






Abstract
Overfeat 把图像分类、定位、检测三个任务整合到一个框架中。Overfeat 在ILSVRC2013 的定位比赛中获得第一名。Overfeat是一个特征提取器。
Finally, we release a feature extractor from our best model called OverFeat.
1. 介绍
ConvNets:
- 端到端学习:输入像素输出类别,不需要手动做特征提取。
- 依赖大量的样本(labeled training samples)。
文章主要讲了:
- 训练一个卷积网络同时做分类、定位和检测能够提高三个任务的精度。
- 全卷积神经网络, offset max-pooling
- 介绍一个方法:通过累积预测窗口去定位和检测。
对象的尺寸和在图片中的位置不一样,如何解决?
- 多位置多尺寸:一个窗口可能包含对象的一部分,这可以分类,但无法定位和检测。计算量极大。
- 每个窗口不仅产生一个类别的分布,同时进行定位(位置和bounding box的大小)。
- 累积所有窗口所有位置的每一个类别的结果。
2. 视觉任务(ILSVRC2013)
- 分类:每个图片的真实标记是图片包含的主要对象的标记。预测五个类别(因为图片可能包含多个未标记的对象)。
- 定位:预测五个类别,和对应的五个定位。
- 检测:可以预测多个对象,也可以为0个。false positives(图片没有的对象,预测成包含该类对象)会被惩罚。
3. 分类
3.1 模型和训练
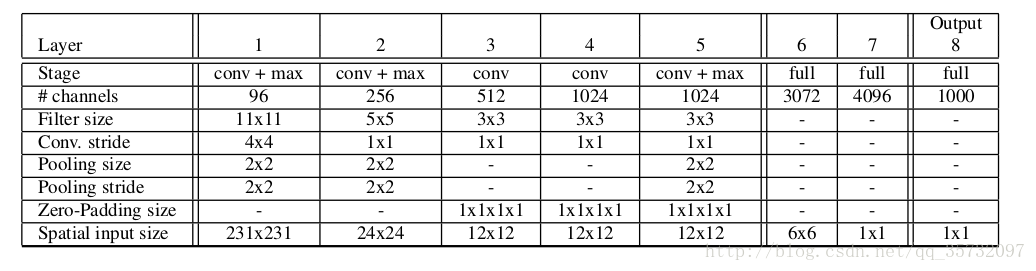
使用AlexNet,下图为 fast model。
- 不使用局部响应归一化
- non-overlapping pooling
- 步长为2,而不是4,特征图变大
训练:和AlexNet的方法一样,每张图片缩放到小边长256,随机提取5张 221*221 图(以及水平对称的图片)。
- mini-batch = 128, 权重初始化服从高斯分布(0, 0.01), momentum = 0.6,
weight-decay= 10−5 , learning-rate=0.05, (30,50,60,70,80)代减少一半,
dropout-ratio=0.5
3.2 特征提取器
上图为 fast model,下图是 accurate model。分类误差为14.18%,16.39%。后者的连接数几乎是前者的两倍。
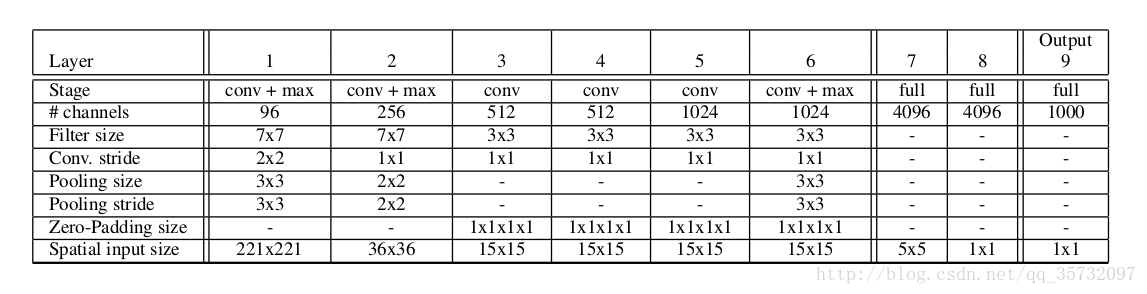
(下面没有按照文章顺序写)
3.3 全卷积神经网络FCN
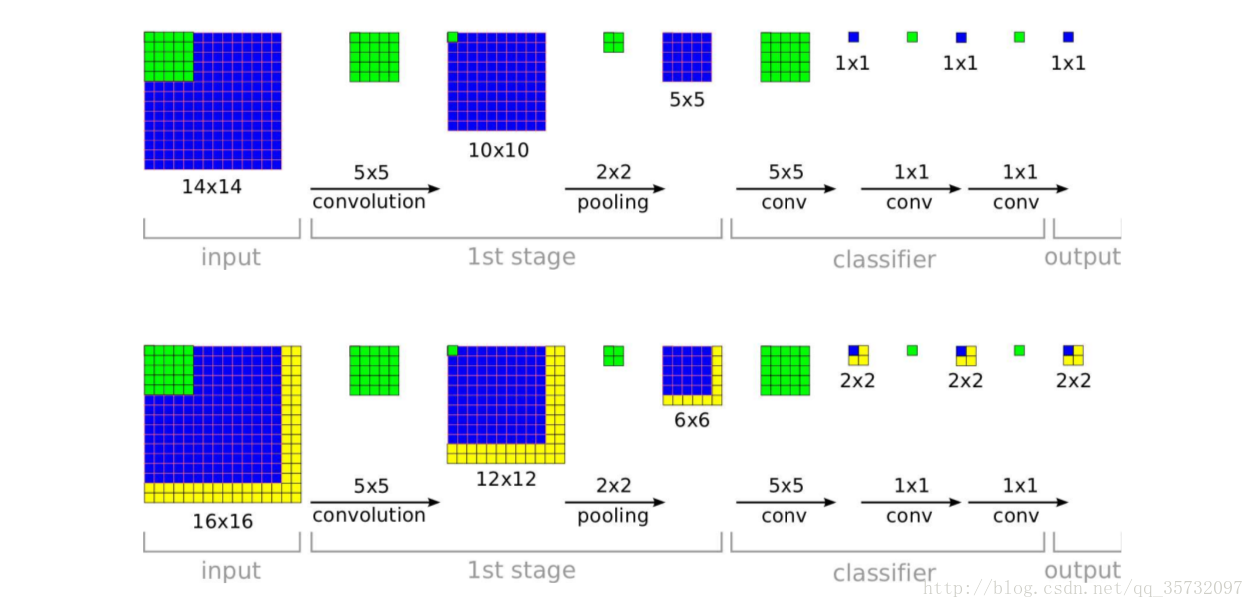
- 训练阶段:输入14×14,经过5×5卷积(stride=1),2×2池化(stride=2),特征图为5×5。
- 传统做法:5×5特征图展开成列向量,和FC1的神经元连接。
- FCN做法:把特征图到第一个全连接层,看成5×5的 filter,输出特征图为1×1。把FC1、FC2的每个神经元看做1×1 filter。
- 测试阶段:输入16×16,经过卷积、池化,特征图为6×6。
- 传统做法:展开成列向量之后,无法连接全连接层。
- FCN:继续卷积运算,最终输出 2×2 score map。
- FCN 的分辨率:accurate model中,下采样率为 2×3×2×3 = 36。下采样率和网络中的卷积、池化的stride的值有关。文章中说输入图片的每36个像素最终可以产生一个1000维的分类向量(应该是在训练图片 221×221 的基础上,某个维度每增加36个像素,最终输出的分类向量中,相应维度多一个值)。
- 全卷积神经网络可输入任意大小的图片,计算量基本不变(图中黄色部分为增加的计算量),更健壮。
- 实际上,全卷积神经网络产生的输出是比较粗略的分布,性能不比10-view 的方法好。原因在于网络的窗口没有和对象对齐。为了避免这个问题,在某个池化层执行offset max-pooling,每种结果分别送入之后的网络,最终得到多种类别分布。offset max-pooling提高了解析度,accurate model中解析度从 36 降到 12。
3.4 offset max-pooling
(文章中offset 的池化大小是 3×3,应该是在 accurate model中,文中的layer 5应该是指 layer 6 ?)
offset max-pooling过程:
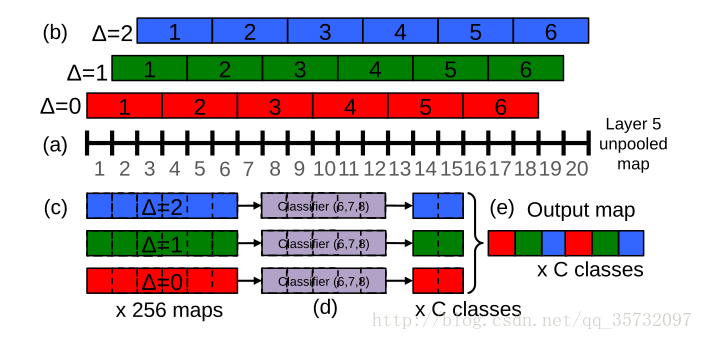
- 对于某个尺寸的图片,输入网络,到达最后一个池化层之前,此时特征图为 20×20。
- 执行 3×3 池化,传统做法将抛弃特征图的第19、20像素点;在offset中,将分别从起始位置 Δ=0、Δ=1、Δ=2 进行池化,得到 3×3 张特征图。
- 分别把 3×3张图送入之后的网络,最终得到九个结果。
3.5 测试
- 在AlexNet中,是从测试图片中提取10张图送入网络,平均10个结果。
- 下图是accurate model测试的过程。OverFeat使用了6种不同的尺度,缩放之后直接送入网络,平均6种尺度的图片和其水平翻转的所有结果 作为最终结果。
- 在最后一个池化层(3*3)使用offset max-pooling,第一个全连接层看成5×5卷积,FC2、FC3看成1×1卷积。
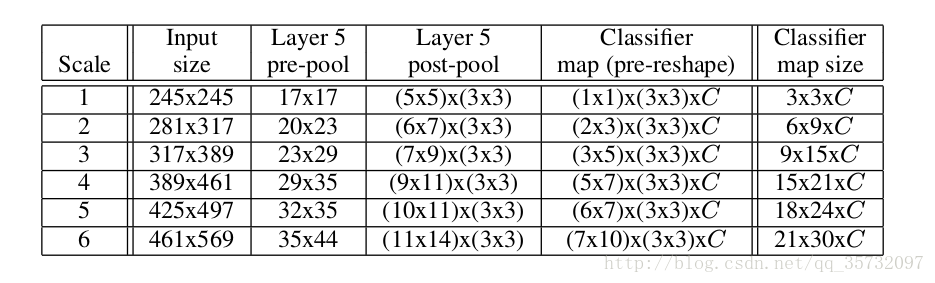
- 以317*389为例:
- 最后一个池化层的输入为 23*29,池化大小为3*3,步长为3,offset max-pooling之后得到 3*3 张(两个维度上共有9 个offset位置) 7*9 的特征图。
- 对于每个offset,第一个全连接层为5*5 卷积核,输出特征图 3*5,第二、三层都是 1*1卷积核,最终输出 3*5 特征图,最后一层有 1000个 filter(1000 个类别),实际上是 3*5*1000 的分值分布,每个类别上有 3*5 个分值。
- 最终共有 (3*5*1000)×(3*3)个结果。
3.6 结果
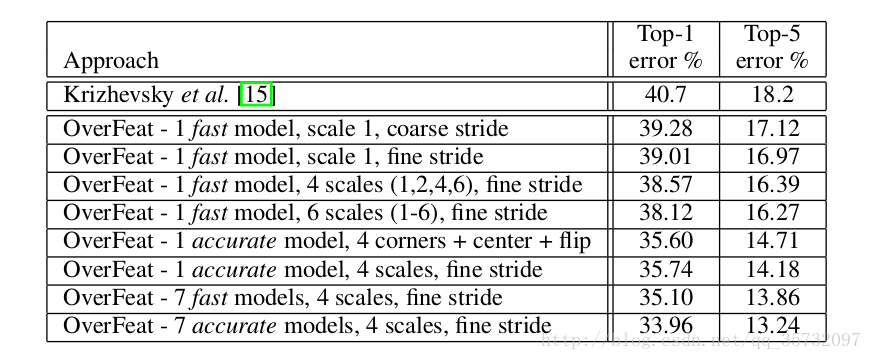
fine stride:Δ=0,1,2;coarse stride:Δ=0
可以看到,offset max-pooling、使用更多的scale都能够提高网络性能;offset max-pooling提高得较少。
4. 定位
主要是把分类网络换成回归网络,然后在各个scale 下训练回归网络来预测bounding box;然后融合预测的各个bounding box。
- 回归网络:4096-1024-4 个神经元,最后一层是 class-specific 的,即:对于每个 class,都需要训练 单独的最后一层;测试时,有1000个类别则输出1000个bbox。
- 损失函数:欧氏距离
- 对于定位问题,测试时,在每一个尺度上同时运行classification network和regressor network。这样,对于每一个尺度来说,classification network给出了图像块的类别的概率分布,regressor network进一步为每一类给出了一个bounding box,这样,对于每一个bounding box,就有一个置信度与之对应。最后,综合这些信息,给出定位结果。
- 结合预测:
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。














 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









