







 这篇博客介绍了中科大肖明军教授团队利用组合多臂老虎机和三阶段Stackelberg博弈解决移动感知数据交易中的卖家选择和激励机制问题。研究关注如何在数据质量未知和多方利益最大化间找到平衡,通过实验验证了方法的有效性和性能优越性。
这篇博客介绍了中科大肖明军教授团队利用组合多臂老虎机和三阶段Stackelberg博弈解决移动感知数据交易中的卖家选择和激励机制问题。研究关注如何在数据质量未知和多方利益最大化间找到平衡,通过实验验证了方法的有效性和性能优越性。
这是一篇关于移动感知数据交易的论文,最近在做的另一项工作借鉴了其中的一些想法和思路,本篇博客对这篇文章进行一个详细的介绍。

目录
文章简介
文章作者:中科大的肖明军教授和谢希科老师团队
主要思想:基于组合多臂老虎机和三阶段 Hierarchical Stackelberg 博弈,实现群智感知数据交易中的各方利润最大化。
应用场景:交易涉及三方:买家、平台和卖家。1)买家向平台提出购买需求;2)平台根据兴趣点 PoIs 选择合适的卖家;3)卖家收集移动感知数据反馈给平台;4)平台对数据进行整理并反馈给买家;5)买家获得数据并支付给平台相应费用;6)平台向卖家支付一定数据交易的费用。

两大挑战
挑战1️⃣:在各个卖家感知数据质量未知的情况下,如何选择一组合适的卖家进行数据收集,以实现总体收集数据的质量最大化,是挑战之一。
- 为了选择合适的卖家,平台需要将数据收集过程划分成多个轮次,在迭代中学习各个卖家的数据质量(此过程可看作 exploration);与此同时,平台可以根据以往迭代的数据质量信息,选择合适的卖家进行数据收集(此过程可看作 exploitation)。总体而言,这是一个在线学习和决策制定的过程。于是,目标变成如何平衡exploration和exploitation,使得收集到的数据的质量最大化。
挑战2️⃣:在确定合适卖家的前提下,如何设置激励机制,以实现参与交易的卖家、平台和买家三方的利益最大化,是挑战之二。
- 为了保证得到足够多的数据,平台需要为卖家设置激励政策,通过为卖家提供合适的利润,使得卖家愿意参与到数据收集工作中来。**(注意,平台作为代理,有权操控卖家所获得的收益。)**同时,为确保平台自身的收益,平台还需要兼顾处理数据的成本。
- 同时,卖家也要权衡自己所得到的收益和自己付出的成本,来决定是否要参与到数据收集工作中来;
- 买家在得到数据之后,在确保数据质量符合自身需求的前提下,向平台支付相应费用。
由 Figure 2 可知,数据卖家的选择(步骤2)和最优激励策略的制定(步骤3)是存在先后顺序的,也就是说,只有确定了收集数据的卖家,才能够根据不同卖家的数据质量确定不同卖家的激励策略。

本文方法
针对上述两大挑战,本工作分别使用组合多臂老虎机和三阶段级联Stackelberg博弈。下面分别对二者展开介绍。
组合多臂老虎机(Combinatorial Multi-Armed Bandit,CMAB)
很小的时候就了解过多臂老虎机,这是赌场中常会出现的一种机器。多臂老虎机是强化学习中比较经典的一个方法,简单来说就是,拉下每个臂,得到的奖励都不同,每个臂可以看作是一个独立的个体。(关于多臂老虎机已经有很多资料,这里不赘述,感兴趣的朋友可以查看文末给出的参考链接。) 这篇文章把数据质量未知的卖家选择过程抽象成 CMAB 问题。具体而言,每个卖家被看作是一个臂,感知数据的质量就是拉下臂对应的奖励(reward,看到这个词就会联想到强化学习哈哈)。
这篇文章采用的算法是 Upper Confidence Bound (UCB)-based greedy policy,关于UCB的介绍,详见这篇文章,或UCB1对应的论文
三阶段级联Stackelberg博弈(Hierarchical Stackelberg Game)
这篇文章把最优激励策略的制定抽象成一个三阶段级联Stackelberg博弈过程,其中,消费者是一级领导者,平台是二级领导者,卖家是追随者。
- 需要注意的是:
- Sellers 收集数据需要成本;
- Platform 整合并处理数据需要成本;
- Consumer 享受数据带来的经济效益。
为实现三方的利润最大化,在每一轮次,消费者决定数据整体处理的单价 P J , t P^{J,t} PJ,t;平台决定卖家的数据收集单价 P t P^t Pt;每个卖家 i i i 决定自身收集数据的感知时间 τ i t \tau^t_i τit。这样一来,激励机制就由三元组 < P J , t , P t , τ i t > <P^{J,t}, P^{t}, \tau^t_{i}> <PJ,t,Pt,τit> 决定。
通过设计三方的利润函数,使用逆向归纳法对三方掌握的变量进行求解,最终得到满足三方利益最大化的变量值,得到博弈的均衡状态。三方的利润函数分别如下:
- Sellers:其中第一项是平台拨给卖家的收益,第二项是卖家收集数据的成本。

- Platform:其中第一项是买家支付给平台的费用,第二项是平台拨给卖家的费用,最后一项是平台整理数据的成本。

- Consumer:其中第一项是买家预估的数据效益,第二项是买家支付给平台的费用。

最终,上述目标就变成了求解以下变量:

如果求解出的变量值满足以下条件,就可以说达到了Stackelberg均衡。

理想状态下,通过求二阶导的形式,就能够确定一个方程是否存在最优解。
实验结果
这篇文章使用 Chicago Taxi Trips 数据集,选取部分( L = 10 L=10 L=10)上客点和下客点作为感兴趣点(PoIs),发现周边 300 300 300个 taxi,也就是seller。选择其中 M M M个taxi 作为所有数据收集来源的seller,第一步就是 M M M 中选 K K K 个 seller 进行数据收集,收集轮次为 N N N. 由于没有关于数据质量的记录,数据的期望质量随机从 [0,1] 中选取,数据的实际观测质量从截断高斯分布中选取。
关于挑战1️⃣,作者通过对 N N N M M M K K K 进行消融实验,证实了本文提出CMAB方法的有效性,相对于其他baseline,能够更好的逼近 optimal revenue,且regret最低。
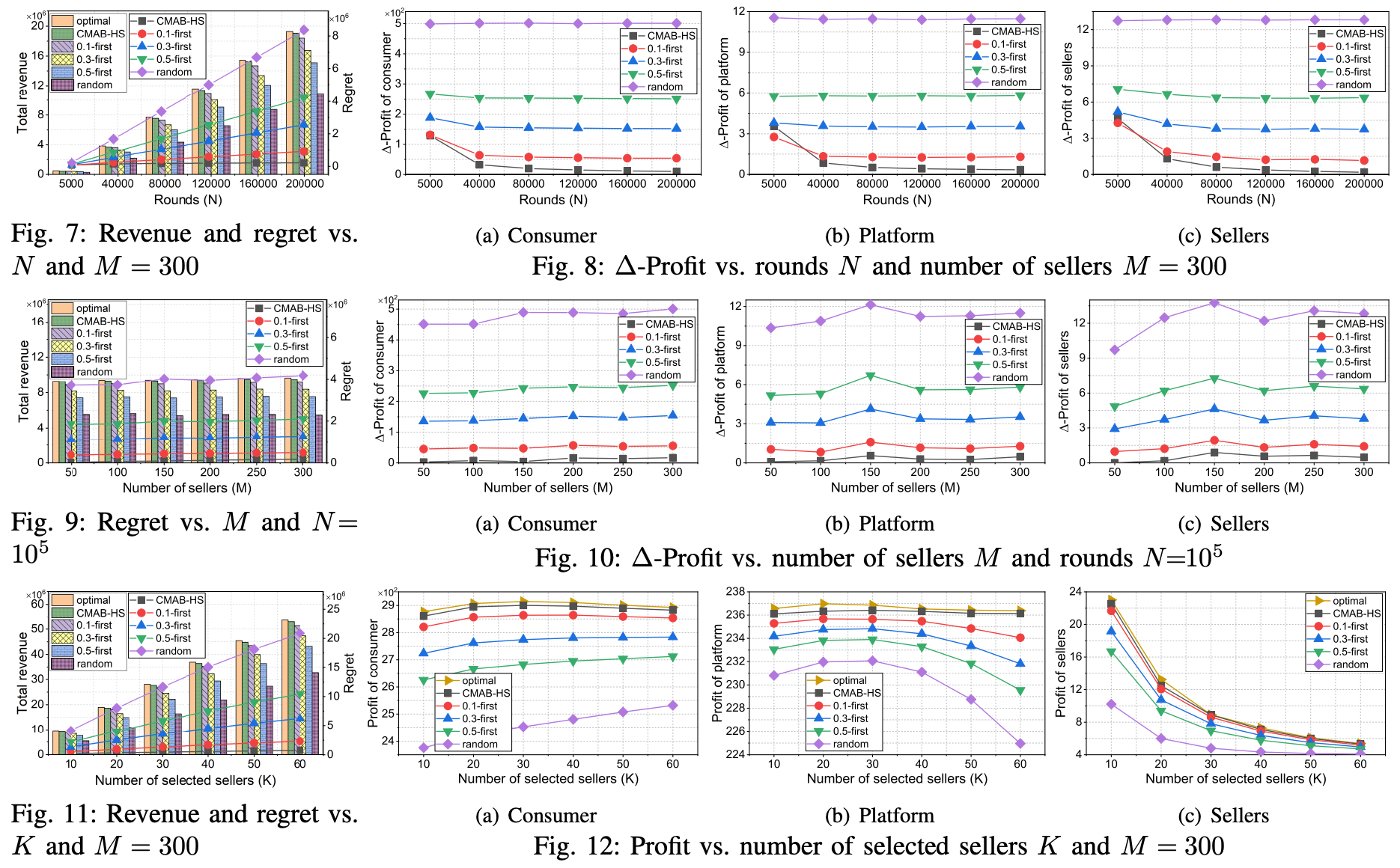
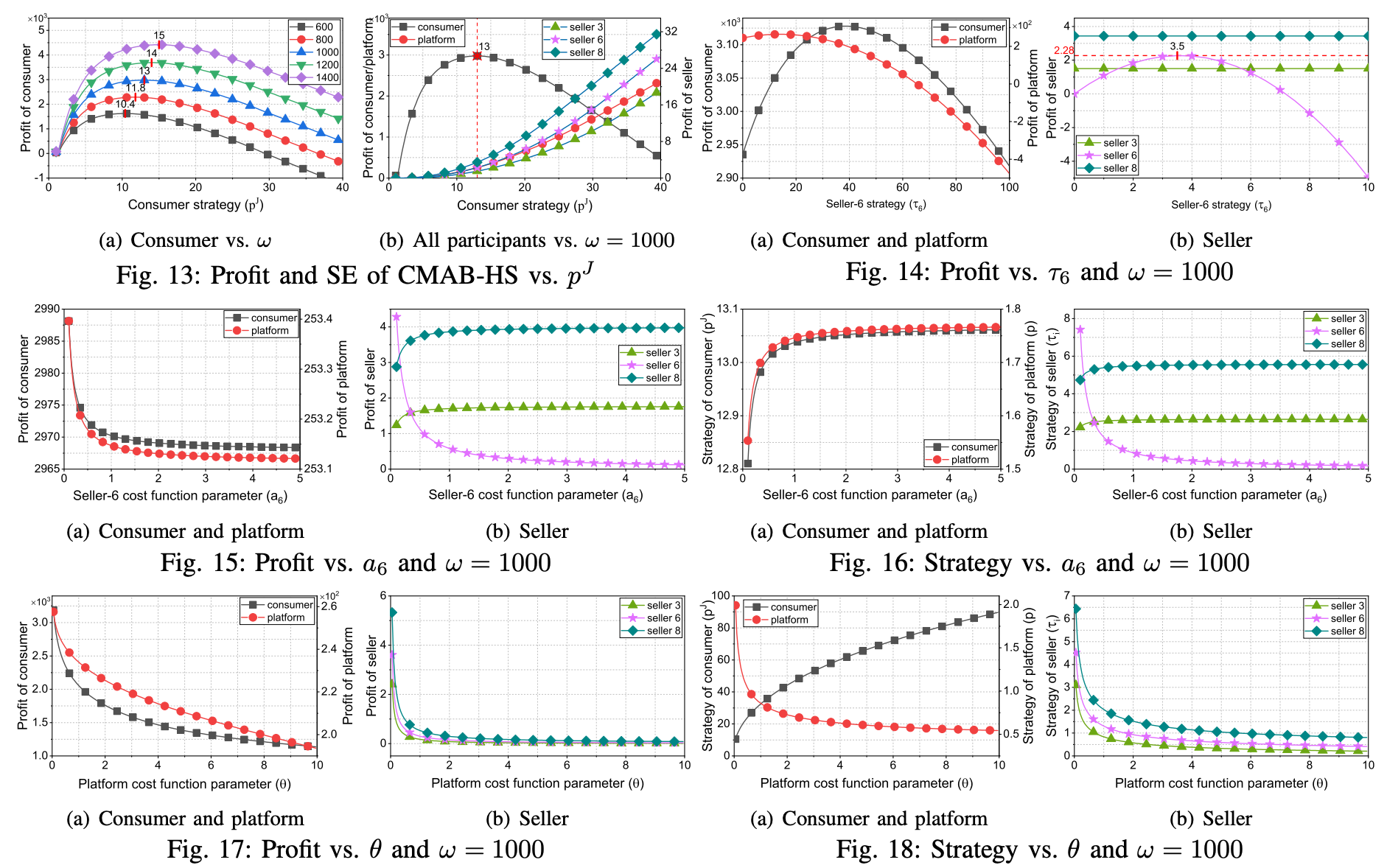
关于挑战2️⃣,作者通过对 θ \theta θ、 ω \omega ω 等参数的消融实验,结合三方的利润变化, Δ \Delta Δ-PoC\、 Δ \Delta Δ-PoP、 Δ \Delta Δ-PoS,证实了三阶段级联Stackelberg博弈的有效性。
















 5747
5747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











