







DSSD是 Cheng Yang Fu和Wei Liu一起合作的,对于SSD一个提升,他们对于SSD的优缺点了如指掌,所以对于SSD的提升也有很多的经验。
arxiv: https://arxiv.org/abs/1701.06659
github: https://github.com/chengyangfu/caffe/tree/dssd
github: https://github.com/MTCloudVision/mxnet-dssd
demo: http://120.52.72.53/www.cs.unc.edu/c3pr90ntc0td/~cyfu/dssd_lalaland.mp4
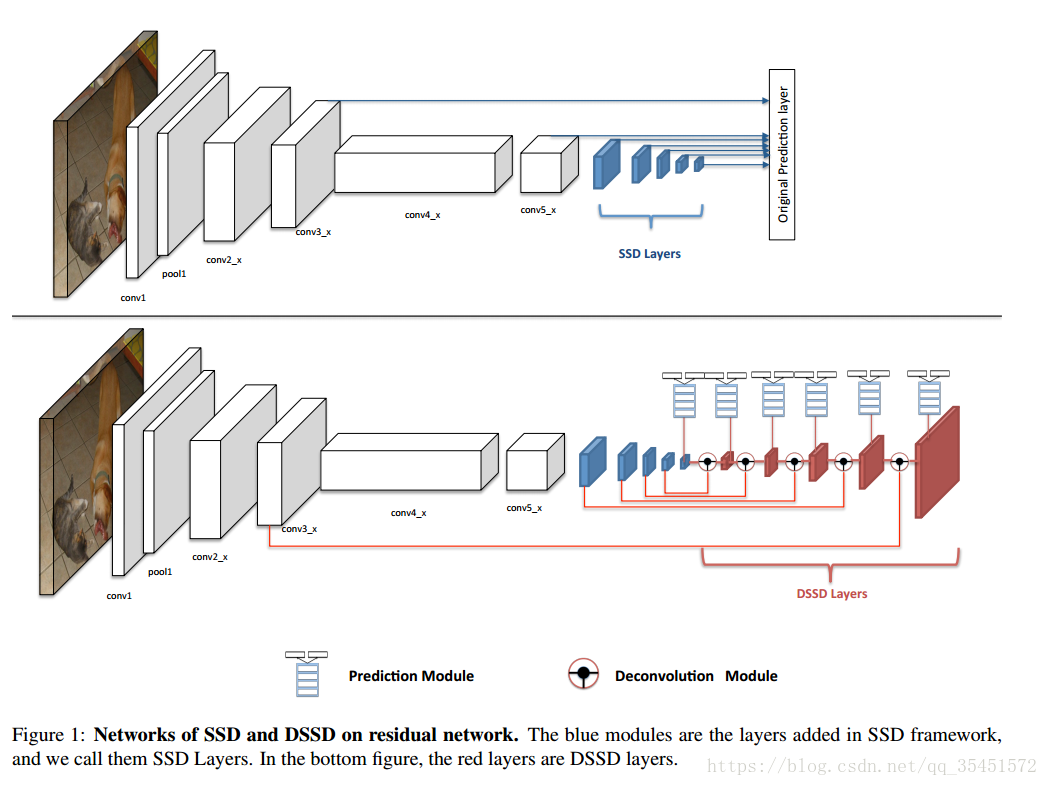
DSSD针对小目标鲁棒性太差,提出了以下两个贡献:
1. 把SSD的基准网络从VGG换成了Resnet-101,增强了特征提取能力;
2. 使用反卷积层(deconvolution layer )增加了大量上下文信息。
从上边的图片中能够看出整个网络是采用了一个类似沙漏(hourglass,即encoder-decoder)的结构。前边采用ResNet-101进行网络特征的提取,SSD中是在提取网络以后又加入了SSD层,而DSSD是在其基础上加入了DSSD层。低分辨率的特征信息作为上下文信息,通过反卷积与前边两倍分辨率的特征图像进行融合,最后通过一个预测模块进行预测。
Prediction Module
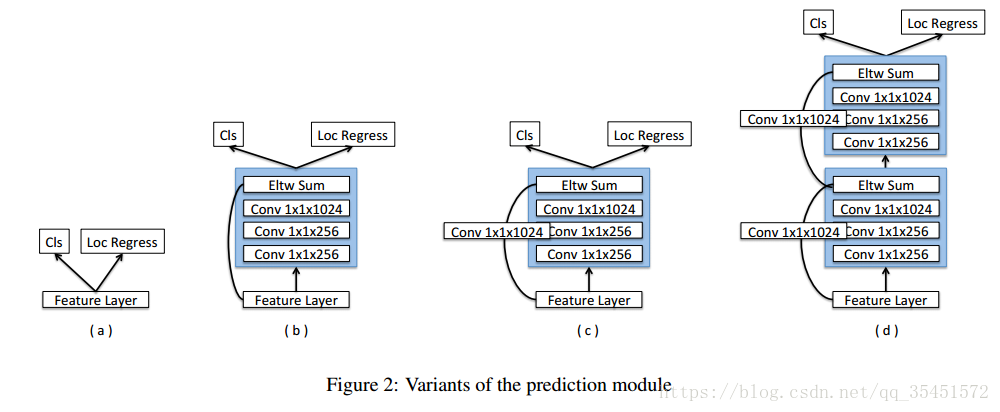
如上图所示:
(a)为原SSD对于特征信息进行分类与定位的模型,其实并没有预测模块,直接进行预测;
(b)为作者在预测之前加入了residual block模块;
(c)将residual block模块中直接映射identity mapping换成了1x1卷积
(d)堆积residual block模块
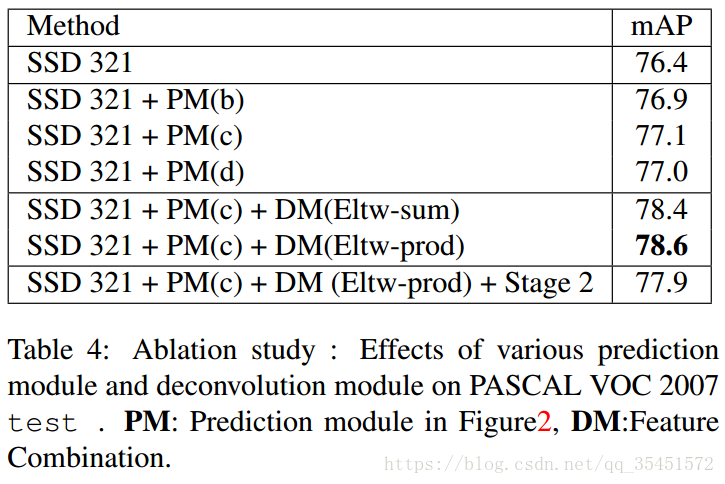
MS-CNN方法指出,改进每个任务的子网可以提高准确性。根据这一思想,作者在每一个预测层后增加残差模块,并且对于多种方案进行了对比。如上图所示,经过试验证明,添加(c)结构模块后,高分辨率图片的检测精度比原始SSD提升明显。
这里边还包括在对PM,就是下图中卷积与反卷积所得到的两个矩阵如何进行合并。Eltw Product方法分为sum与prod两种。sum是默认操作,就是将A和B相加减。prod表示点积,MAX求最大值。通过实验对比能够看出使用prod方法得到检测结果的准确率更加高一点。
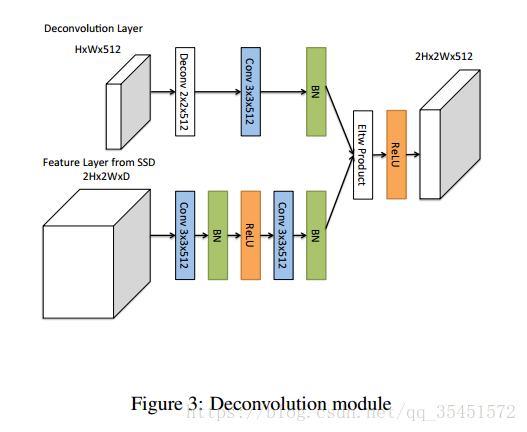
第一幅结构图中,红色的小圆圈就代表着反卷积模块,就是代表上图中的结构。作者在设计的时候,考虑到预测时间以及初始化参数的曹锁,所以将上边的反卷积操作设计成一个比较浅层。利用反卷积进行特征信息的提取作者是参考Learning to refine object segments 论文中的想法。
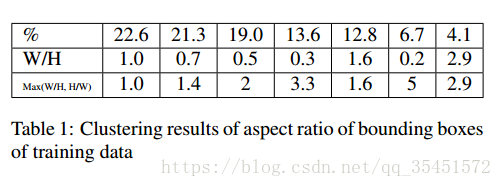
作者在DSSD中也是采用了K-means聚类方法对框的长宽比例进行聚类,根据数据集用K-means聚类方法重新得到了7种default boxes维度,得到上边图片所示的比例,使用这些比例能够更加具有代表性。

上表说明了在VGG和ResNet上哪些层作为最后的预测feature layer。将VGG替换为ResNet并不是简单地进行替换,还需要考虑使用哪些体征层作为最后预测的层,这里边需要主要的是ResNet选择的层感受野与VGG选择层的感受野应该相对应,不然检测效果会变得更差。

最后的检测结果如上图所示,通过对比能够明显看出在SSD与DSSD都是用321输入的时候,DSSD效果都优于SSD。而使用DSSD 513的时候效果更是有了更大的提升。
参考
论文阅读-《DSSD : Deconvolutional Single Shot Detector》 - CSDN博客
DSSD: Deconvolutional Single Shot Detector 论文笔记 - CSDN博客














 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









