







***********JSP页面***************
查询数据的jsp页面内容:
a标签: href=”GetDataServlet/selectJobs”>点击获取招聘信息
表格:
<c:forEach items="${jobList}" var="job">
<tr>
<td>${job.id}</td>
<td>${job.jobName}</td>
<td>${job.company}</td>
<td style="color:gray;">${job.address}</td>
<td style="color: red;">${job.salary}</td>
<td>
<a href="#">修改</a> |
<a href="#">删除</a>
</td>
</tr>
</c:forEach>

用图状显示数据:
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: '不同薪酬的情况'
},
tooltip: {},
legend: {
data:['薪资']
},
xAxis: {
data: []
},
yAxis: {},
series: [{
name: '薪资',
type: 'bar',
data: []
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
// 发起请求
var xhr = new XMLHttpRequest();
// 定义url连接
var url = "GetDataServlet/selectAvgSal";
// 打开到服务器的连接
xhr.open("get", url, true);
// 绑定回调函数
xhr.onreadystatechange = function () {
if(xhr.readyState == 4){// 响应完成
if(xhr.status == 200){ // 响应正常200 ok
// 响应回来的text字符串数据
var data = xhr.responseText;
// 将字符串转换为json对象
var json = JSON.parse(data);
//绑定到myChart
myChart.setOption({
xAxis: {
data: json.jobNames
},
series: [{
// 根据名字对应到相应的系列
name: '平均薪酬',
data: json.avgSals
}]
});
}
}
};
// 发送请求
xhr.send(null);
</script>
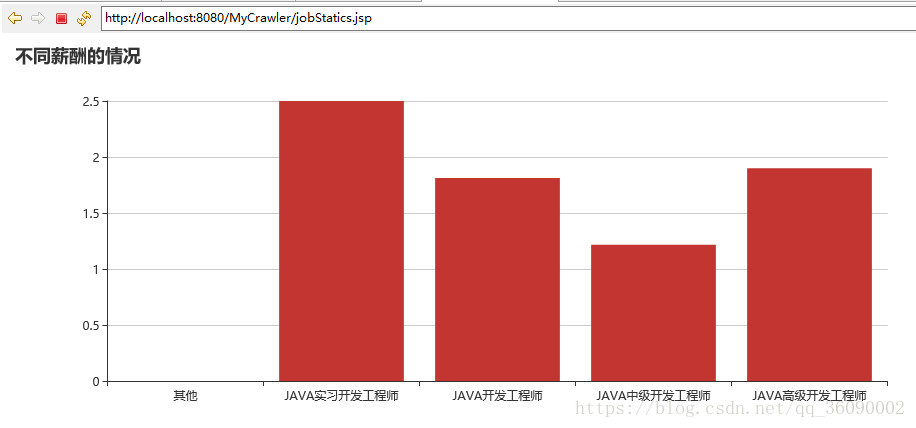
由于数据没有处理好,在图状显示的时候有点瑕疵,望大佬们见谅
项目jar包:
***********END***************














 5130
5130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









