







KMP算法是解决字符串匹配问题的高效算法
问题
字符串匹配问题:
假设文本是一个长度为n的数组T[0...n-1],而模式是一个长度为m的数组P[0...m-1],其中m<=n,如果存在s(0<=s<=n-m),并且T[s...s+m-1]=P[0...m-1],那么称模式P在文本T中出现,且P在T中出现的位置是以s开始的。找出所有模式P在T中出现的开始位置,通俗地说就是找字符串P在T中出现的位置。
算法思想
一般的暴力算法,就是从T的第一个字符开始,和P逐个字符进行比较,如果中间有字符不相等就,从T的第二个字符进行比较 ....直到末尾。
KMP算法力求匹配了的字符串,不再进行比较,即一次匹配到P的i+1了,说明T[s...s+ i] 和P[0...i]是相等的,此时如果T[s+ i+1]和P[i+1]不相等,那么应该从T和P的什么位置进行比较呢?
KMP在这个问题上进行了优化,即事先求出P字符串和 P的子串(从第一个字符开始,到 i ( 0 <= i< P.length))的所有前缀的长度(前缀 : 字符串从第一个字符开始匹配)
比较过程:
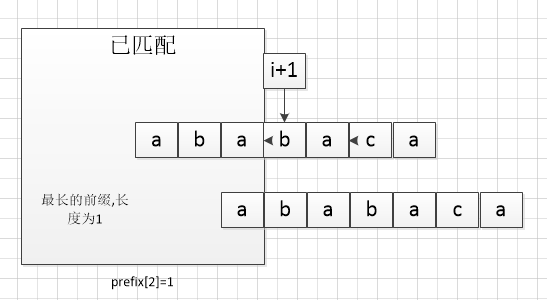
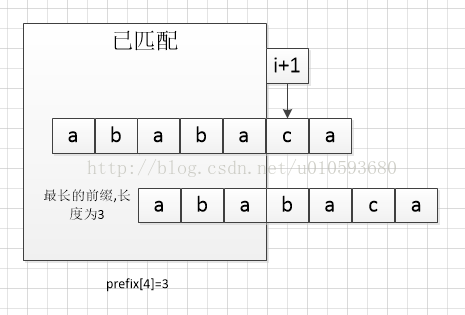
如果现在T和P已经匹配到了P[i+1],即已经确定P[0...i]=T[s...s+i],那么如果如果此时P[i+1] != T[s+i+1],那么将T[s+i+1]和P[ prefix[i] ]相比较,而第一步就是要求prefix[i]的,prefix[i]数组中保存的是:当只有p[0...i]的字符串时,此时,p[0...i]的后部的字符串与p[0...i]的前部的字符串匹配的最大长度,(不包含自身与自身匹配的情况)
求ababaca的最长匹配的字符串的长度:
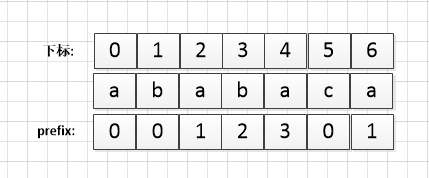
p[0]时的最长匹配的字符串的长度明显为0,
p[0...1]时的最长匹配的字符串的长度也明显为0,
当已经匹配了P[0...2]时:
当已经匹配了P[0...4]时:
计算前P[0...i]( 0=<i<=m-1)的最长匹配字符串的长度代码:
void kmpPrefixFunction(char *p,int length,int *prefix)
{
prefix[0]=0;
int k = 0;//前缀的长度
for(int i=1; i<length; i++)
{
while(k>0&&p[k]!=p[i])
{
k=prefix[k-1];
}
if(p[k]==p[i])//说明p[0...k-1]共k个都匹配了
{
k=k+1;
}
prefix[i]=k;
}
}接下来就是利用前面求得的prefix[]数组来加快字符串匹配速度了
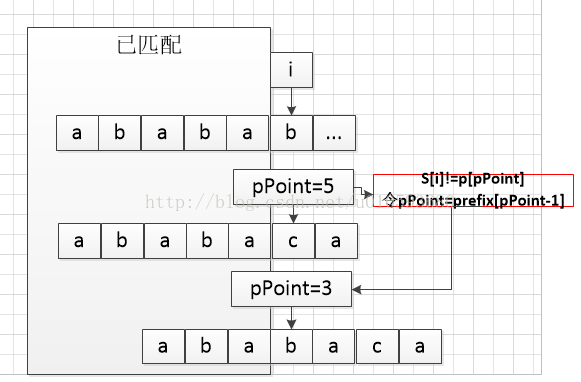
当我们的模式P[0...i-1]已经与S[k...k+i-1]中的字符匹配了,当p[i]不能与S[k+i]匹配时,我们不能无视S[k...k+i-1],将P直接向右移动i-1个字符,直接令s[k+i]与p[0]比较,是因为可能S[k...k+i-1]的后部字符串可能和P的前部字符串相匹配,如下图匹配到P[5]时,与S不匹配了,但这时S的后部与P[0...3]匹配了。/微笑,这时大家应该感觉到刚才求得的prefix[]数组的作用了吧!! 当S[i]!=p[pPoint]时,令pPoint=prefix[pPoint-1],接下来继续将S[i]与p[pPoint]相比较,不行,再令pPoint=prefix[pPoint-1]...(当pPoint等于0时,说明,S后部没有和P前部匹配的,就可以无视已经匹配的S[k...k+i-1]了,直接s[k+i]与p[0]比较了)
匹配函数的源代码:
void kmpMatch(char * s,int sLength,char * p,int pLength,int *prefix)
{
int pPoint=0;
for(int i=0; i<=sLength-pLength;i++)
{
while(pPoint!=0&&(s[i]!=p[pPoint]))
{
pPoint = prefix[pPoint-1];
}
if(s[i]==p[pPoint])
{
pPoint++;
if(pPoint == pLength)
{
printf("找到:%d \n",i-pPoint+1);
//pPoint = 0;//上一个在s匹配的字符串,不能成为下一个匹配字符串的一部分
pPoint=prefix[pPoint-1];//上一个在s匹配的字符串,也能成为下一个匹配字符串的一部分
}
}
}
}最后把以上函数和测试代码一并发上:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void kmpMatch(char * s,int sLength,char * p,int pLength,int *prefix)
{
int pPoint=0;
for(int i=0; i<=sLength-pLength;i++)
{
while(pPoint!=0&&(s[i]!=p[pPoint]))
{
pPoint = prefix[pPoint-1];
}
if(s[i]==p[pPoint])
{
pPoint++;
if(pPoint == pLength)
{
printf("找到:%d \n",i-pPoint+1);
//pPoint = 0;//上一个在s匹配的字符串,不能成为下一个匹配字符串的一部分
pPoint=prefix[pPoint-1];//上一个在s匹配的字符串,也能成为下一个匹配字符串的一部分
}
}
}
}
void kmpPrefixFunction(char *p,int length,int *prefix)
{
prefix[0]=0;
int k = 0;//前缀的长度
for(int i=1; i<length; i++)
{
while(k>0&&p[k]!=p[i])
{
k=prefix[k-1];
}
if(p[k]==p[i])//说明p[0...k-1]共k个都匹配了
{
k=k+1;
}
prefix[i]=k;
}
}
//匹配函数的朴素算法,用于比较
void normal_match(char * s,int sLength,char * p,int pLength){
int k;
for(int i=0;i<sLength-pLength+1;i++){
for(k=0;k<pLength;k++){
if(s[i+k]!=p[k]){
break;
}
}
if(k==pLength){
printf("找到:%d \n",i);
}
}
}
int main()
{
char *s = "ababacababababababbaabbababaabaababacabababababbcababbabababcababba";
char *p = "ababacab";
int pLength = strlen(p);
int *prefix = (int *)malloc(pLength*sizeof(int));
kmpPrefixFunction(p,pLength,prefix);
printf("字符串的最长前缀长度分别是:");
for(int i=0; i<pLength; i++)
{
printf("%d\t",prefix[i]);
}
printf("\n使用KMP匹配\n");
kmpMatch(s,strlen(s),p,pLength,prefix);
printf("使用朴素算法:\n");
normal_match(s,strlen(s),p,pLength);
return 0;
}
时间复杂度证明:
计算前缀的时间复杂度O(m) m为匹配串的长度
分析:首先看外部for循环:可以知道该循环最多执行m-1次,而比较难分析的是while循环中执行的次数:现在来说明while循环中代码在m-1次循环中总执行次数最大为m-1次:
1、k的初始值为0,且k只有在k=k+1时才能增长,且最多增长m-1次(for循环次数确定)
2、while循环中的代码每执行一次,k都会减小,并且保证k>=0
由以上两点说明:while中的代码最多执行m-1次,所以计算前缀的时间复杂度是O(m)
匹配算法kmpMatch的时间复杂度也为O(n) (n为待匹配字符串长度)
证明方法和最长字符串前缀证明类似。














 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









