










在机器视觉,图像处理领域,卷积神经网络取得了巨大的成功。本文将参考UFLDL和DEEPLEARNING.NET的教程,结合自己的理解,梳理一下卷积神经网络的构成以及其BP算法的求解。虽然利用theano可以方便的实现LeNet5,但是不利于学习和理解卷积神经网络,所以最后会自己动手用Python实现一个简单的LeNet5,并尝试利用python的PyCUDA库进行加速。
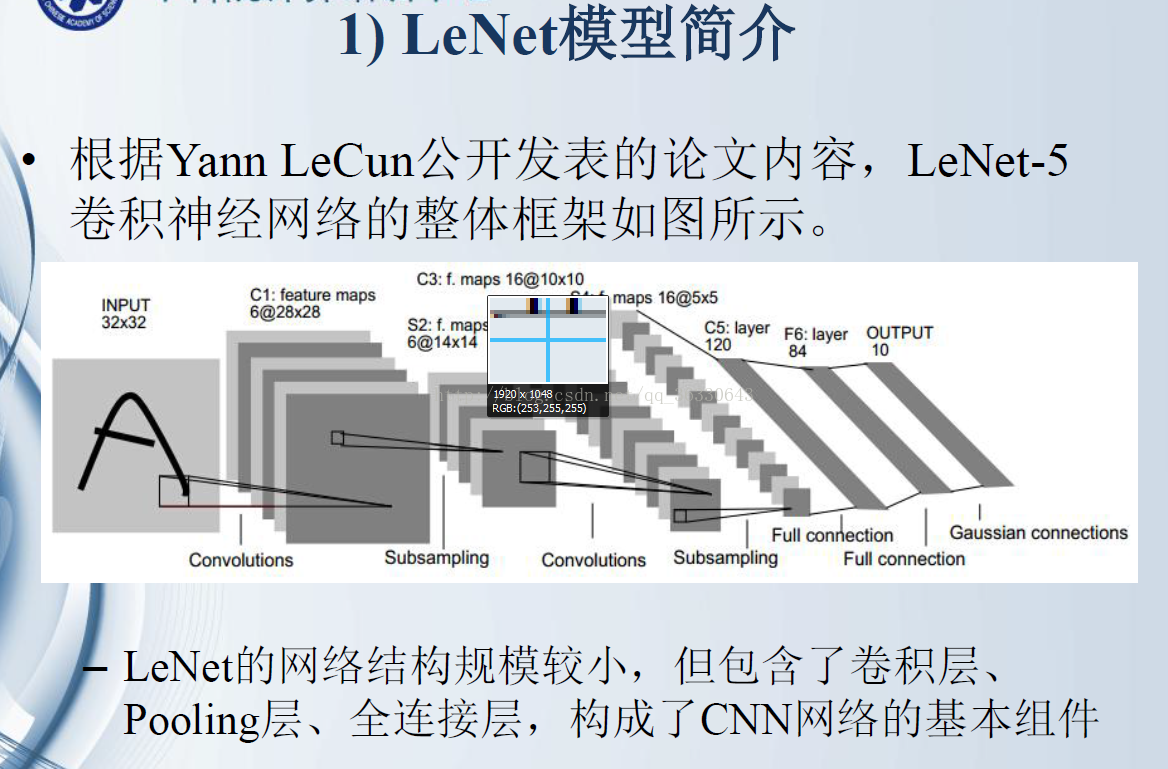
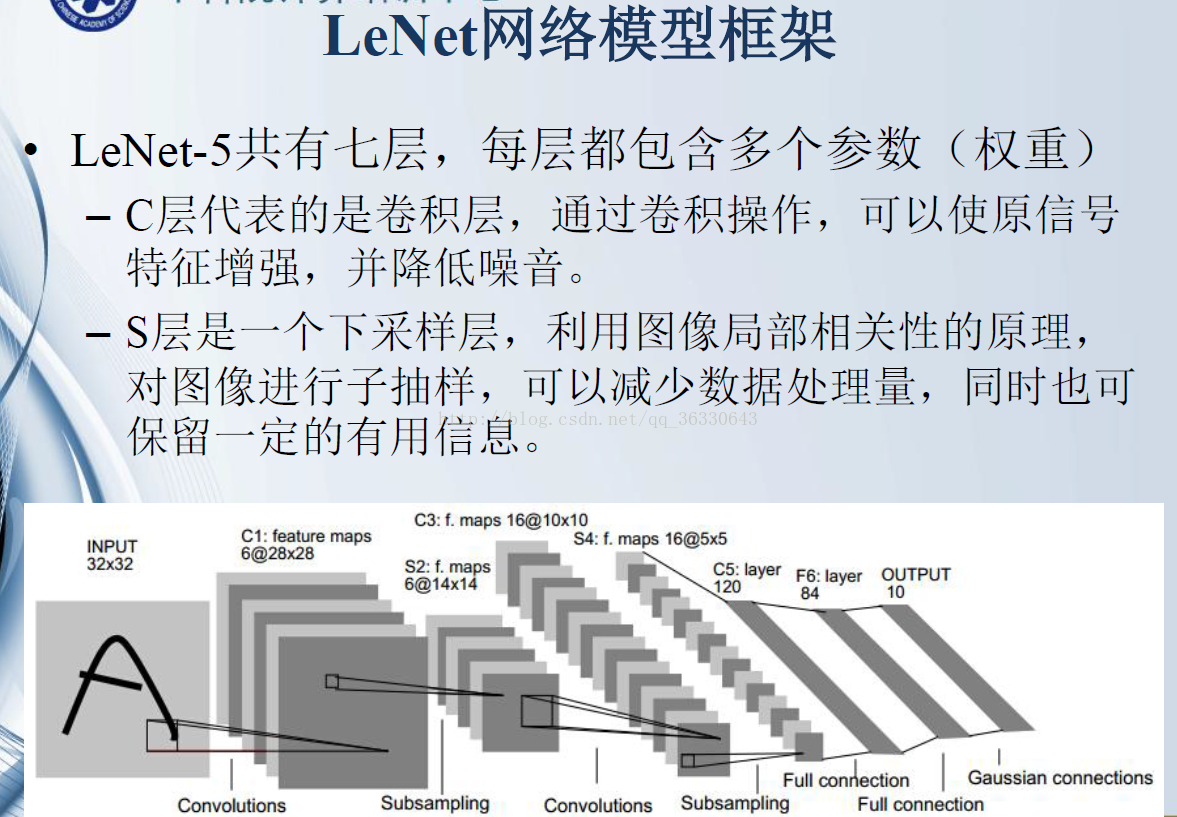
LeNet-5共有7层(不包含输入),每层都包含可训练参数。
输入图像大小为32*32,比MNIST数据集的图片要大一些,这么做的原因是希望潜在的明显特征如笔画断点或角能够出现在最高层特征检测子感受野(receptive field)的中心。因此在训练整个网络之前,需要对28*28的图像加上paddings(即周围填充0)。
C1层:该层是一个卷积层。使用6个大小为5*5的卷积核对输入层进行卷积运算,特征图尺寸为32-5+1=28,因此产生6个大小为28*28的特征图。这么做够防止原图像输入的信息掉到卷积核边界之外。
S2层:该层是一个池化层(pooling,也称为下采样层)。这里采用max_pool(最大池化),池化的size定为2*2,池化的具体过程如下图(图引自cs231n)
经池化后得到6个14*14的特征图,作为下一层神经元的输入。
C3层:该层仍为一个卷积层,我们选用大小为5*5的16种不同的卷积核。这里需要注意:C3中的每个特征图,都是S2中的所有6个或其中几个特征图进行加权组合得到的。输出为16个10*10的特征图。
S4层:该层仍为一个池化层,size为2*2,仍采用max_pool。最后输出16个5*5的特征图,神经元个数也减少至16*5*5=400。
C5层:该层我们继续用5*5的卷积核对S4层的输出进行卷积,卷积核数量增加至120。这样C5层的输出图片大小为5-5+1=1。最终输出120个1*1的特征图。这里实际上是与S4全连接了,但仍将其标为卷积层,原因是如果LeNet-5的输入图片尺寸变大,其他保持不变,那该层特征图的维数也会大于1*1。
F6层:该层与C5层全连接,输出84张特征图。为什么是84?下面有论文的解释(感谢翻译)。
输出层:该层与F6层全连接,输出长度为10的张量,代表所抽取的特征属于哪个类别。(例如[0,0,0,1,0,0,0,0,0,0]的张量,1在index=3的位置,故该张量代表的图片属于第三类)
此处为论文对F6层和输出层的解释:
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
使用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。
tensorflow代码实现:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
slim = tf.contrib.slim
def lenet(images, num_classes=10, is_training=False,
dropout_keep_prob=0.5,
prediction_fn=slim.softmax,
scope='LeNet'):
"""Creates a variant of the LeNet model.
Note that since the output is a set of 'logits', the values fall in the
interval of (-infinity, infinity). Consequently, to convert the outputs to a
probability distribution over the characters, one will need to convert them
using the softmax function:
logits = lenet.lenet(images, is_training=False)
probabilities = tf.nn.softmax(logits)
predictions = tf.argmax(logits, 1)
Args:
images: A batch of `Tensors` of size [batch_size, height, width, channels].
num_classes: the number of classes in the dataset.
is_training: specifies whether or not we're currently training the model.
This variable will determine the behaviour of the dropout layer.
dropout_keep_prob: the percentage of activation values that are retained.
prediction_fn: a function to get predictions out of logits.
scope: Optional variable_scope.
Returns:
logits: the pre-softmax activations, a tensor of size
[batch_size, `num_classes`]
end_points: a dictionary from components of the network to the corresponding
activation.
"""
end_points = {}
with tf.variable_scope(scope, 'LeNet', [images, num_classes]):
net = slim.conv2d(images, 32, [5, 5], scope='conv1')
net = slim.max_pool2d(net, [2, 2], 2, scope='pool1')
net = slim.conv2d(net, 64, [5, 5], scope='conv2')
net = slim.max_pool2d(net, [2, 2], 2, scope='pool2')
net = slim.flatten(net)
end_points['Flatten'] = net
net = slim.fully_connected(net, 1024, scope='fc3')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout3')
logits = slim.fully_connected(net, num_classes, activation_fn=None,
scope='fc4')
end_points['Logits'] = logits
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
lenet.default_image_size = 28
def lenet_arg_scope(weight_decay=0.0):
"""Defines the default lenet argument scope.
Args:
weight_decay: The weight decay to use for regularizing the model.
Returns:
An `arg_scope` to use for the inception v3 model.
"""
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=tf.truncated_normal_initializer(stddev=0.1),
activation_fn=tf.nn.relu) as sc:
return sc
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











