







1 Method
1.作者发现直接将输入图像直接使用Transformer进行编码,并且将得到的特征图直接上采样到全分辨率的密集输出,无法产生令人满意的结果。
2. 原因为:Transformers将输入视为1D序列,并且只关注在所有阶段建模的全局上下文信息,因此会缺乏详细的局部信息。并且,这些信息无法通过直接上采样到完整分辨率来恢复,因此会导致粗略的分割结果。
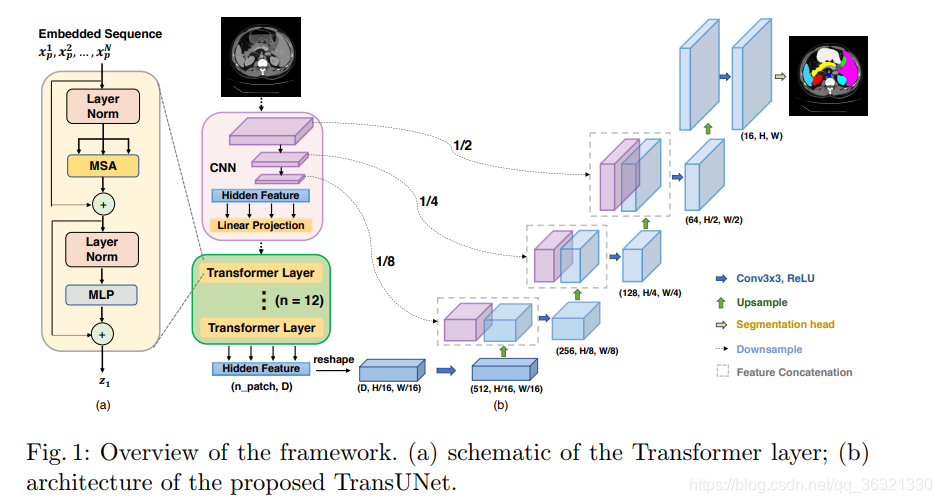
3. TransUNet采用混合CNN-Transformer结构,充分利用了来自CNN特征的详细高分辨率空间信息以及来自Transformer的全局上下文信息。
输入图像
X
∈
R
H
×
W
×
C
X \in \mathbb{R}^{H \times W \times C}
X∈RH×W×C,我们的目标为预测尺寸为
H
×
W
H \times W
H×W 的像素级标签图。
首先将 X X Xreshape成一些序列经过flattened 2D patched { x p i ∈ R P 2 ⋅ C ∣ i = 1 , … , N } \{ x^{i}_p \in \mathbb{R}^{P^{2}\cdot C } | i=1,\ldots,N \} {xpi∈RP2⋅C∣i=1,…,N},其中patch的大小为 P × P P \times P P×P, N = H W P 2 N = \frac{HW}{P^{2}} N=P2HW是patch的数目。
Patch Embedding 使用可训练的线性投影将向量化的patch
x
p
x_{p}
xp映射到潜在的D维空间中。为了对patch的空间信息进行编码,我们学习特定的位置嵌入(Position Embedding),将其添加到patch embedding中以保留空间位置信息。(跟NLP类似,只不过NLP Transformer中的Position Embedding不是可训练的,直接用公式计算)
z
0
=
[
x
p
1
E
;
x
p
2
E
;
⋯
;
x
p
N
E
]
+
E
p
o
s
z_{0}=[x^{1}_pE;x^{2}_pE;\cdots;x^{N}_pE]+E_{pos}
z0=[xp1E;xp2E;⋯;xpNE]+Epos
其中
E
∈
R
(
P
2
⋅
C
)
×
D
E \in \mathbb{R}^{(P^2 \cdot C)\times D}
E∈R(P2⋅C)×D是patch embedding投影,
E
p
o
s
∈
R
N
×
D
E_{pos} \in \mathbb{R}^{N \times D}
Epos∈RN×D表示position embedding.
Transformer的编码器由L层多头自注意力(Multihead Self-Attention,MSA)和多层感知器(Multi-Layer Perceptron,MLP)模块组成,因此第l层的输出可以进行如下表示:
z
l
′
=
M
S
A
(
L
N
(
z
l
−
1
)
)
+
z
l
−
1
z'_{l}=MSA(LN(z_{l-1}))+z_{l-1}
zl′=MSA(LN(zl−1))+zl−1
z
l
=
M
L
P
(
L
N
(
z
l
′
)
)
+
z
l
′
z_{l}=MLP(LN(z'_{l}))+z'_{l}
zl=MLP(LN(zl′))+zl′
其中,
L
N
(
⋅
)
LN(\cdot)
LN(⋅)表示层归一化运算,
z
l
z_{l}
zl表示编码的图像表示。
TransUNet
方法1:将特征图
z
L
∈
R
H
W
P
2
×
D
z_{L} \in \mathbb{R}^{\frac{HW}{P^{2}} \times D}
zL∈RP2HW×D直接上采样到全分辨率,以预测输出。为了恢复空间顺序,将
H
W
P
2
\frac{HW}{P^{2}}
P2HW reshape成
H
P
×
W
P
\frac{H}{P} \times \frac{W}{P}
PH×PW,并通过
1
×
1
1 \times 1
1×1的卷积将通道数目减小到类别数,最后直接对特征图进行双线性上采样到
H
×
W
H \times W
H×W大小,以预测最终的分割结果。
缺点:方法1理论上行得通,但是 H P × W P \frac{H}{P} \times \frac{W}{P} PH×PW通常比 H × W H \times W H×W小很多,因此在上采样过程中会丢失很多低级细节。
为了补偿低级细节的丢失,TransUNet采用混合CNN-Transformer结构作为编码器以及级联上采样器(Cascaded Upsampler)。原始图像先经过CNN进行特征提取,然后再Transformer进行编码。级联上采样器类似于UNet上采样,逐层恢复空间大小并结合skip connection。
Experiments
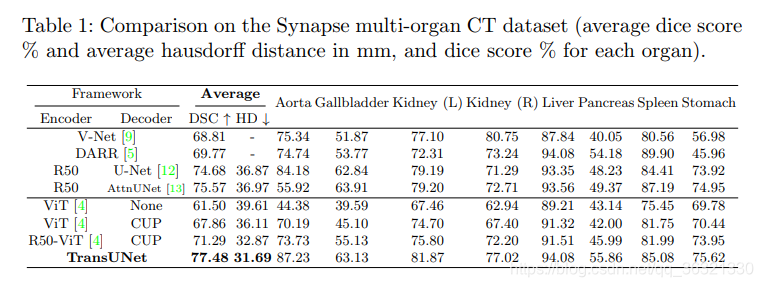
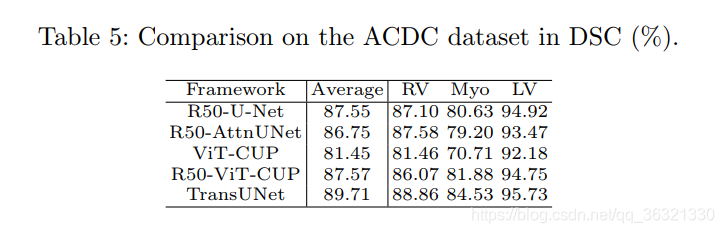
Decoder为None的是方法1,CUP表示级联上采样器。可以发现直接transformer的分割方法确实差很多。
消融实验:
1.证明了CUP比None好
2.纯Transformer做分割会由于失去低级细节导致不如UNet等传统网络效果好。
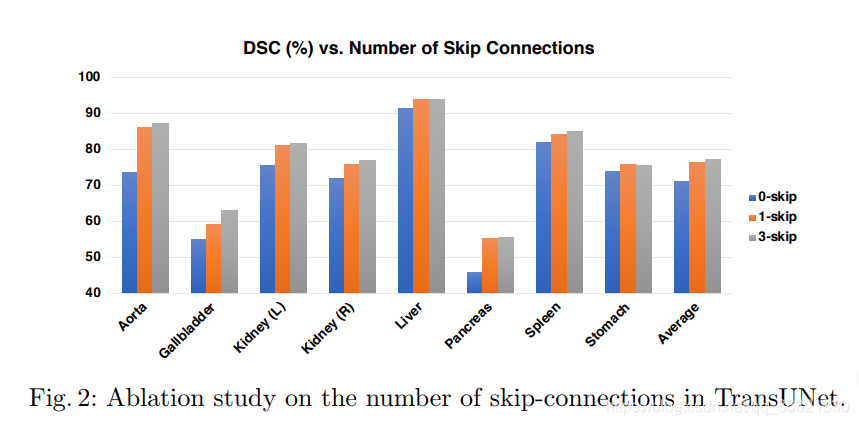
3.skip connection的数量越多,分割效果越好(作者只测试了0 1 2 3 个skip connection的实验)
4.当图像的分辨率从
224
×
224
224 \times 224
224×224变成
512
×
512
512 \times 512
512×512并保持patch size不变(16)时,Average DSC提高了6.88%。但是此时需要付出更大的计算代价。

5. 较小的patch size可以获得更高的分割性能。注意:patch size与sequence length成反比,(patch size = 16,sequence size=196;patch size = 32,sequence size=49),本文的patch size选的是16.

6.对比两种不同参数的TransUNet
Base:hidden size:12 , layers数目:768 , MLP大小:3072 , head数目: 12
Large:hidden size:24 , layers数目:1024 , MLP大小:4096 , head数目: 16
考虑计算成本,本文用的Base

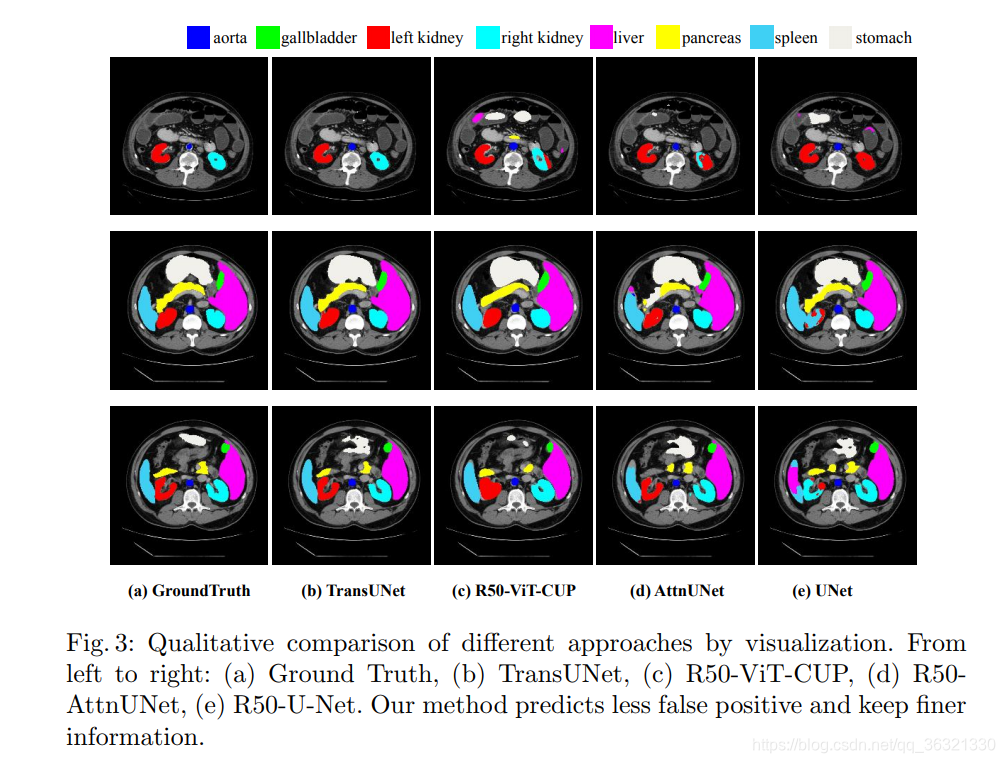
Visualizations














 4087
4087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









