








Python 使用BeautifulSoup4框架获取页面中我们想要的数据(案例)
上篇文章我们说了如果通过正则表达式来进行取a标签。但是正则表达式
就需要自己去花时间写正则,如果面都的数据比较复杂,那么我们会不方便取数据所以我们应该要使用一个框架来对html内容的分析:BeautifulSoup4这个框架是大部分爬虫框架中比较简单易用又实用的框架了(废话不多说直接讲流程)
ps:本篇文章使用的框架是 BeautifulSoup4
第一步:
我们要使用requests模块就要用pip来安装:
不了解 requests可以参考案例 : https://blog.csdn.net/qq_36051316/article/details/83314826
python -m pip install requests
第二步
使用BeautifulSoup4模块就要用pip来安装:
python -m pip install BeautifulSoup4
顺利安装完上面两个东西,我们就可以开始上代码了:
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import time
url = "https://blog.csdn.net/"
# 创建一个列表,来装我们的a标签的所有内容
alists = []
html_str = requests.get(url)
#接下来就把我们获取到的html内容放到我们BeautifulSoup这个方法中,通这个方法得到一个对象,在这个对象里BeautifulSoup帮我们把整个html变成了各个节点,我们就可以利用框架快速查找到我们需要的标签。
soup = BeautifulSoup(html_str.text, 'html.parser')
#find_all 通过这个方法寻找a标签
all_a = soup.find_all('a')
#循环将a标签放到我们的列表里面
for item in all_a:
if item:
if len(item) > 2:
alists.append(item)
#循环输出列表,打印我们刚刚得到的数据
for a in alists:
#replace 这个方法是字符串处理的一种方法,我们去掉\n\t这样的话我们就可以看到不换行的结果了
print(str(a).replace("\n",""))
pass
print("当前时间: ",time.strftime('%Y.%m.%d %H:%M:%S ',time.localtime(time.time())))
ps:最后一个当前时间的使用可以参考文章:https://blog.csdn.net/qq_36051316/article/details/83472659
运行上面代码就能得到结果:
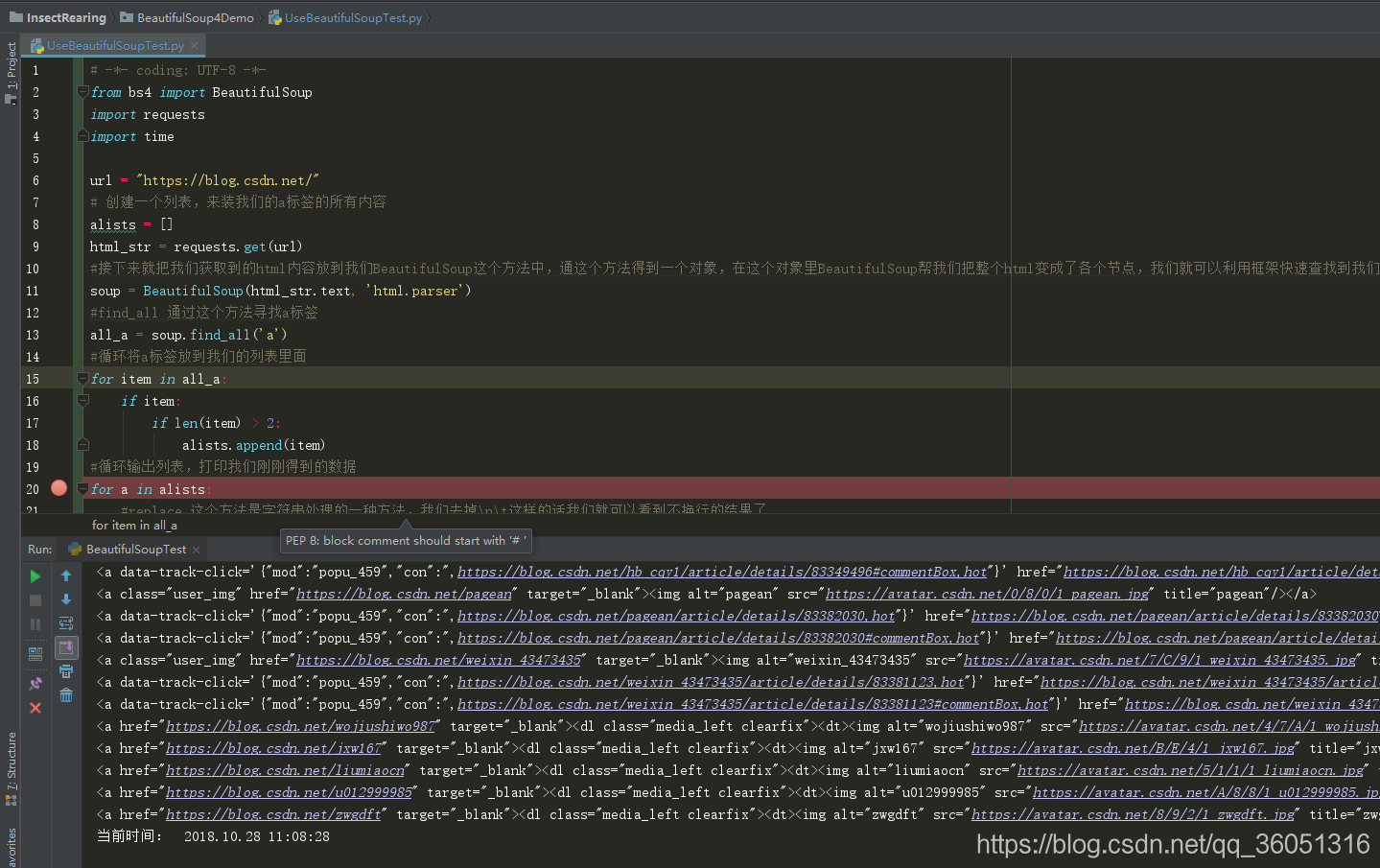
不知道大家能不能理解,博主的表达能力也是比较差的,如果有不懂的话可以留言,希望大家多多给建议!















 9875
9875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











