







循环神经网络
1. 循环神经网络
在DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。
对于这类问题,RNN则比较的擅长。那么RNN是怎么做到的呢?
假设我们的样本是基于序列的,比如从序列索引 1 1 1到序列索引 τ τ τ的。对于这其中的任意序列索引号 t t t,它对应的输入是对应的样本序列中的 x ( t ) x^{(t)} x(t)。而模型在序列索引号 t t t位置的隐藏状态 h ( t ) h^{(t)} h(t),则由 x ( t ) x^{(t)} x(t)和在 t − 1 t−1 t−1位置的隐藏状态 h ( t − 1 ) h^{(t-1)} h(t−1)共同决定。在任意序列索引号 t t t,我们也有对应的模型预测输出 o ( t ) o^{(t)} o(t)。通过预测输出 o ( t ) o^{(t)} o(t)和训练序列真实输出 y ( t ) y^{(t)} y(t),以及损失函数 L ( t ) L^{(t)} L(t),我们就可以用DNN类似的方法来训练模型,接着用来预测测试序列中的一些位置的输出。
1.1 RNN的结构
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
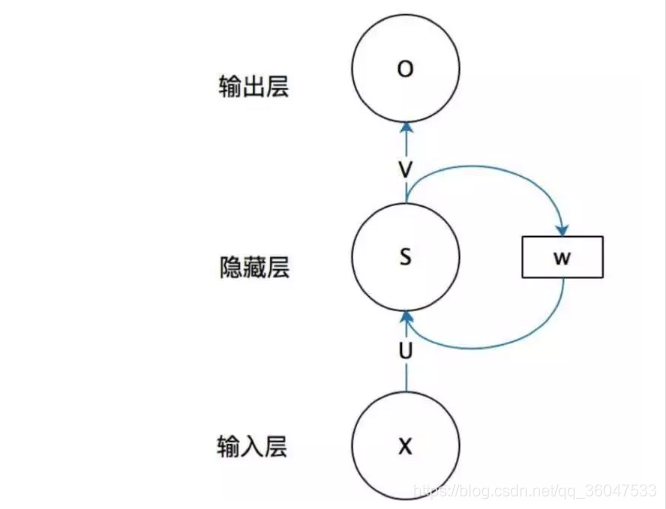
在上图中 x表示的是输入层的值;s表示的是隐藏层的值;U是输入层到隐藏层的权重矩阵;o表示输出层的值;V是隐藏层到输出层的权重矩阵。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
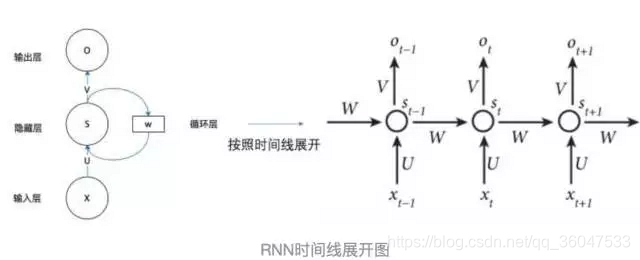
这个网络在
t
t
t时刻接收到输入
X
t
X_t
Xt 之后,隐藏层的值是
S
t
S_t
St ,输出值是
O
t
O_t
Ot 。关键一点是,
S
t
S_t
St 的值不仅仅取决于
X
t
X_t
Xt ,还取决于
S
t
−
1
S_{t-1}
St−1。我们可以用下面的公式来表示循环神经网络的计算方法:
O
t
=
g
(
V
∗
S
t
)
S
t
=
f
(
U
∗
X
t
+
W
∗
S
t
−
1
)
O_t=g(V*S_t)\\ S_t=f(U*X_t+W*S_{t-1})
Ot=g(V∗St)St=f(U∗Xt+W∗St−1)
S
t
S_t
St的值不仅仅取决于
X
t
X_t
Xt, 还取决于
S
t
−
1
S_{t-1}
St−1
但该网络的输出 O t O_t Ot 如何与真实值比较呢?下面来看一下更详细的图:
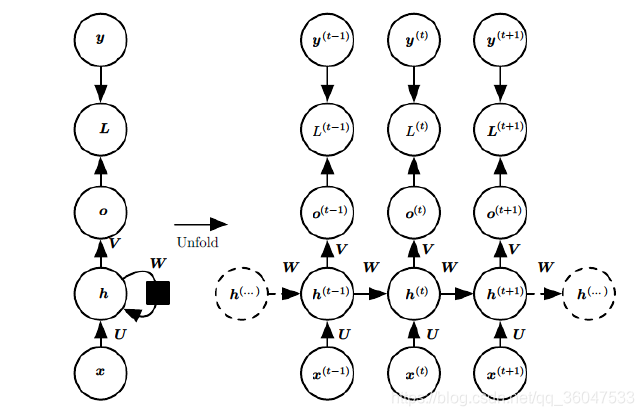
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
这幅图描述了在序列索引号
t
t
t 附近RNN的模型。其中:
1)
x
(
t
)
x^{(t)}
x(t)代表在序列索引号
t
t
t时训练样本的输入。同样的,
x
(
t
−
1
)
x^{(t−1)}
x(t−1) 和
x
(
t
+
1
)
x^{(t+1)}
x(t+1) 代表在序列索引号
t
−
1
t−1
t−1和
t
+
1
t+1
t+1时训练样本的输入。
2)
h
(
t
)
h^{(t)}
h(t)代表在序列索引号
t
t
t 时模型的隐藏状态。
h
(
t
)
h^{(t)}
h(t) 由
x
(
t
)
x^{(t)}
x(t)和
h
(
t
−
1
)
h^{(t-1)}
h(t−1)共同决定。
3)
o
(
t
)
o^{(t)}
o(t) 代表在序列索引号
t
t
t 时模型的输出。
o
(
t
)
o^{(t)}
o(t)只由模型当前的隐藏状态
h
(
t
)
h^{(t)}
h(t)决定。
4)
L
(
t
)
L^{(t)}
L(t) 代表在序列索引号
t
t
t时模型的损失函数。
5)
y
(
t
)
y^{(t)}
y(t)代表在序列索引号
t
t
t 时训练样本序列的真实输出。
6)U,W,VU,W,V 这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
1.2 RNN前向传播算法
有了上面的模型,RNN的前向传播算法就很容易得到了。
对于任意一个序列索引号t,我们隐藏状态
h
(
t
)
h^{(t)}
h(t) 由
x
(
t
)
x^{(t)}
x(t)和
h
(
t
−
1
)
h^{(t−1)}
h(t−1)得到:
h
(
t
)
=
σ
(
z
(
t
)
)
=
σ
(
U
x
(
t
)
+
W
h
(
t
−
1
)
+
b
)
h^{(t)}=σ(z^{(t)})=σ(Ux^{(t)}+Wh^{(t−1)}+b)
h(t)=σ(z(t))=σ(Ux(t)+Wh(t−1)+b)
其中σ 为RNN的激活函数,一般为tanh, b为线性关系的偏倚。序列索引号t时模型的输出
o
(
t
)
o^{(t)}
o(t)的表达式比较简单:
o
(
t
)
=
V
h
(
t
)
+
c
o^{(t)}=Vh^{(t)}+c
o(t)=Vh(t)+c
在最终在序列索引号t时我们的预测输出为:
y
(
t
)
=
σ
(
o
(
t
)
)
y^{(t)}=σ(o{(t)})
y(t)=σ(o(t))
通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
通过损失函数
L
(
t
)
L^{(t)}
L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即
y
^
(
t
)
\hat y^{(t)}
y^(t)和
y
(
t
)
y^{(t)}
y(t)的差距。
1.3 RNN反向传播算法
RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数U,W,V,b,c。由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。当然这里的BPTT和DNN也有很大的不同点,即这里所有的U,W,V,b,c在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
为了简化描述,这里的损失函数我们为对数损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失L为:
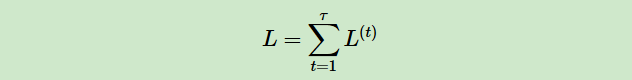
其中V,c 的梯度计算是比较简单的:
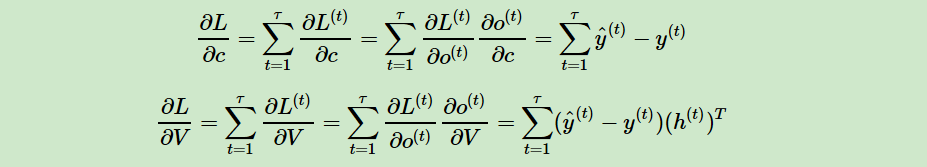
但是W,U,b的梯度计算就比较的复杂了。从RNN的模型可以看出,在反向传播时,在某一序列位置t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置t+1时的梯度损失两部分共同决定。对于W在某一序列位置t的梯度损失需要反向传播一步步的计算。我们定义序列索引t位置的隐藏状态的梯度为:
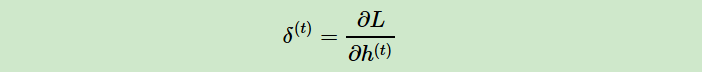

1.4 RNN存在的问题
RNN链式的特征揭示了 其本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
RNN面临的最大挑战就是无法解决长期依赖问题。例如对下面两句话:
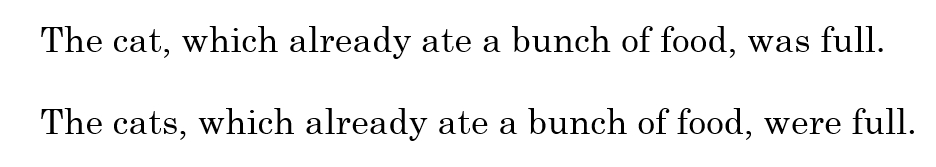
最后的was与were如何选择是和前面的单复数有关系的,但对于简单的RNN来说,两个词相隔比较远,如何判断是单数还是复数就很关键。
RNN受到短期记忆的影响。如果序列很长,他们将很难将信息从较早的时间步传送到后面的时间步。因此,如果你尝试处理一段文本进行预测,RNN可能会遗漏开头的重要信息。
在反向传播期间,RNN存在梯度消失的问题(梯度用于更新神经网络权重的值)。梯消失度问题是当梯度反向传播随着时间的推梯度逐渐收缩。如果梯度值变得非常小,则不会产生太多的学习。
因此,在递归神经网络中,获得小梯度更新的层会停止学习。那些通常是较早的层。因为这些层不再学习,RNN会忘记它在较长序列中看到的内容,因此只有短期记忆。
** 解决方法**
1)渗透单元及其它多时间尺度的策略
2)长短期记忆和其它门控RNN
3)优化长期依赖(截断梯度、引导信息流的正则化)
LSTM和GRU解决方案LSTM和GRU是作为短期记忆的解决方案而创建的。它们具有称为门(gate)的内部机制,它可以调节信息流。
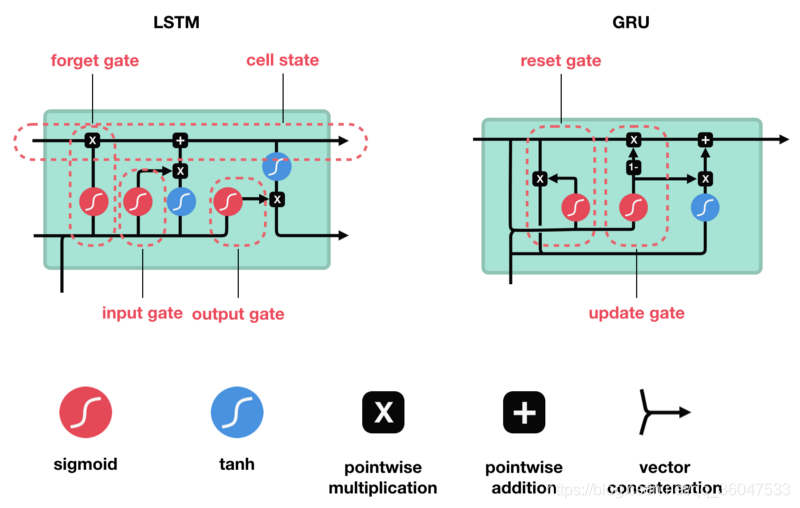
下面将会对长短期记忆网络(LSTM)以及门控循环单元(GRU)做介绍
参考文献:
http://ai.51cto.com/art/201711/559441.htm
https://www.cnblogs.com/pinard/p/6509630.html
https://blog.csdn.net/mpk_no1/article/details/72875185
https://blog.csdn.net/qq_28437273/article/details/79656605
https://www.atyun.com/30234.html
2. LSTM
LSTM(Long Short Term Memory) 是一种特殊的 RNN 类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
2.1 LSTM的结构
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。LSTM是一种拥有三个“门”结构的特殊网络结构,如下图:
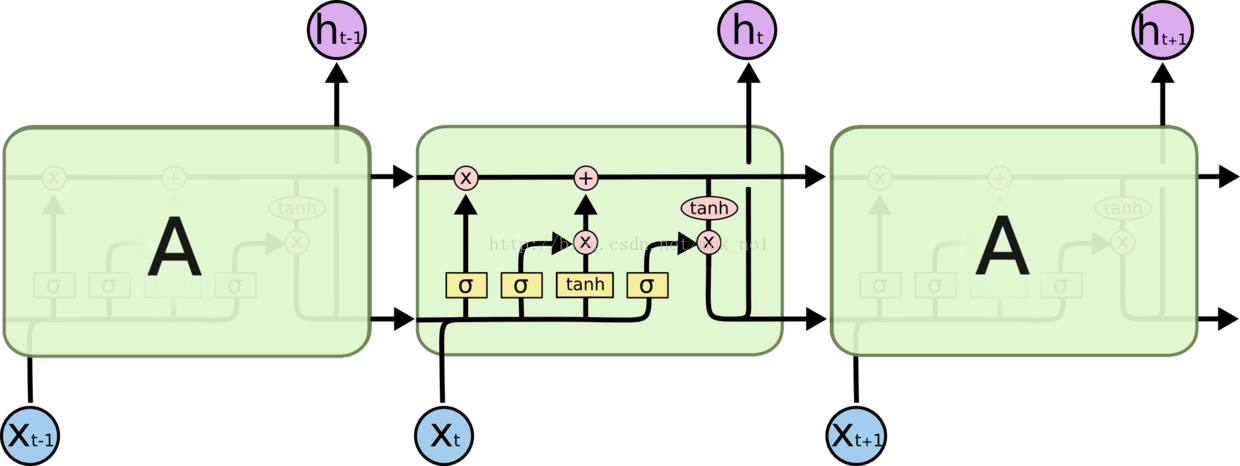
LSTM 靠一些“门”的结构让信息有选择性地影响RNN中每个时刻的状态。所谓“门”的结构就是一个使用sigmod神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”结构。之所以该结构叫做门是因为使用sigmod作为激活函数的全连接神经网络层会输出一个0到1之间的值,描述当前输入有多少信息量可以通过这个结构,于是这个结构的功能就类似于一扇门,当门打开时(sigmod输出为1时),全部信息都可以通过;当门关上时(sigmod输出为0),任何信息都无法通过。
2.2 LSTM模型结构剖析
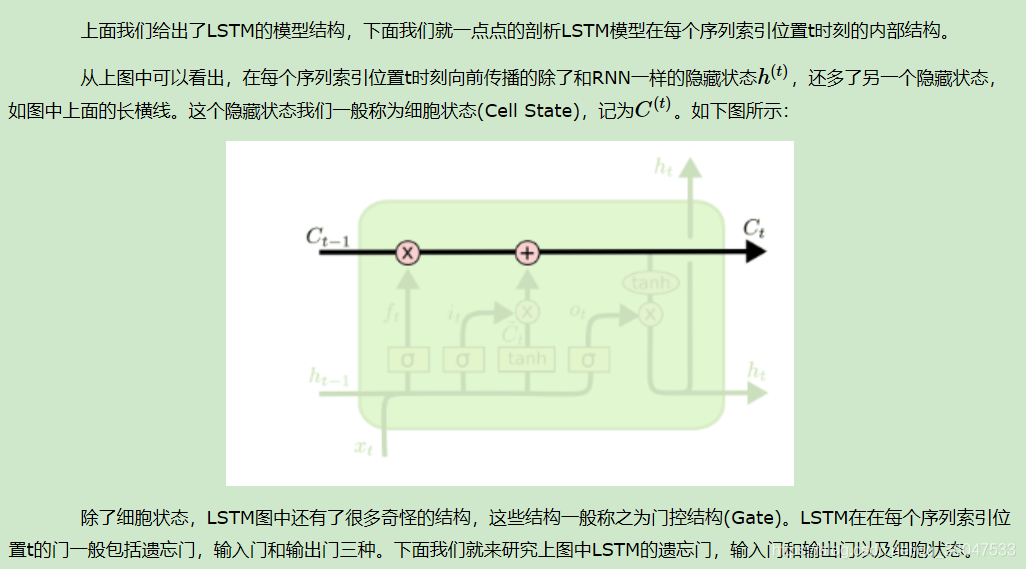
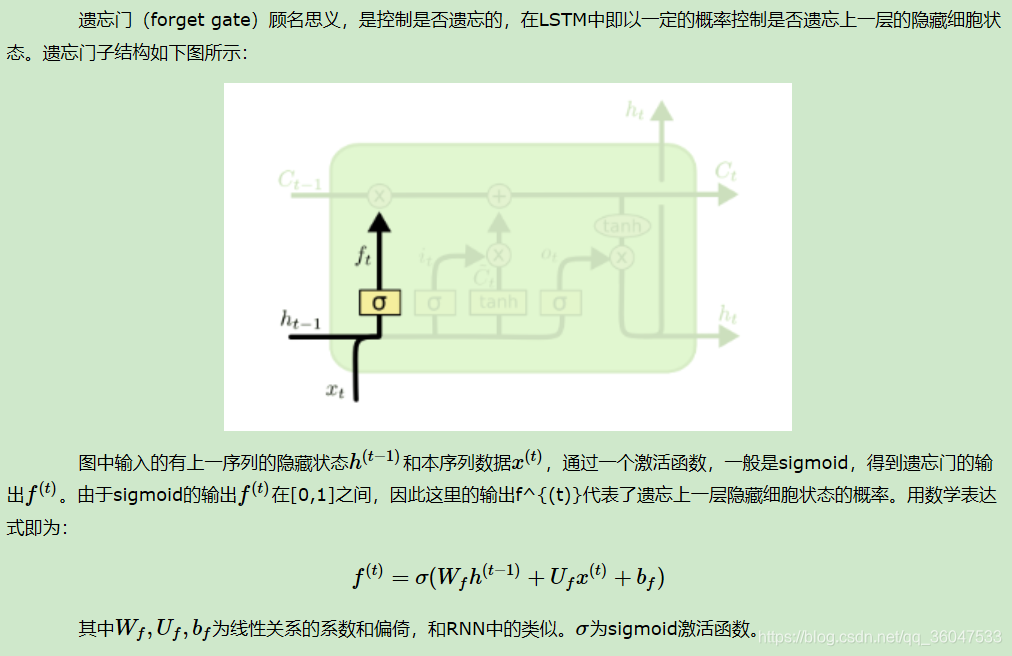
2.2.1 LSTM之遗忘门
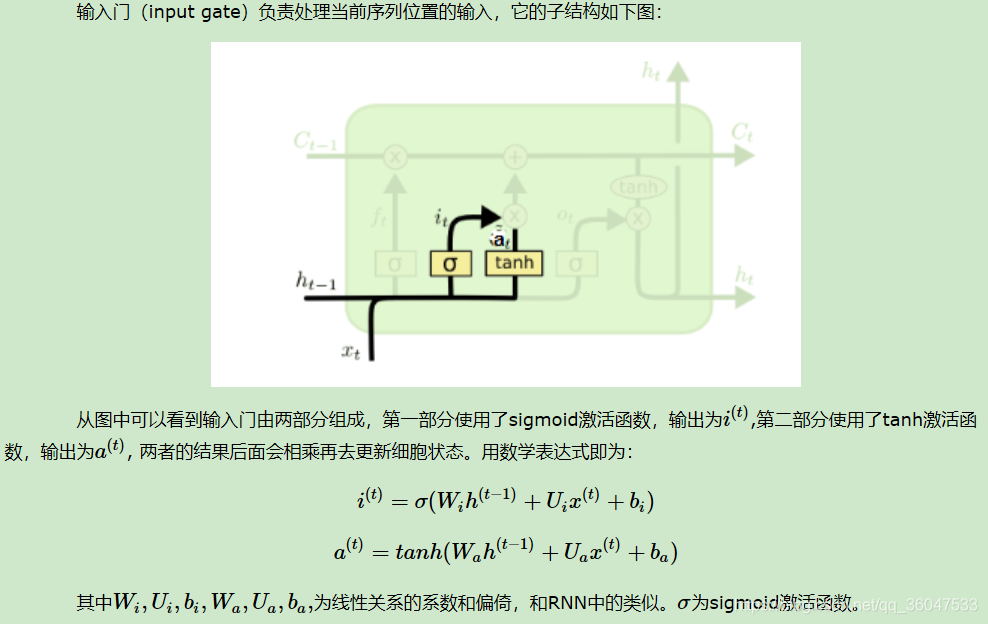
2.2.2 LSTM之输入门
2.2.3 LSTM之细胞状态更新
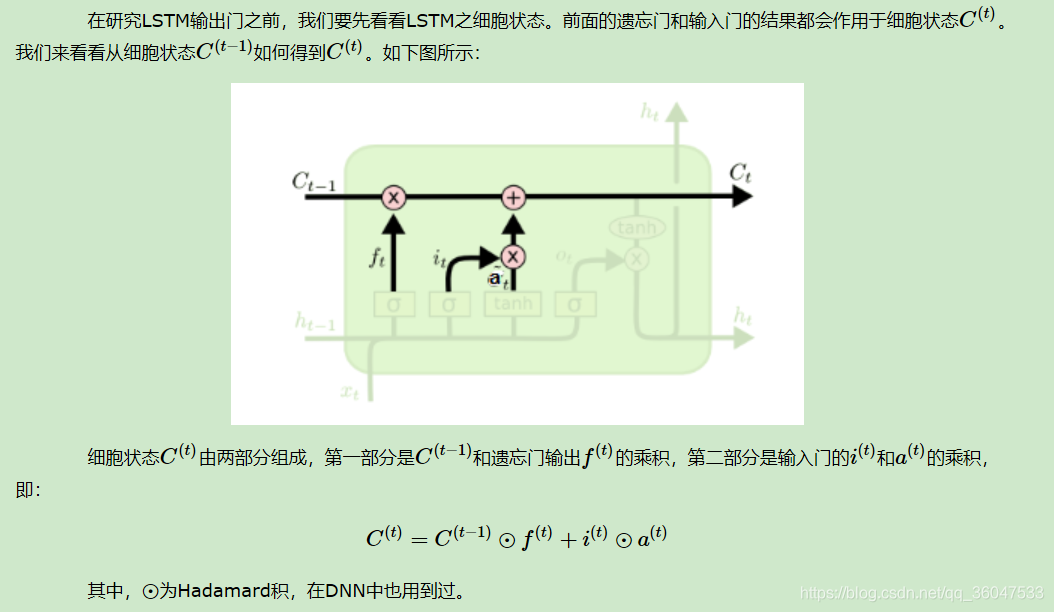
2.2.4 LSTM之输出门
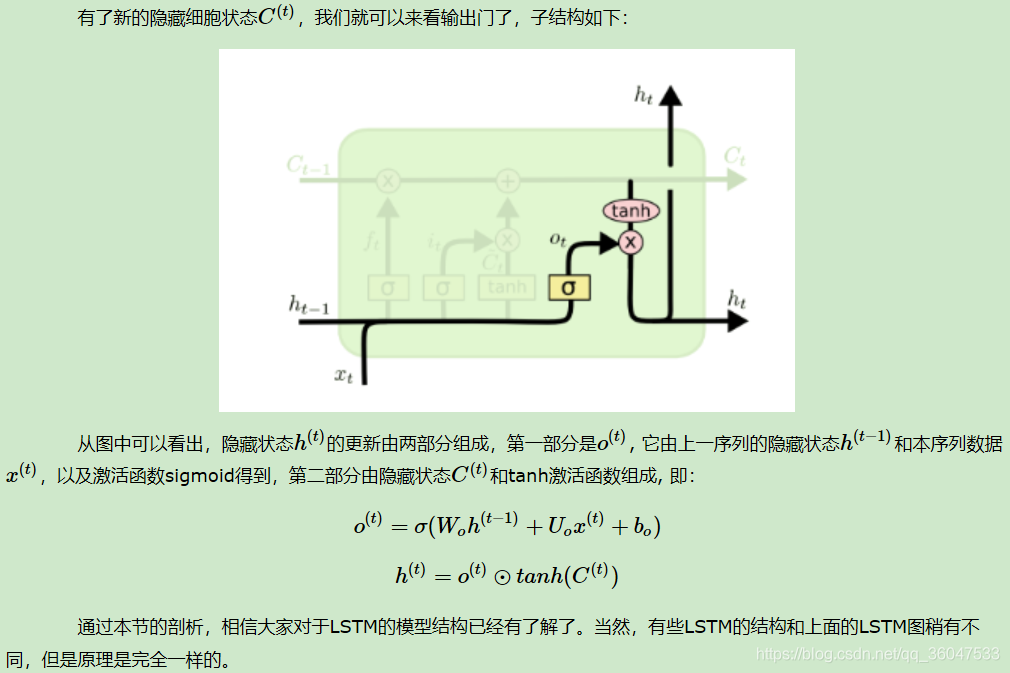
2.3 LSTM前向传播算法

2.4 LSTM反向传播算法推导关键点


这部分内容来自以下链接:
https://www.cnblogs.com/pinard/p/6519110.html
参考链接:
https://blog.csdn.net/mpk_no1/article/details/72875185
https://www.cnblogs.com/pinard/p/6519110.html
https://www.atyun.com/30234.html
https://www.cnblogs.com/pinard/p/6519110.html
3. GRU
GRU可以看成是LSTM的变种,GRU把LSTM中的遗忘门和输入门用更新门来替代。
GRU是新一代RNN,与LSTM非常相似。GRU不使用单元状态,而是使用隐藏状态来传输信息。它只有两个门,一个重置门和一个更新门(reset gate and update gate)。下图是GRU更新 h t h_t ht的过程:
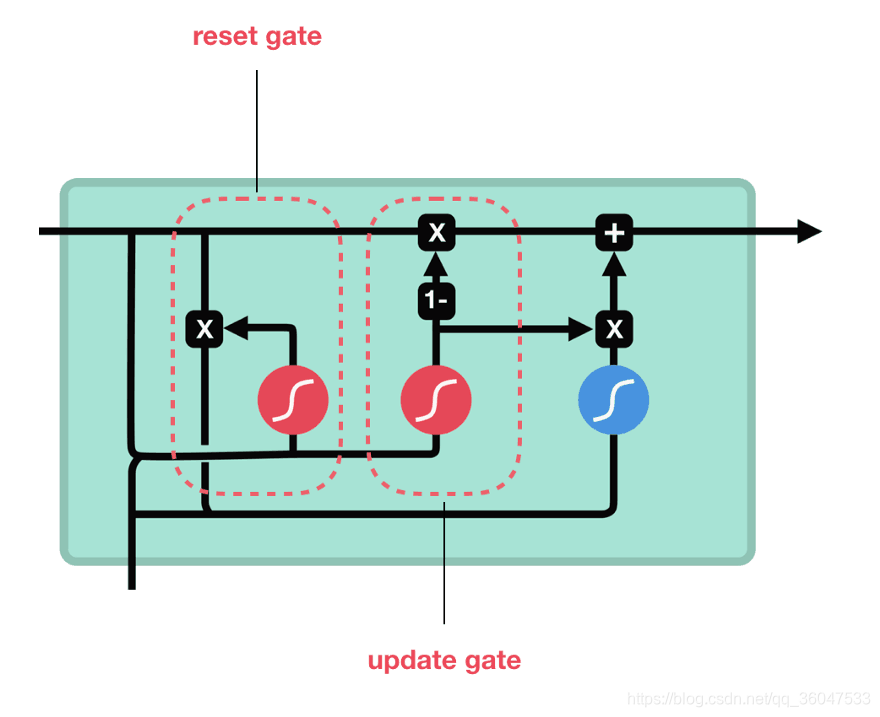
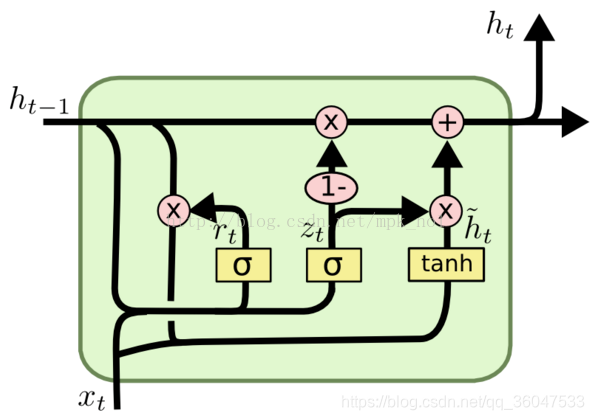
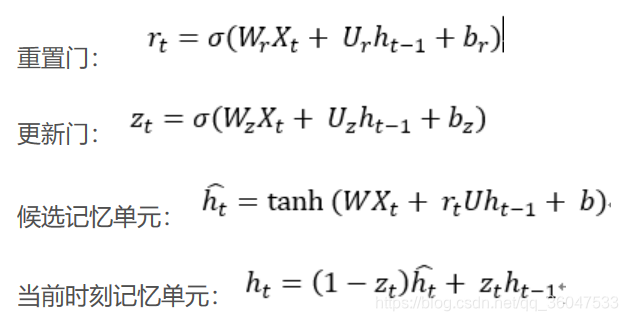
更新门的作用类似于LSTM的遗忘和输入门。它决定要丢弃哪些信息和要添加哪些新信息。
重置门是另一个用来决定要忘记多少过去的信息的门。这就是GRU。GRU的张量操作较少;因此,他们的训练速度要比LSTM快一些。
参考链接:
https://www.cnblogs.com/pinard/p/6519110.html
https://www.atyun.com/30234.html
https://blog.csdn.net/mpk_no1/article/details/72875185
4. 双向RNN
BRNN是连接两个相反的隐藏层到同一个输出.基于生成性深度学习,输出层能够同时的从前向和后向接收信息.该架构是1997年被Schuster和Paliwal提出的.引入BRNNS是为了增加网络所用的输入信息量.例如,多层感知机(MLPS)和延时神经网络(TDNNS)在输入数据的灵活性方面是非常有局限性的.因为他们需要输入的数据是固定的.标准的递归神经网络也有局限,就是将来的数据数据不能用现在状态来表达.BRNN恰好能够弥补他们的劣势.它不需要输入的数据固定,与此同时,将来的输入数据也能从现在的状态到达.
BRNN的原理是将正则RNN的神经元分成两个方向。一个用于正时方向(正向状态),另一个用于负时间方向(反向状态).这两个状态的输出没有连接到相反状态的输入。通过这两个时间方向,可以使用来自当前时间帧的过去和将来作为输入信息,输出由这两个RNN的状态共同决定。
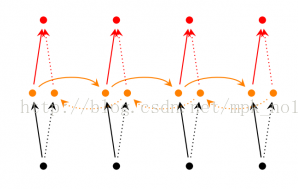
从上图可以看出,双向RNN的主题结构就是两个单向RNN的结合。在每一个时刻t,输入会同时提供给这两个方向相反的RNN,而输出则是由这两个单向RNN共同决定(可以拼接或者求和等)。
同样地,将双向RNN中的RNN替换成LSTM或者GRU结构,则组成了BiLSTM和BiGRU。
参考链接
https://www.cnblogs.com/dylancao/p/9882677.html
https://blog.csdn.net/mpk_no1/article/details/72875185
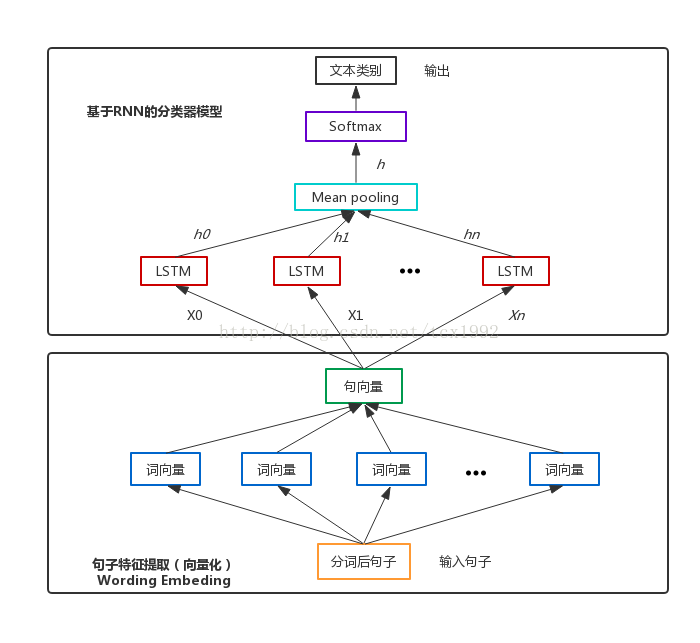
5. Text-RNN的原理
参考链接:
https://blog.csdn.net/tcx1992/article/details/78194384
利用Text-RNN模型来进行文本分类。














 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









