








目录
一、Kettle整合Hadoop
环境 kettle 8.2 版本:
kettle国内镜像下载地址:http://mirror.bit.edu.cn/pentaho/Pentaho%208.2/client-tools/
1、 整合步骤
1. 确保Hadoop的环境变量设置好HADOOP_USER_NAME为root
2. 从hadoop下载核心配置文件
/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml
/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml3. 把hadoop核心配置文件放入kettle目录
data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp264. 修改 data-integration\plugins\pentaho-big-data-plugin\plugin.properties文件
- 修改plugin.properties
active.hadoop.configuration=hdp265. 创建Hadoop clusters
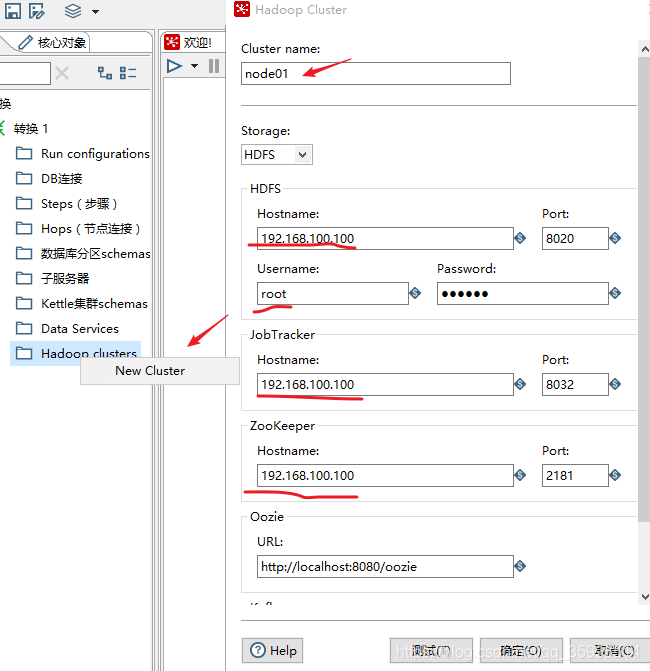
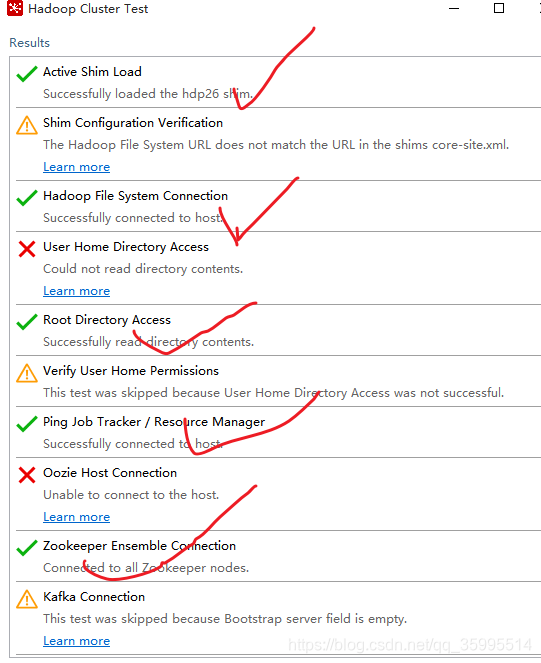
打红色的对勾的缺一不可,node01 失效要 配置 windows 的 hosts 映射

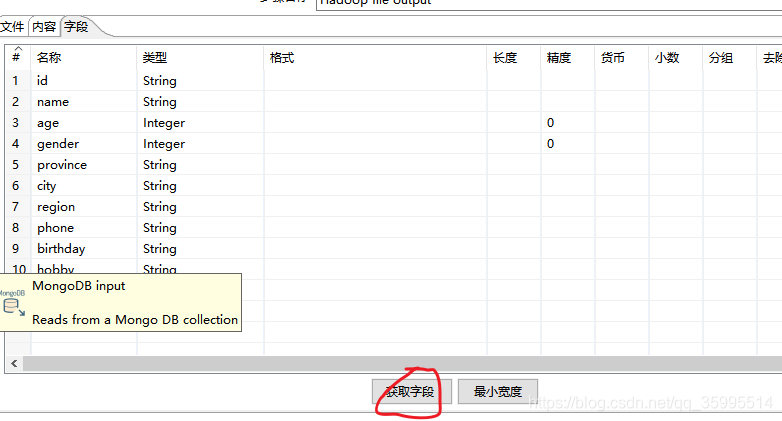
2、Hadoop file input组件
需求:从Hadoop文件系统读取/hadoop/test/1.txt文件,把数据输入到Excel中
1. 配置Hadoop File Input组件
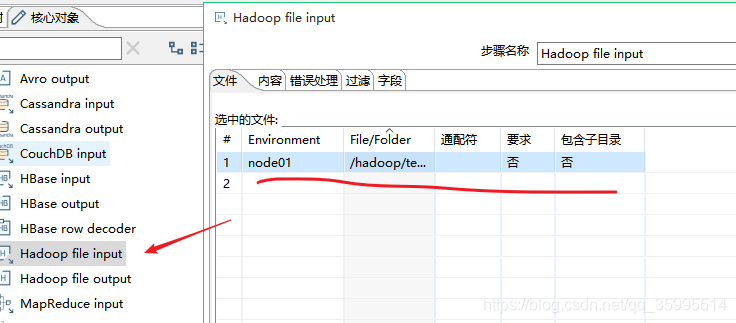
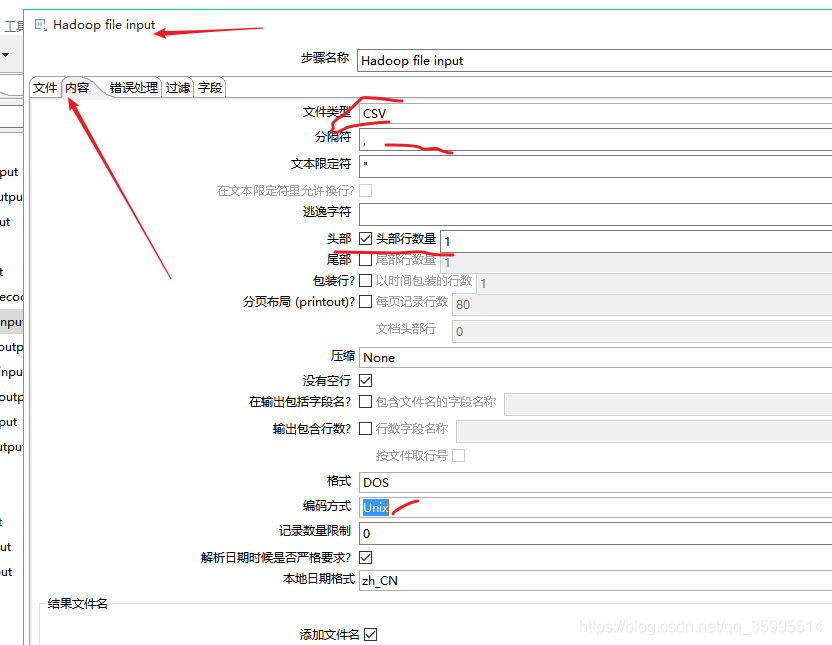

2. Excel 配置输出路径 即可
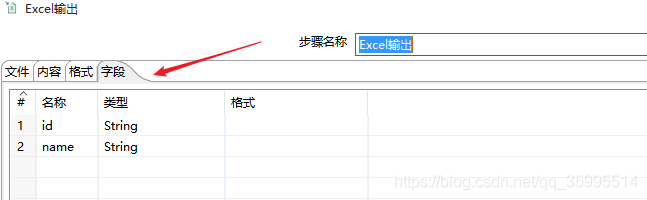
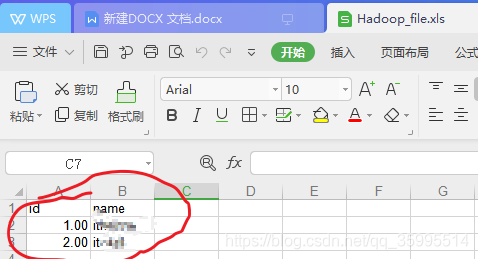
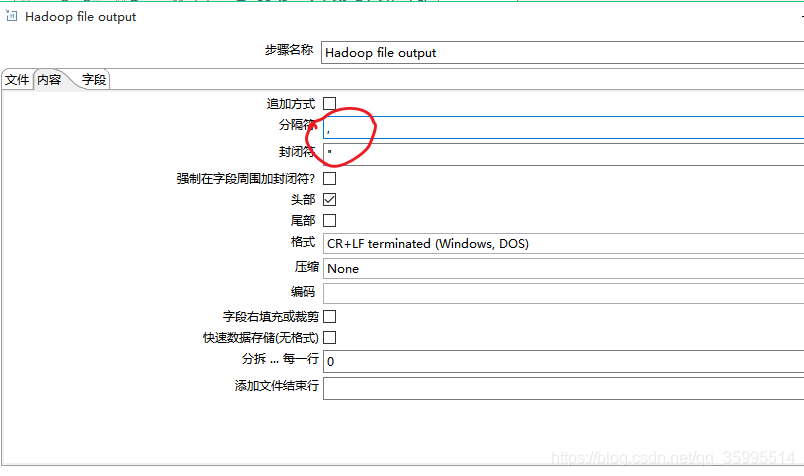
3、Hadoop file output组件
需求:读取 user.json 把数据写入到hdfs文件系统的的/hadoop/test/2.txt中。
1. 配置 JSON 输入组件
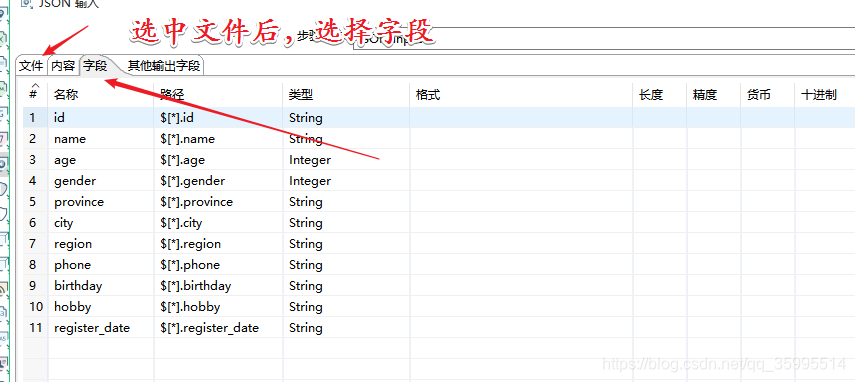
2. 配置Hadoop file output组件

二、Kettle整合Hive
1、初始化数据
1. 连接hive
2. 创建并切换数据库
show databases; -- 查询数据库
drop database test cascade; -- 强制删除数据库
create database test; -- 创建数据库
use test; -- 切换数据库3. 创建表
CREATE TABLE a (
a int,
b int
)
ROW format delimited
fields terminated BY ','
stored AS TEXTFILE;4. 创建数据文件
vim a.txt
1,11
2,22
3,335. 从文件中加载数据到表
load data local inpath '/export/datas/a.txt' overwrite into table a;2、 kettle与Hive 整合配置
1. 从虚拟机下载Hadoop的jar包
/export/servers/hadoop-2.7.5/share/hadoop/common/2. 把jar包放置在\data-integration\lib目录下
3. 重启kettle,重新加载生效
3、从hive 中读取数据
- hive数据库是通过jdbc来进行连接,可以通过
表输入控件来获取数据。
需求:从hive数据库的test库的a表中获取数据,并把数据保存到Excel中。
实现步骤:
1. 设计一下kettle组件结构
2. 配置表输入组件
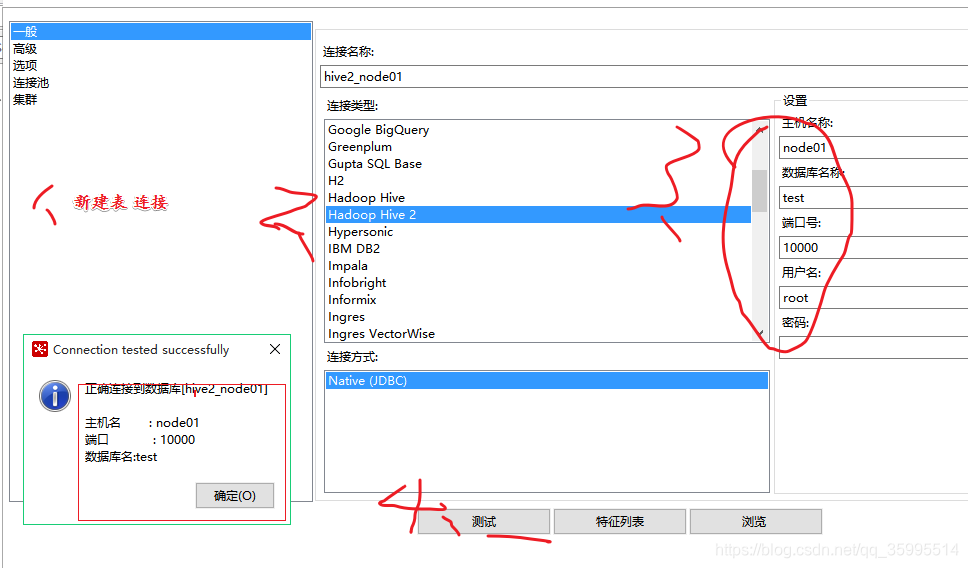
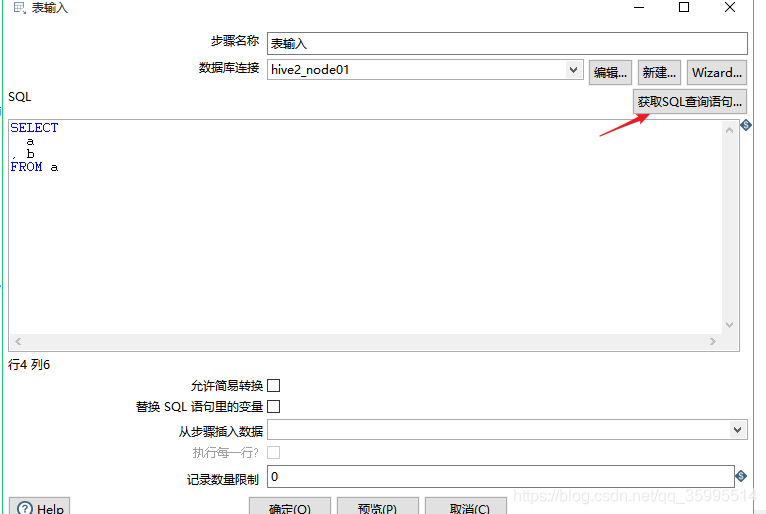
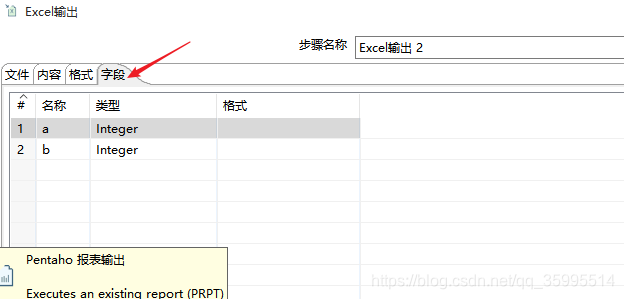
3. 配置表输出
4、把数据保存到hive数据库
hive数据库是通过jdbc来进行连接,可以通过
表输出控件来保存数据。
需求:从Excel中读取数据,把数据保存在hive数据库的test数据库的 a 表。
实现步骤:
1. 配置 Excel输入组件
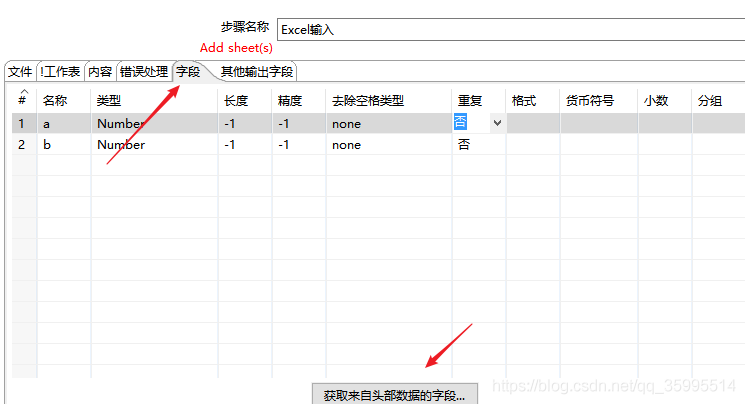
2. 配置表输出组件
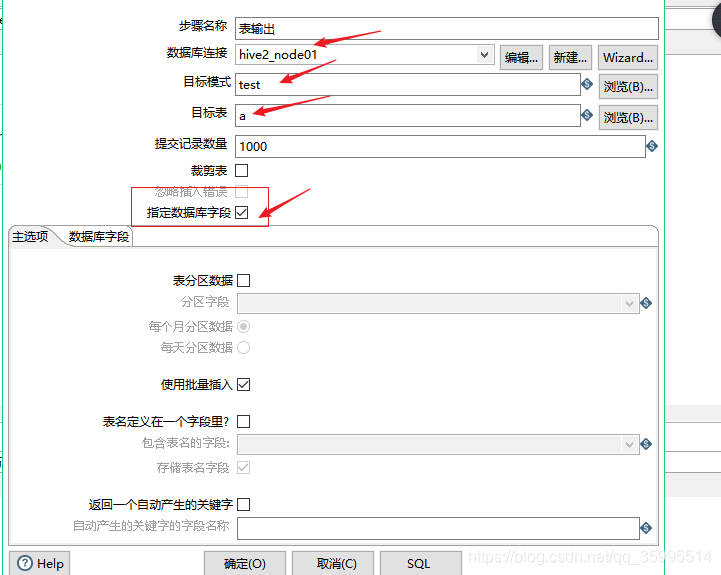
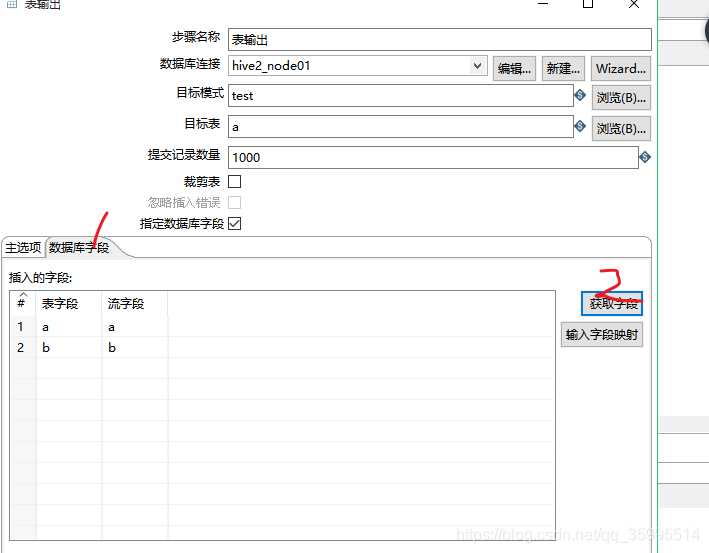
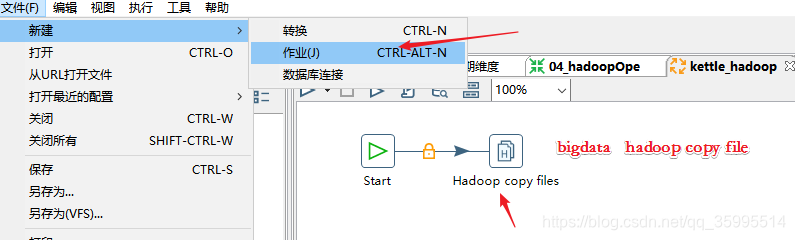
5、Hadoop Copy Files组件
Kettle作业中的Hadoop Copy Files作业项可以将本地的文件上传到HDFS,也可以向Hive导入数据。
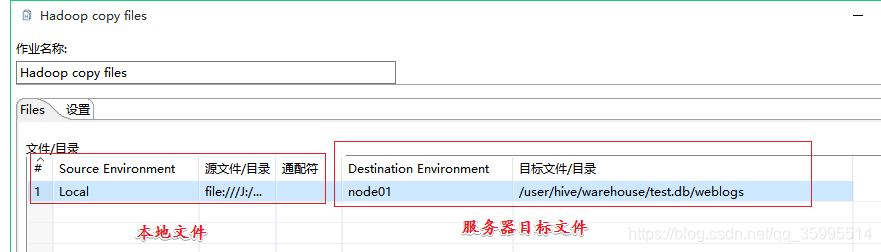
需求: 把资料\kettle测试数据\weblogs_parse.txt文件导入到Hive表中
资源下载地址:Pentaho Community Wiki
实现步骤:
1. 创建表
---创建weblogs表语句
create table test.weblogs (
client_ip string,
full_request_date string,
day string,
month string,
month_num int,
year string,
hour string,
minute string,
second string,
timezone string,
http_verb string,
uri string,
http_status_code string,
bytes_returned string,
referrer string,
user_agent string
)
row format delimited
fields terminated by '\t';2. 配置Hadoop copy files
3. 测试数据是否已经抽取到Hive中
数据比较多 , 笔记本 内存有很小 ,跑起来 太费劲了

6、执行Hive的HiveSQL语句
Kettle中可以执行 Hive 的HiveSQL语句,使用作业的SQL脚本。
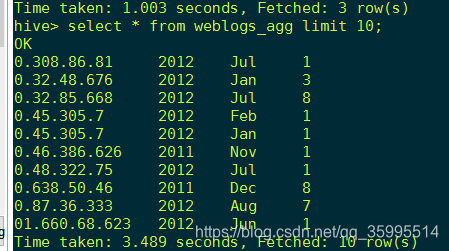
需求:聚合查询weblogs表(以IP和年月分组统计的PV数据),同时建立一个新表保存查询数据。
实现步骤:
1. 拖取组件,配置 SQL 组件
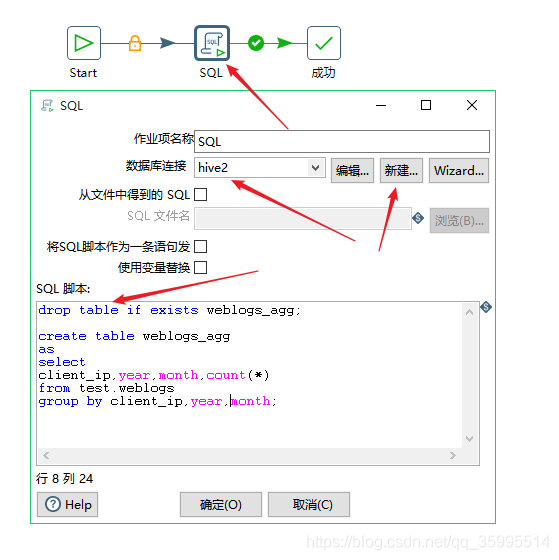
2. 测试数据是否生成
三、Kettle整合HBase
1、HBase初始化
从hbase集群中复制 hbase-site.xml 文件到 kettle 安装目录下的 “plugins/pentaho-big-data-plugin/hadoop-configurations/hdp26” 目录下。
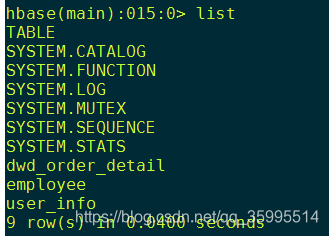
1. 进入HBase shell, 查看状态
2. 创建表,并查看
-- 创建表
create 't1','f1'
-- 查看表
describe 't1'
-- 添加数据
put 't1','rowkey001','f1:name','zhangsan'
-- 获取数据
get 't1','rowkey001'

2. HBase input组件
Kettle提供了HBase input控件来读取HBase数据库中的数据。
需求:读取HBase数据库中表里面的数据,把数据保存到Excel
实现步骤:
1. 准备一些测试数据
create 't_user','cf'
put 't_user','392456197008193000','cf:name','张三'
put 't_user','392456197008193000','cf:age','20'
put 't_user','392456197008193000','cf:gender','0'
put 't_user','392456197008193000','cf:province','北京市'
put 't_user','392456197008193000','cf:city','昌平区'
put 't_user','392456197008193000','cf:region','回龙观'
put 't_user','392456197008193000','cf:phone','18589407692'
put 't_user','392456197008193000','cf:birthday','1970-08-19'
put 't_user','392456197008193000','cf:hobby','美食;篮球;足球'
put 't_user','392456197008193000','cf:register_date','2018-08-06 09:44:43'
put 't_user','267456198006210000','cf:name','李四'
put 't_user','267456198006210000','cf:age','25'
put 't_user','267456198006210000','cf:gender','1'
put 't_user','267456198006210000','cf:province','河南省'
put 't_user','267456198006210000','cf:city','郑州市'
put 't_user','267456198006210000','cf:region','郑东新区'
put 't_user','267456198006210000','cf:phone','18681109672'
put 't_user','267456198006210000','cf:birthday','1980-06-21'
put 't_user','267456198006210000','cf:hobby','音乐;阅读;旅游'
put 't_user','267456198006210000','cf:register_date','2017-04-07 09:14:13'
put 't_user','892456199007203000','cf:name','王五'
put 't_user','892456199007203000','cf:age','24'
put 't_user','892456199007203000','cf:gender','1'
put 't_user','892456199007203000','cf:province','湖北省'
put 't_user','892456199007203000','cf:city','武汉市'
put 't_user','892456199007203000','cf:region','汉阳区'
put 't_user','892456199007203000','cf:phone','18798009102'
put 't_user','892456199007203000','cf:birthday','1990-07-20'
put 't_user','892456199007203000','cf:hobby','写代码;读代码;算法'
put 't_user','892456199007203000','cf:register_date','2016-06-08 07:34:23'
put 't_user','492456198712198000','cf:name','赵六'
put 't_user','492456198712198000','cf:age','26'
put 't_user','492456198712198000','cf:gender','2'
put 't_user','492456198712198000','cf:province','陕西省'
put 't_user','492456198712198000','cf:city','西安市'
put 't_user','492456198712198000','cf:region','莲湖区'
put 't_user','492456198712198000','cf:phone','18189189195'
put 't_user','492456198712198000','cf:birthday','1987-12-19'
put 't_user','492456198712198000','cf:hobby','购物;旅游'
put 't_user','492456198712198000','cf:register_date','2016-01-09 19:15:53'
2. 配置 HBase Input 组件
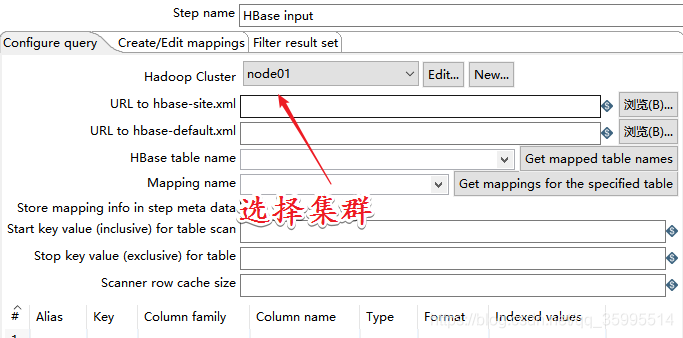
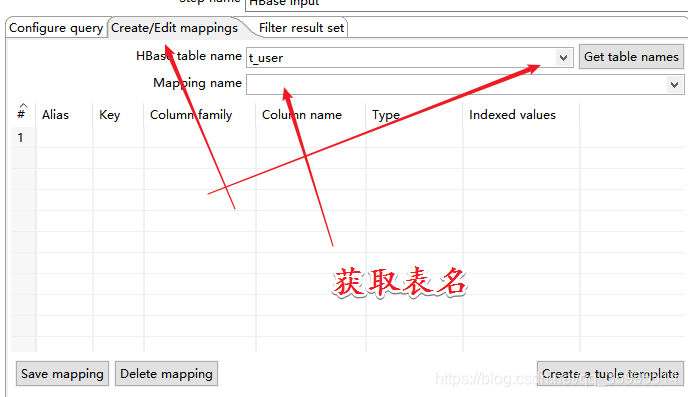
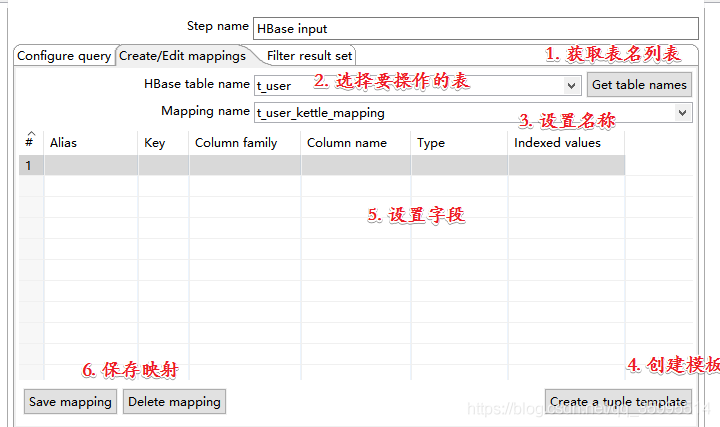
返回到 configure query , 下面 我们使用 "create a tuple template " 模板 导出到 Excel中的 数据并没有 展开,可能不是我们想要的结果, 我们自己 设计映射 字段关系。
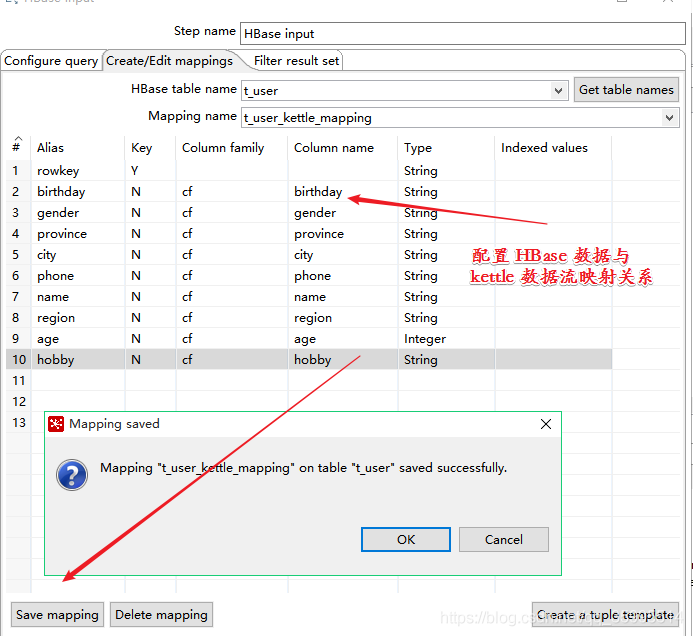
查看结果

我们使用 "create a tuple template " 模板 导出到 Excel中的 数据并没有 展开,不是我们想要的结果, 我们自己 设计映射 字段关系,因为 HBase 的设计 就是 rowkey 的 column Family 下有很多的 column 自动生成 的模板 是 不能将数据 展开的。
3、HBase output组件
Kettle提供了“HBase output”控件来保存数据到 HBase 数据库中。
需求:从 user.json 中读取数据,把数据保存在HBase的t_user_2表中实现步骤:
[
{
"id": "392456197008193000",
"name": "张三",
"age": 20,
"gender": 0,
"province": "北京市",
"city": "昌平区",
"region": "回龙观",
"phone": "18589407692",
"birthday": "1970-08-19",
"hobby": "美食;篮球;足球1",
"register_date": "2018-08-06 09:44:43"
},
{
"id": "267456198006210000",
"name": "李四",
"age": 25,
"gender": 1,
"province": "河南省",
"city": "郑州市",
"region": "郑东新区",
"phone": "18681109672",
"birthday": "1980-06-21",
"hobby": "音乐;阅读;旅游",
"register_date": "2017-04-07 09:14:13"
},
{
"id": "892456199007203000",
"name": "王五",
"age": 24,
"gender": 1,
"province": "湖北省",
"city": "武汉市",
"region": "汉阳区",
"phone": "18798009102",
"birthday": "1990-07-20",
"hobby": "写代码;读代码;算法",
"register_date": "2016-06-08 07:34:23"
},
{
"id": "492456198712198000",
"name": "赵六",
"age": 26,
"gender": 2,
"province": "陕西省",
"city": "西安市",
"region": "莲湖区",
"phone": "18189189195",
"birthday": "1987-12-19",
"hobby": "购物;旅游",
"register_date": "2016-01-09 19:15:53"
},
{
"id": "392456197008193000",
"name": "张三",
"age": 20,
"gender": 0,
"province": "北京市",
"city": "昌平区",
"region": "回龙观",
"phone": "18589407692",
"birthday": "1970-08-19",
"hobby": "美食;篮球;足球1",
"register_date": "2018-08-06 09:44:43"
},
{
"id": "392456197008193000",
"name": "张三",
"age": 20,
"gender": 0,
"province": "北京市",
"city": "昌平区",
"region": "回龙观",
"phone": "18589407692",
"birthday": "1970-08-19",
"hobby": "美食;篮球;足球1",
"register_date": "2018-08-06 09:44:43"
}
]实现步骤:
1. 配置HBase output组件

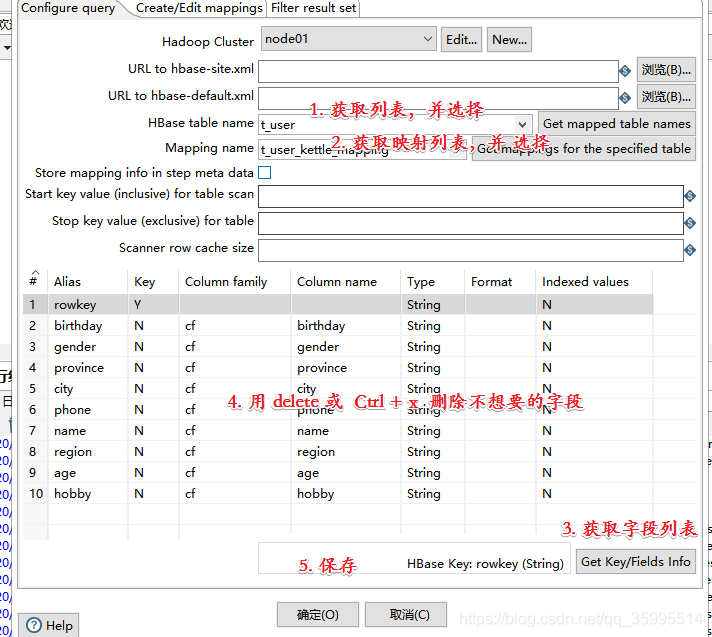
2. 配置kettle数据流与HBase映射关系
表不能存在 创建 即可 ,不用提前创建
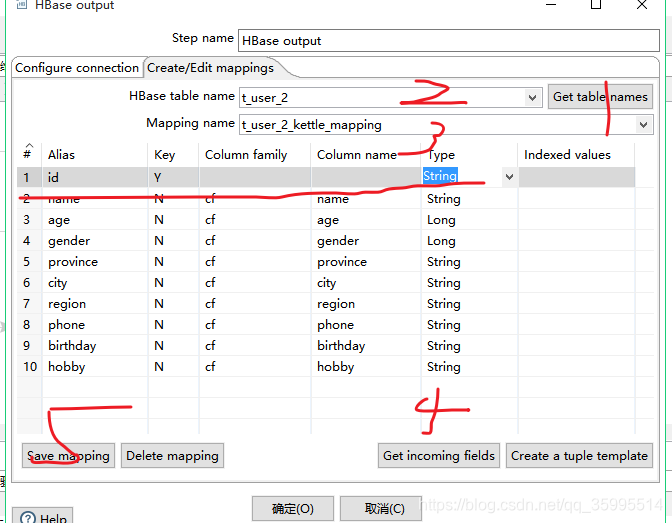
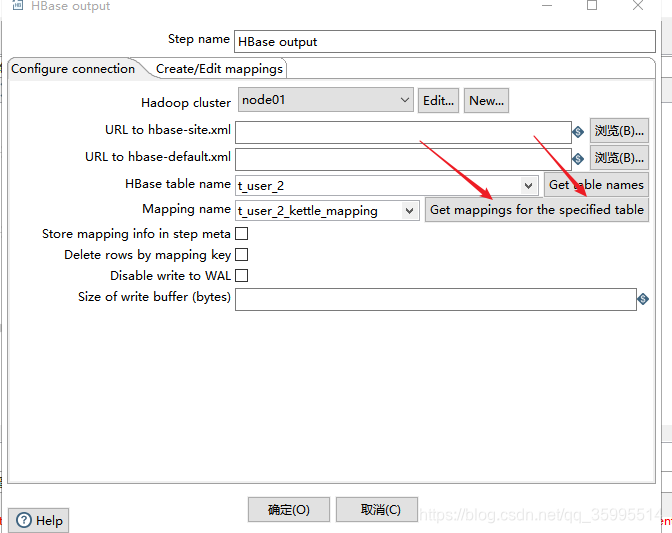
查看结果
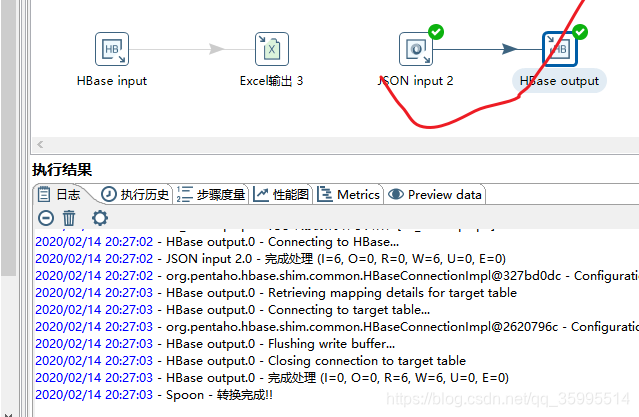
![]()
到目前 位置,我们就 将 kettle 与 Hadoop,Hive, HBase 整合完成,并且 演示了 基本的案例操作。
遇到的问题:
- IP 的在 Windows在映射 在 System32 中的 hosts 中添加
- zookeeper ,HBase 启动 正常 ,报错了 去看看是否挂掉,HMaster 时间久了不用, 好像就挂了
------------------------------------ 感谢 点赞!-----------------------------------------
------------------------------------ 感谢 点赞!-----------------------------------------
------------------------------------ 感谢 点赞!-----------------------------------------
















 2778
2778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











