






许多人对编程面试(coding interview)感到恐惧,这可能是他们觉得编码面试压力大,艰巨和挑战性的。通常不知道如何去准备。
今天,将向您介绍在编程面试中涉及到的主要数据结构和算法,阅读本文后,您应该对需要做哪些准备才能找到梦想的工作有一个好思路。
我们将介绍以下内容:
- Why should you learn data structures and algorithms?为什么学习数据结构和算法
- Understanding Big O notation理解大写O
- Important data structures to learn重要数据结构的学习
- Important algorithms to learn重要算法学习
- What to learn next接下来要学什么
为什么学习数据结构和算法
编码面试可以测试面试者者解决问题的能力和对计算机科学概念的理解。通常,您将获得30-45分钟来解决一个复杂问题。
这就是数据结构和算法的用武之地。这些面试可以测试一般有这几个方向:链表,队列,排序,搜索等主题,因此准备工作至关重要。
如果获得这份工作,您将经常遇到需要修复的错误,并且公司希望确保您可以克服这些障碍。此外,您将经常使用特定的数据结构和算法来优化代码,从而使其尽可能高效地运行。
理解大写O
是一种渐进分析,描述了算法执行所需的时间。换句话说,它是用来描述算法的效率或复杂性。
大写O描述了算法随着N的不断增加该算法的执行时间或者运行时间。尽管我们可以使用平均情况和最佳情况来分析算法的效率,但是我们通常使用具有O表示法的最差情况。
今天,您将了解时间复杂度,但请注意,空间复杂度也是一个重要的概念/首先,运行时复杂性可能时一个很难理解的概念,让我们看一些示例。
O(1)
public int findInt(int[] arr) {
return arr[0];
}O(1)描述一个算法,无论其输入如何该算法执行时间不变。无论数据包含一千个整数还是一个整数,该函数执行时间都是一定的。因为都只需要执行一次。
public int func(int[] arr) {
for (int i = 1; i <= arr.length; i++) {
for (int i = 1; i <= arr.length; i++) {
System.out.println(i);
}
}
}![]() 描述一个函数整体运行时间是输入长度的平方。这类运行时间一般是嵌套循环,外侧循环N,内侧需要执行N2步。
描述一个函数整体运行时间是输入长度的平方。这类运行时间一般是嵌套循环,外侧循环N,内侧需要执行N2步。
要记住一些关规则:
忽略常数:当我们使用O时,通常是不考虑常数的,比如即使运行复杂度是O(2N), 我们依然称之为O(N)
去掉不太占优势的项:我们通常只保留最主要的项。比如![]() 通常:
通常:

另外关于O的文章有可以同步阅读:https://www.educative.io/blog/a-big-o-primer-for-beginning-devs
重要的数据结构
用最简单的术语来说,数据结构是在计算机中组织和存储数据以便对其进行访问和修改的方式。您将学习在编程面试中测试的重要数据结构的基础。
数组
数组是顺序存储在存储器中的相同的变量类型的项目的集合。它是最流行和最简单的数据结构之一,通常用于实现其他数据结构。
数组中的项目索引从0开始,并且每个项目项目都称为元素。还需要注意的是,在Java中,您不能更改数组的大小。对于需要动态大小的数据,建议使用链表。

在上面的示例中:
- 数据的长度是5
- 索引3的值为1
- 在Java中,此数组中的所有值都必须是整数类型
用Java初始化数组:
int[] intArray = new int[14];
intArray[3] = 5;
intArray[4] = 3;
intArray[13] = 14;
// Indexes with no value are null常见面试问题:
-
查找数组中的第一个非重复整数
-
以降序重新排列数组
-
向右旋转数组一个索引
-
使用分治法的最大和子数组
链表
链表是连在一起的一个线性序列,每一个节点包含一个值和一个指向列表下一个节点的指针。与数组不同,链表没有索引,因此您必须从第一个节点开始并遍历每个节点,直到到达我们想要第n个节点。最终一个节点将指向一个空值。
第一个节点称之为头,最后一个节点称为尾。下面是一个单链表
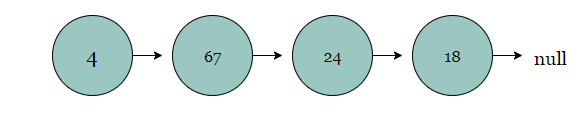
链表具有大量的应用:
-
实现堆栈,队列和哈希表
-
创建目录
-
多项式表示和算术运算
-
动态内存分配
Java中链表的基本实现
import java.io.*;
// Java program to implement
// a Singly Linked List
public class LinkedList {
Node head; // head of list
// Linked list Node.
// This inner class is made static
// so that main() can access it
static class Node {
int data;
Node next;
// Constructor
Node(int d)
{
data = d;
next = null;
}
}
// Method to insert a new node
public static LinkedList insert(LinkedList list, int data)
{
// Create a new node with given data
Node new_node = new Node(data);
new_node.next = null;
// If the Linked List is empty,
// then make the new node as head
if (list.head == null) {
list.head = new_node;
}
else {
// Else traverse till the last node
// and insert the new_node there
Node last = list.head;
while (last.next != null) {
last = last.next;
}
// Insert the new_node at last node
last.next = new_node;
}
// Return the list by head
return list;
}
// Method to print the LinkedList.
public static void printList(LinkedList list)
{
Node currNode = list.head;
System.out.print("LinkedList: ");
// Traverse through the LinkedList
while (currNode != null) {
// Print the data at current node
System.out.print(currNode.data + " ");
// Go to next node
currNode = currNode.next;
}
}
// Driver code
public static void main(String[] args)
{
/* Start with the empty list. */
LinkedList list = new LinkedList();
//
// ******INSERTION******
//
// Insert the values
list = insert(list, 1);
list = insert(list, 2);
list = insert(list, 3);
list = insert(list, 4);
list = insert(list, 5);
list = insert(list, 6);
list = insert(list, 7);
list = insert(list, 8);
// Print the LinkedList
printList(list);
}
} 常见面试问题:
-
翻转列表
-
在链表中找到中间值
-
移除列表中的环
堆栈
堆栈是按照LIFO(后进先出)顺序的线性数据结构。这是什么意思?想象一堆盘子。您放在堆栈顶部的最后一块盘子是您取出的第一块盘子。堆栈以这种方式工作:您添加的最后一个值是您删除的第一个值。
可将堆栈视为可以添加和删除的项目的集合,堆栈中常见的函数是push,pop,isEmpty和peek。
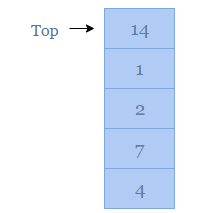
堆栈有许多应用:
-
回溯到以前的状态
-
表达评估和转换
堆栈的基本实现:
class Stack {
static final int MAX = 1000;
int top;
int a[] = new int[MAX]; // Maximum size of Stack
boolean isEmpty()
{
return (top < 0);
}
Stack()
{
top = -1;
}
boolean push(int x)
{
if (top >= (MAX - 1)) {
System.out.println("Stack Overflow");
return false;
}
else {
a[++top] = x;
System.out.println(x + " pushed into stack");
return true;
}
}
int pop()
{
if (top < 0) {
System.out.println("Stack Underflow");
return 0;
}
else {
int x = a[top--];
return x;
}
}
int peek()
{
if (top < 0) {
System.out.println("Stack Underflow");
return 0;
}
else {
int x = a[top];
return x;
}
}
}class Main {
public static void main(String args[])
{
Stack s = new Stack();
s.push(10);
s.push(20);
s.push(30);
System.out.println(s.pop() + " Popped from stack");
}
} 常见面试问题:
-
使用堆栈检查括号匹配
-
在一个数组中实现两个堆栈
-
下一个更大的元素使用堆栈
队列
队列与堆栈非常相似,因为它们都是具有动态大小的线性数据结构。但是,队列是FIFO(先进先出)数据结构。为了可视化此数据结构,假设您正在排队过山车。排队的第一批人可以离开排队。
在此数据结构中,元素从“后”进入而从“前”离开。队列中的标准功能是入队,出队,后排,前排和isFull。

队列有许多应用:
- 当资源由多个使用者共享时
- 创建目录
- 当数据在两个资源之间异步传输时
队列的基本实现:
class Queue
{
int front, rear, size;
int capacity;
int array[];
public Queue(int capacity) {
this.capacity = capacity;
front = this.size = 0;
rear = capacity - 1;
array = new int[this.capacity];
}
// Queue is full when size becomes equal to
// the capacity
boolean isFull(Queue queue)
{ return (queue.size == queue.capacity);
}
// Queue is empty when size is 0
boolean isEmpty(Queue queue)
{ return (queue.size == 0); }
// Method to add an item to the queue.
// It changes rear and size
void enqueue( int item)
{
if (isFull(this))
return;
this.rear = (this.rear + 1)%this.capacity;
this.array[this.rear] = item;
this.size = this.size + 1;
System.out.println(item+ " enqueued to queue");
}
// Method to remove an item from queue.
// It changes front and size
int dequeue()
{
if (isEmpty(this))
return Integer.MIN_VALUE;
int item = this.array[this.front];
this.front = (this.front + 1)%this.capacity;
this.size = this.size - 1;
return item;
}
// Method to get front of queue
int front()
{
if (isEmpty(this))
return Integer.MIN_VALUE;
return this.array[this.front];
}
// Method to get rear of queue
int rear()
{
if (isEmpty(this))
return Integer.MIN_VALUE;
return this.array[this.rear];
}
} 常见面试问题:
-
反转队列的前k个元素
-
使用队列生成从1到n的二进制数
图
图是由边连接的节点,构成的一个网。

在上面的示例中,一组顶点为(12、2、4、18、23),边为(12-2、12-4、2-4、4-18、4-23、18-23, 2-18)。
图是非常通用的数据结构,可以解决大量现实问题。图通常用于LinkedIn或Facebook等社交网络。随着GraphQL的兴起,数据被组织为图形或网络。
图的基本实现:
import java.util.*;
class Graph {
// A utility function to add an edge in an
// undirected graph
static void addEdge(ArrayList<ArrayList<Integer> > adj,
int u, int v)
{
adj.get(u).add(v);
adj.get(v).add(u);
}
// A utility function to print the adjacency list
// representation of graph
static void printGraph(ArrayList<ArrayList<Integer> > adj)
{
for (int i = 0; i < adj.size(); i++) {
System.out.println("\nAdjacency list of vertex" + i);
for (int j = 0; j < adj.get(i).size(); j++) {
System.out.print(" -> "+adj.get(i).get(j));
}
System.out.println();
}
}
// Driver Code
public static void main(String[] args)
{
// Creating a graph with 5 vertices
int V = 5;
ArrayList<ArrayList<Integer> > adj
= new ArrayList<ArrayList<Integer> >(V);
for (int i = 0; i < V; i++)
adj.add(new ArrayList<Integer>());
// Adding edges one by one
addEdge(adj, 0, 1);
addEdge(adj, 0, 4);
addEdge(adj, 1, 2);
addEdge(adj, 1, 3);
addEdge(adj, 1, 4);
addEdge(adj, 2, 3);
addEdge(adj, 3, 4);
printGraph(adj);
}
} 常见面试问题:
-
查找两个顶点之间的最短路径
-
检查两个顶点之间是否存在路径
-
在图中找到“母顶点”
哈希表
什么是哈希? 在深入研究哈希表之前,必须了解什么是哈希。
哈希是将对象分配到唯一索引(称为键)的过程。每个对象都使用键-值对标识,对象的集合称为字典。
哈希表是通过在数组中存储元素并通过键标识它们来实现的。哈希函数接受一个键并返回存储该值的索引。
因此,无论何时将键输入到哈希函数中,它都将始终返回相同的索引,该索引将标识关联的元素。此外,如果哈希函数曾经收到返回已使用索引的唯一键,则可以创建带有链表的元素链。

哈希表具有许多有用的应用:
-
当资源由多个使用者共享时
-
密码验证
-
链接文件名和路径
常见面试问题:
-
在数组中查找对称对
-
使用哈希的列表的并集和交集
二叉搜索树(Binary search tree)
一个二叉搜索树是一个节点由一个二叉树的数据结构。节点具有以下属性:
-
左子节点始终包含小于父节点的值。
-
右子节点始终包含大于父节点的值。
-
两个子节点也将是二进制搜索树。
二叉搜索树用于许多搜索应用程序中,还用于确定需要在3D有戏中渲染的对象。这种数据结构在工程项目中被广泛使用,因为分层数据是如此普遍。
tree新手?查阅我们的文章Data Structures 101:使用Java深入研究树。

常用操作:
-
遍历每个元素
-
在树中插入元素
-
先序遍历(根左右)(4,2,1,3,5,6)
-
中序遍历(左根右)(2,1,3,4,5,6)
-
后序遍历(左右根)(1,3,2,6,5,4)
常见面试问题:
-
在二分搜索树中找到第k个最大值
-
在二叉搜索树中找到最小值
-
使用广度优先搜索遍历给定目录
重要算法的学习
递归
递归是一种函数直接或间接调用自身的做法。相应的函数称为递归函数。尽管递归通常与算法相关联,但将递归作为解决问题的一种方法或方法可能会有所帮助。
因此,为什么递归有用呢?或者递归到底是什么?我们来看一下如何用递归计算阶乘。
public static long factorial(int number){
//base case - factorial of 0 or 1 is 1
if(number <=1){
return 1;
}
return number*factorial(number - 1);
}在上述的示例中,函数开始于数字n,当函数调用的时候,它将调用factorial(n−1)。假定n为4的时候;该函数将返回
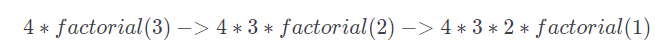
当n=1时,函数将返回![]() 我们得到
我们得到![]() =4*3*2*1,结果为24.
=4*3*2*1,结果为24.
在这里,您可以看到递归的力量。通过将复杂问题分解为较小的问题实例直到我们能够解决它,这是一种广泛使用的实践。使用递归,可以简化很多复杂问题。
冒泡排序
冒泡排序是一种简单的排序算法,如果相邻元素的顺序不正确,则会交换它们。该算法将多次迭代数组,直到元素处于正确的顺序。
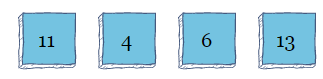
假定有一下一个数组:
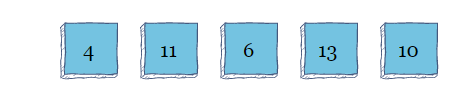
当算法从左到右扫描数组进行第一次迭代时,从索引0开始,它会比较索引i和i+1,在索引1的位置,它将看到11比6大,交换这两个值。
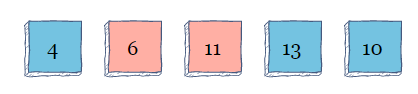
随着算法继续扫描迭代,它将看到13大于10并将两者交换

接下来,它将遍历数组进行第二次迭代。当看到11大于10时,它将交换索引2和3中的值
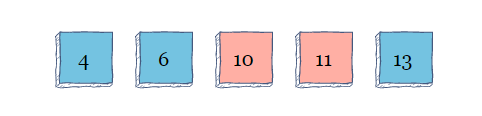
该算法将扫描阵列以进行第三次迭代,并且由于它不需要为第三次迭代进行任何更多交换,因此该算法将结束。
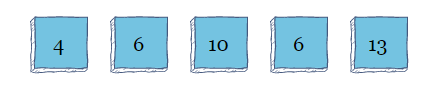
如您所见,气泡排序在处理更多元素时可能会表现不佳,使其主要用作简单的教育工具。其算法复杂度为![]()
实现冒泡排序
public static void bubble_srt(int array[]) {
int n = array.length;
int k;
for (int m = n; m >= 0; m--) {
for (int i = 0; i < n - 1; i++) {
k = i + 1;
if (array[i] > array[k]) {
swapNumbers(i, k, array);
}
}
printNumbers(array);
}
}选择排序
选择排序是一种将元素集合拆分为已排序和未排序的算法。在每次迭代期间,该算法会找到未排序组中的最小元素,并将其移至已排序组的末尾。
让我们看一个例子:
首先,所有元素都是未排序的。对于第一次迭代,该算法将遍历每个元素,并将4标识为最小值。该算法将交换11(未排序组中的第一个元素)与未排序组中最低的元素4

现在,已排序的组是索引0,未排序的组是索引1到索引3。对于第二次迭代,算法将从索引1开始并扫描数组,将6标识为未排序组中的最小值。它将交换11和6。
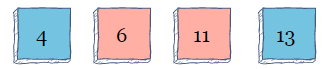
现在,已排序的组从索引0到索引1,而未排序的组从索引2到索引3。对于第三次迭代,算法将从索引2开始,并找到11作为最低值。因为11已经在正确的索引中,所以它不会移动。至此,算法结束。
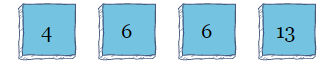
与冒泡排序类似,选择排序通常是一种低效的算法。它的运行时复杂度为![]()
实现选择排序:
public static int[] doSelectionSort(int[] arr){
for (int i = 0; i < arr.length - 1; i++)
{
int index = i;
for (int j = i + 1; j < arr.length; j++)
if (arr[j] < arr[index])
index = j;
int smallerNumber = arr[index];
arr[index] = arr[i];
arr[i] = smallerNumber;
}
return arr;
}
}插入排序
插入排序是一种简单的排序算法,它通过一次对一个元素进行排序来构建最终数组。它是如何工作的?
-
检查每个元素并将其与左侧的已排序元素进行比较
-
以正确的顺序插入已排序元素的项目
让我们来看一个例子。
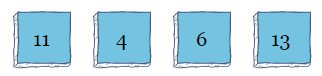
该算法从索引0开始,其值为11。由于11的左边没有元素,因此它保持在原位置。现在,在索引1上。它左边的值为11,这意味着我们将11和4交换。
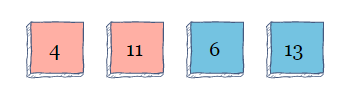
同样,该算法在4的左侧查找。因为在4的左侧没有元素,所以它保持在原位置。接下来,进入索引2。值为6的元素向左看。因为小于11,所以要进行两次切换。
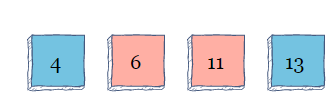
元素6再次向左看,但是因为4小于6,所以它保持在原位置。接下来,我们转到索引4处的元素。该算法向左看,但是因为11小于13,所以它保持在原位置。现在,算法完成了
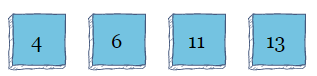
插入排序几乎总是比冒泡排序和选择排序更有效,因此在处理少量元素时使用频率更高。与其他两种排序算法相似,插入排序也具有![]() 。
。
实现插入排序:
public static int[] doInsertionSort(int[] input){
int temp;
for (int i = 1; i < input.length; i++) {
for(int j = i ; j > 0 ; j--){
if(input[j] < input[j-1]){
temp = input[j];
input[j] = input[j-1];
input[j-1] = temp;
}
}
}
return input;
}二分查找
二分查找是查找元素的最有效的搜索算法。该算法通过将数组或列表的中间元素与目标元素进行比较来工作。如果值相同,则将返回元素的索引。如果没有,列表将减少一半。
如果目标值小于中间值,则新列表将是左半部分。如果目标值大于中间值,则新列表将是右半部分。
此过程继续进行,您将继续拆分列表并搜索其中的一半,直到搜索算法找到目标值并返回位置
该算法的运行时间复杂度为![]() 需要注意的是,二分查找仅在列表已排序时才有效。
需要注意的是,二分查找仅在列表已排序时才有效。
为了可视化二分查找,假设您有一个包含十个元素的排序数组,并且您正在寻找的索引为33。
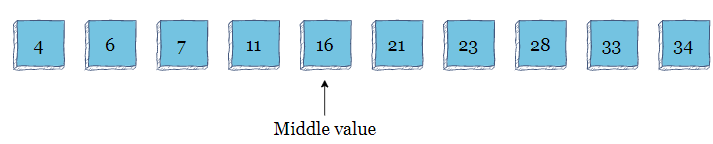
此数组的中间值为16,算法将其与33进行比较。33大于16,因此算法将数组拆分并在后半部分搜索
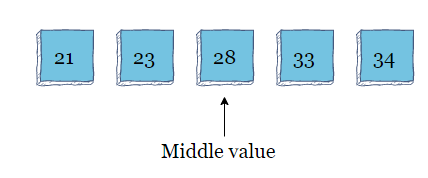
新的中间值为28。因为33大于28,所以算法在数组的后半部分搜索。
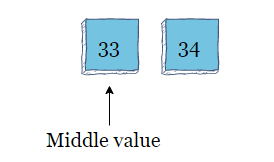
将数组再次拆分为右半部分后,新的中间值为33。该算法将看到中间值和目标值相同,并返回元素的位置
实现二分查找:
int binarySearch(int arr[], int l, int r, int x)
{
if (r >= l) {
int mid = l + (r - l) / 2;
// If the element is present at the
// middle itself
if (arr[mid] == x)
return mid;
// If element is smaller than mid, then
// it can only be present in left subarray
if (arr[mid] > x)
return binarySearch(arr, l, mid - 1, x);
// Else the element can only be present
// in right subarray
return binarySearch(arr, mid + 1, r, x);
}
// We reach here when element is not present
// in array
return -1;
} 接下来要学什么
请记住,我们今天介绍的概念仅仅是一个介绍。重要的是,您必须深入了解概念并练习编码问题。以下是我们建议您熟悉的其他主题:
-
堆排序
-
快速分类
-
合并排序
-
动态编程
-
AVL树
-
双链表
-
Dijkstra的算法
-
尝试















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









