







1. 过拟合(Over fitting)的定义
为了更好的描述欠拟合和过拟合,我先借用一下吴恩达课程中的一张图来描述一下。
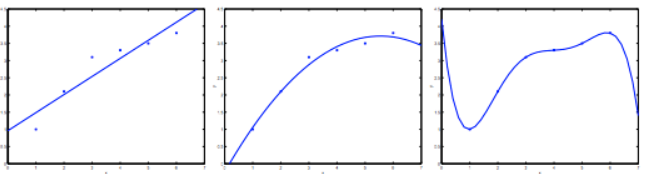
对于一个简单的数据集(x,y),x代表特征,y代表结果。
上图中的左边这幅图,它采用了只有两个参数的hypothesis:(
表示偏置),我们可以看到这个函数不能很好的拟合所有的点,也称这个模型欠拟合。
对于中间这幅图,它加了一个特征:;从而得到有三个参数的hypothesis:
得到图中的一条曲线,我们可以看到其拟合效果还算可以。
对于最右边的这幅图,我们在最左边的图的基础上给它添加了多个参数是hypothesis变成了一个五次多项式:,我们可以看到这个曲线穿过了图中所有的点,但是用于测试数据时,其正确率可能会很低,因为他过分拟合了测试集中的数据而使假设变得过度严格,这种情况可称之为过拟合。过拟合的征兆一般是在训练集上正确率很高,但是在测试集上正确率很低。
2. 过拟合的解决方法
我们从上面过拟合的例子可以知道,因为参数过多导致了过拟合的发生,那么过拟合的解决方法就有以下两种:
- 人工选择参数,减少一些不必要的参数
- 让模型自动的选择参数,或者降低不必要的参数的权重
- 增大训练集
对第一种方法,实际可行度不高,因为需要做大量的测试才能确定一个参数是否有用。所以一般采用第二种方法,该方法也叫正则化(Regularization)。
3. 正则化
正则化防止模型过拟合的做法就是保留所有的特征但是减少该特征所对应的参数的大小,也就是中的
的大小,从而使该特征在整个模型中的权重减少。
4. 正则化后的线性回归模型
加了正则化后的线性回归模型的Cost function为:
上式中,m表示训练样本的数量,n表示参数的个数,表示正规系数。这里我们要注意对
不做正则化,因为
表示偏置,没有对应的特征。
与上式Cost function相对应的Gradient descend步骤如下:
因为Cost function中加入了每个参数的平方,那么如果该参数对应的特征没有多大用处的时候,梯度下降过程中就会对该参数减少,从而改变该特征的权重。














 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









