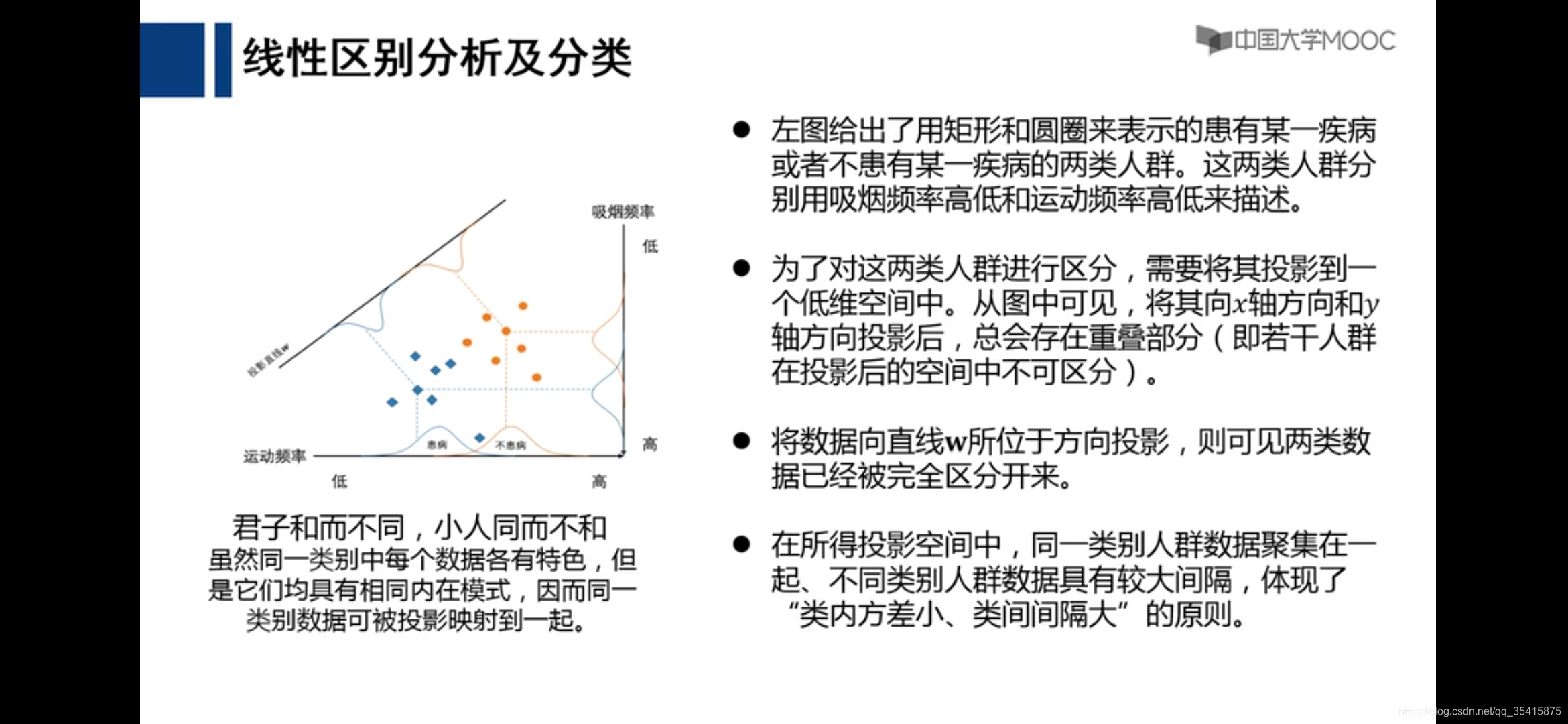
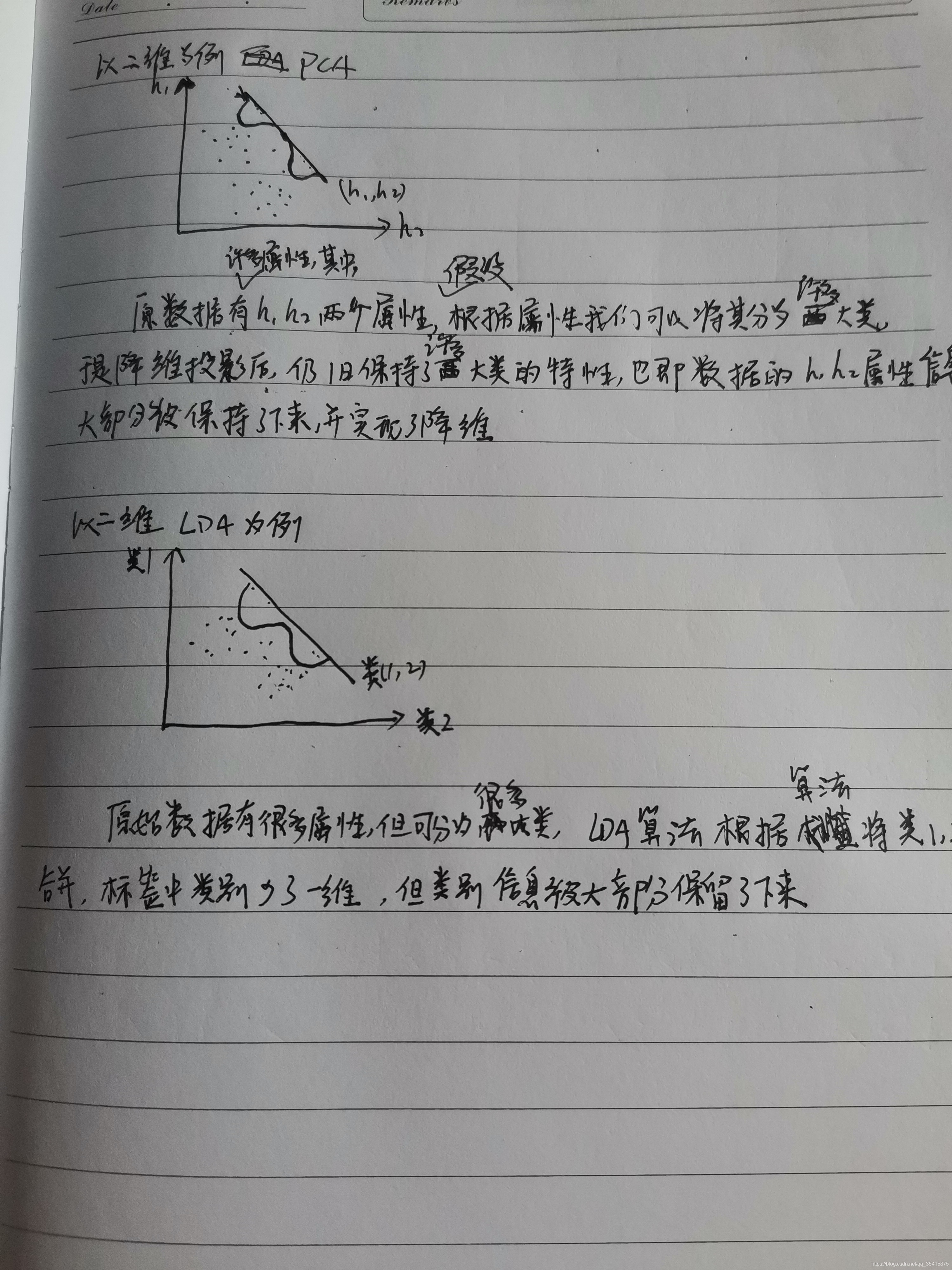
线性区别分析及分类(LDA监督学习降维法)





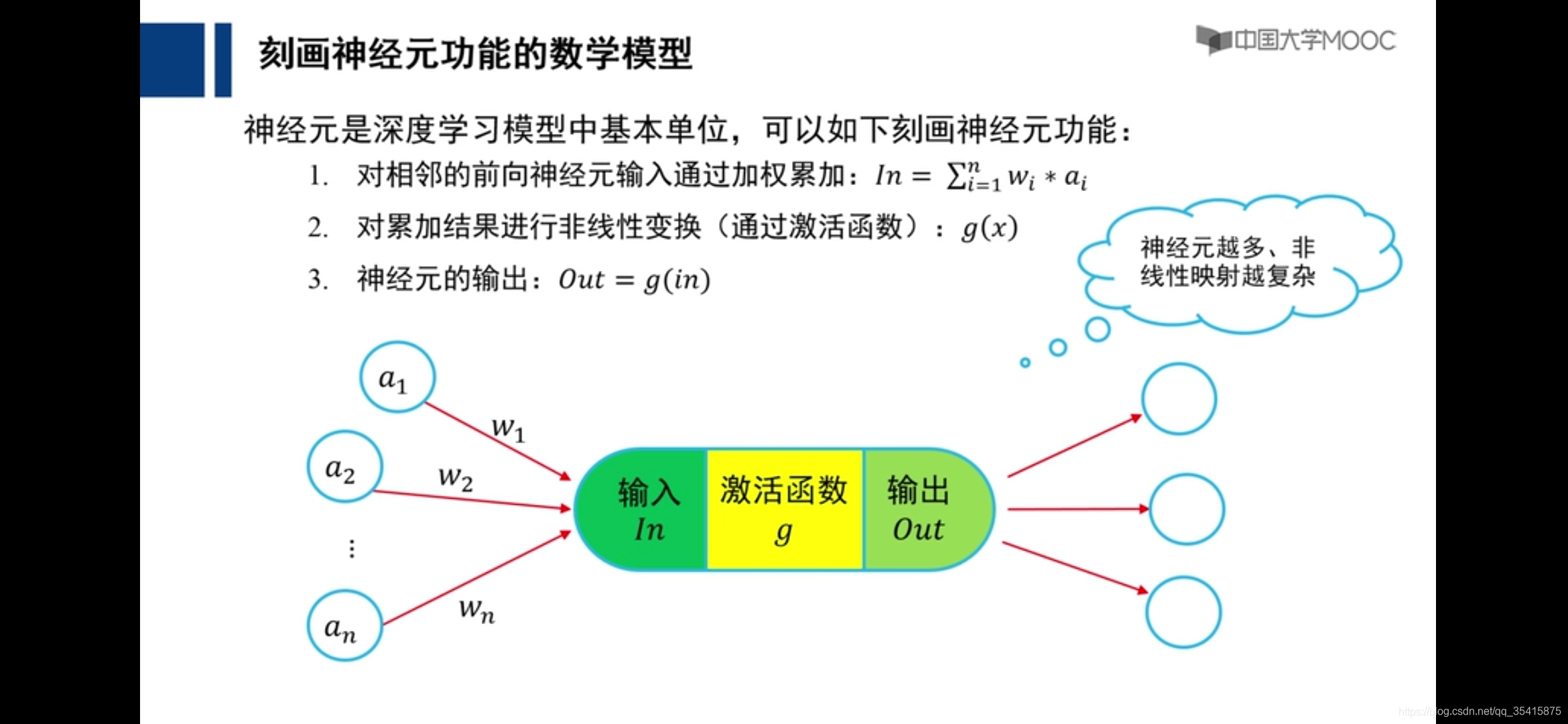
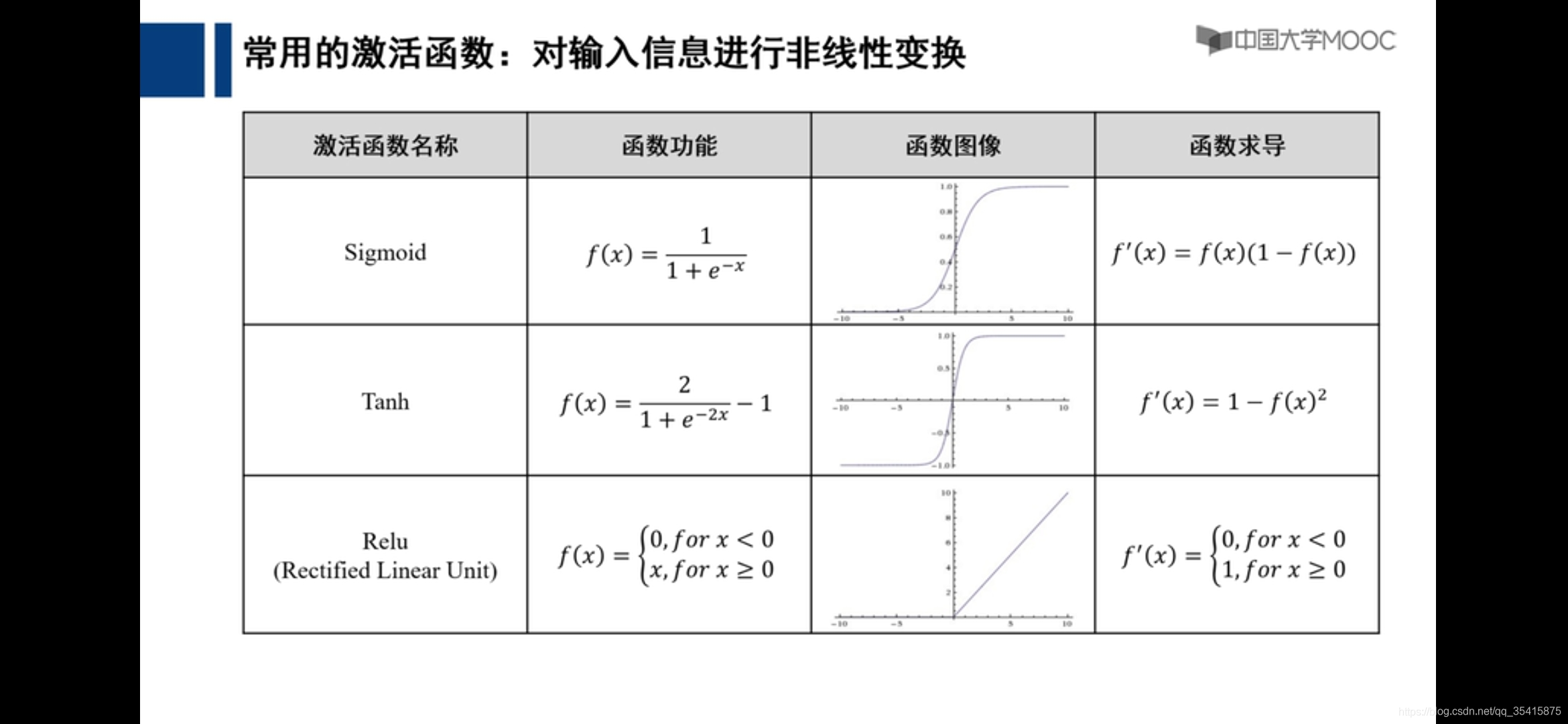
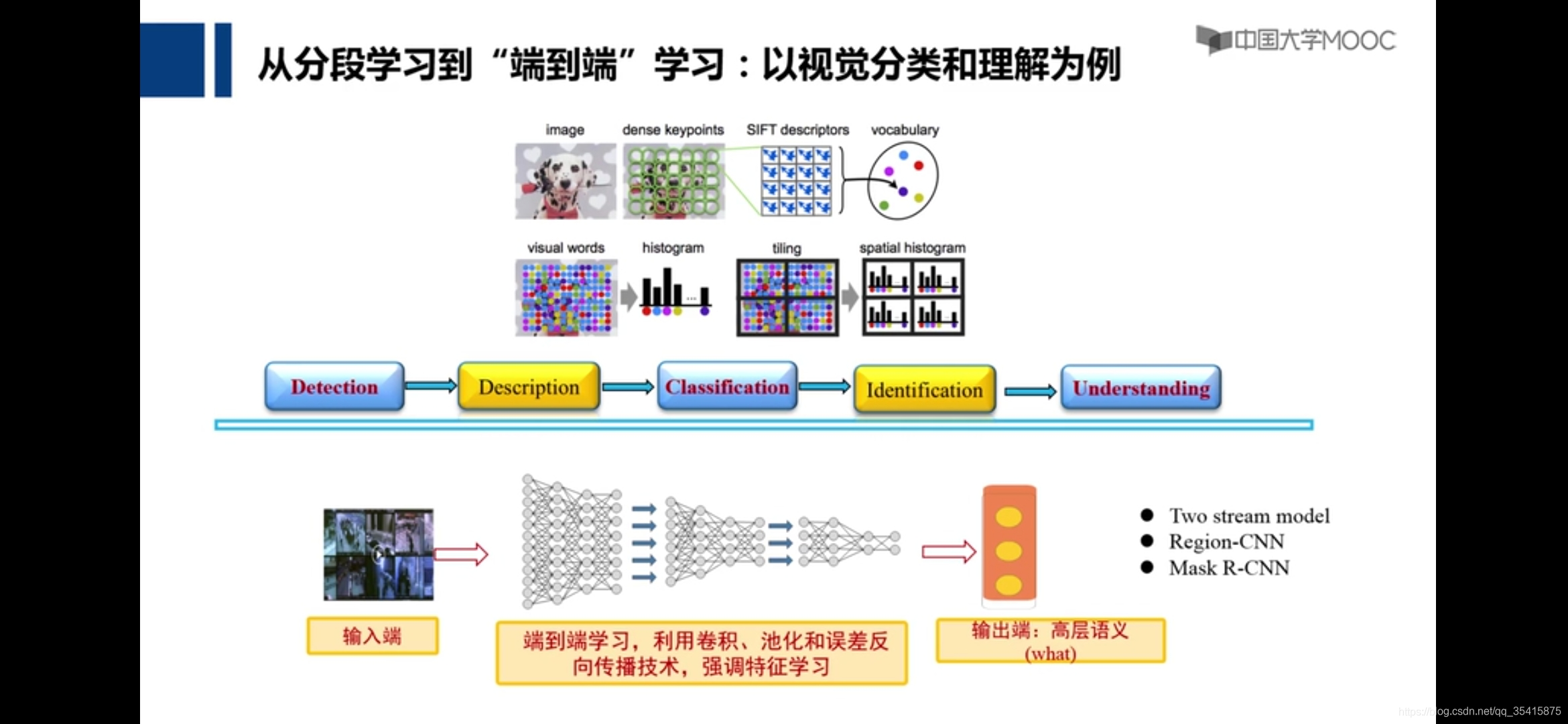
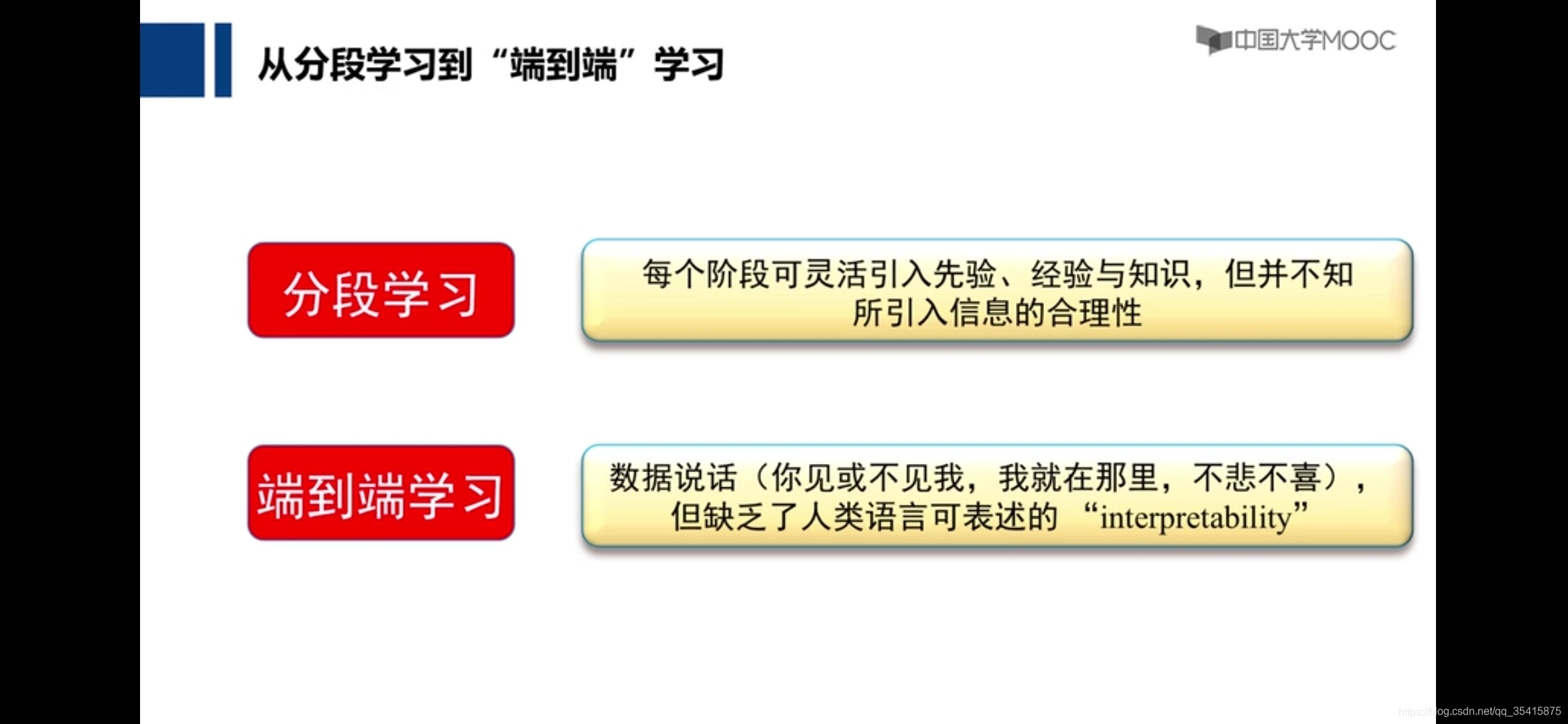
深度学习基本概念
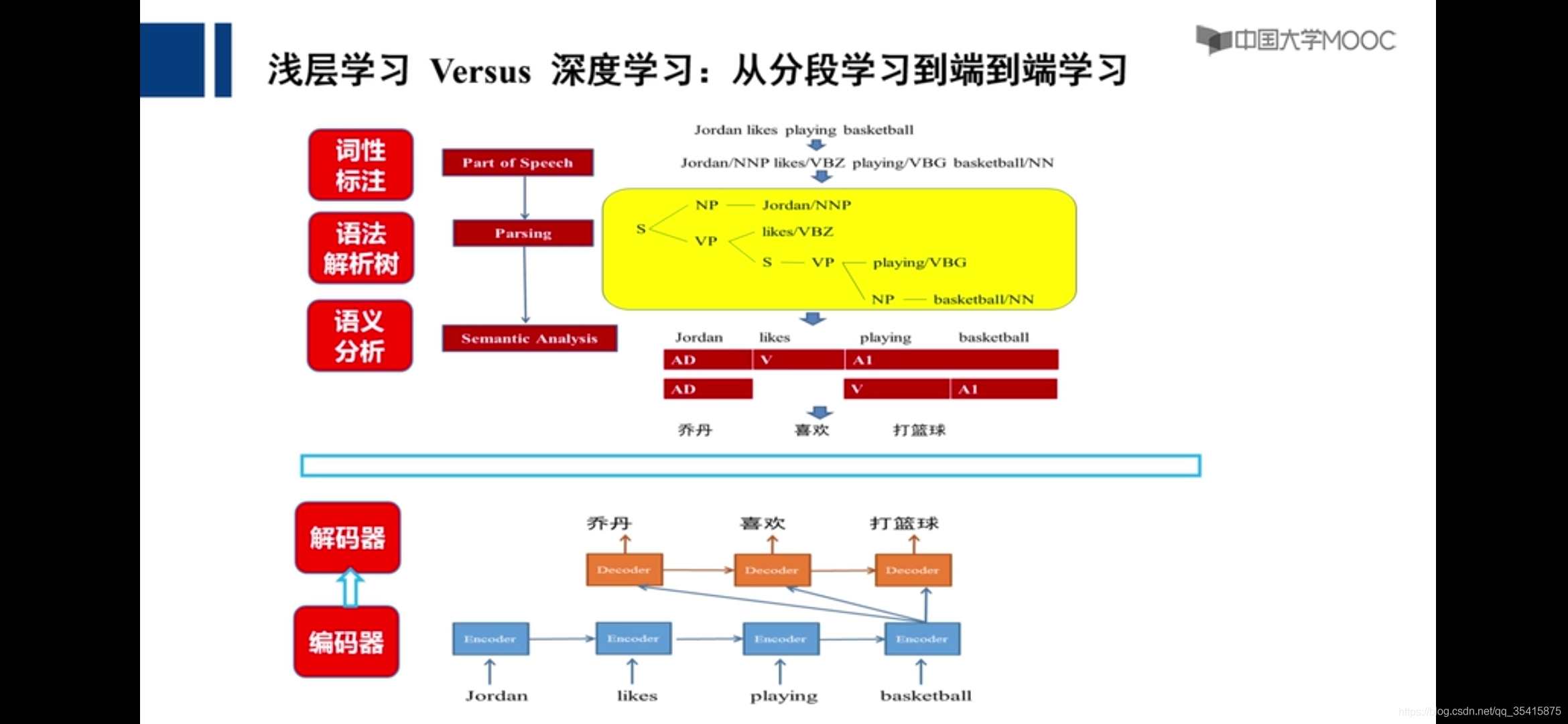
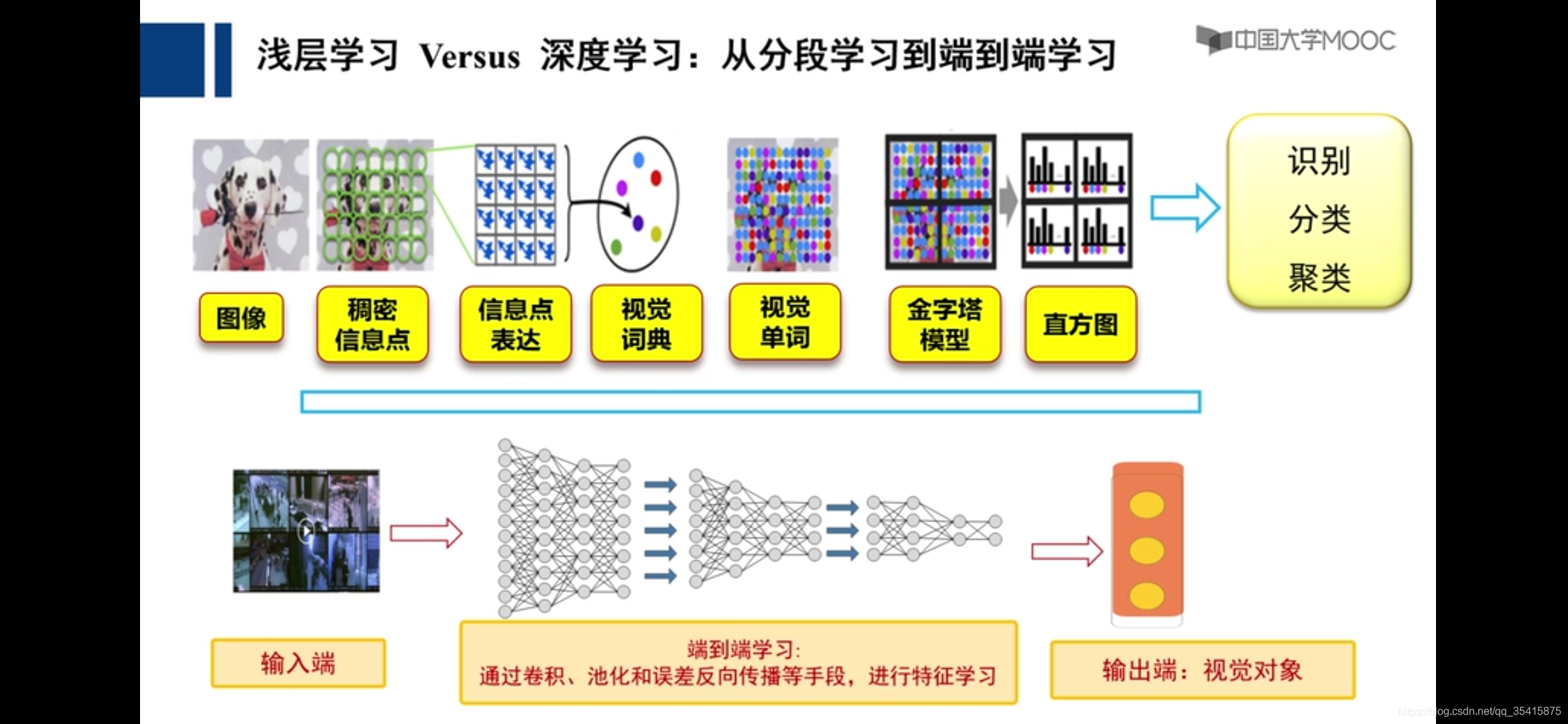
浅层学习:每个阶段可采用更好的函数
深度学习:端到端
像素点空间——>像素点组成的线条——>视觉对象——>视觉语义
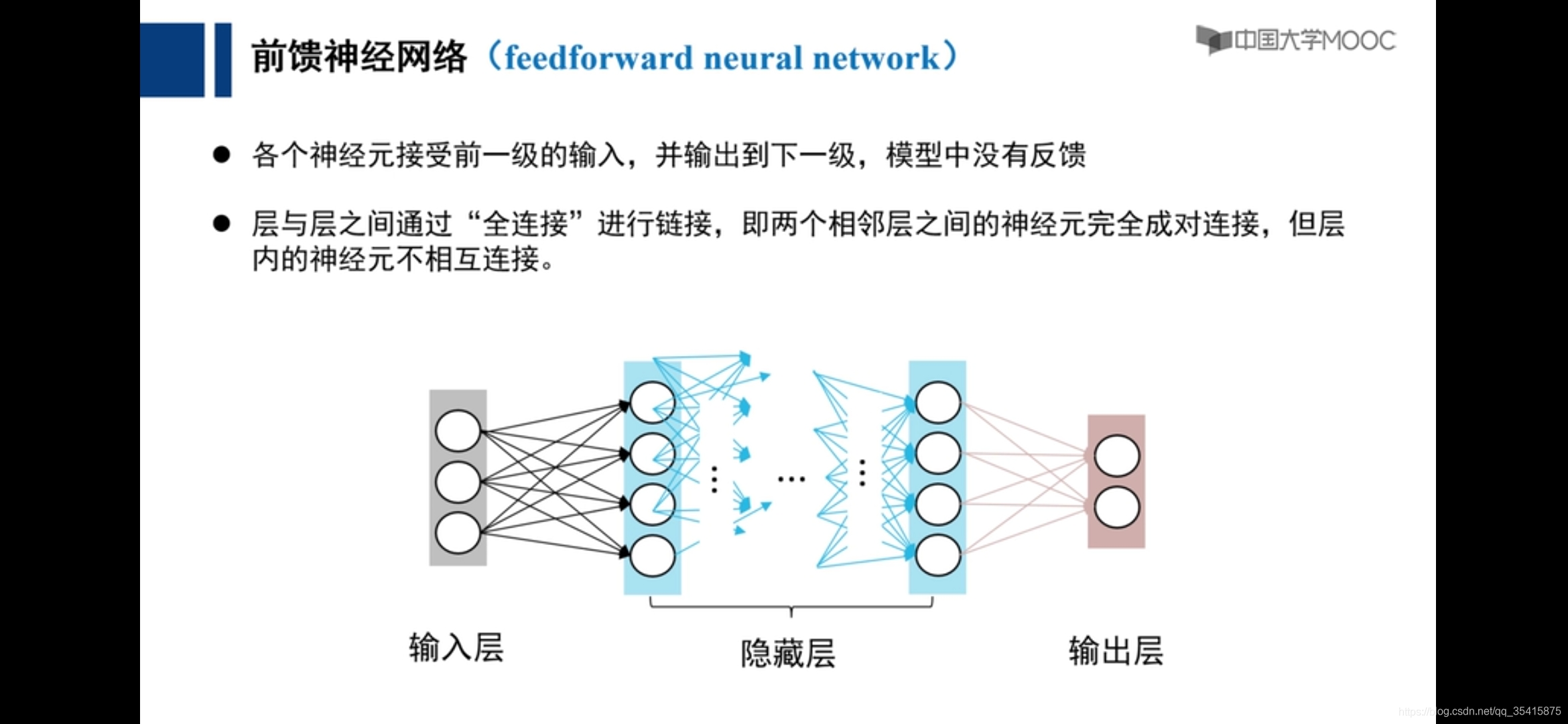
关于前馈神经网络,反馈神经网络,前馈网络的误差向后传播(BP)的区别链接: link.
前馈神经网络
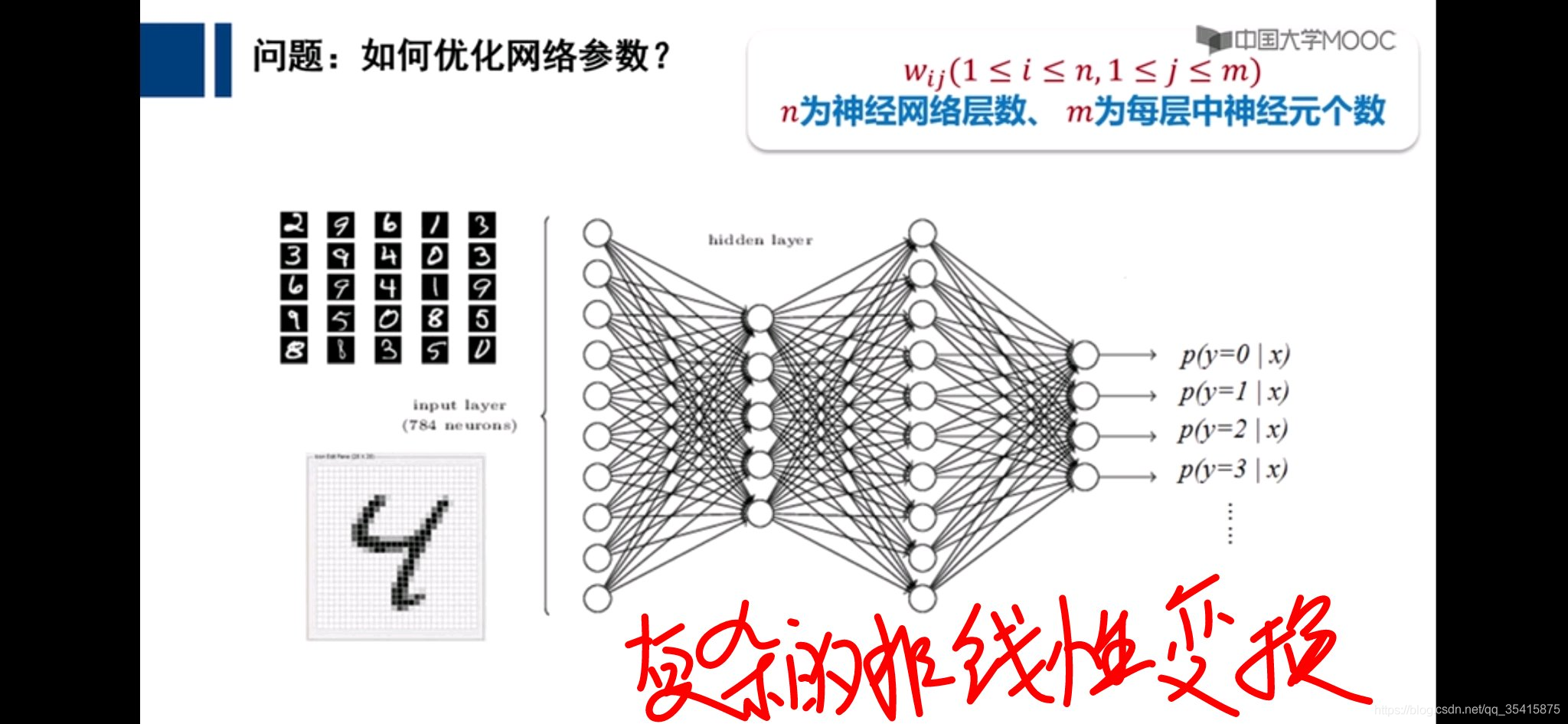

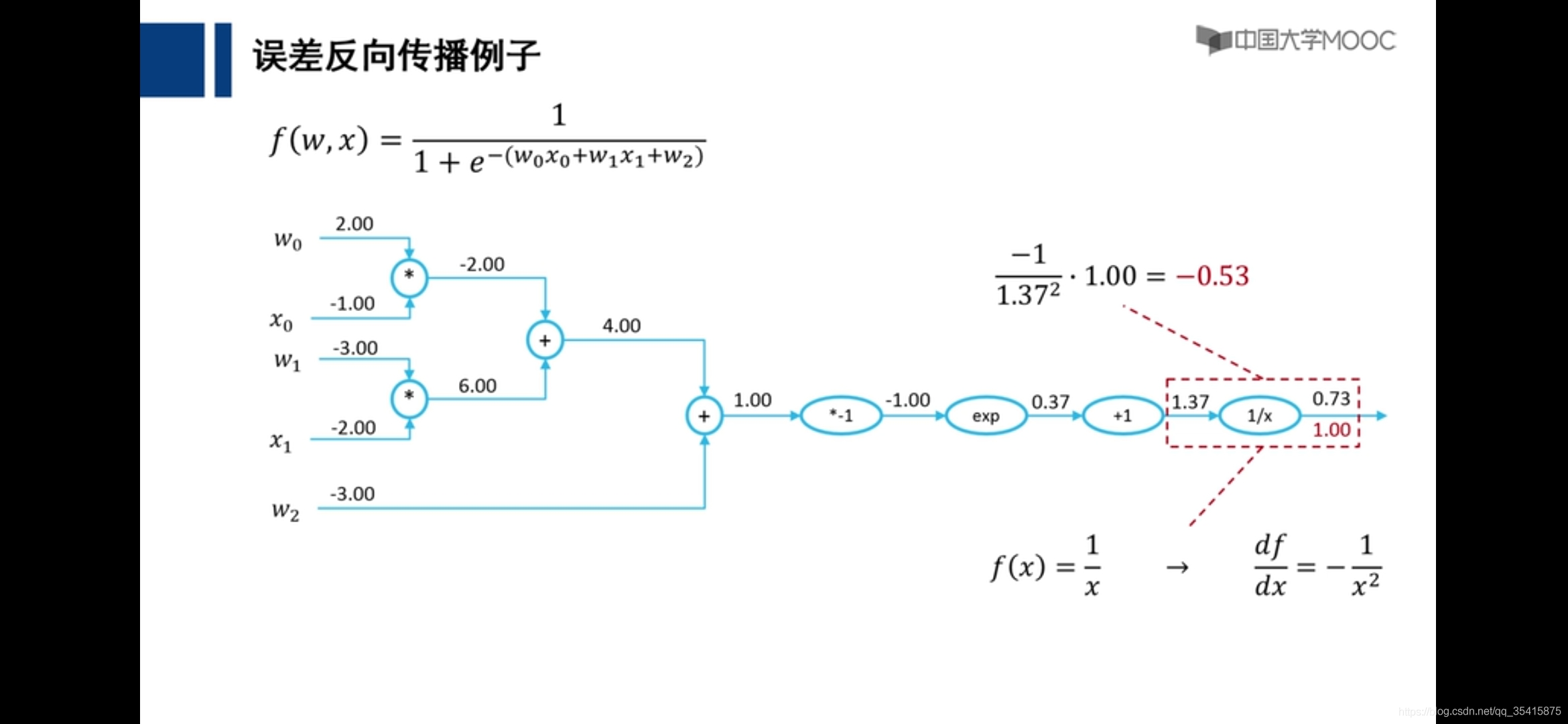
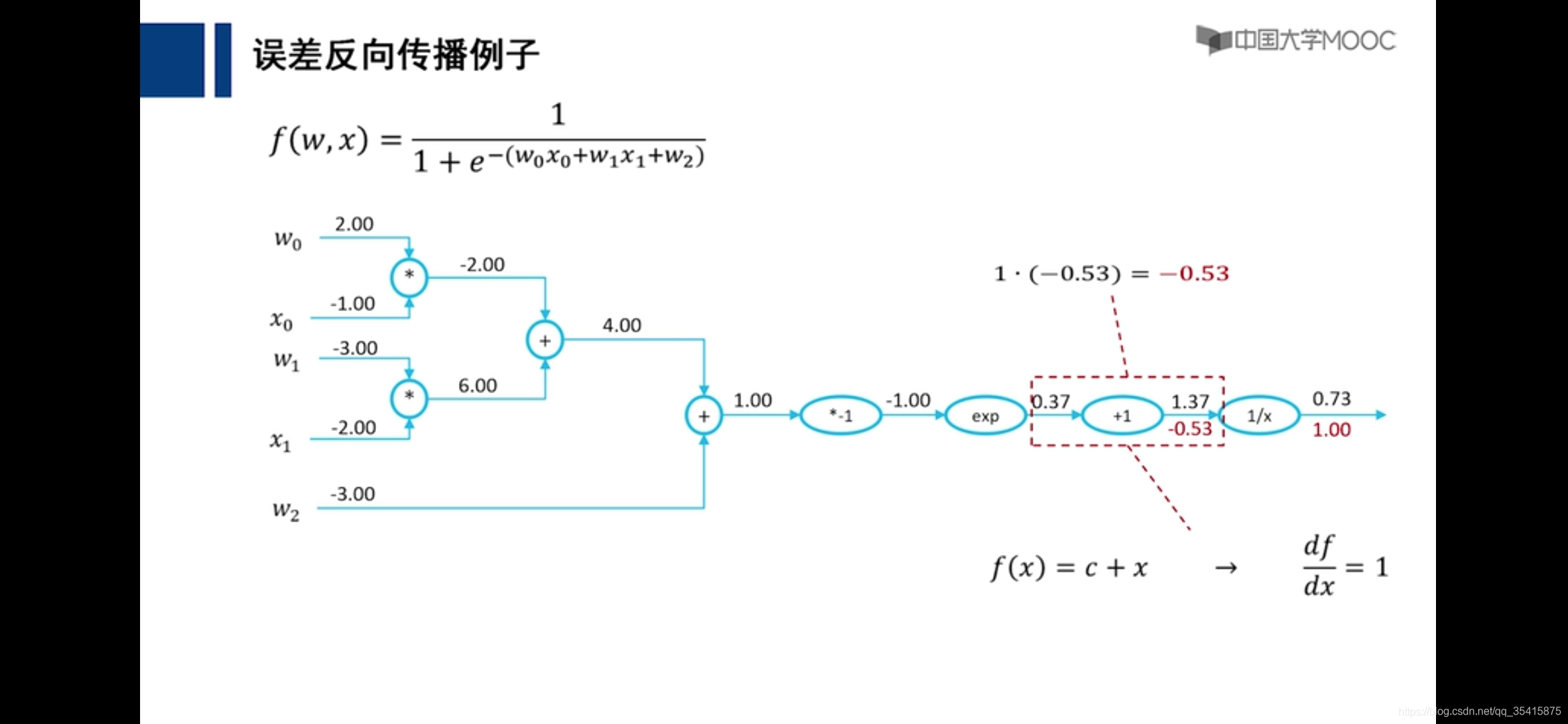
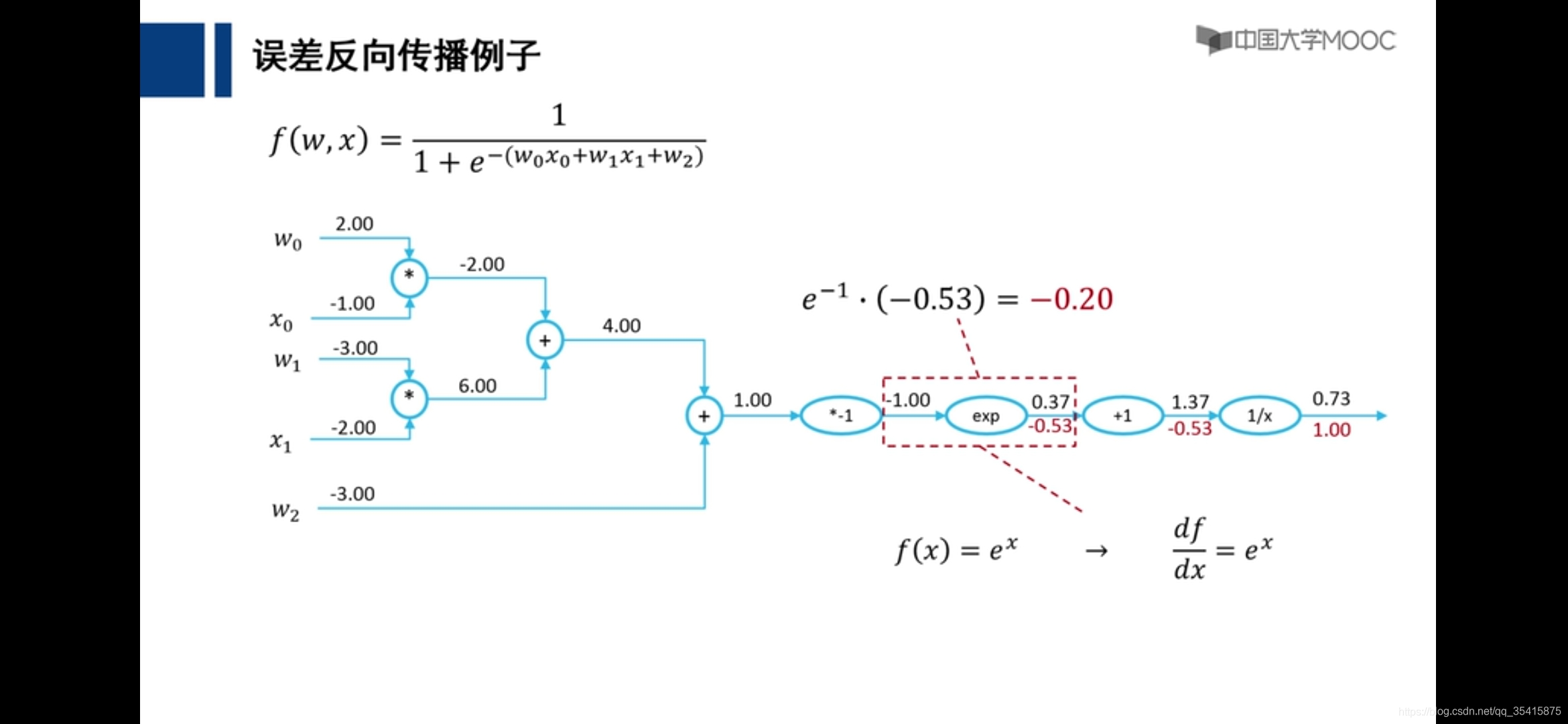
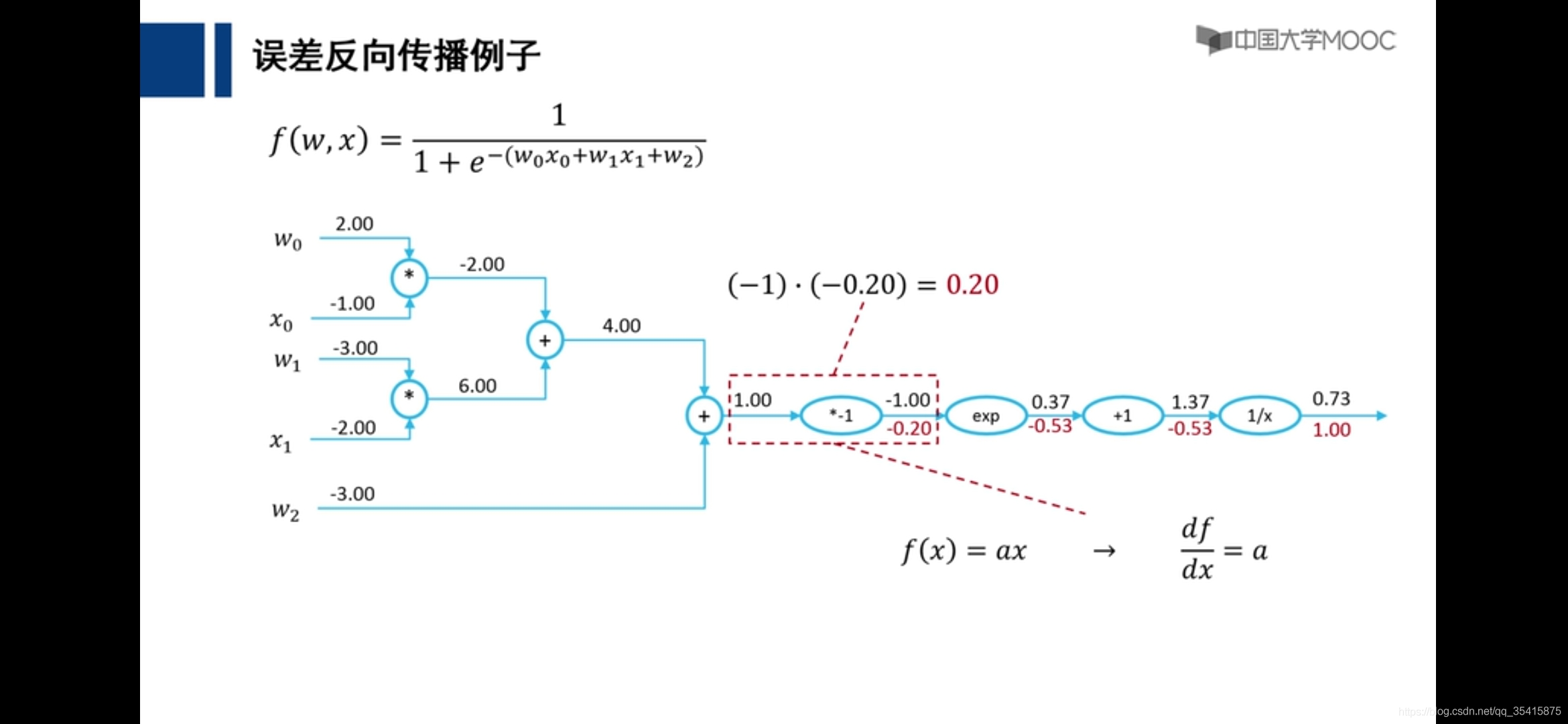
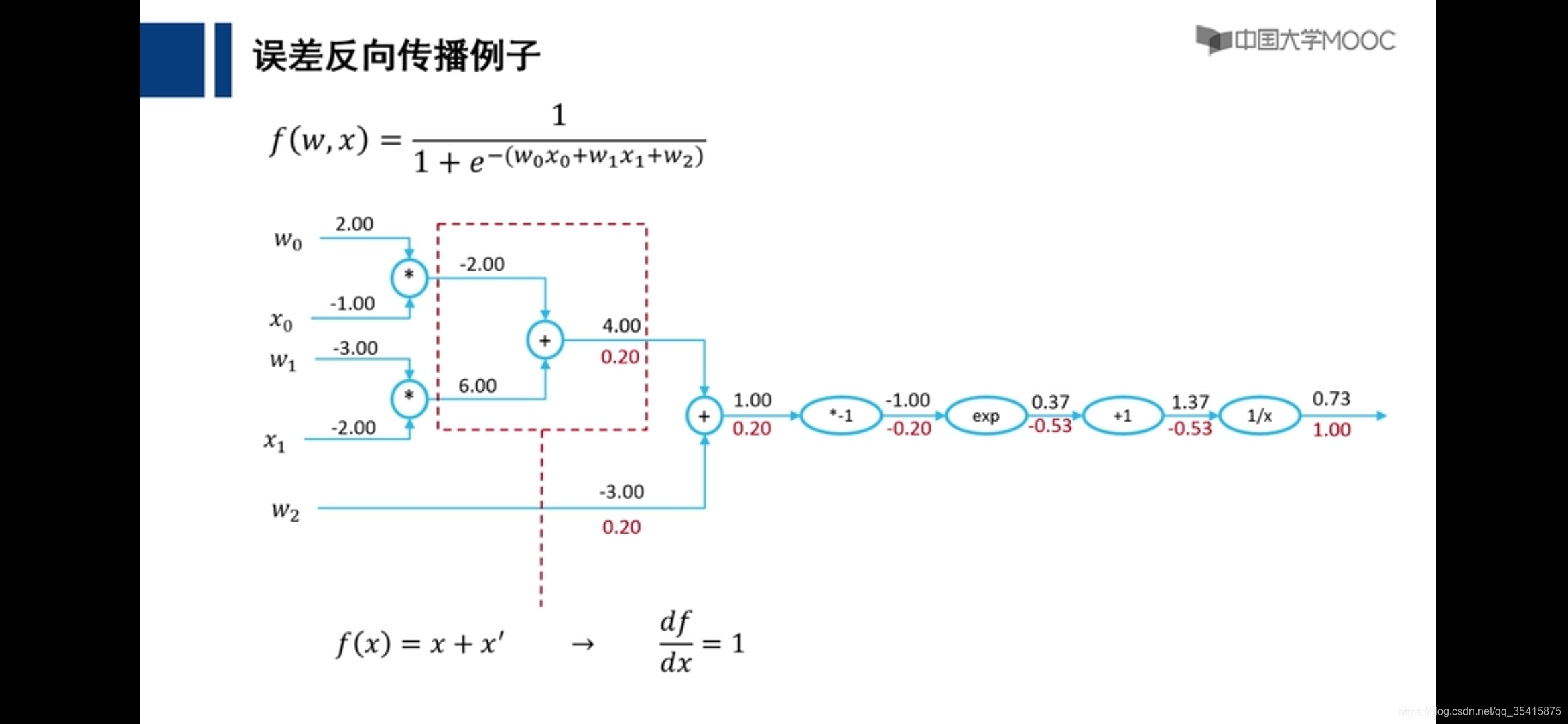
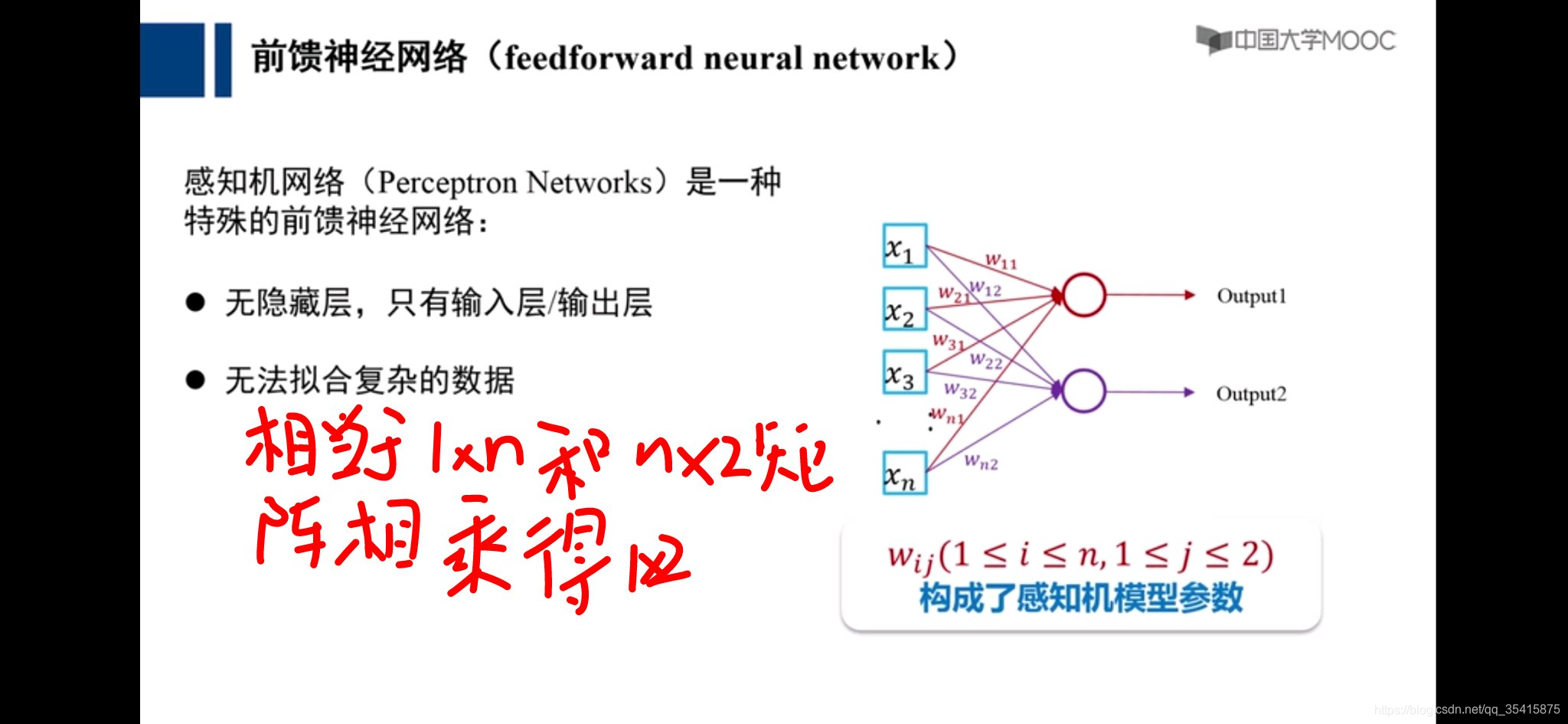
红色数字为该部分应当为结果相差1,所应该承担的
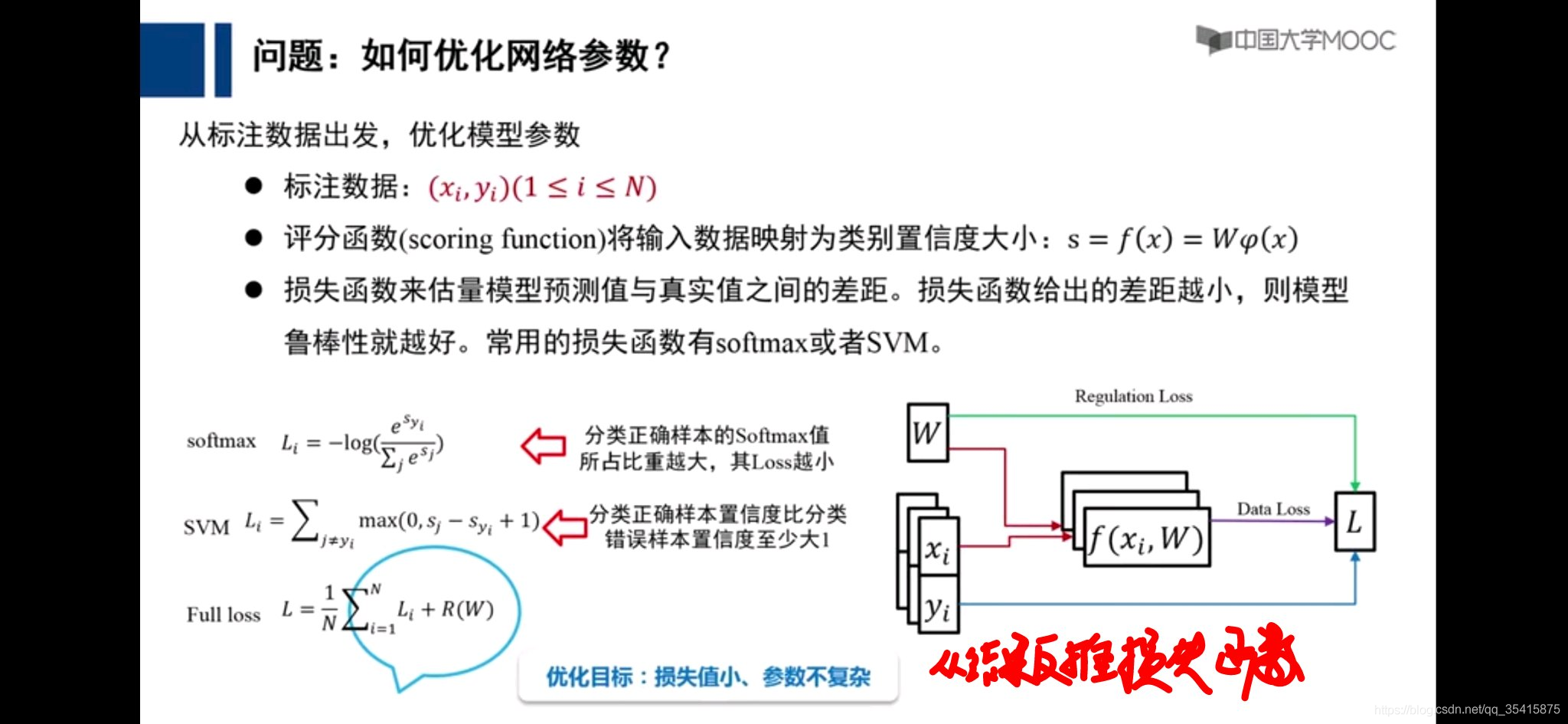
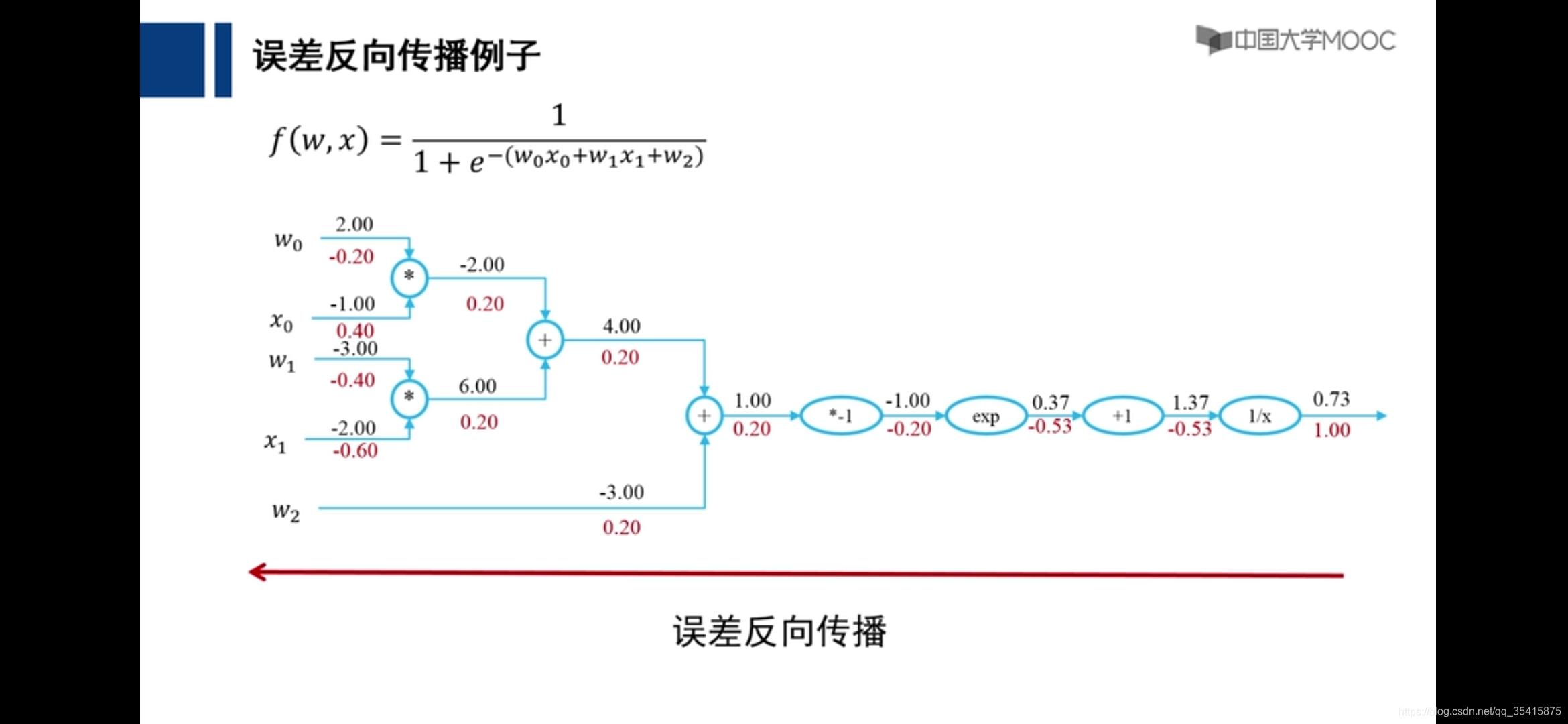
误差向后传播
理论基础,自我理解

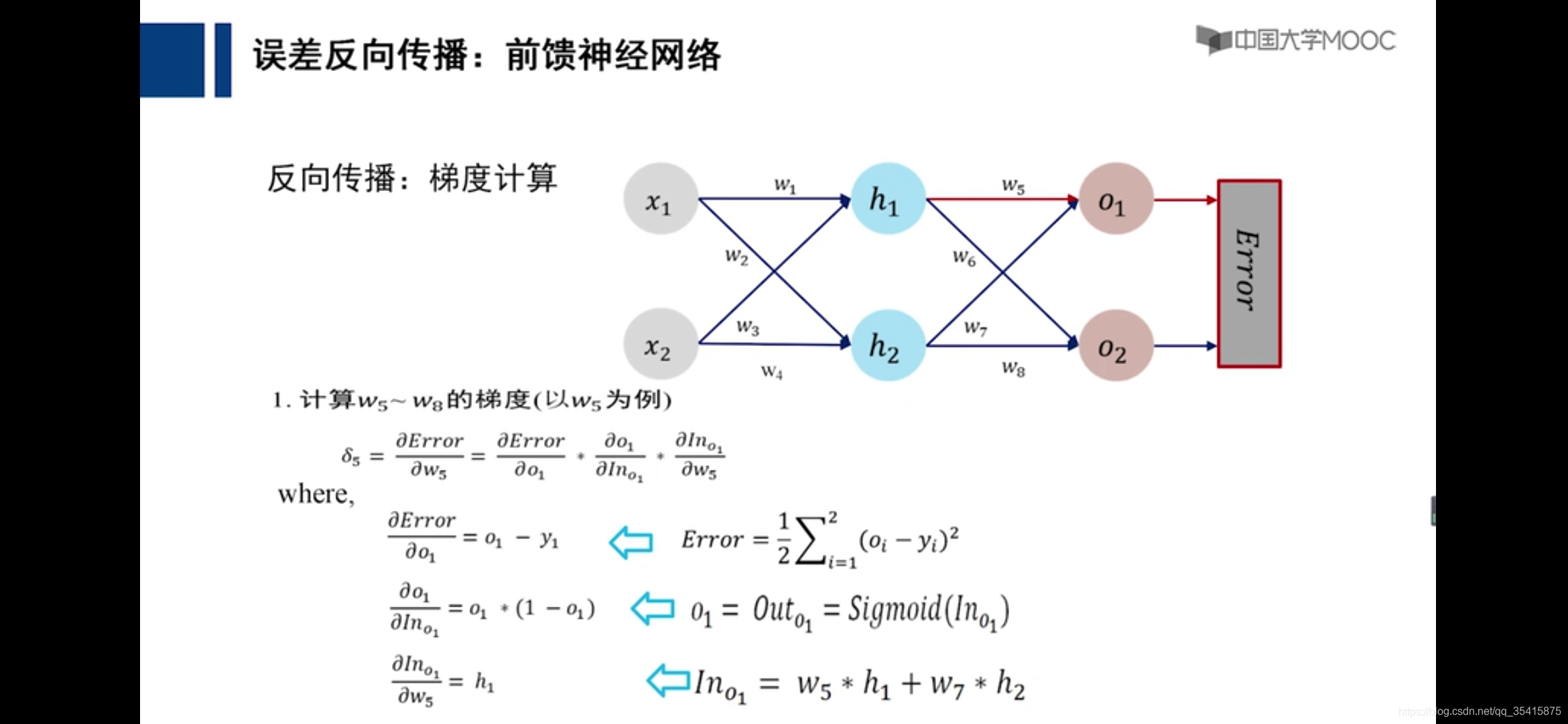
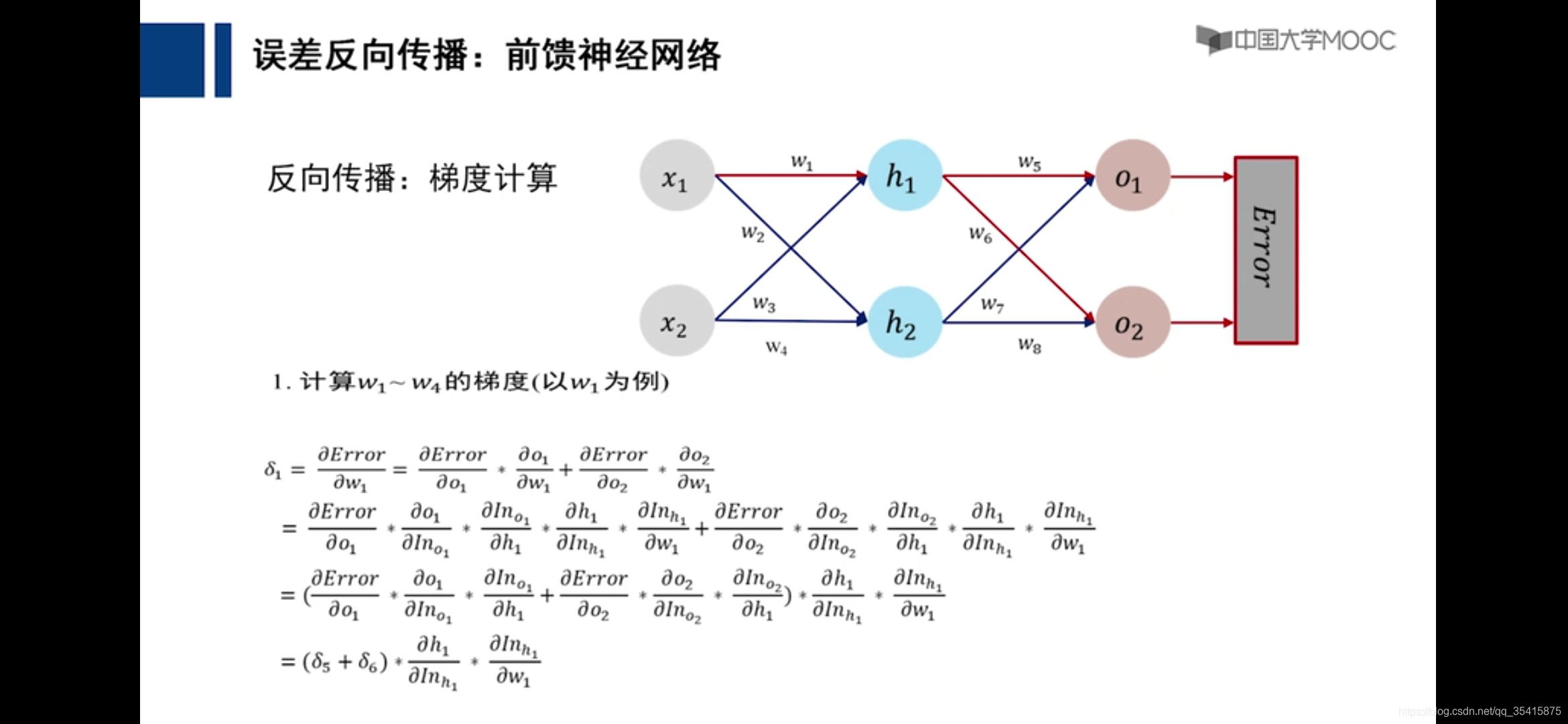

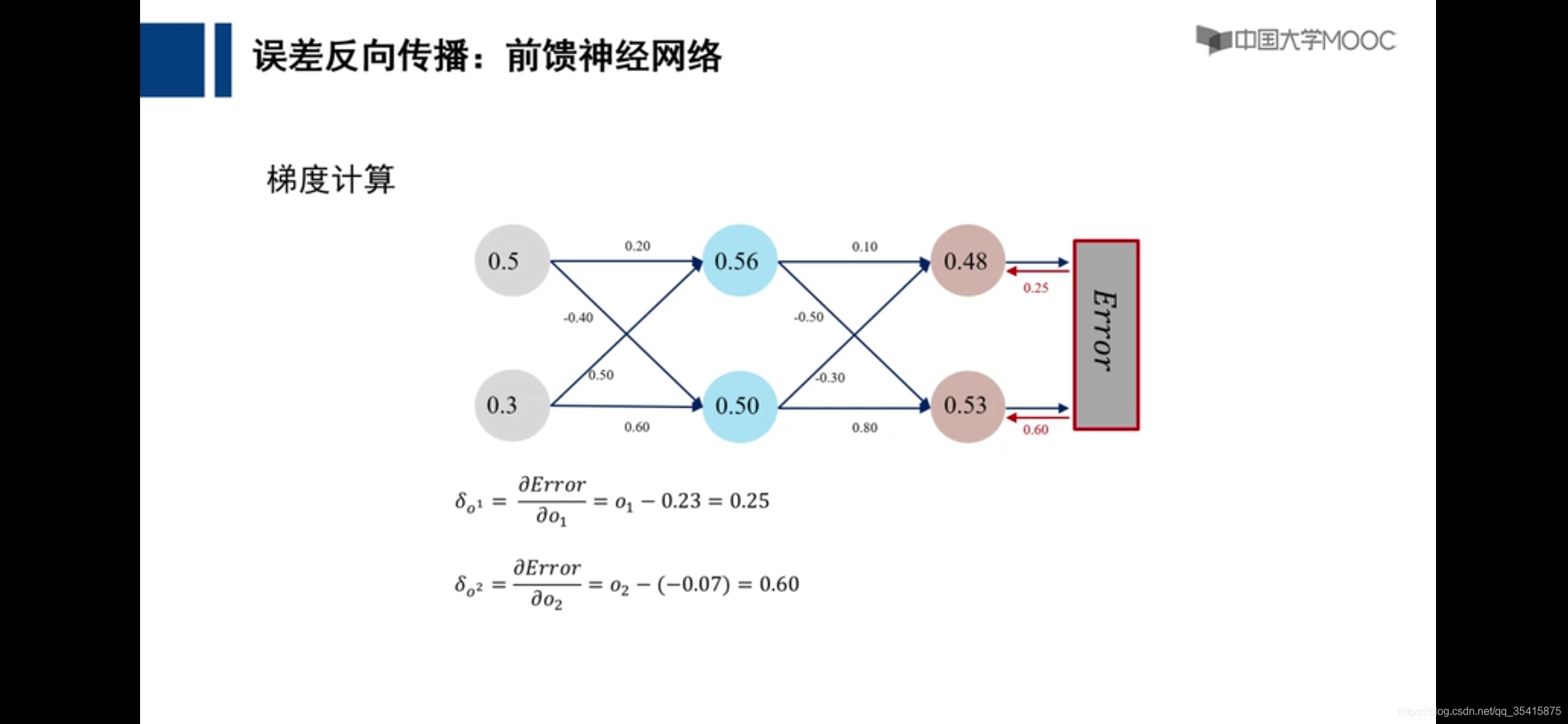
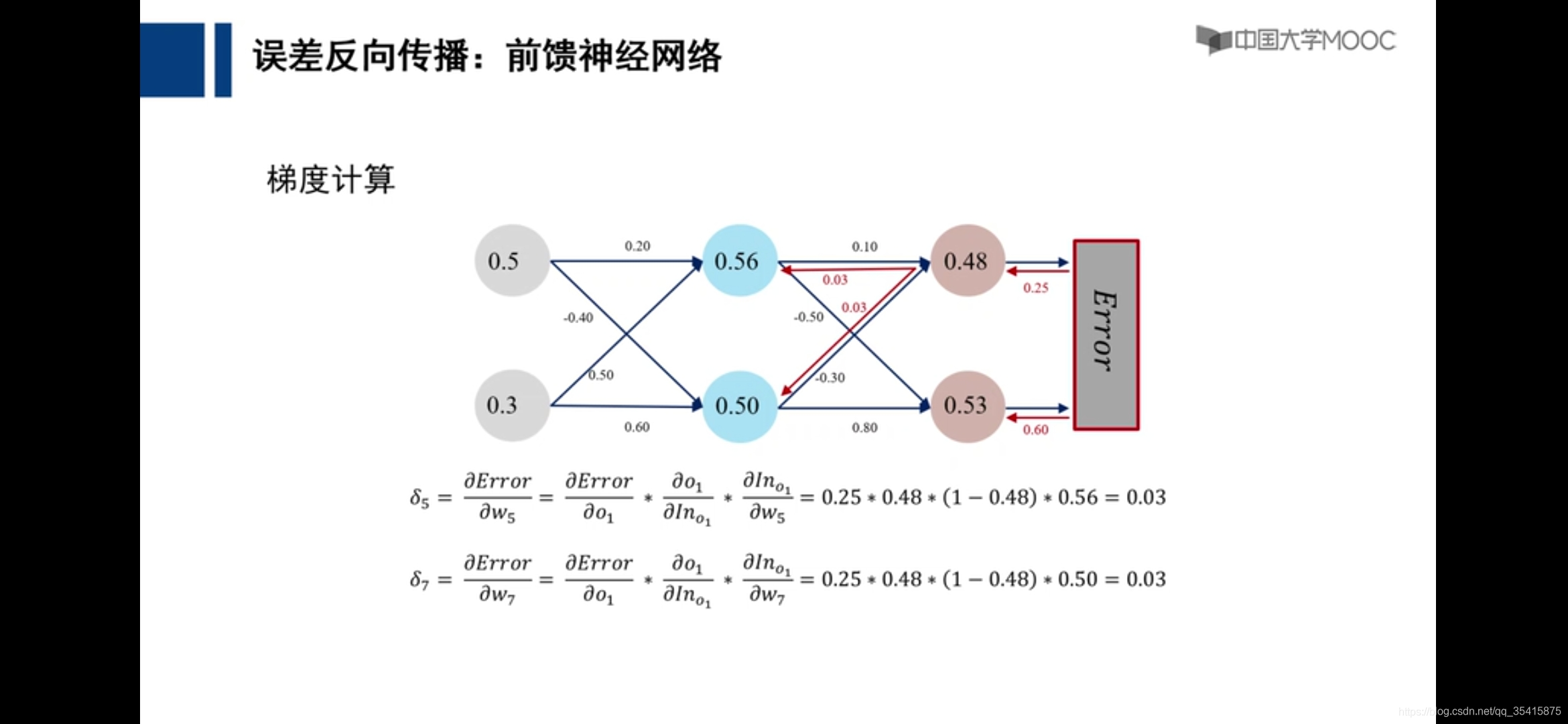
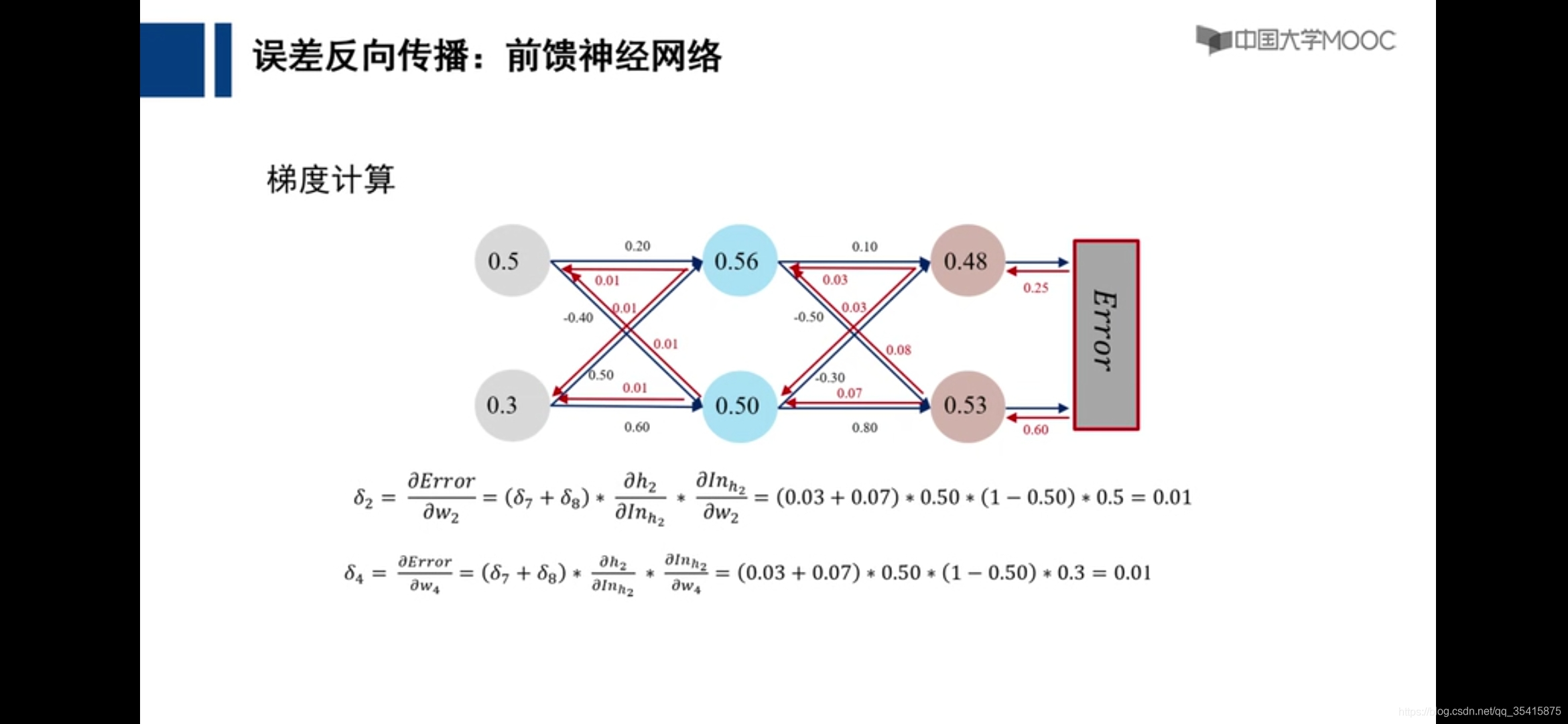
通过各个计算的偏导数更新参数,即是损失函数下降最快的地方
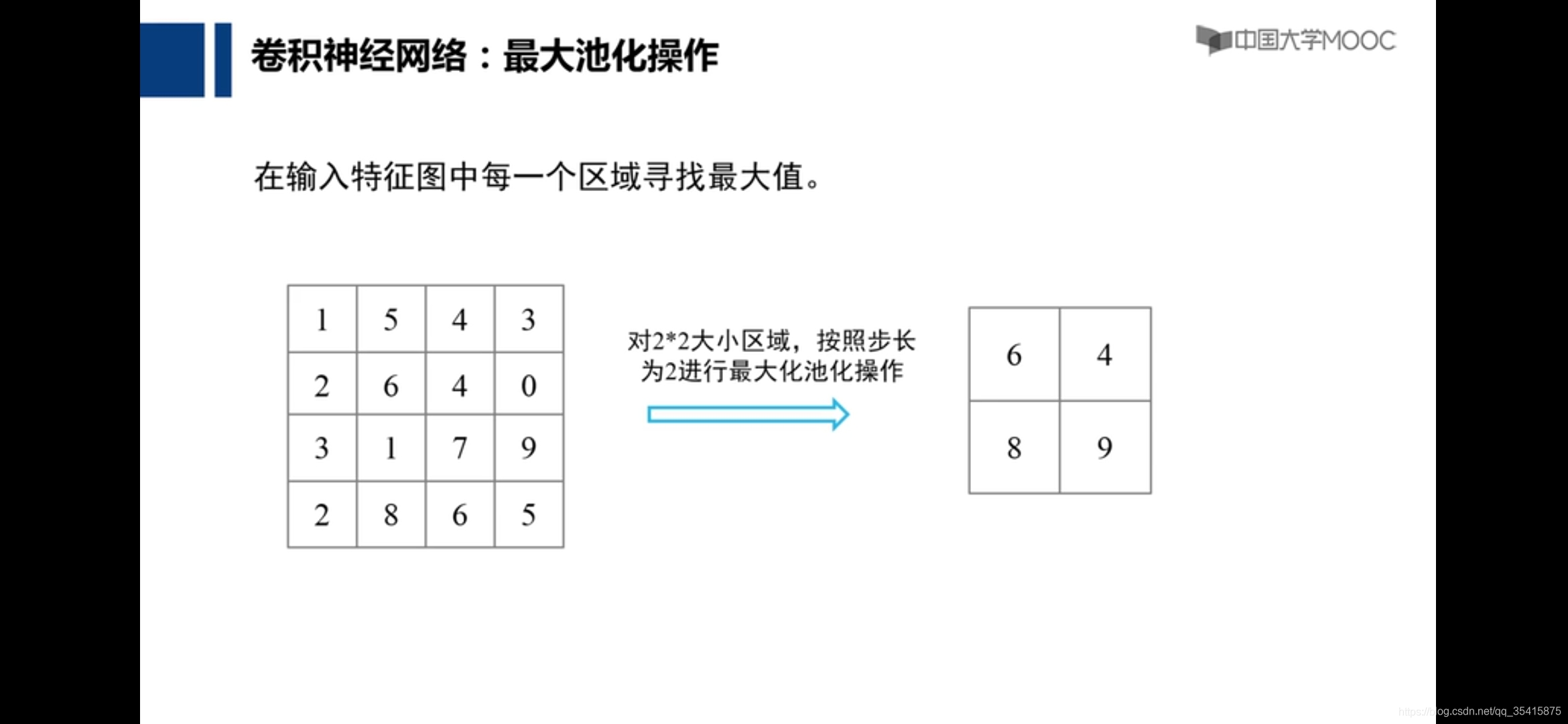
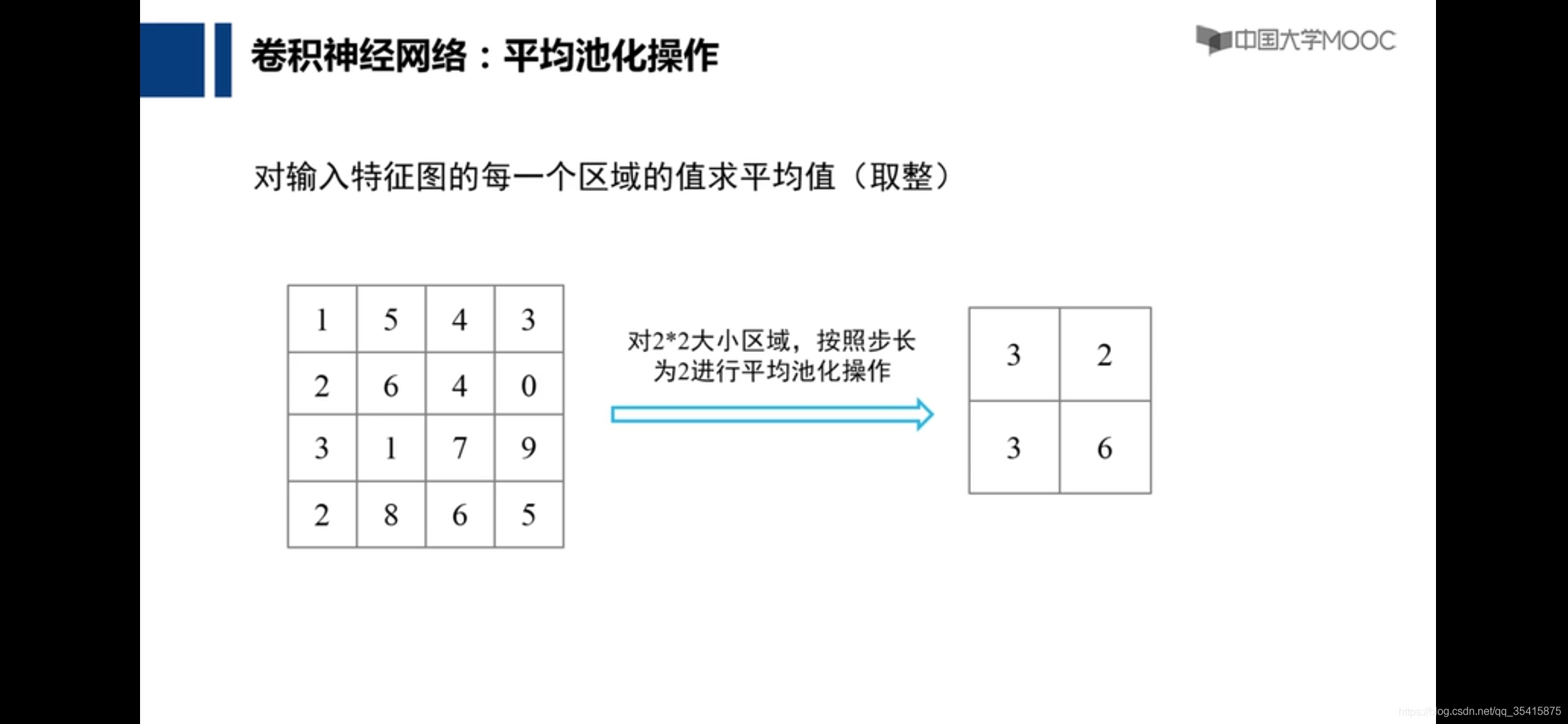
卷积神经网络
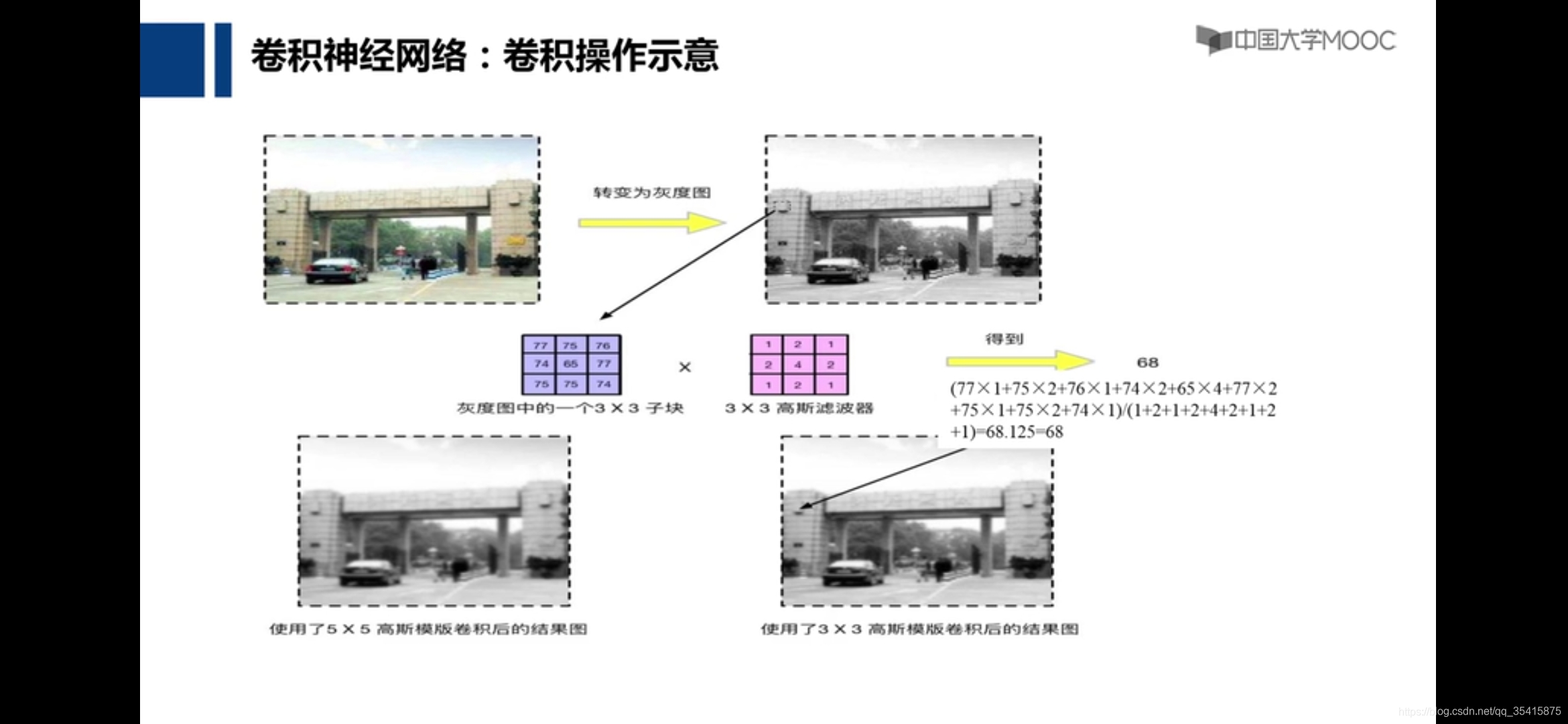
由式子可以看到,68比原像素点大,中心像素点以四为权重,其他像素点以小于四为权重累加,意味着中心像素点慢慢向四周像素点趋同
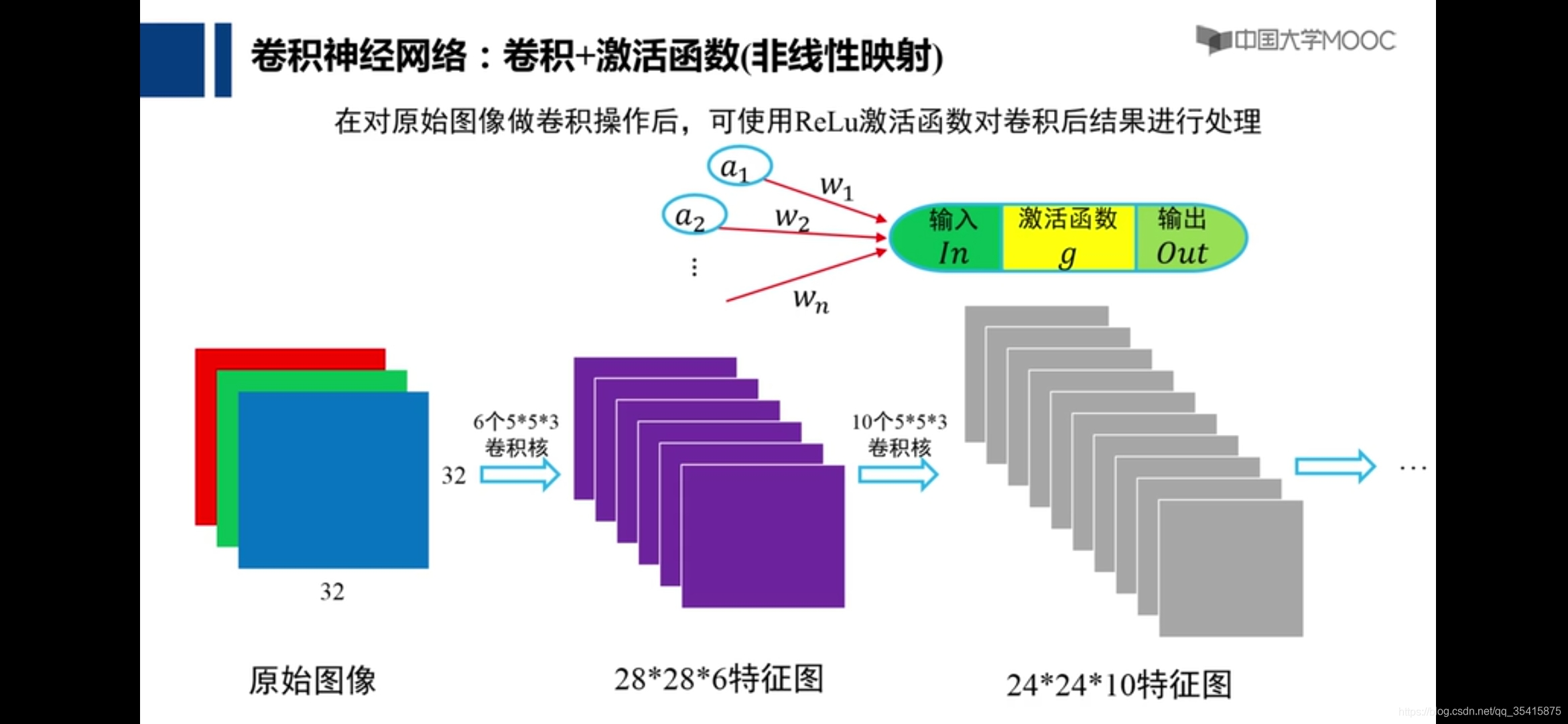
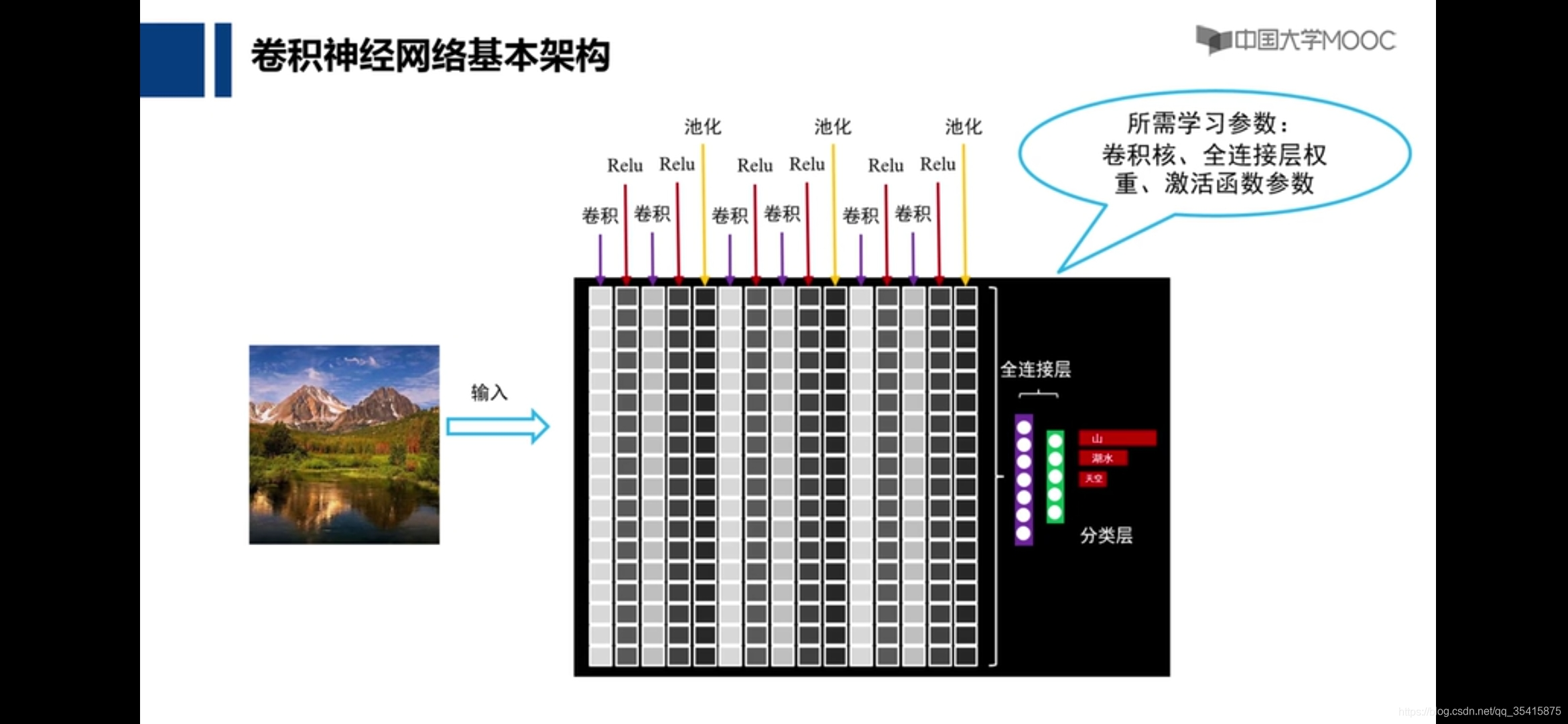
就以人脸识别来说,最初网络也不知道应该提取什么特征才可以使的与相似图片比对的相似度最大,也即使的loss最小,但最后通过训练,神经网络发现将卷积核网络参数设置为提取眼睛,鼻子,嘴巴,耳朵等特征可以获得最佳结果,这是一个自动化的过程,是网络自动发现参数的过程
图像分类和定位
中间红字即是多任务训练,训练既需要定位,又需要分类的神经网络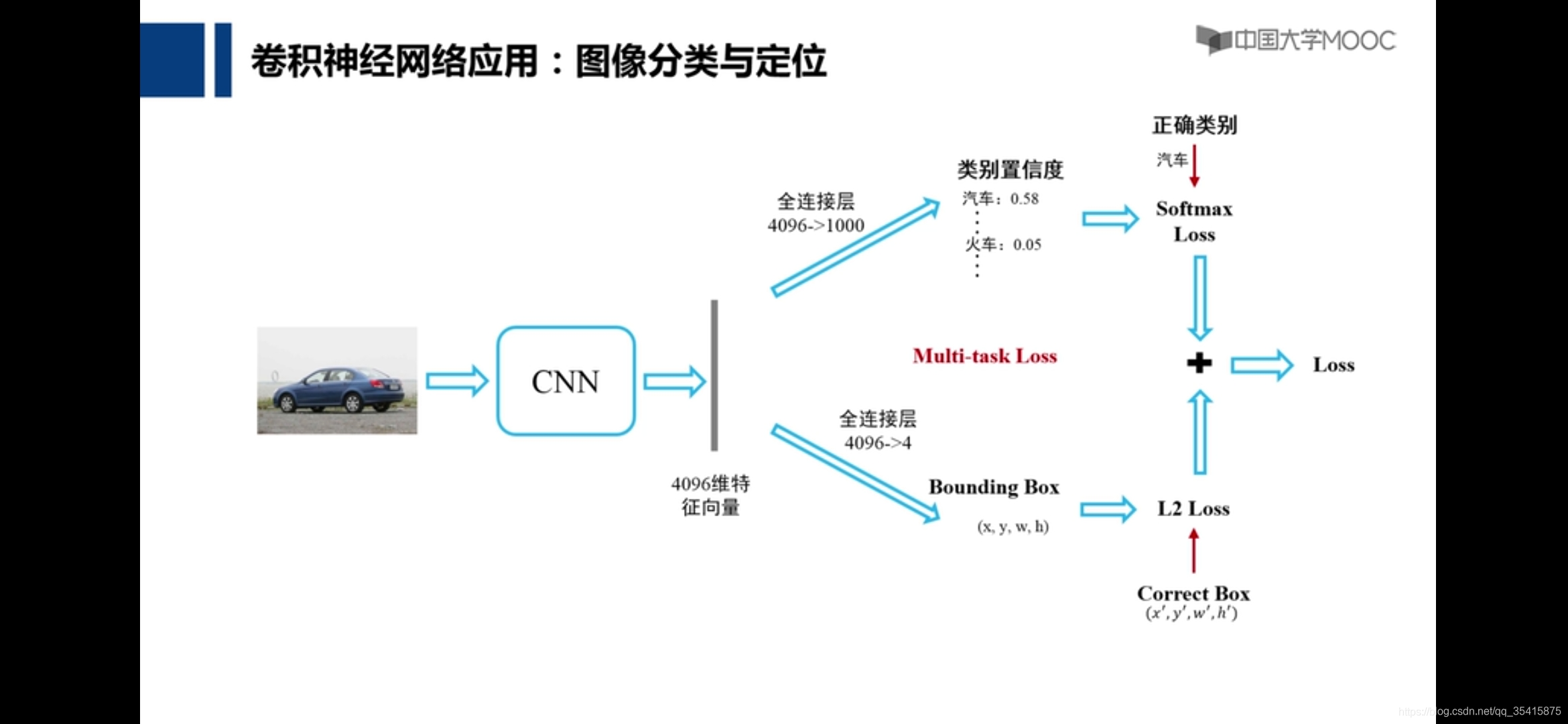
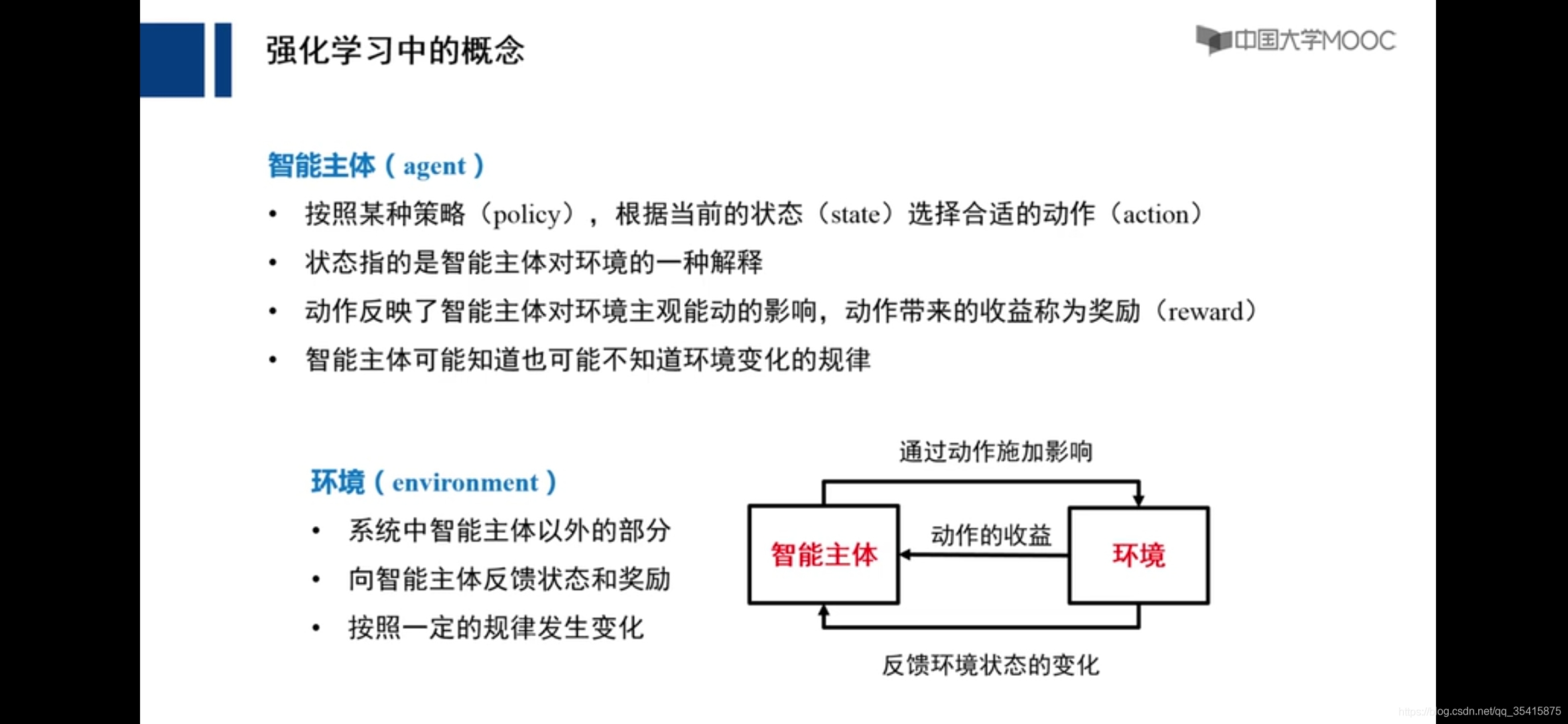
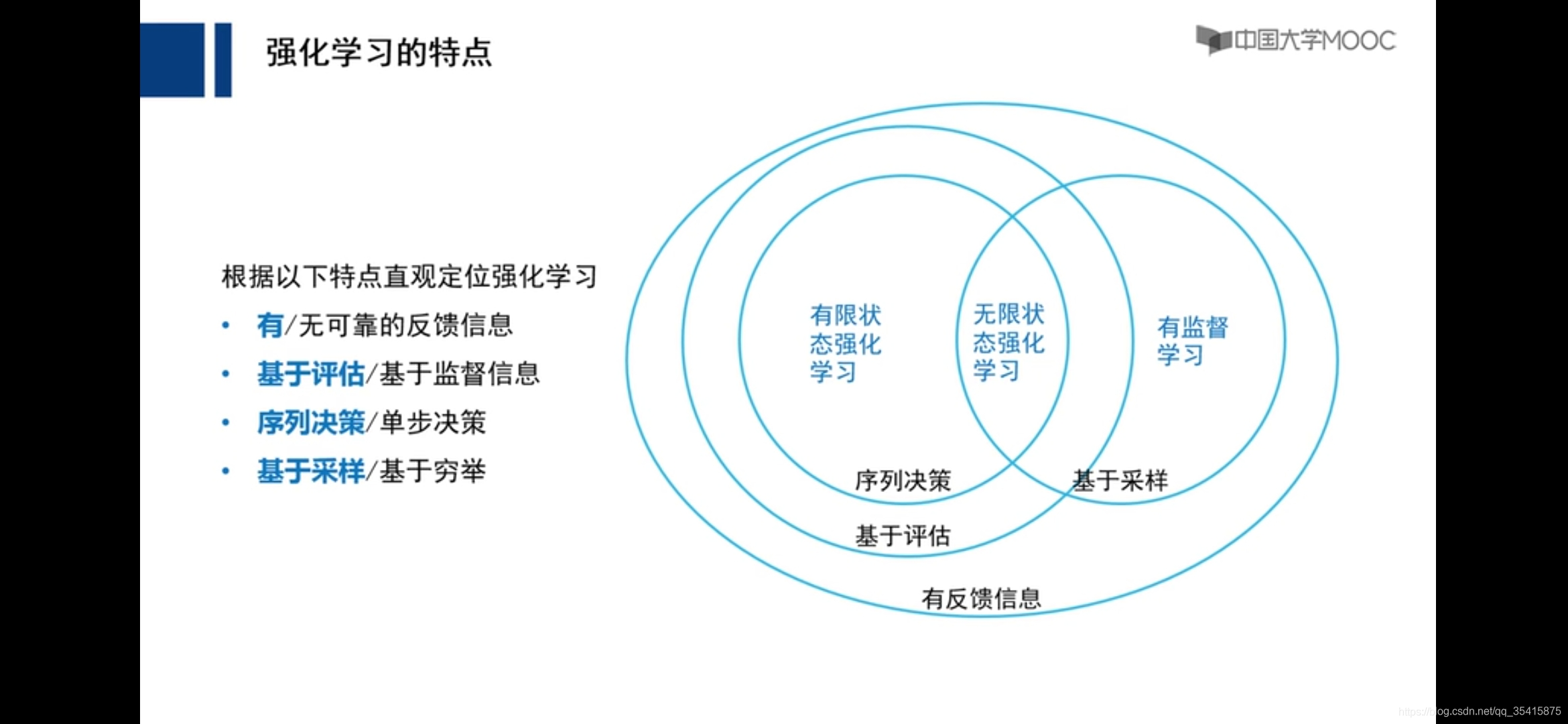
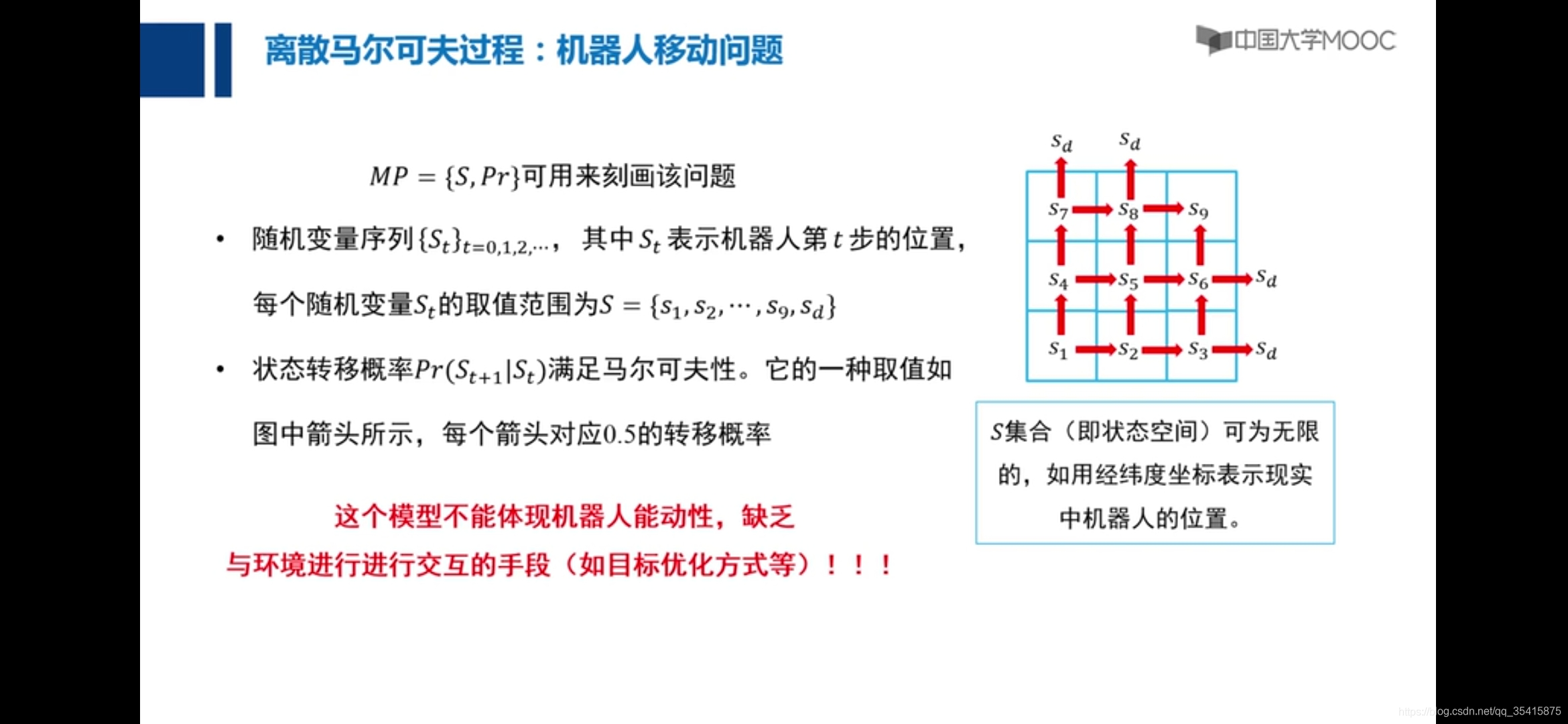
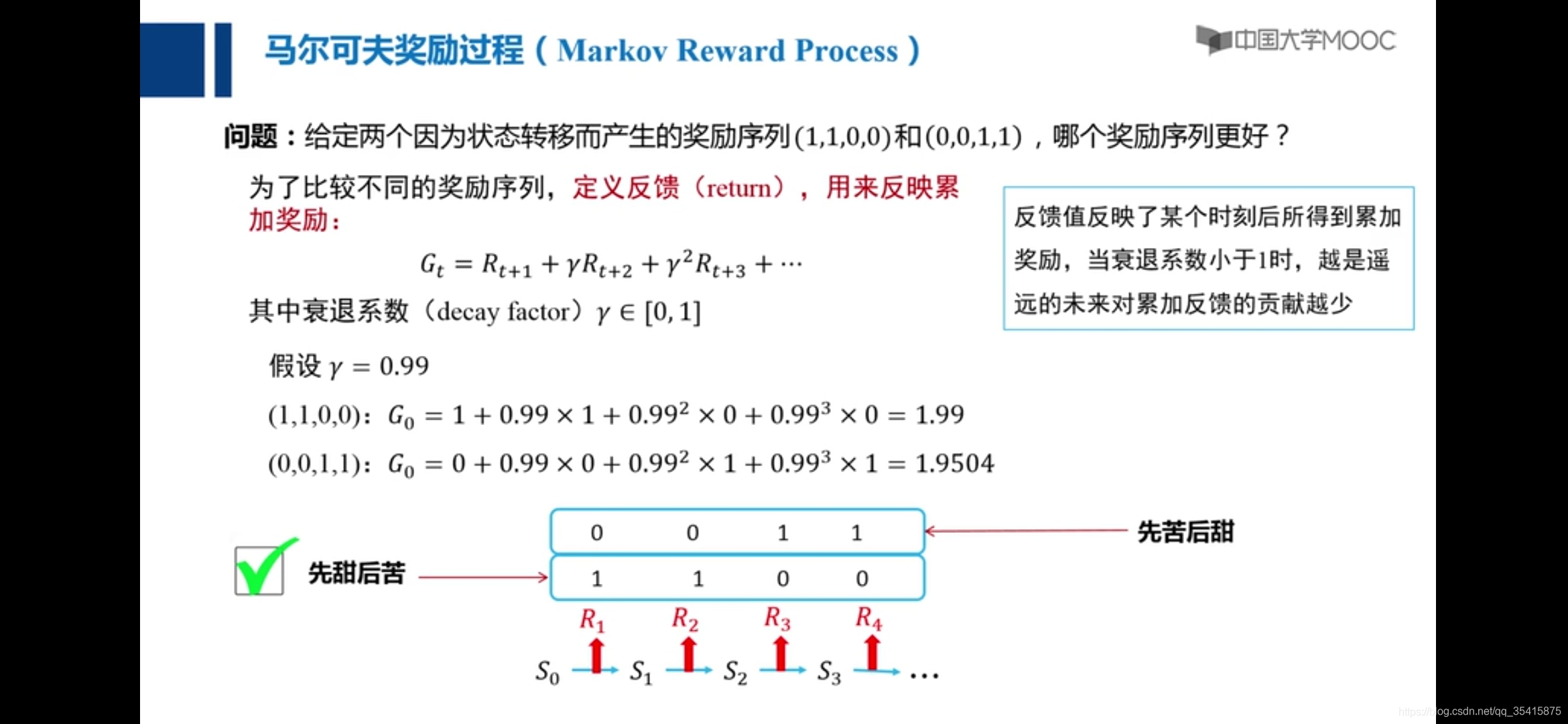
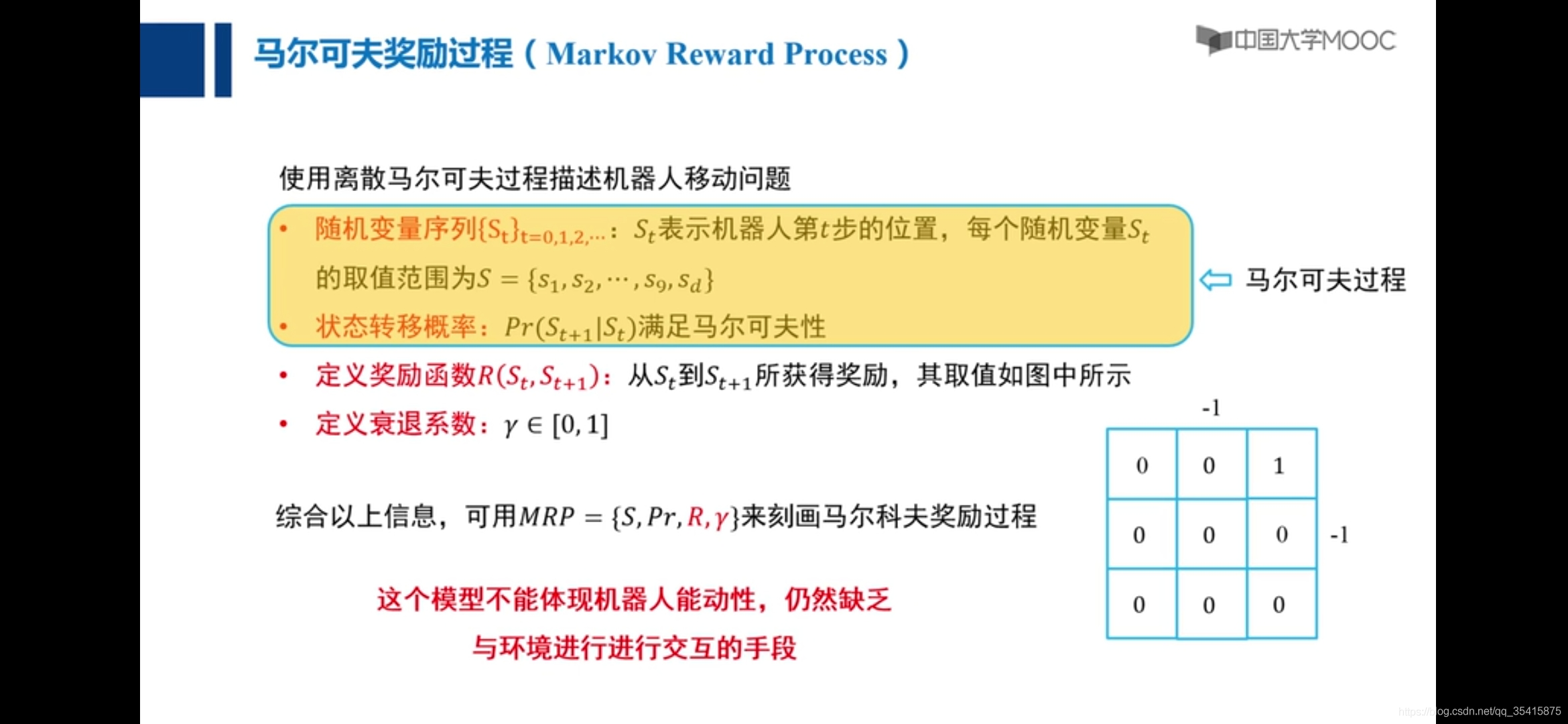
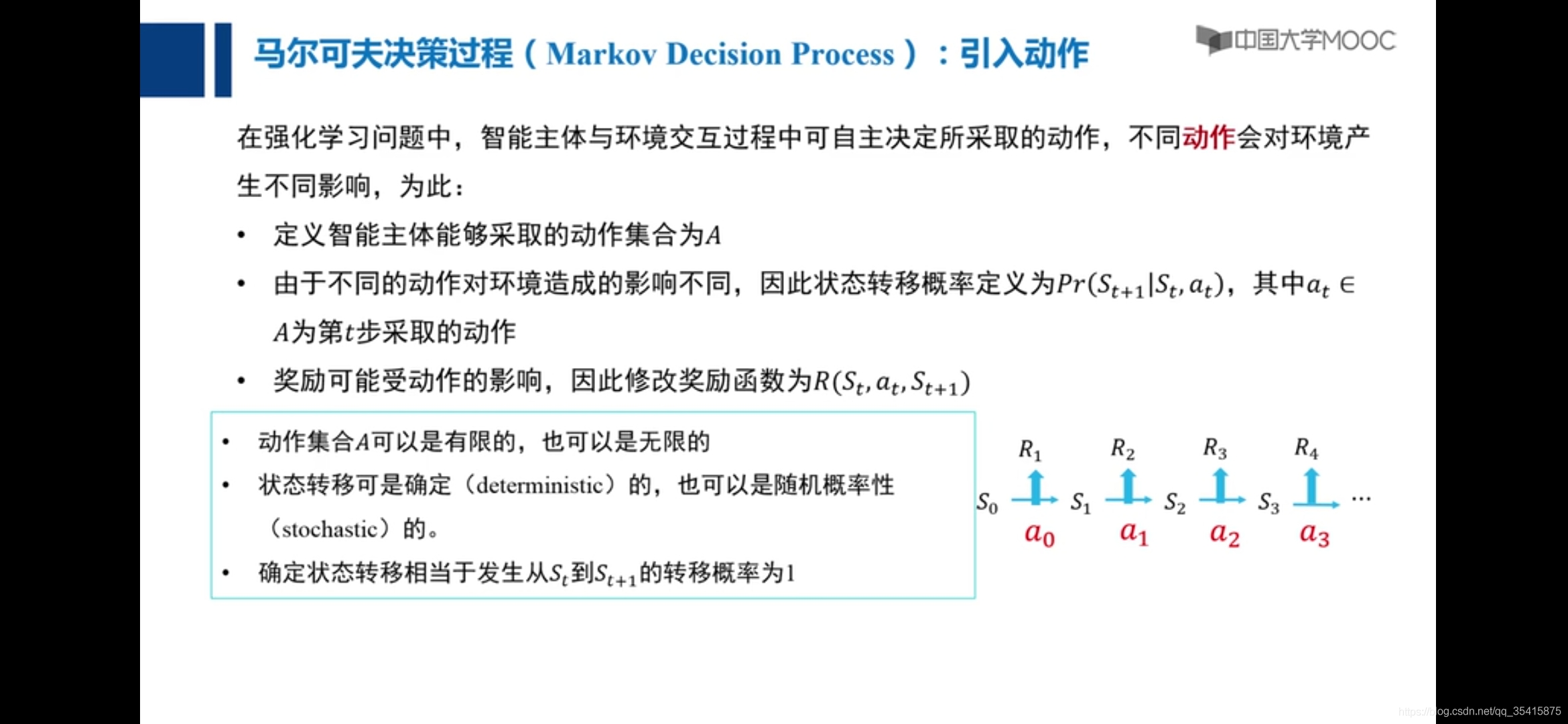
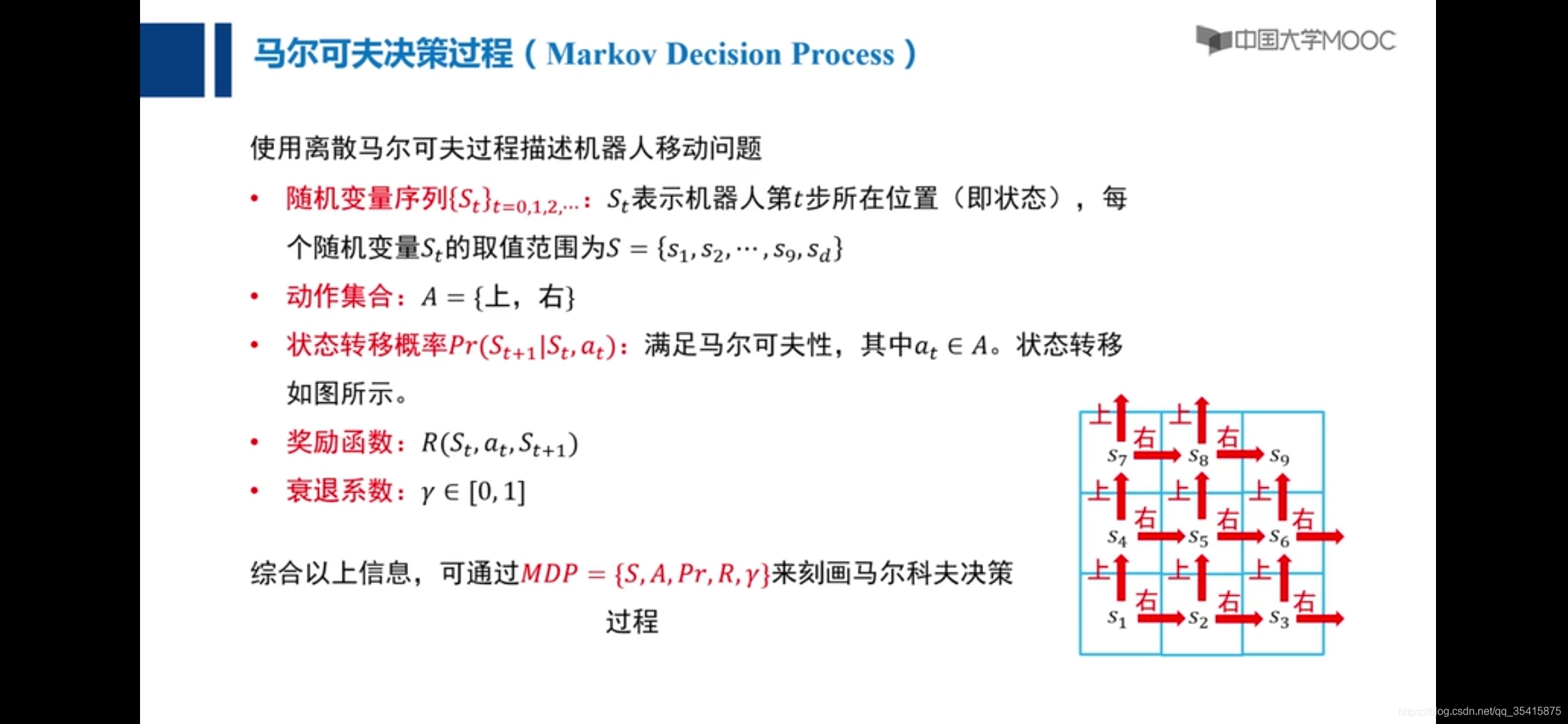
强化学习
要素:1.状态转移概率Pr 2.状态转移奖励R 3.状态转移所采取的动作a(集和A ) 4.状态S(集和{S}) 5.衰退系数γ
策略π:一系列状态通过动作到状态的过程
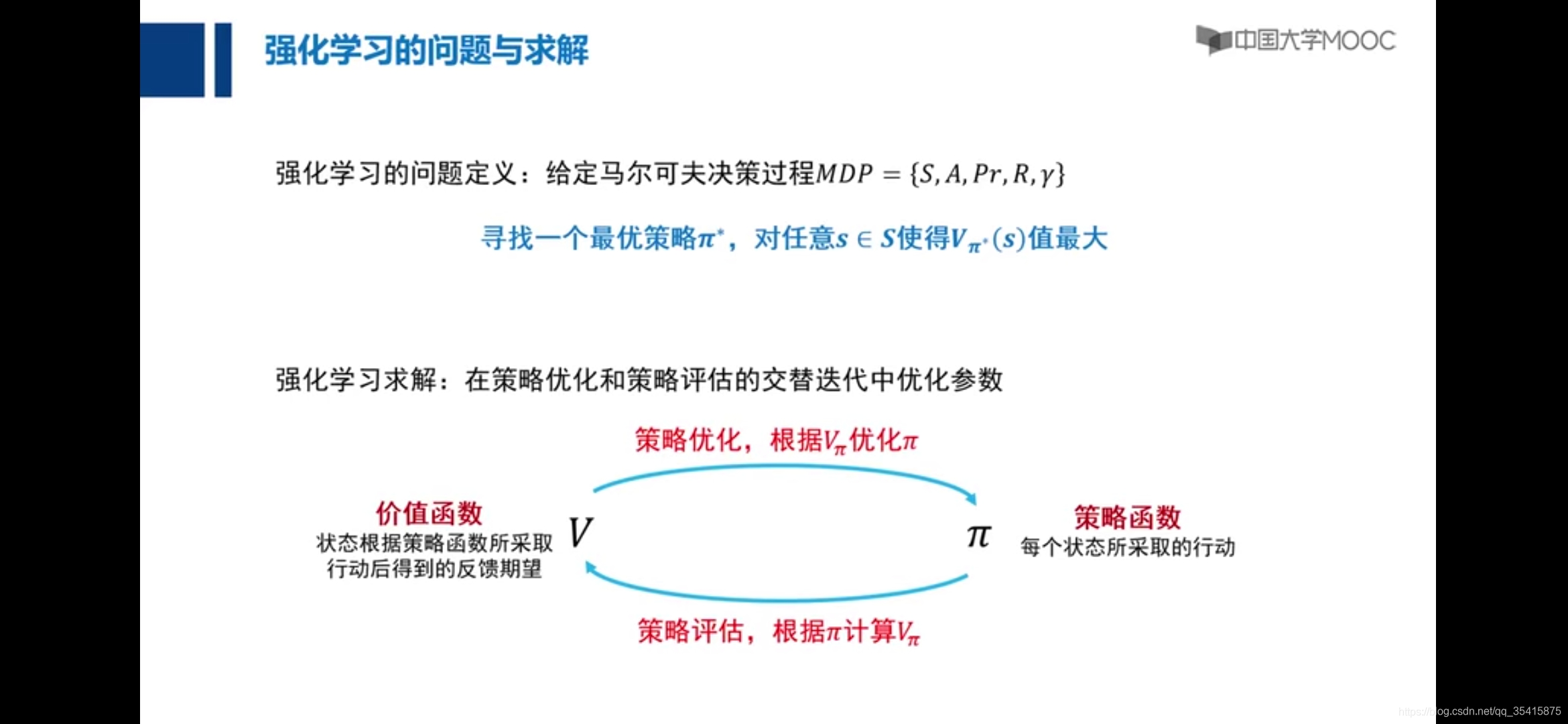



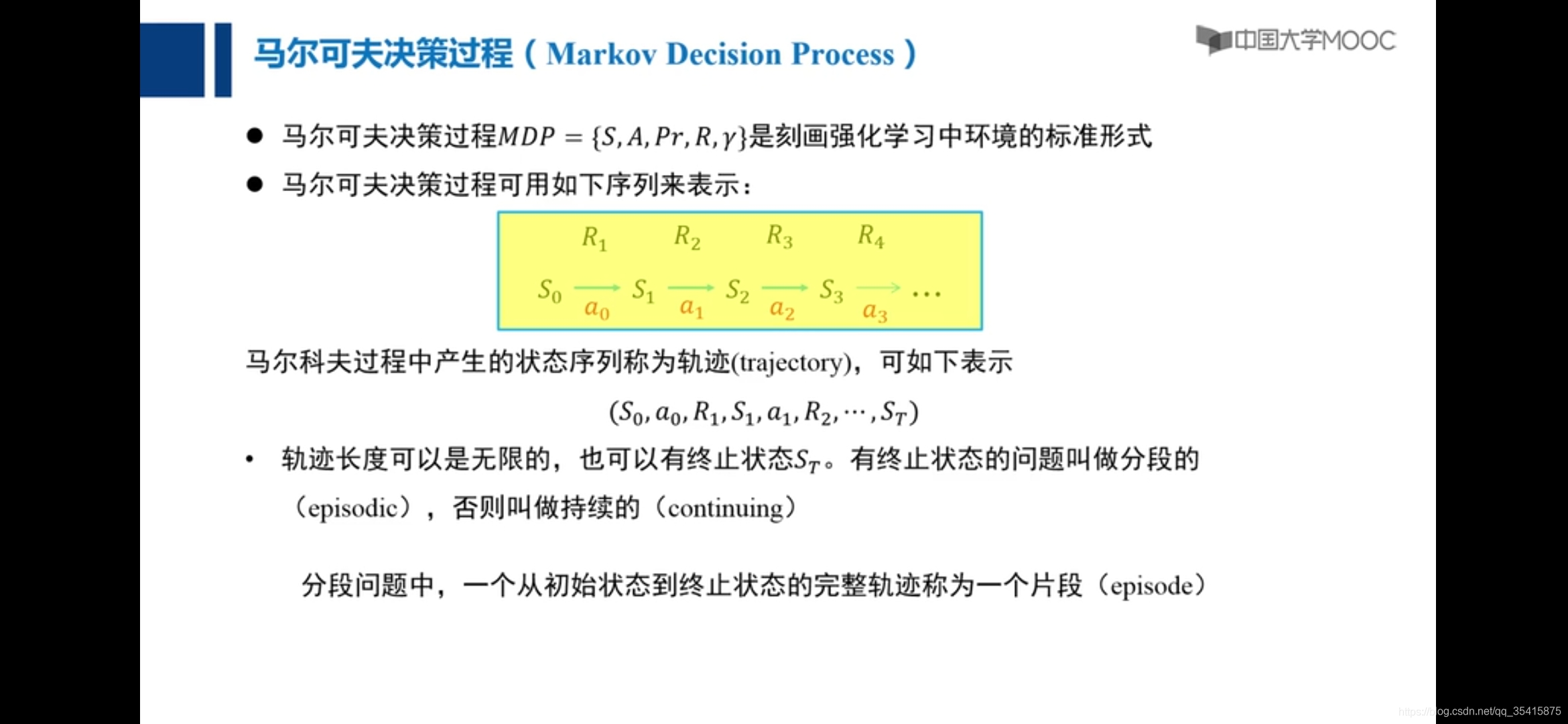






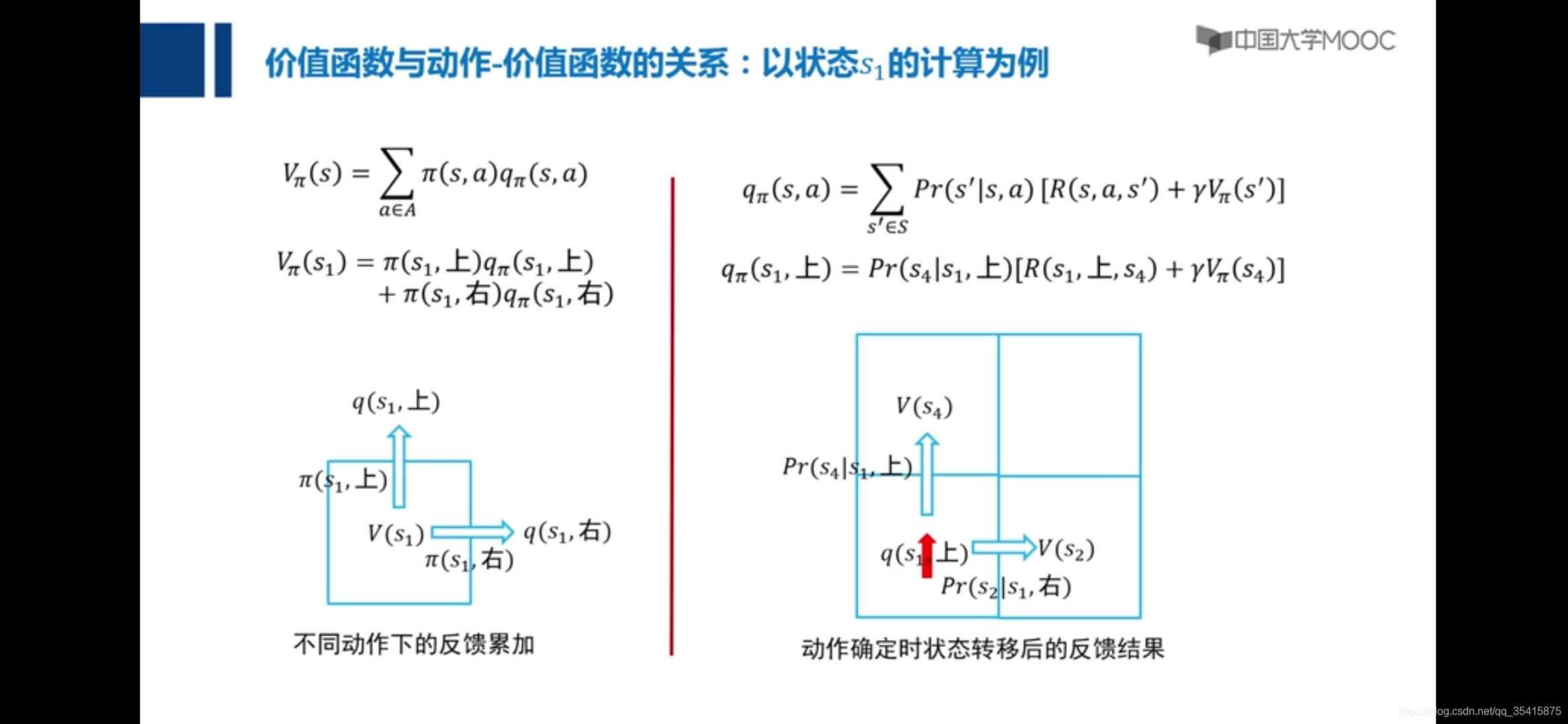

策略优化与策略评估








主要区别在于与当前状态价值也有了联系
Q学习

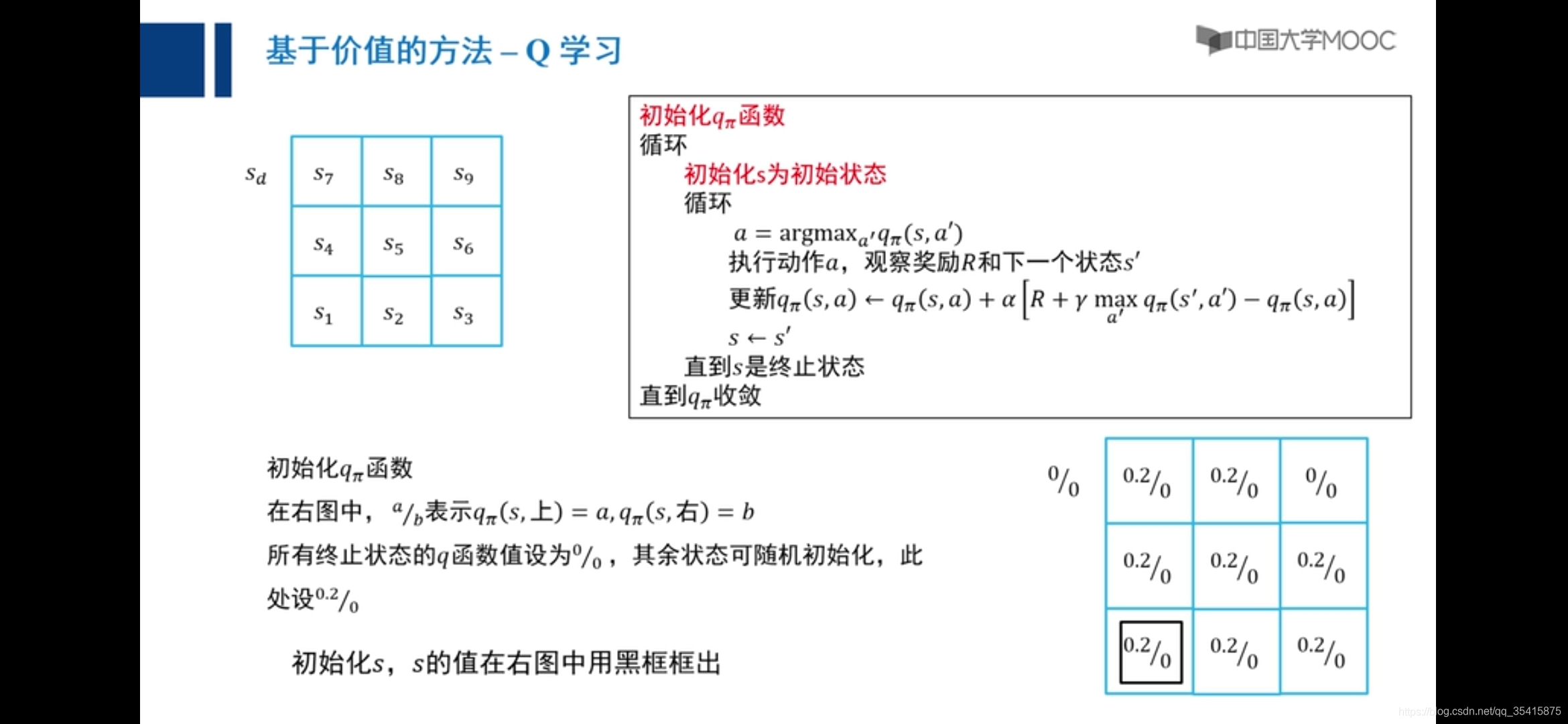
向右是零,向上是0.2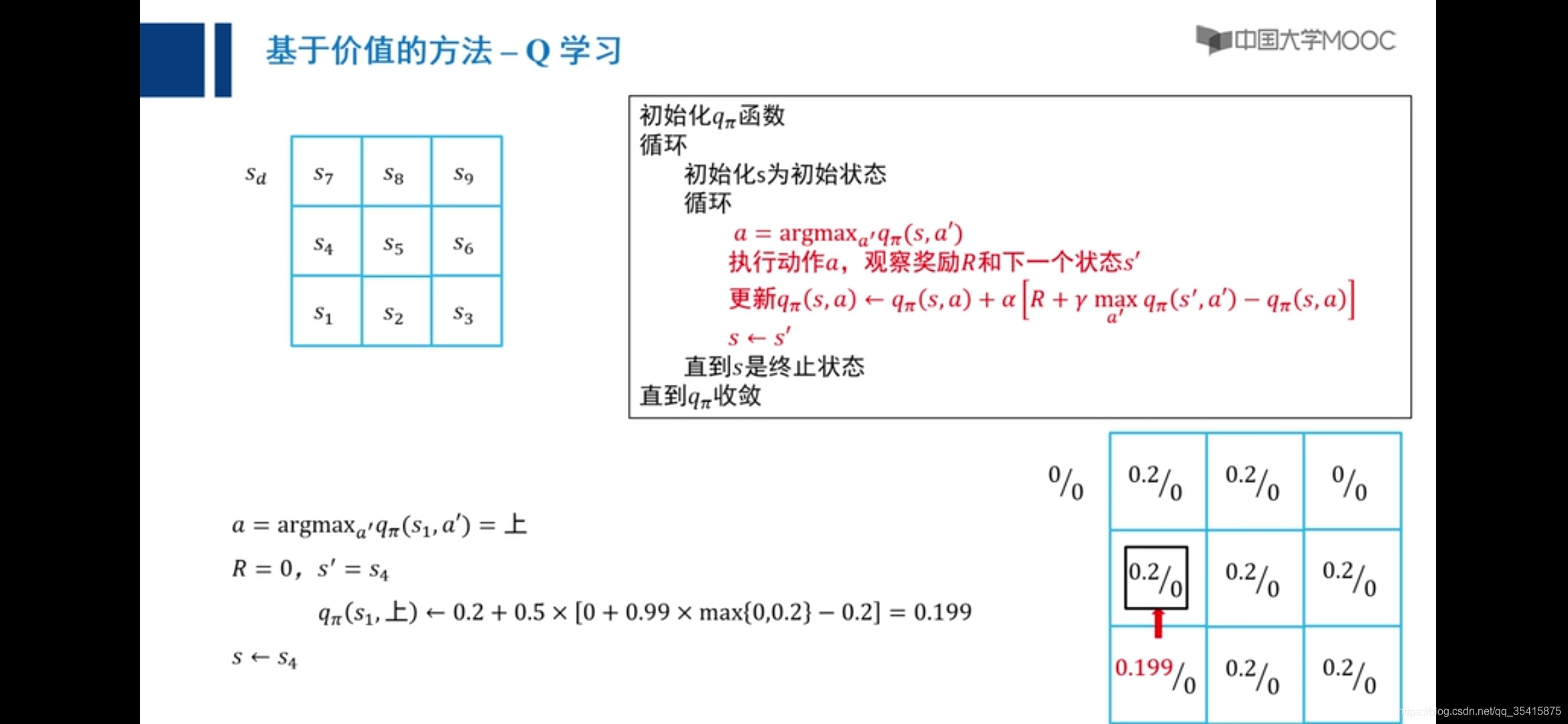
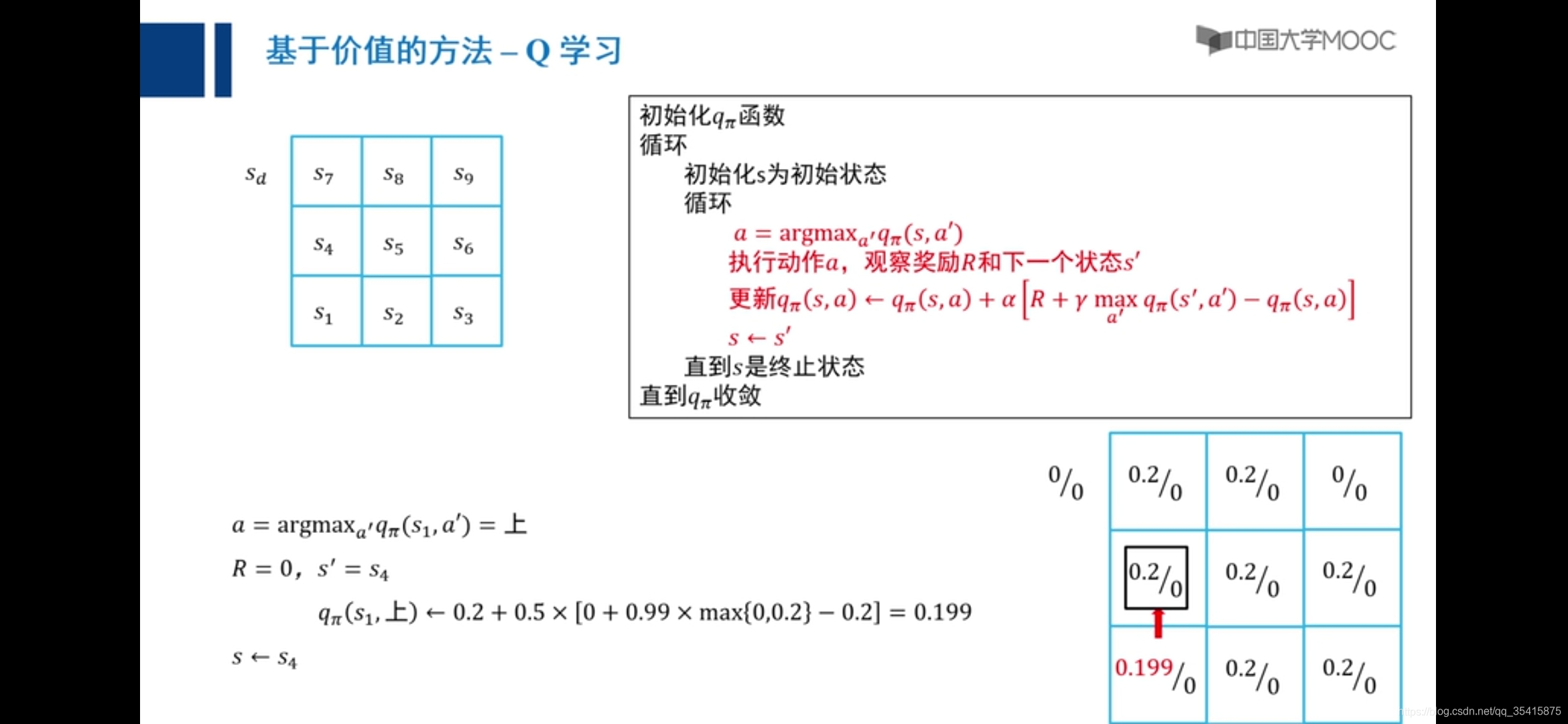
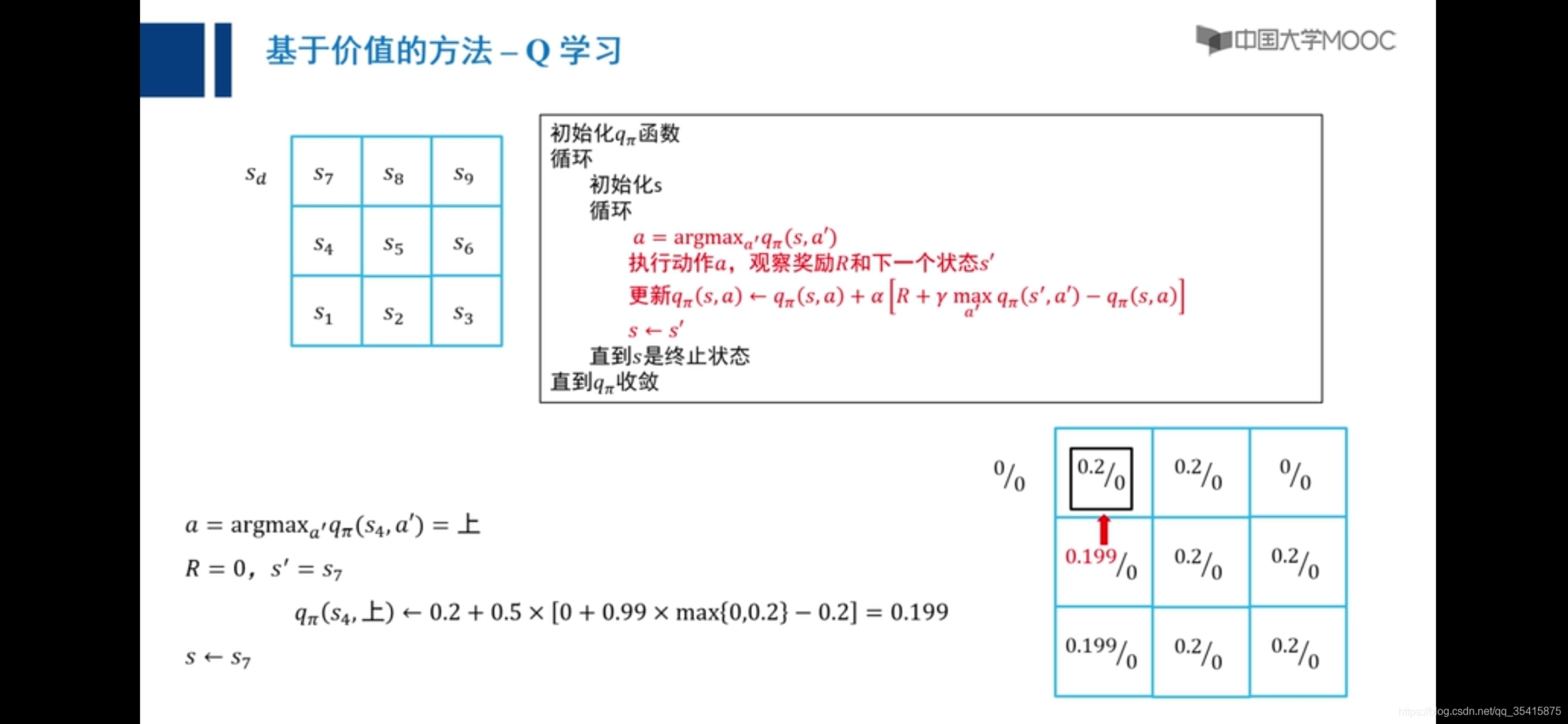
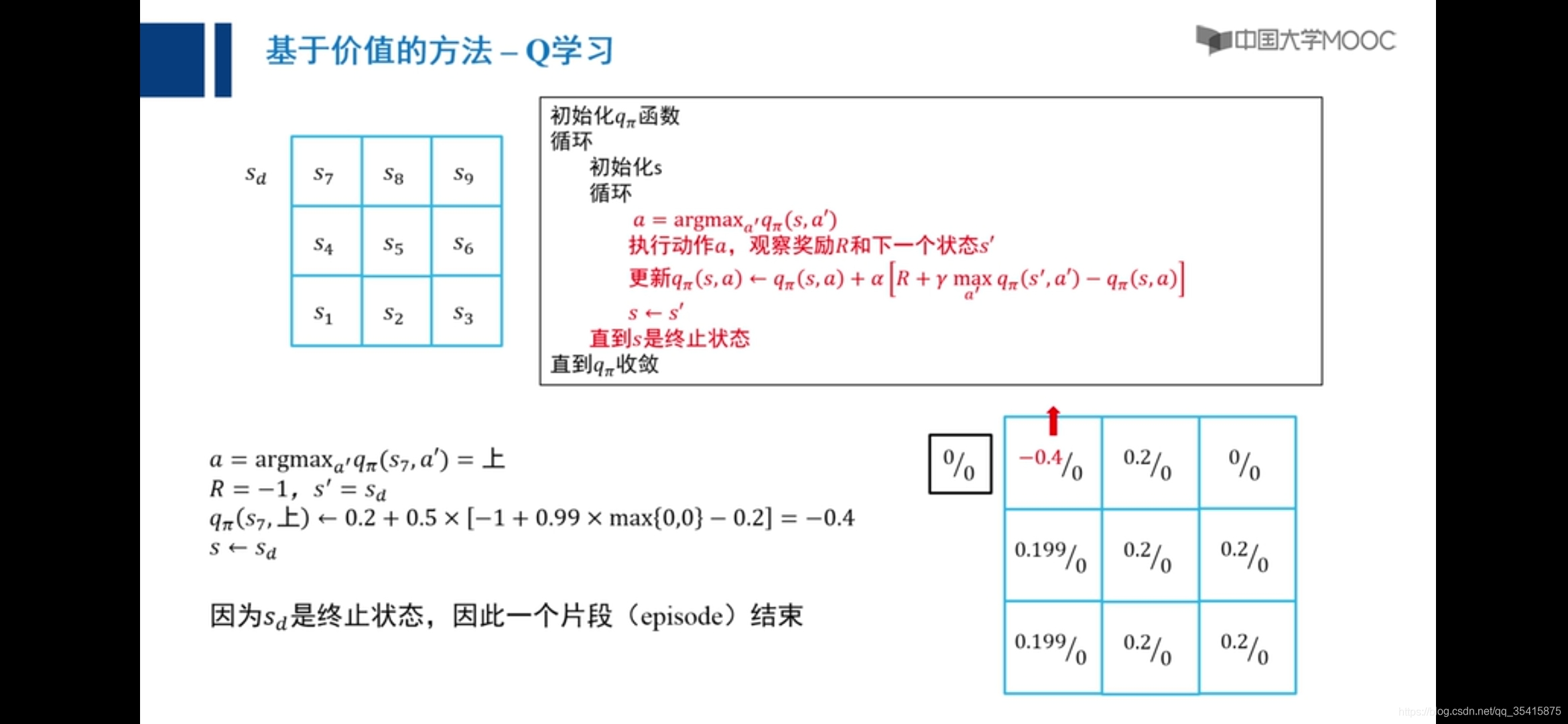
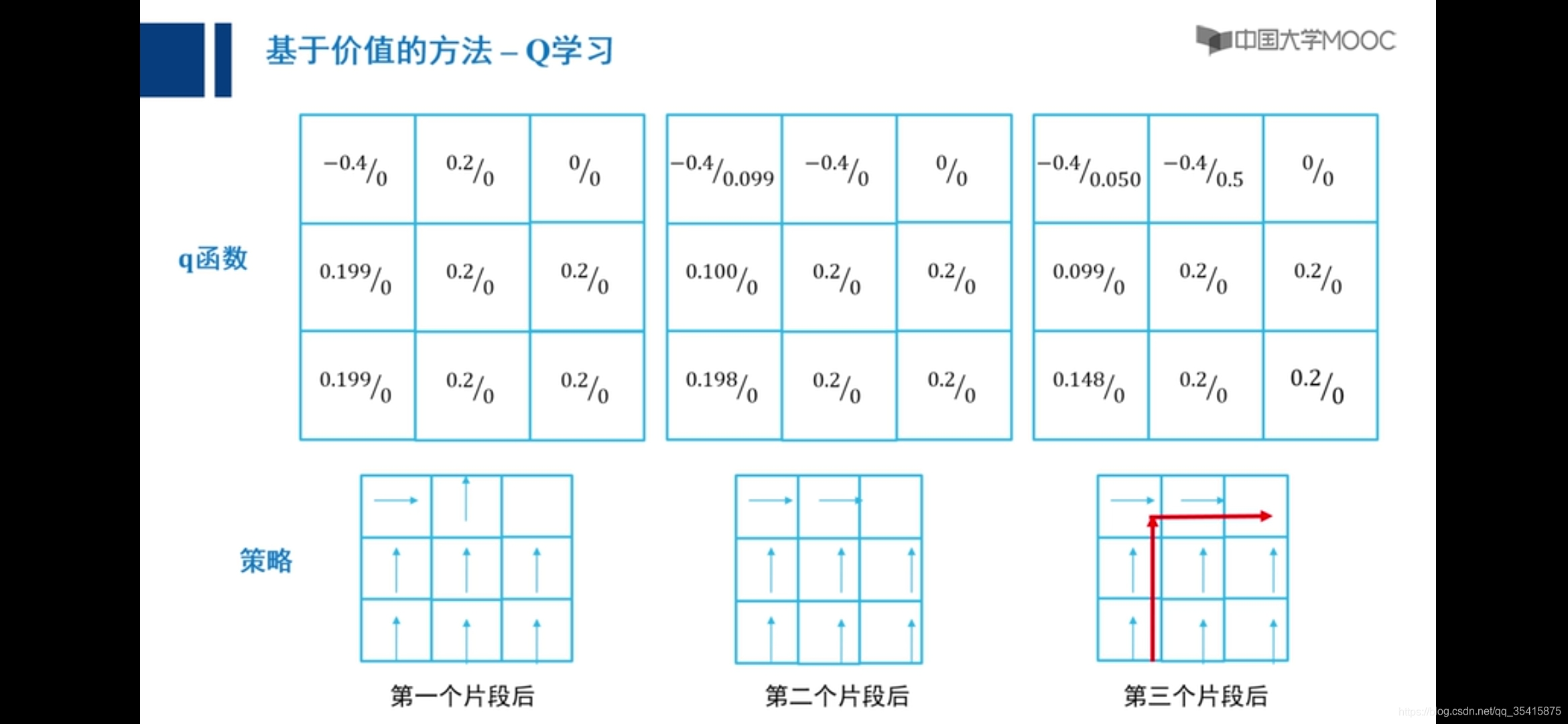
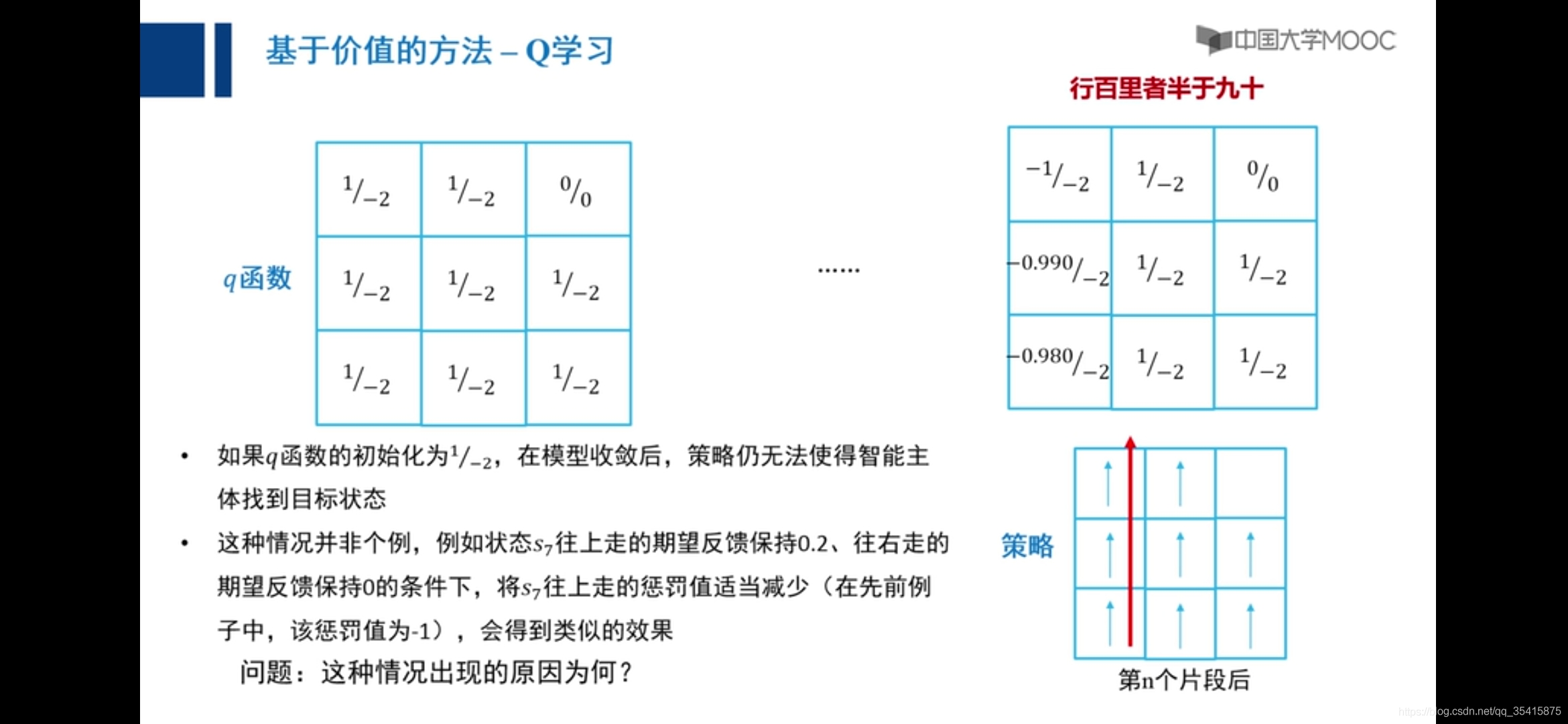
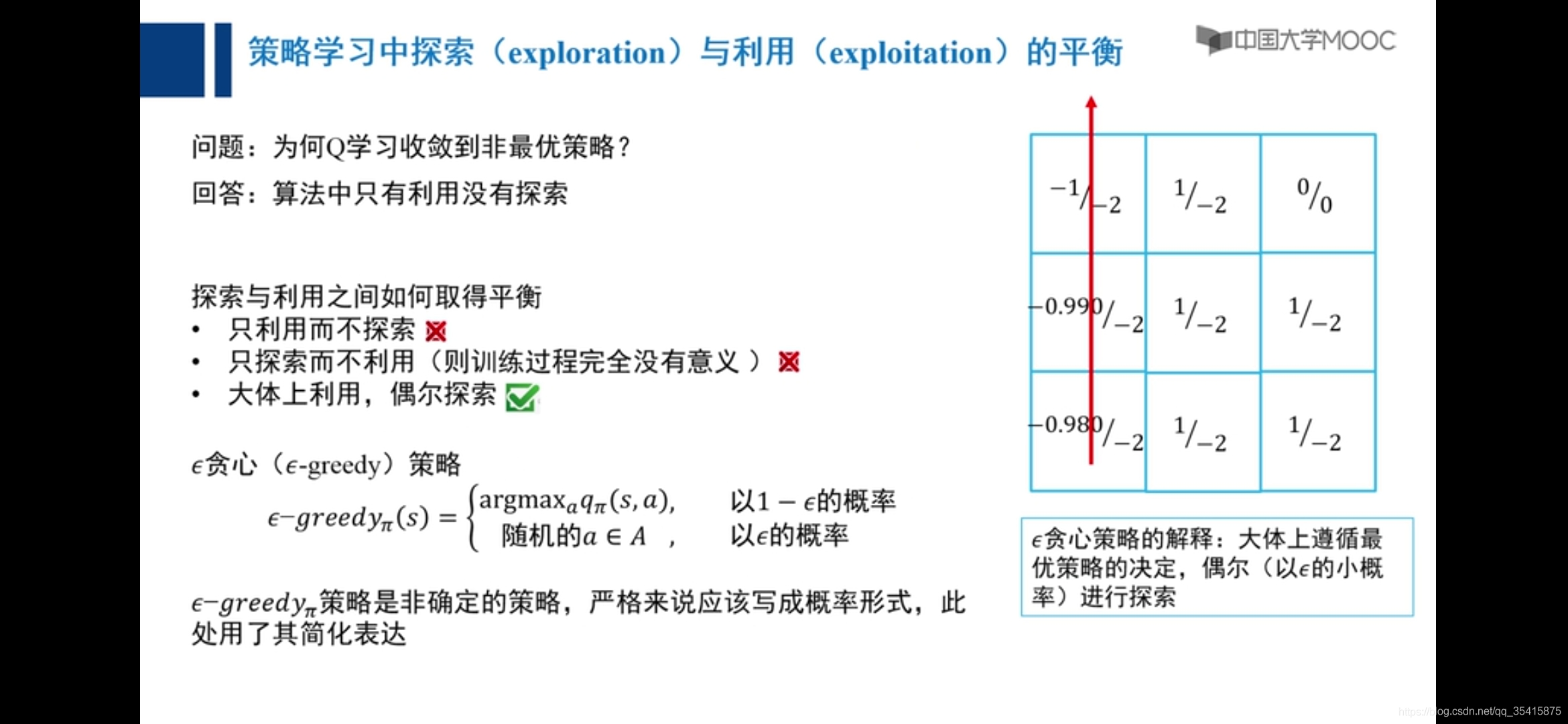
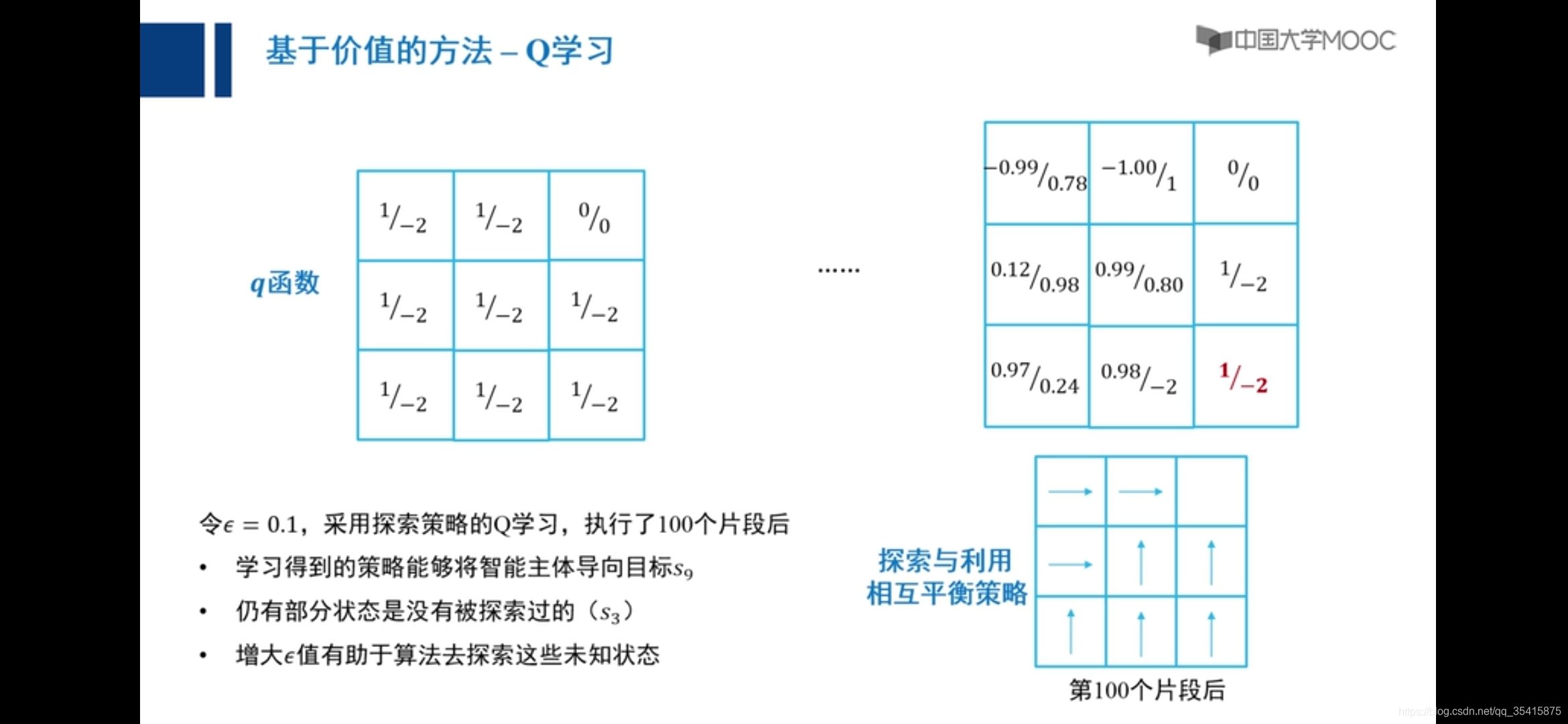
原因:主要是由于越界惩罚和采取动作后反馈值期望大小不确定,添加小概率向任意方向走解决,称之为探索

深度强化学习(深度Q学习)


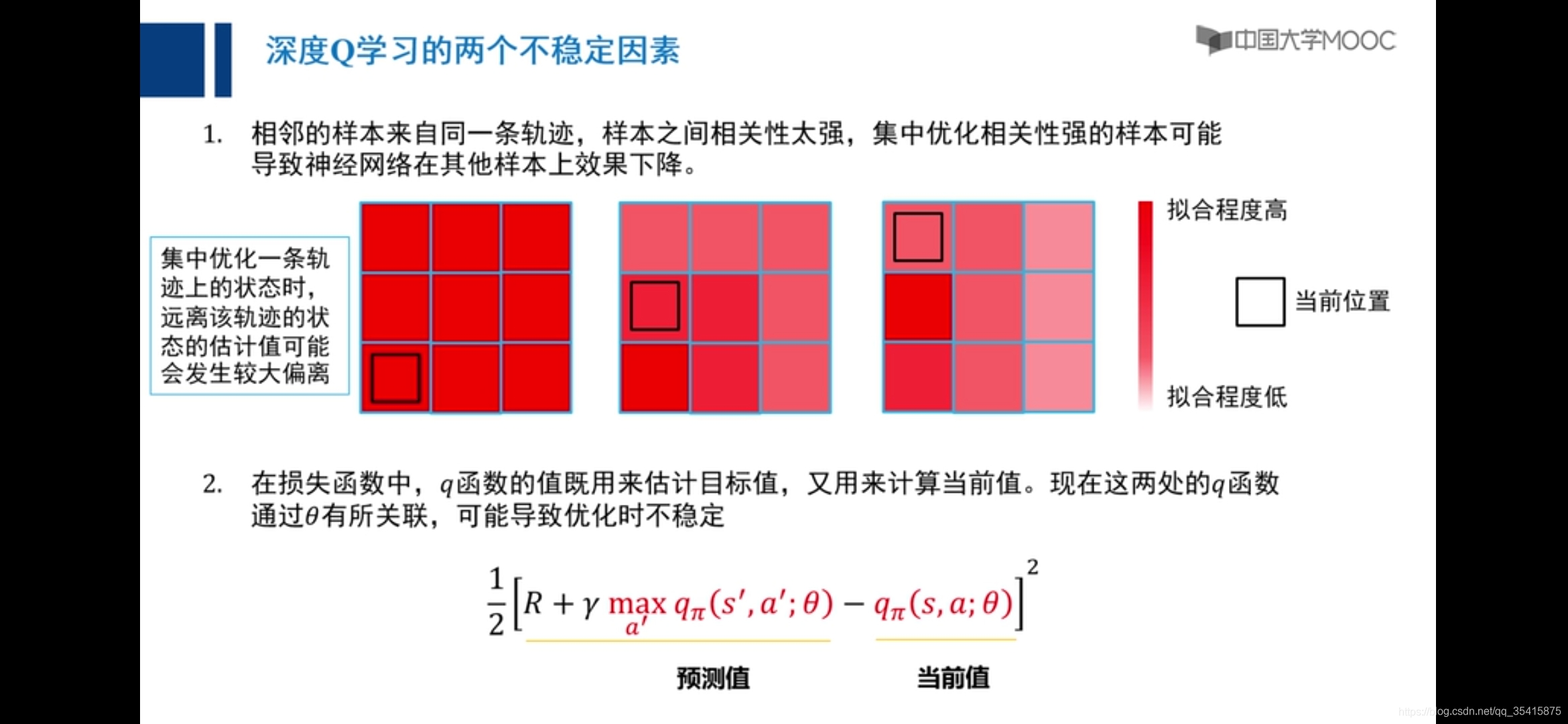
???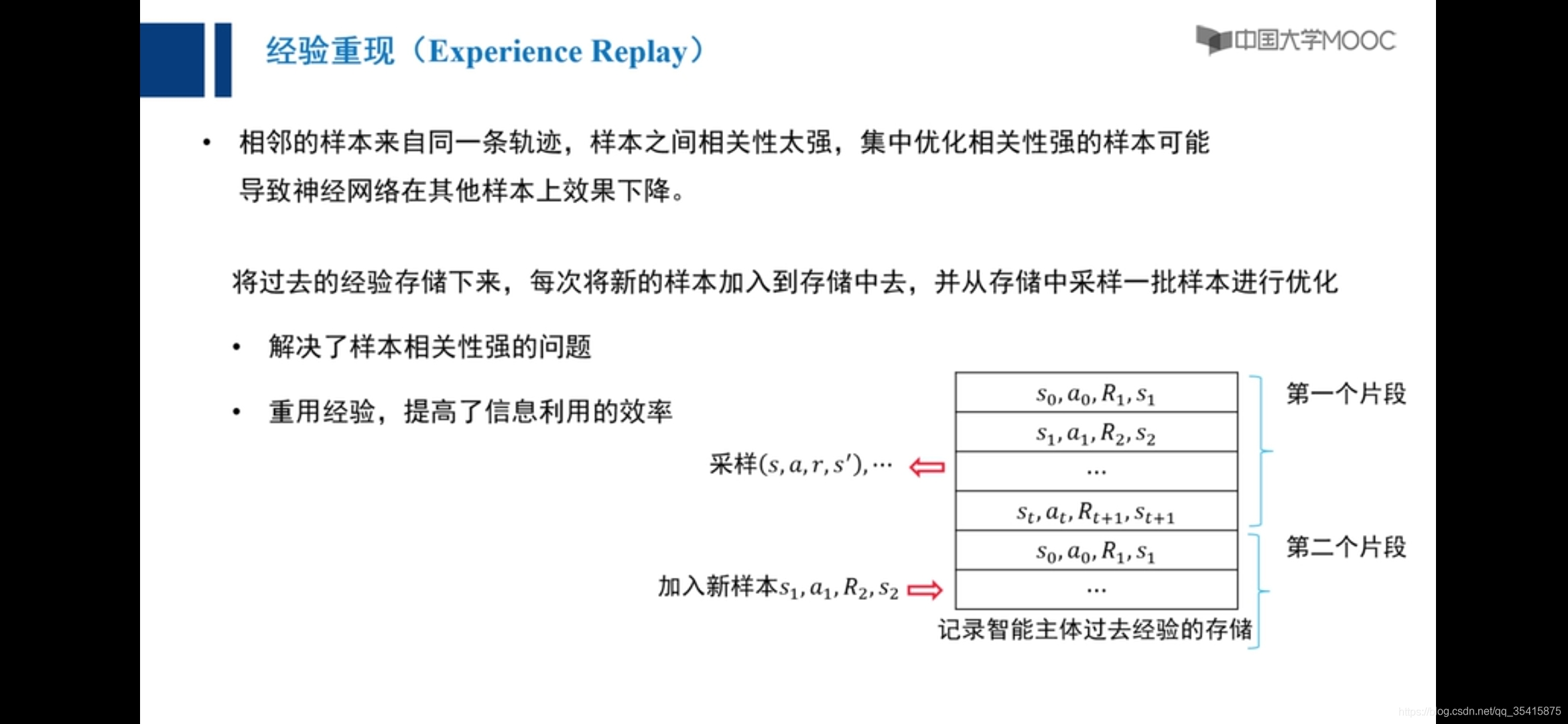
??
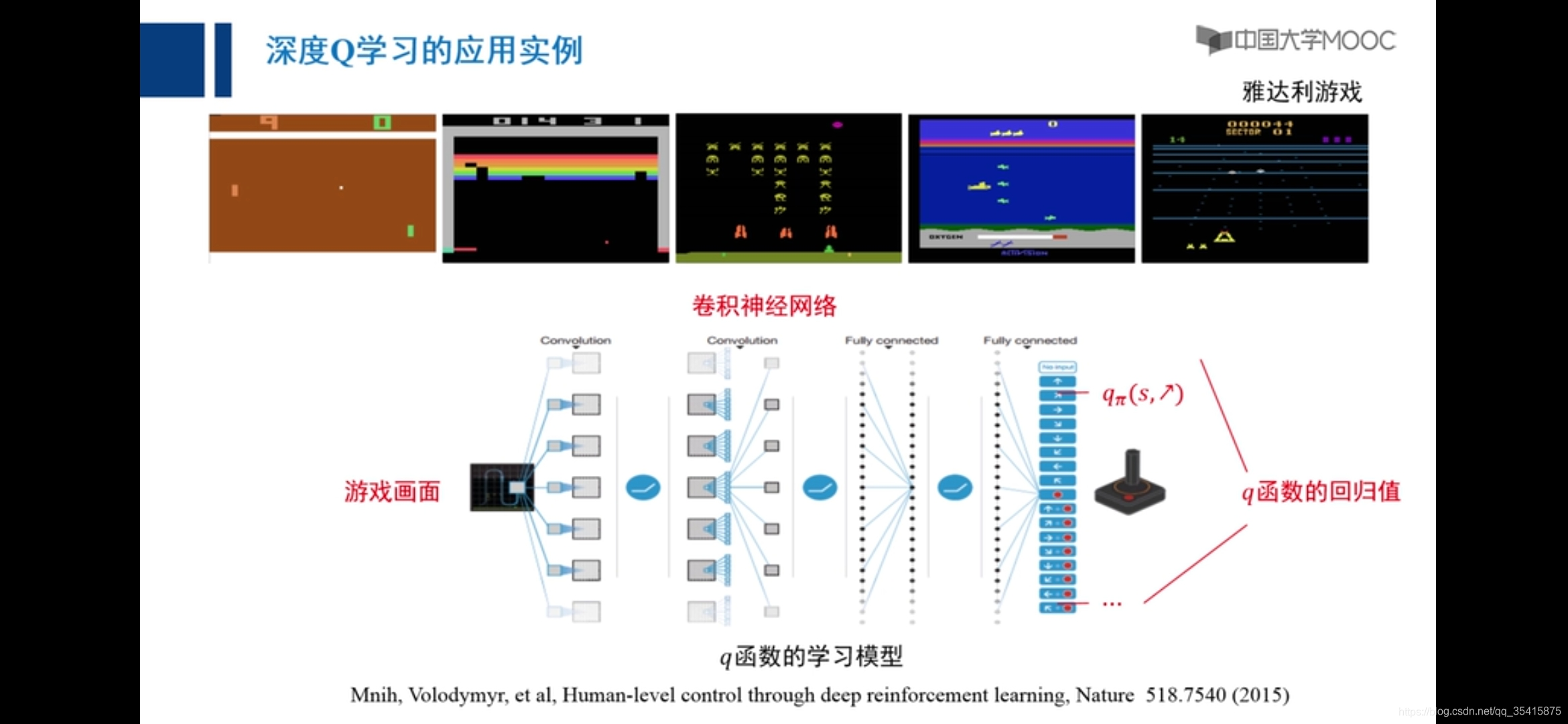
??
博弈相关

囚徒困境
纳什均衡:





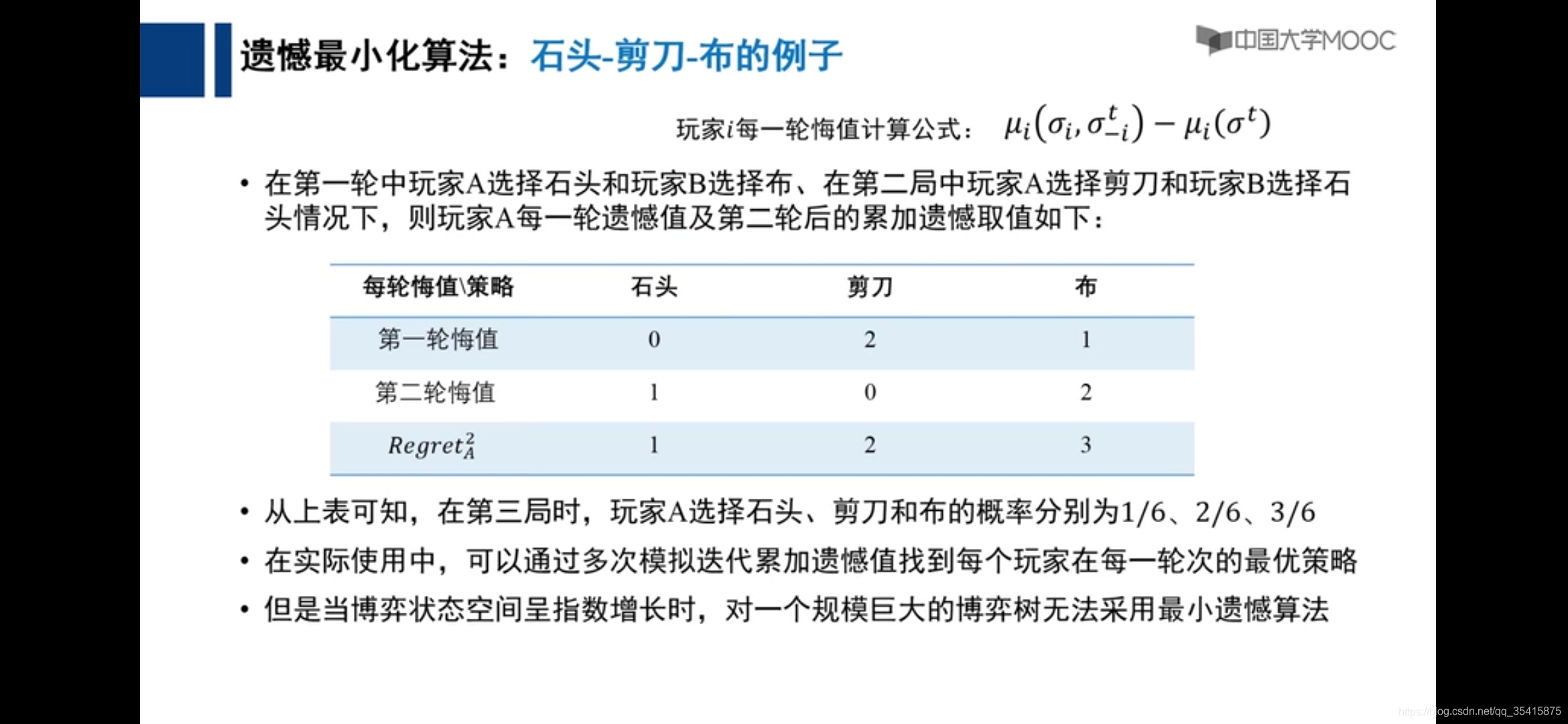
遗憾最小化算法
这页可暂时跳过指知道u表示获取收益即可




虚拟遗憾最小化算法
人工智能安全




通过对伪造数据一次次的训练达到可以识别伪造数据的效果来对抗白盒攻击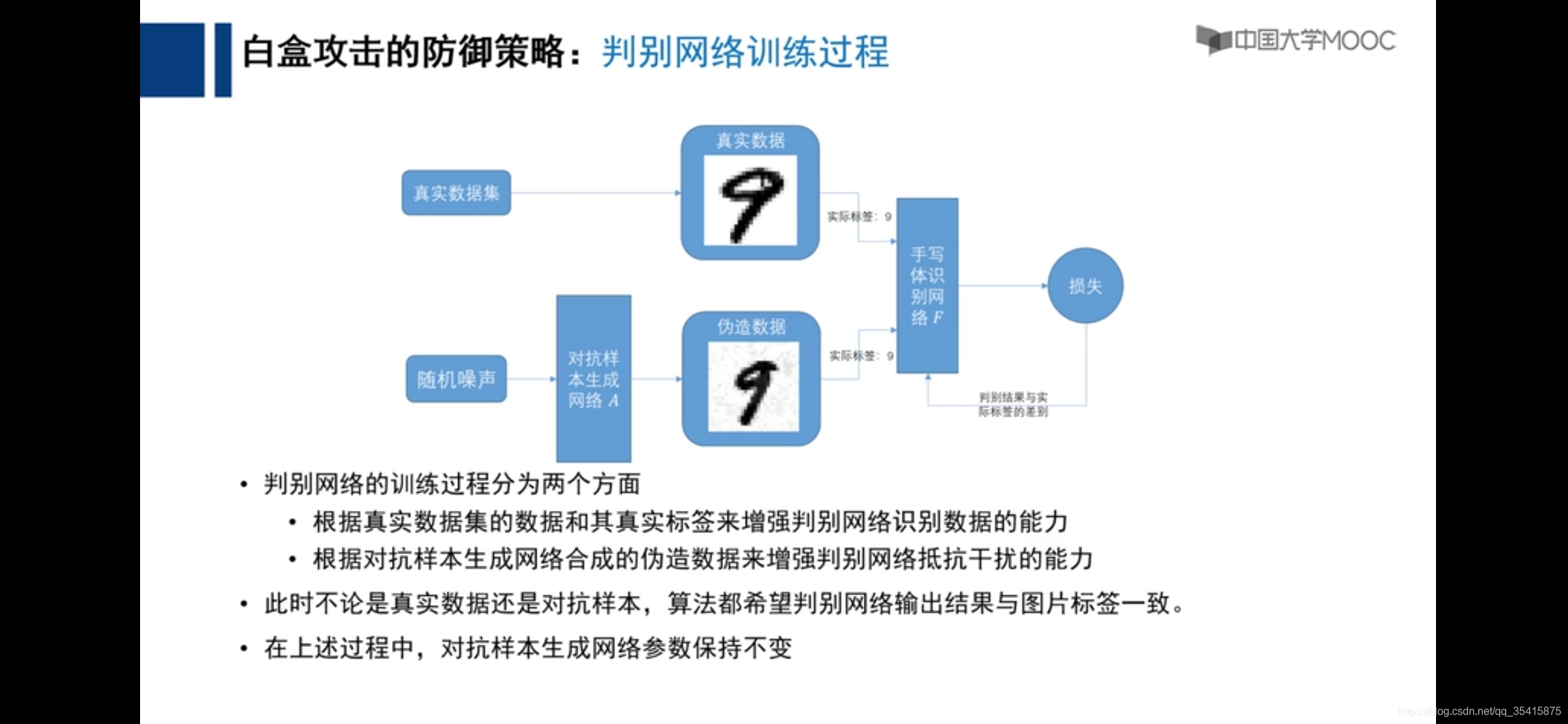
通过对数据的标签故意写错而判别网络不变,通过将这种误差传递给伪造数据网络,意味着只能是数据改变,趋近于故意给定的标签,以此来达到造储对抗数据的目的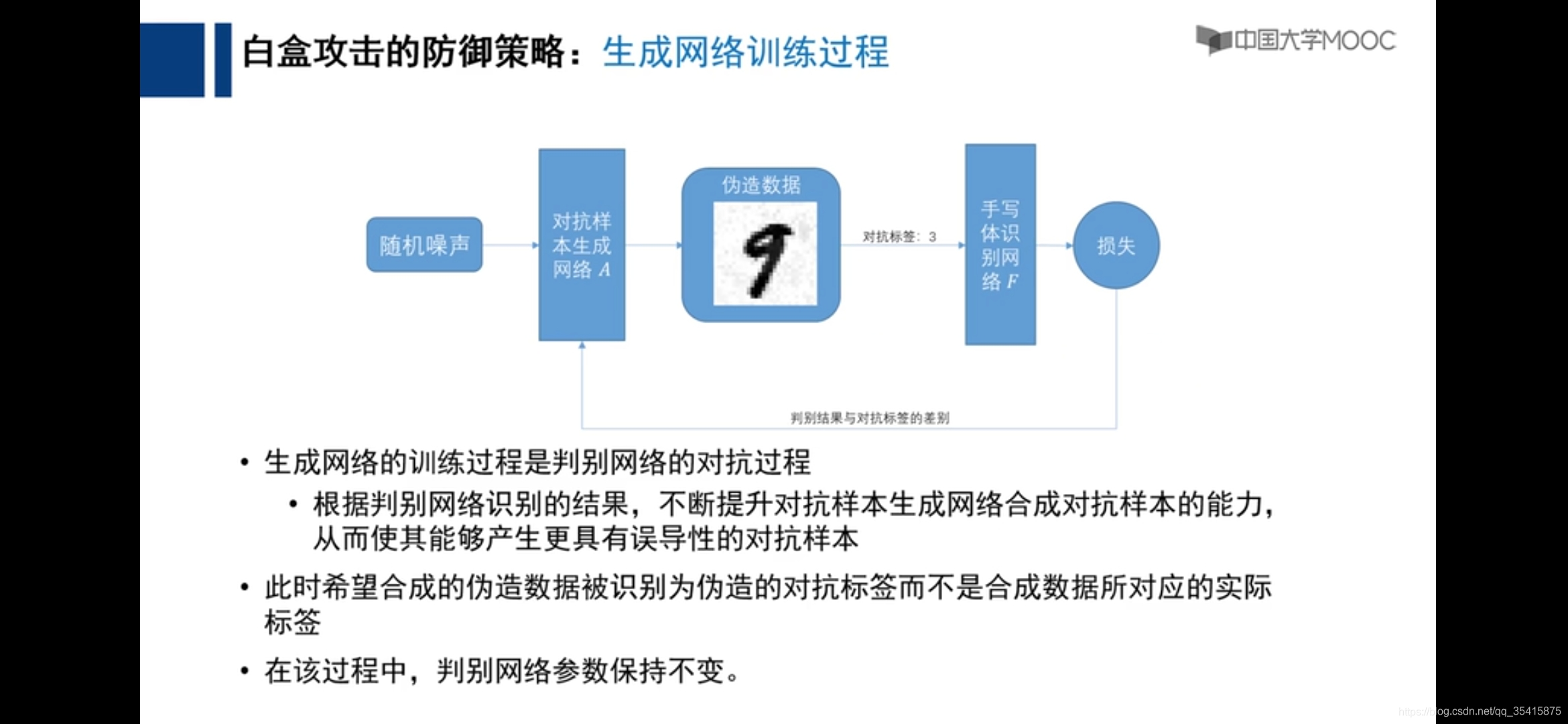



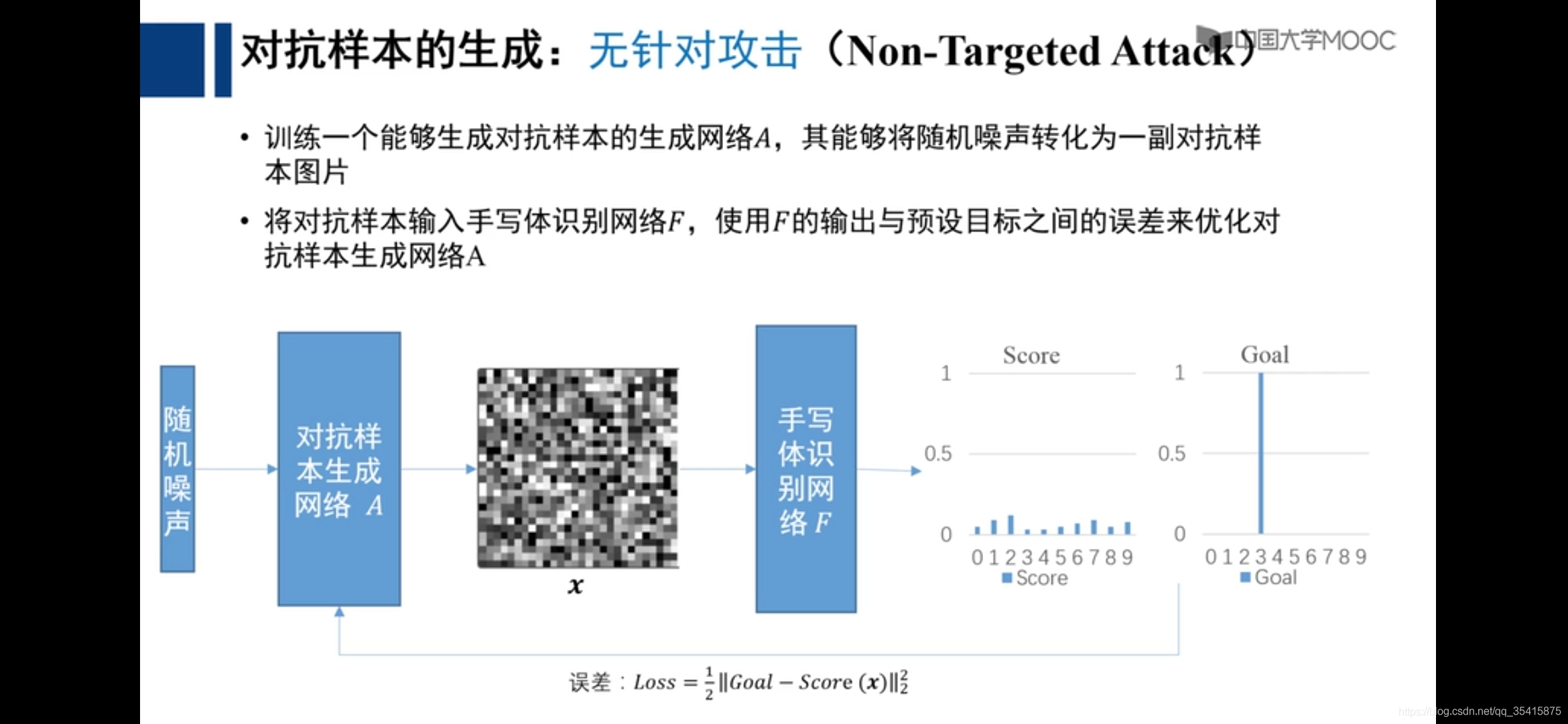
无针对攻击模式对于输入样本是随机的噪声数据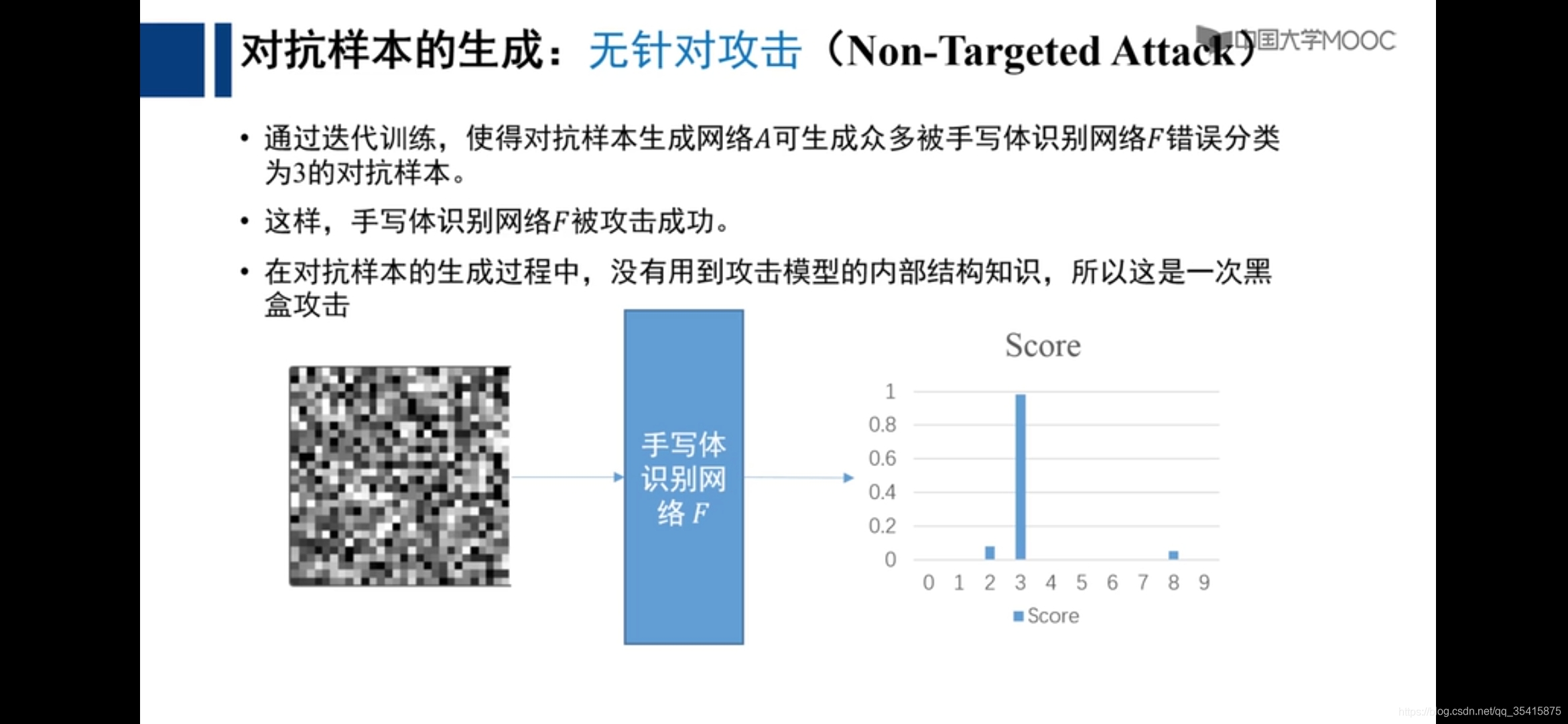
人可识别的数据通过网络进行改变直至其趋近于错误标签

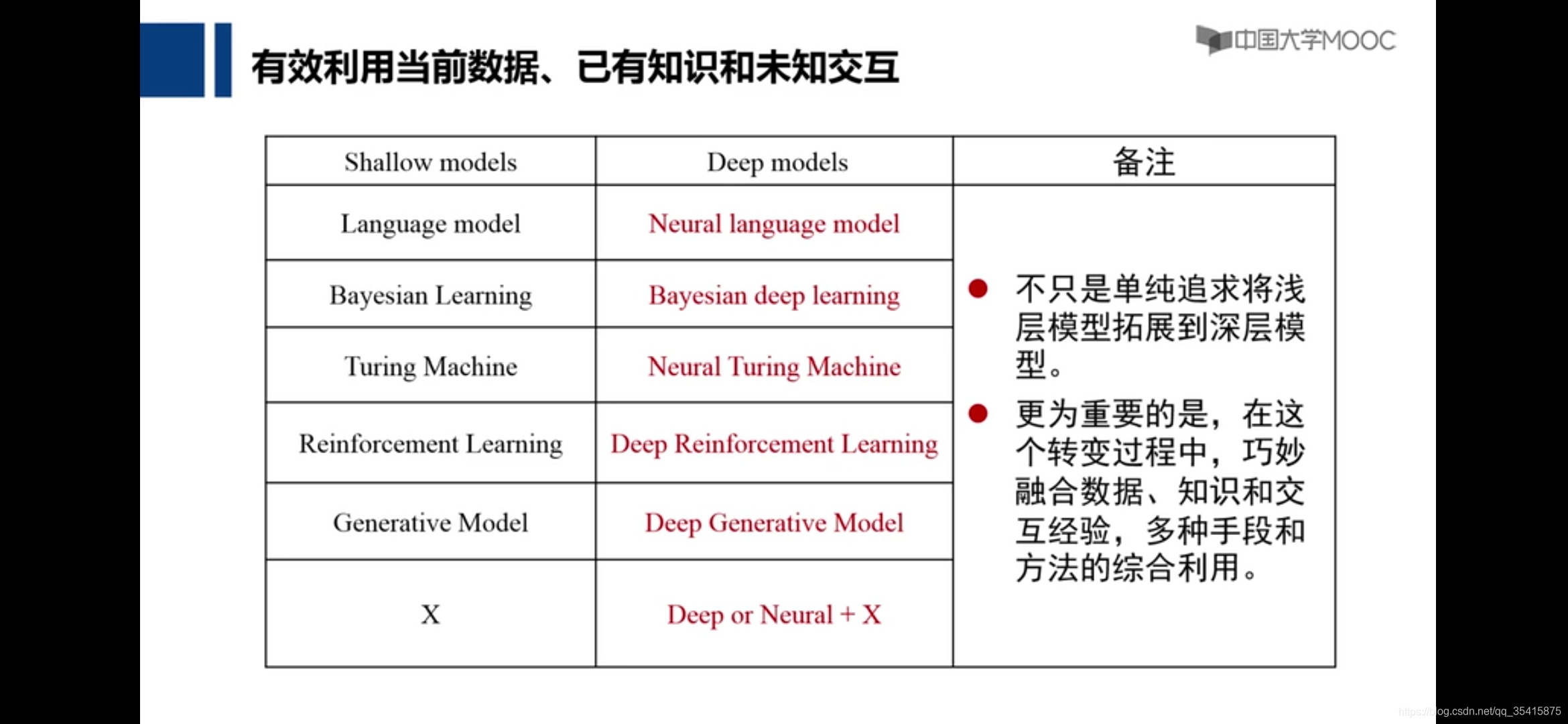
记忆所驱动的智能计算
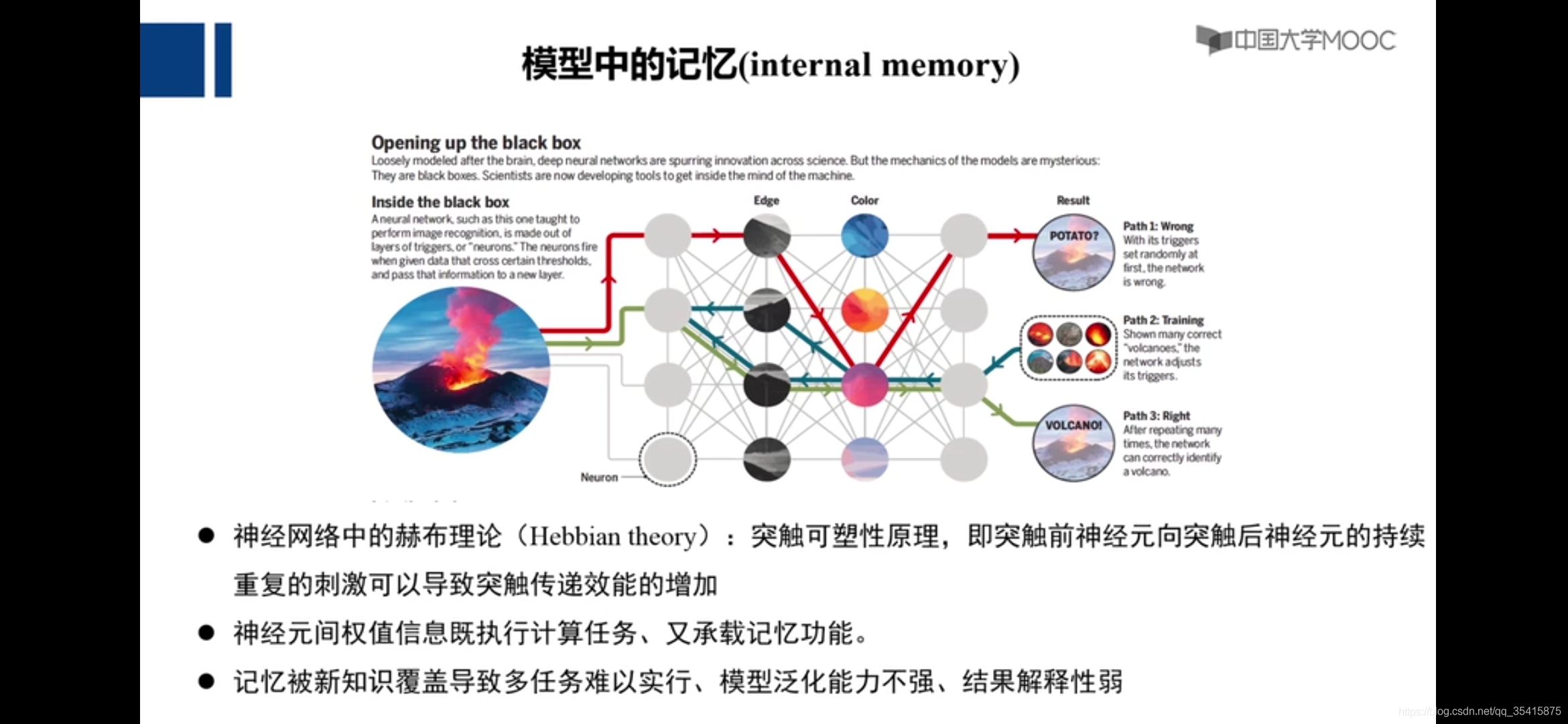
神经图灵机:不仅使用了当前的输入数据,也使用了先前放于记忆体中的大量数据和先验知识,来处理当前数据
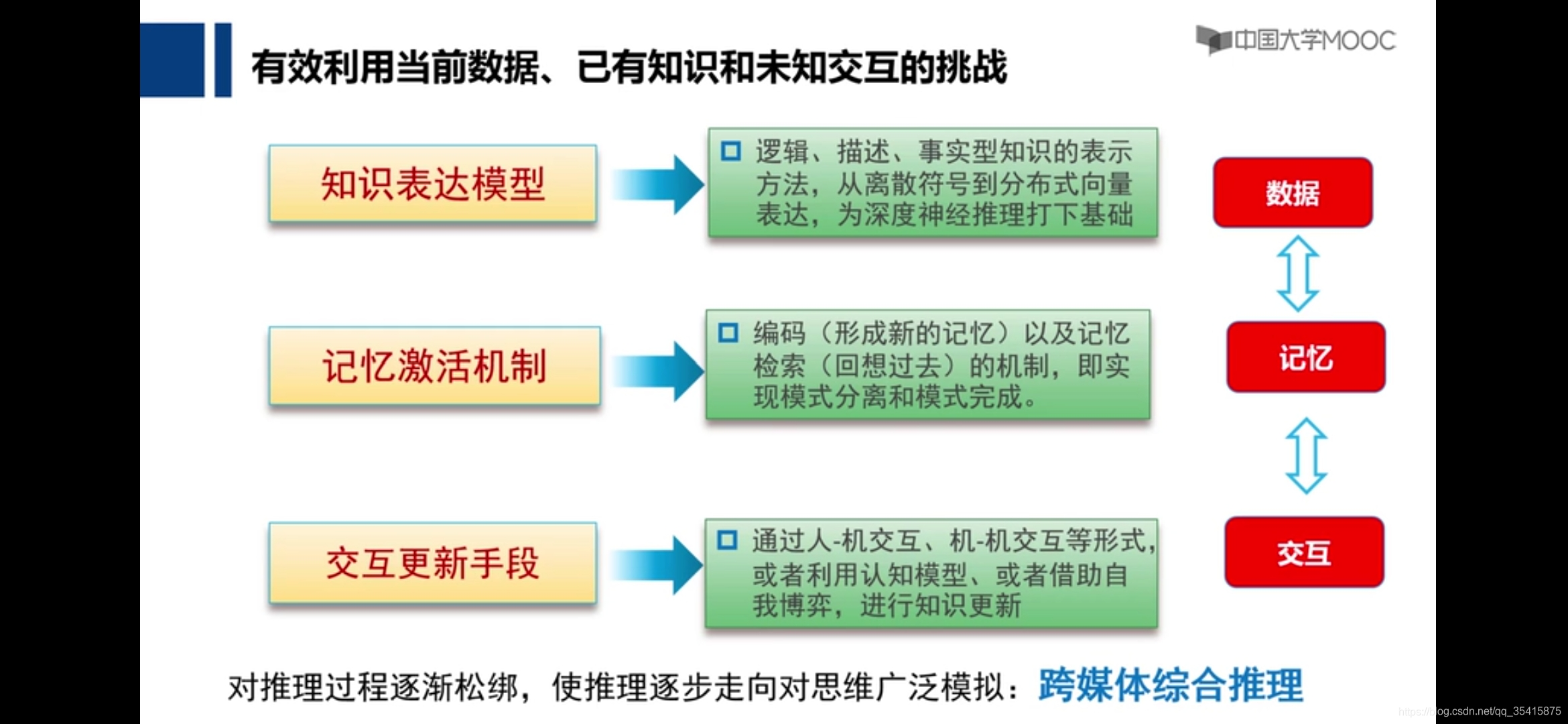
一个可以根据已有经验推理,可以根据数据学习,可以进行简单试错学习做出决策的机器,有了判断,加之权重激活,又为什么不可以说是智能生命体呢?
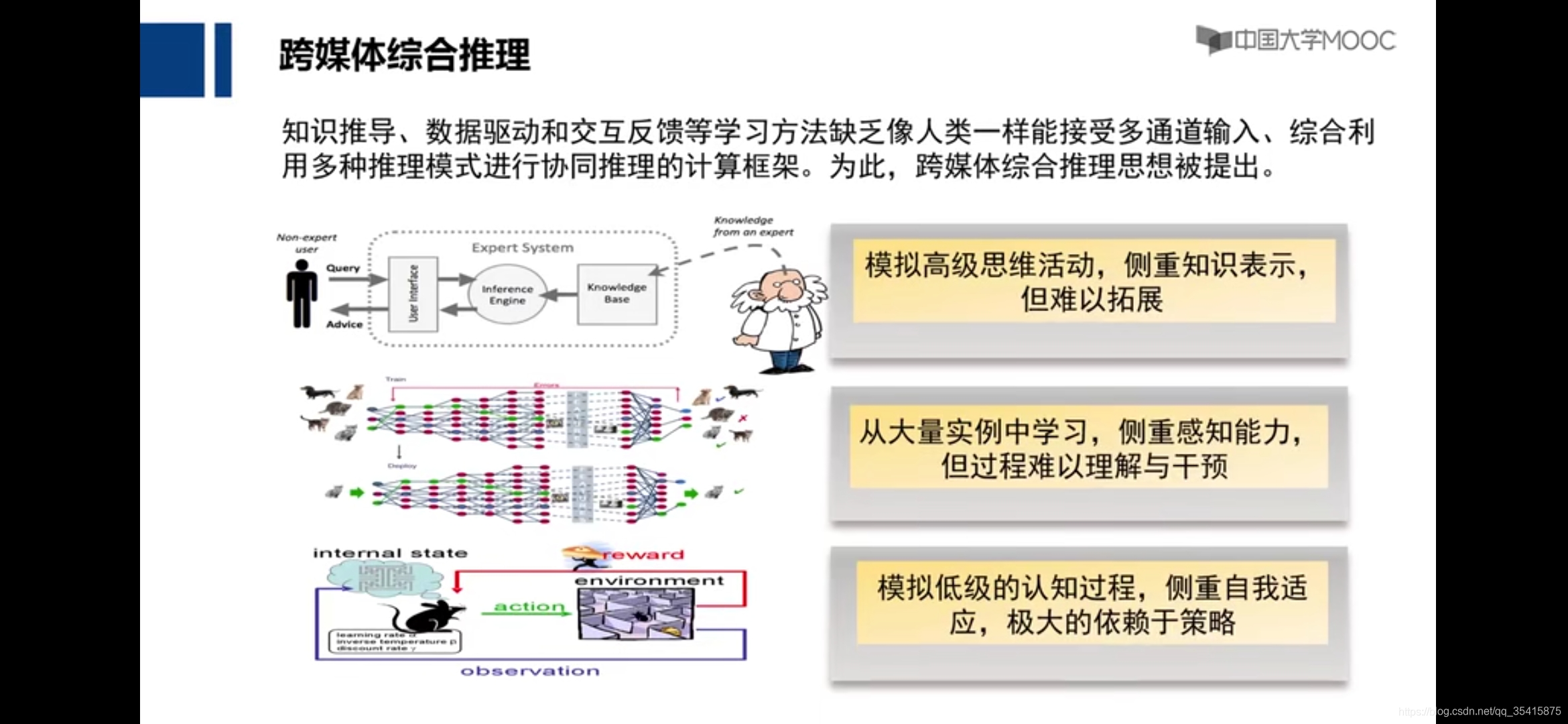
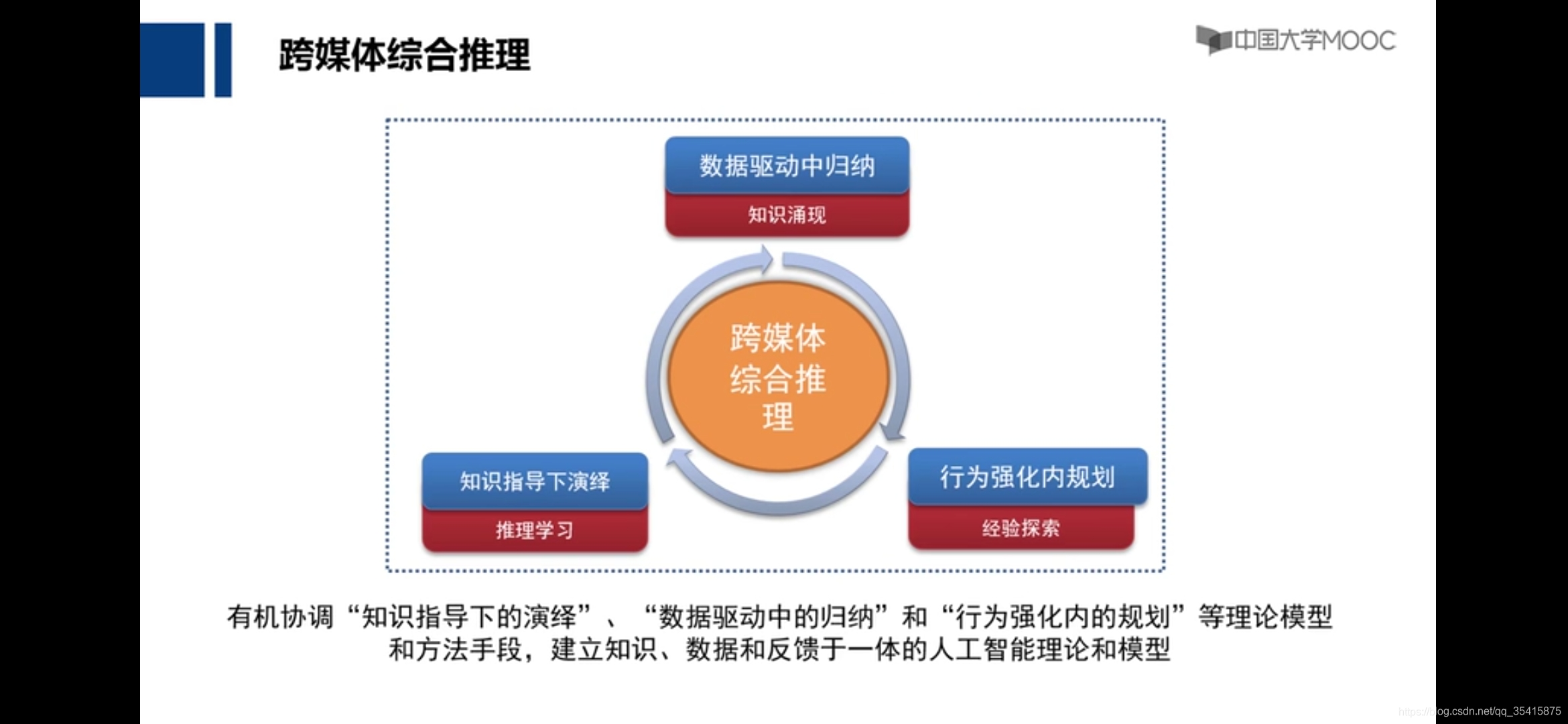
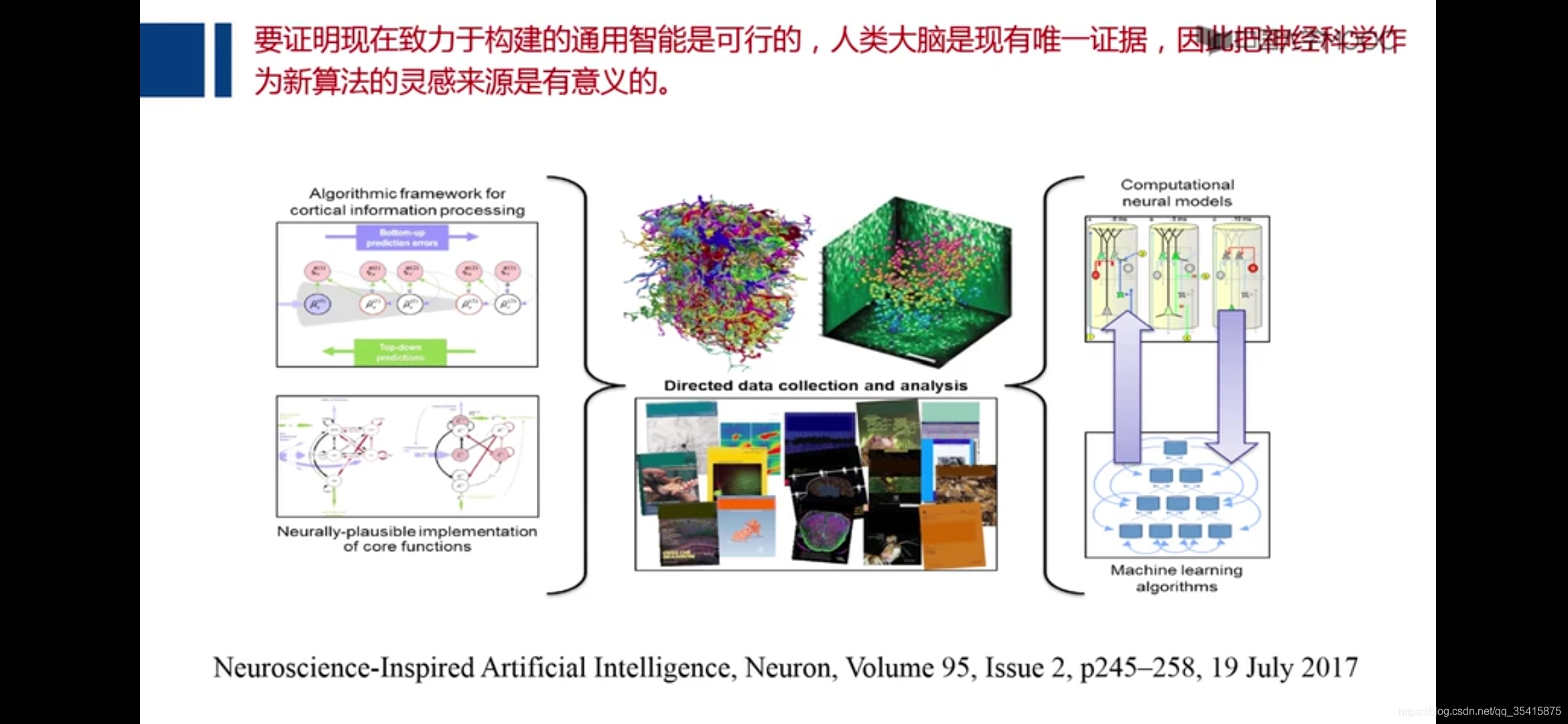
可计算社会学

传统社会学:
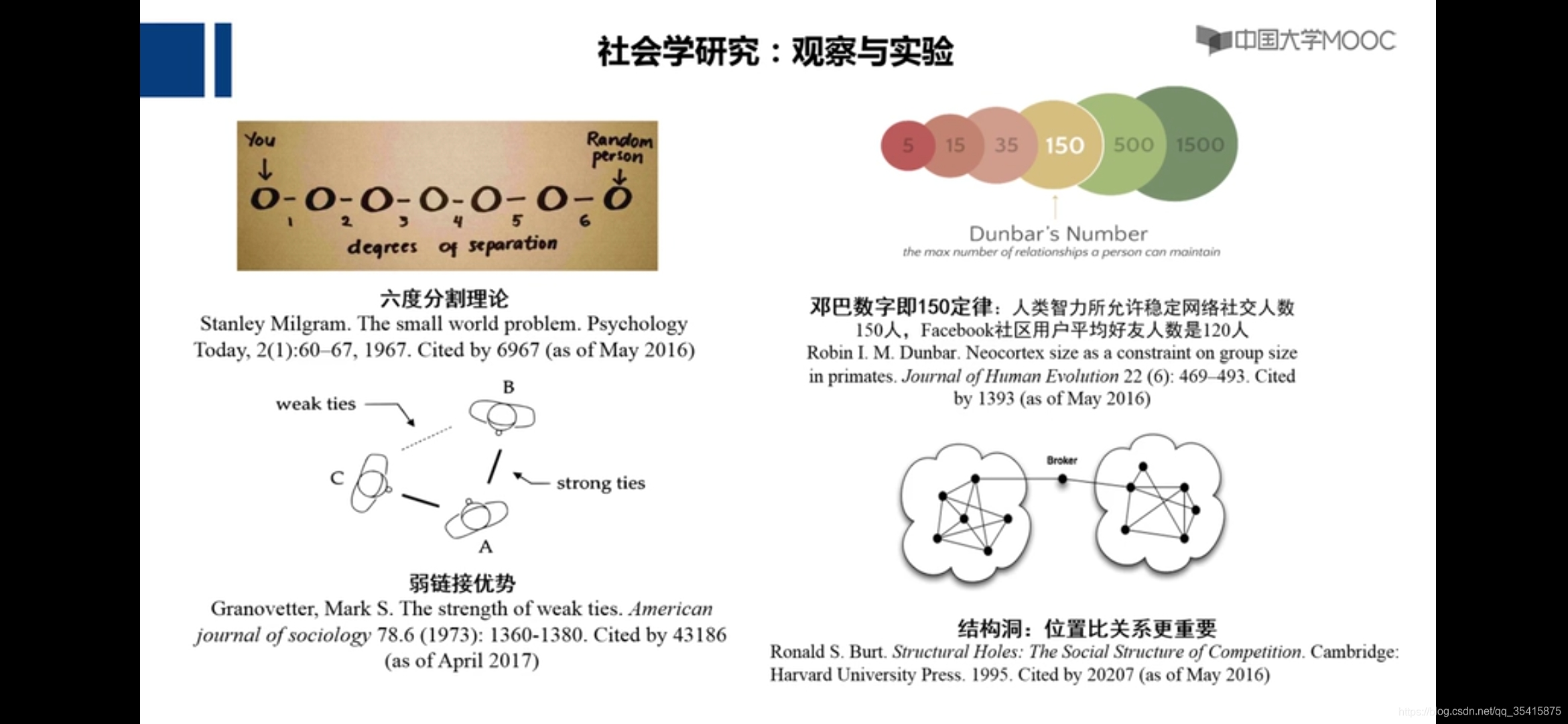



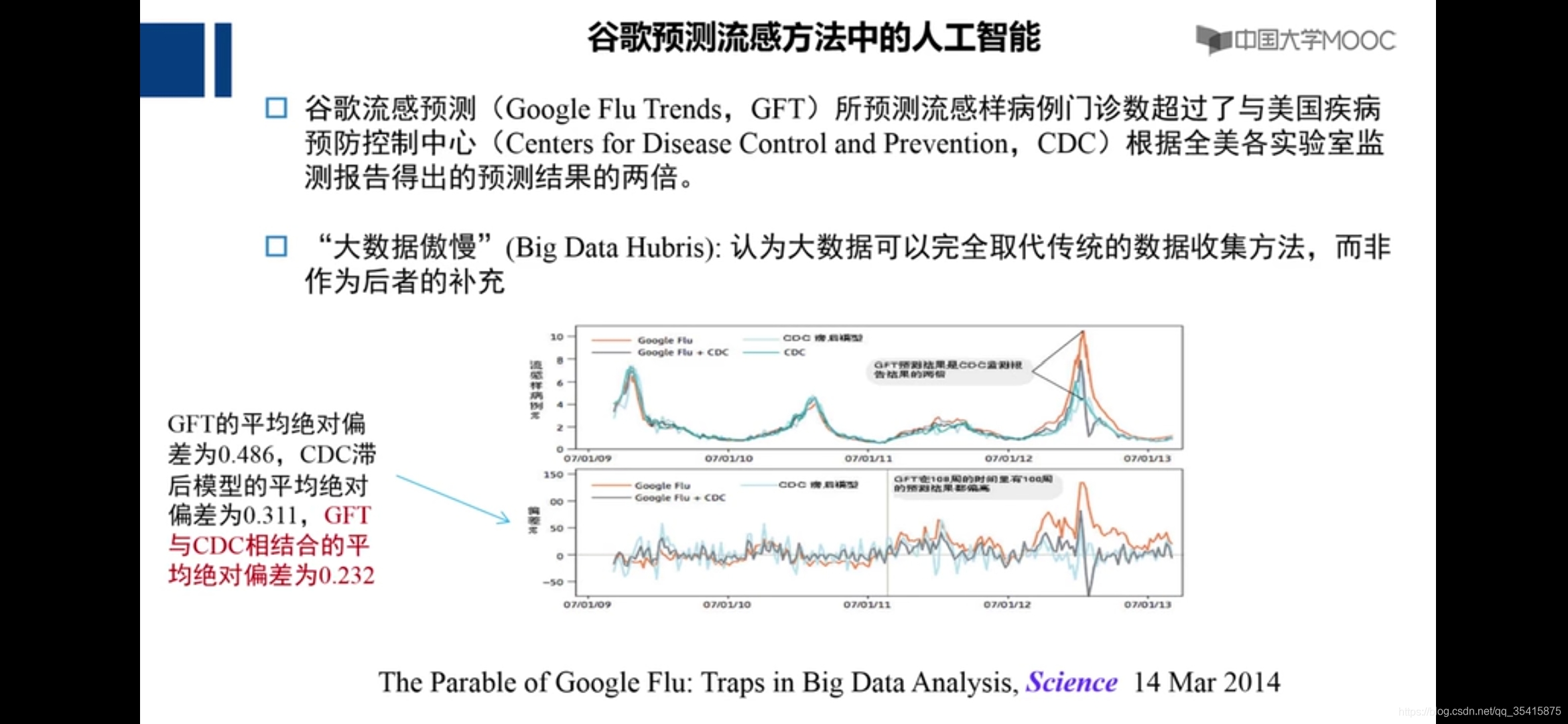

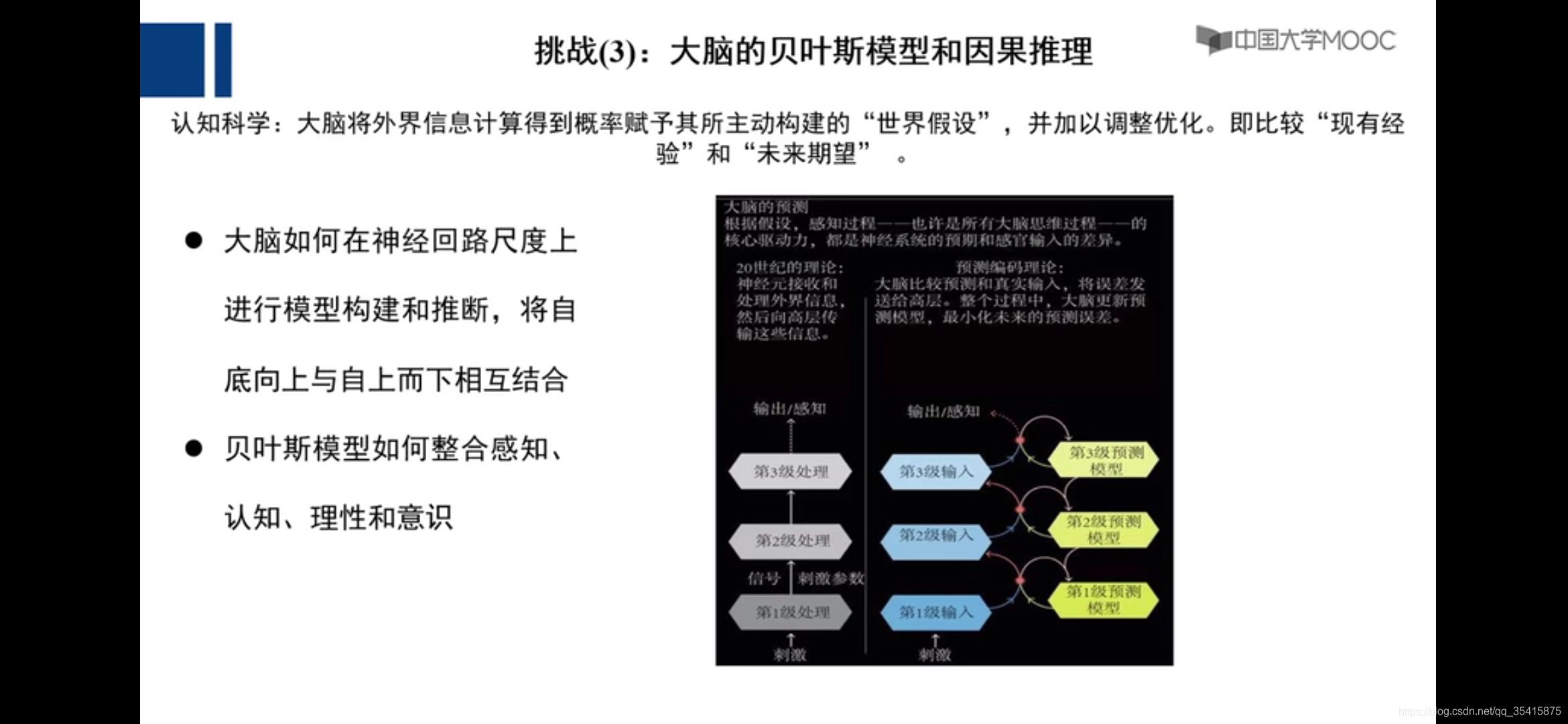
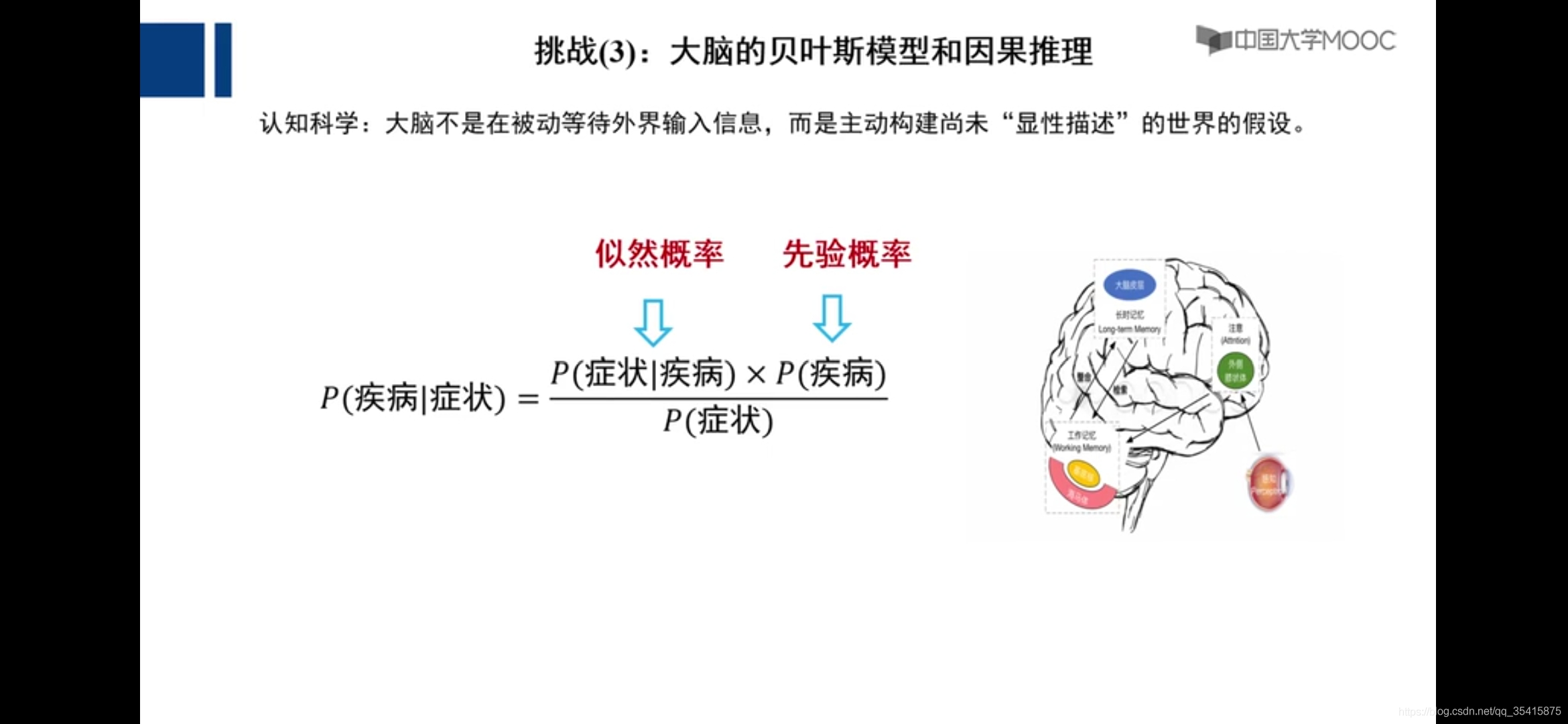
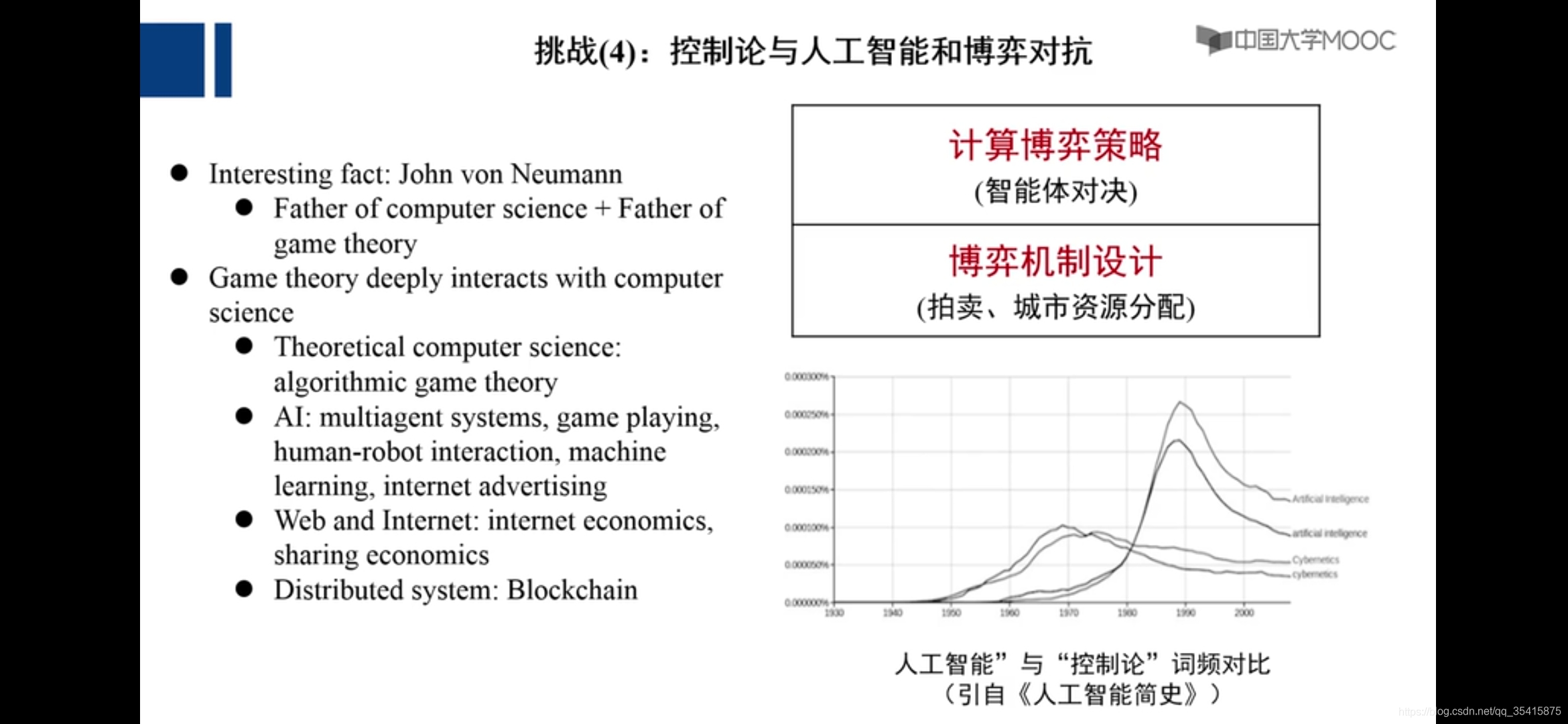
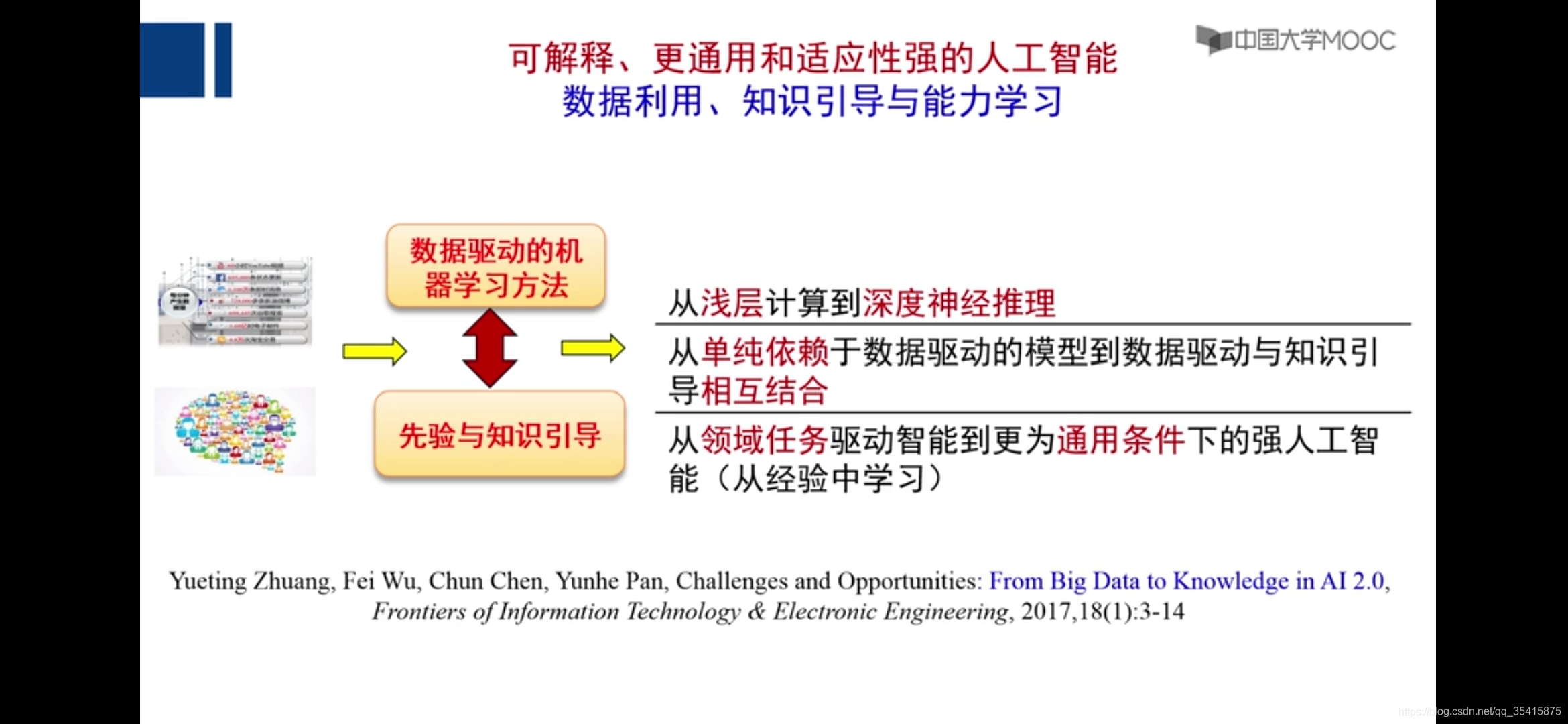
若干挑战


 元学习:学习学习的能力(有点悖论,让没学习能力的机器,通过学习学习得到学习的能力)****
元学习:学习学习的能力(有点悖论,让没学习能力的机器,通过学习学习得到学习的能力)****
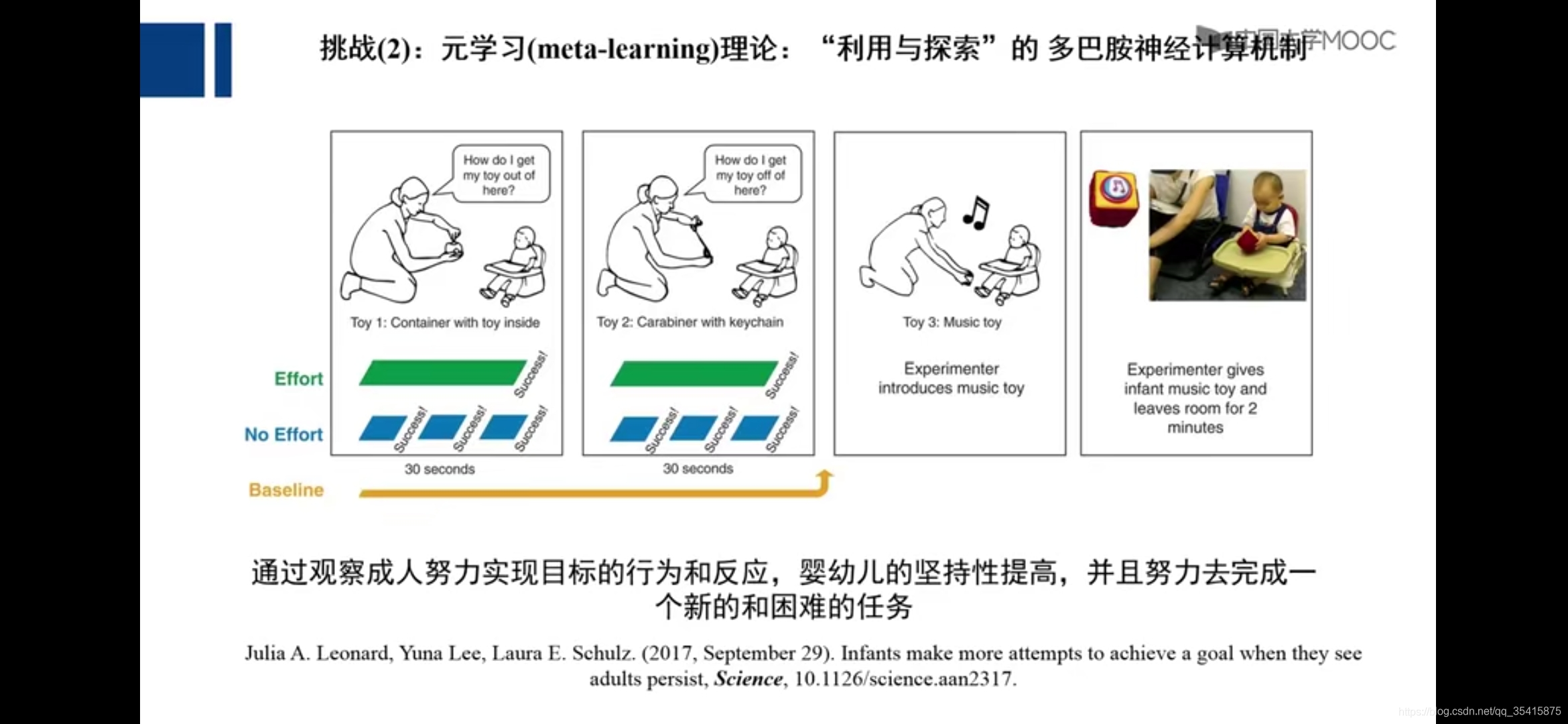
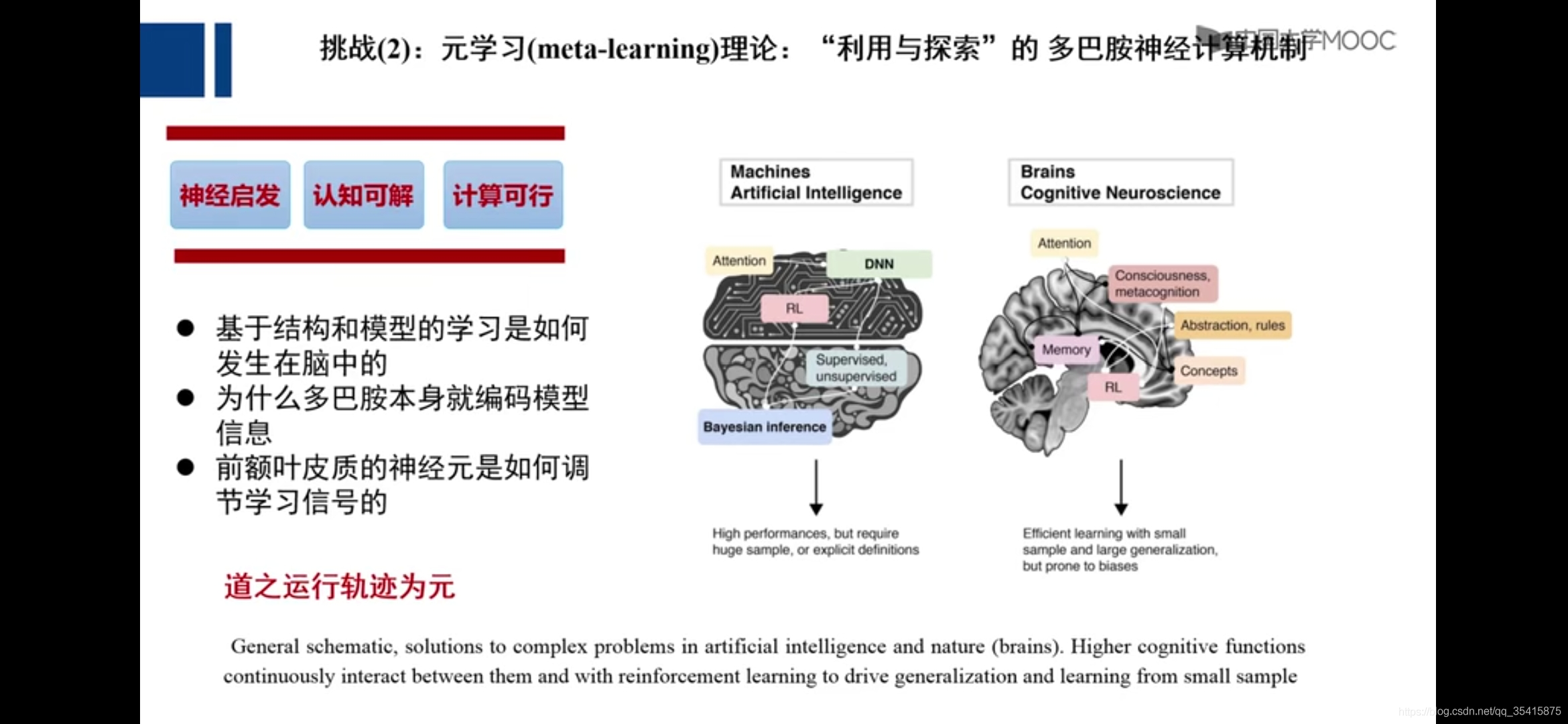















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









