




 本文围绕Redis展开,介绍了持久化机制,包括RDB、AOF及混合持久化;阐述主从架构原理与复制风暴应对方法;讲解Java连接Redis、Lua脚本应用;还介绍了Redis哨兵高可用集群和Cluster集群模式的搭建、选举原理、网络问题处理及集群运维等信息技术相关内容。
本文围绕Redis展开,介绍了持久化机制,包括RDB、AOF及混合持久化;阐述主从架构原理与复制风暴应对方法;讲解Java连接Redis、Lua脚本应用;还介绍了Redis哨兵高可用集群和Cluster集群模式的搭建、选举原理、网络问题处理及集群运维等信息技术相关内容。
持久化
- rdb 快照持久化,生成dump.rdb二进制文件
- 配置save 60 1000 // 60s内至少有1000个键被改动
- 支持save & bgsave(默认) 同步与异步模式
- 可手动执行save/bgsave命令触发持久化
- bgsave为非阻塞主线程,写时复制机制(copy-on-write,COW),创建副本时同步更新副本
- 恢复速度相比较快
- 默认开启rdb
扩展学习写时复制机制
- aof
- apend only file
- 配置 apendonly yes,生成apendonly.aof
- 将命令写到aof文件
- 支持always(每条都写,慢但安全) everysec(每秒,相对安全,推荐) no(交给操作系统,快但不安全) 三种选项
- get等获取数据命令不会写入
- 恢复就是通过将命令重新执行
- 运行恢复速度相比较慢,丢数据可能性较小
- AOF支持定期重写机制,提升恢复性能,将命令集进行优化,去掉垃圾命令,比如多次执行incr radcount,只会记录最终结果
- aof重写实则就是以当前内存的数据生成对应set命令
- 比如执行
set qinchen 888,则aof会记录如下内容
// 以下是一种叫resp协议格式数据,*3代表命令参数个数 $3表示命令有几个字符
*3
$3
set
$7
qinchen
$3
888
// 注意,如果是带过期时间set命令,则记录的不是原始命令
set qinchen 888 ex 1000
*3
$3
set
$7
qinchen
$3
888
$9
PEXPIREAT
$7
qinchen
$13
1604249786301
- 可两种可同时开启,恢复时默认选中aof,恢复数据更安全
- redis4.0,支持开启混合持久化机制
- 触发一次重写时aof将变成二进制内容
- 后续再执行set命令时依旧以命令方式写入aof
- 其本质是rdb + aof 机制的组合
- 最终生成的是appendonly.aof文件(内容结构就是RDB格式+AOF格式的组合)
- 数据恢复:只需将rdb/aof文件放在对应目录下,重启后自动恢复
- 并可考虑写crontab定时脚本,将rdb/aof文件备份到其他目录
主从架构
-
一主两从模式,配置简单,主节点负责写
-
replicaof master ip port
-
原理
- 从节点启动,给master发送psync命令,同步数据
- 主节点执行bgsave,生成rdb文件
- master新生成数据放入缓存中
- 从节点收到后清空原有数据,加载新的rdb数据
- master将将缓存中的命令再发给slave
- slave再将缓存命令执行
- 后续就一直由master将写命令同步给slave即可
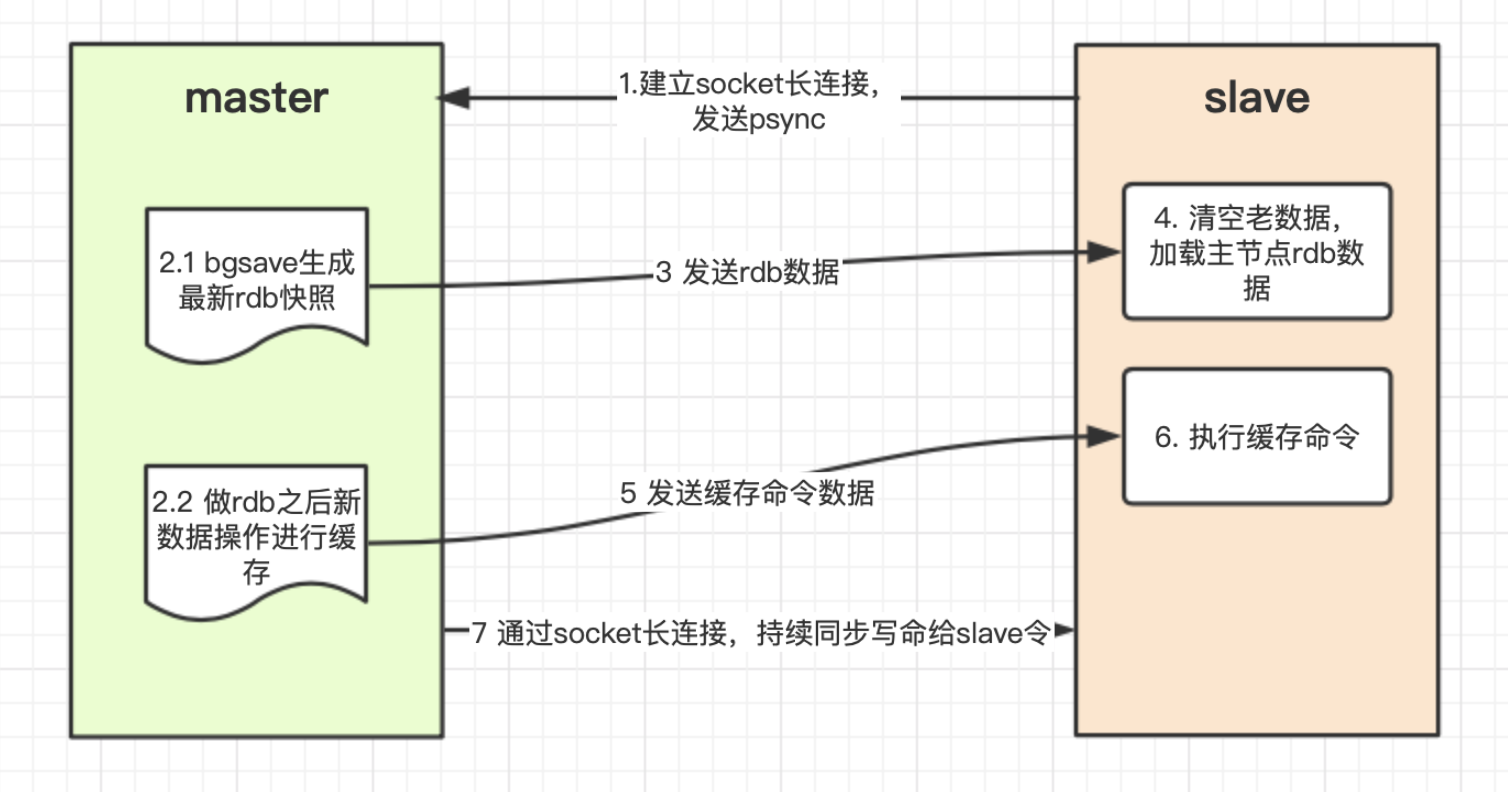
-
过程中slave挂了后,再恢复时,通过偏移量从master缓冲区同步数据(类似断点续传)
-
但由于缓冲区大小有限制,若slave挂的时间较长,则slave重启后,偏移量已不在master缓冲中,则将全量恢复master数据
主从复制风暴
- 从节点较多时,将对主节点造成较大压力
- 可将slave分层,部分slave和slave之间做同步
Java连接Redis
- Jedis,配置连接池,连接地址
- 通过jedisPool获取jedis客户端API,操作数据即可
- 可通过aop,实现Redis的读写分离,玩玩即可
- 通过Pipline管道,批量执行操作,可提升redis命令执行性能
- 注意管道操作无法保证数据一致性,因为Redis没有事务,不能保证操作的原子性
Lua脚本
- 想实现类似数据库事务机制,需借助Lua脚本
- Redis自带事务机制很鸡肋,几乎没有人用
- 2.6版本开始,内置lua解释器,eval "脚本内容",可对lua脚本进行求值
- 分布式锁技术就应用到了lua脚本技术
- 报错数据可回滚
- 脚本中的多条命令,Redis底层其实就是当做一条命令执行的,可保证操作的原子性
- 缺点:脚本较长可能导致其他命令阻塞,导致严重影响性能
- 所以注意:不能出现死循环、较耗时等操作
Redis哨兵高可用集群
- sentinel是特殊的Redis服务,不提供数据的读写,主要监控redis实例节点
- 推荐3个server + 3个sentinel 节点
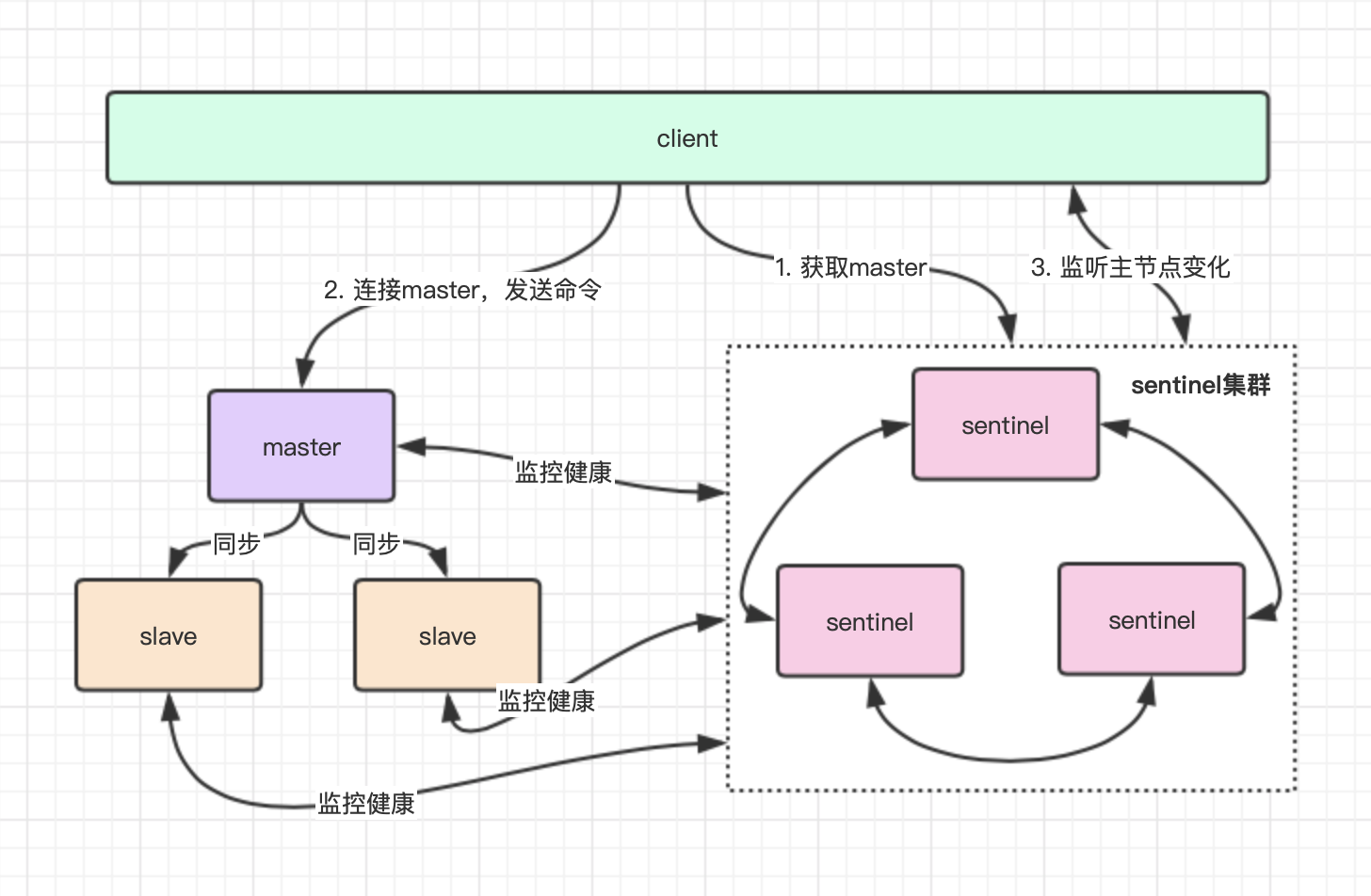
- client直接连接sentinel,由sentinel告知客户端Master节点信息
- 后续客户端就直接与redis主节点建立连接,不会通过sentinel代理访问
- 哨兵监听主节点状态,半数以上哨兵发现主节点挂了,则重新选举新的master,并第一时间通知client
redis的client一般都实现了订阅sentinel发布的节点变动消息,所以client才能收到master变动情况,具体内部选举原理与集群模式类似,请看后面集群选举部分介绍。
- 搭建好后,使用info命令可查看集群运行信息,且哨兵信息会自动被写入sentinel-xx.conf配置文件中
- 哨兵集群挂了,整个集群瘫痪,不可用
- 验证高可用效果
// 1. 可以循环向redis中写值
// 2. 停掉主节点
// 3. 客户端发生异常
// 4. 间隔一段时间后自动恢复正常,命令执行成功
// 5. 查看sentinel-xx.conf 文件可以看到最后一条master已是最新选举的,多次选举都会被记录
// 6. 使用info命令也可查看其自动切换后的信息
// 7. 重启挂掉的master,自动变成从节点,然后从最新主节点同步最新数据
- 注意:集群中的从节点不支持读,读写都是走的主节点,从节点仅仅是起到当master挂了后顶上去的作用
- 总结:扩展性不佳,无法支撑更高并发,且内存设置不宜过大,否则容易导致持久化文件过大,影响数据恢复及主从同步效率
Springboot中,StringRedisTemplate与RedisTemplate区别在于其序列化机制不同,前者是原生内容设置到Redis,后者默认则是利用JDK序列化策略,保存的key & value都是被序列化后的内容。
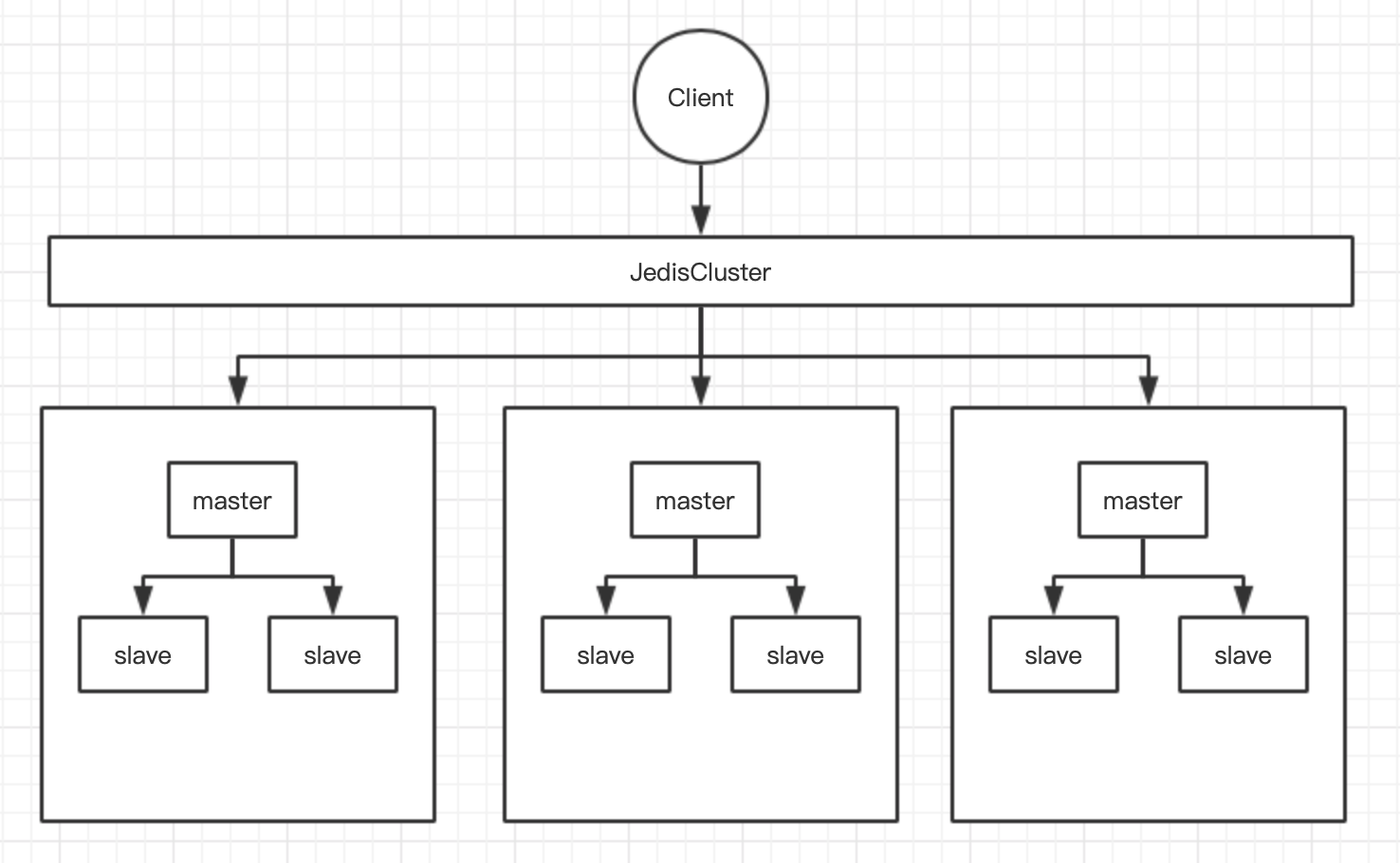
Cluster集群模式(3.0+)
- 集群由多个小的主从集群组合而成
- 客户端使用JedisCluster访问集群
- 数据分片存放在不同小集群中
- 通过对key进行hash定位算法(CRC16算法),放入不同小集群
HASH_SLOT = CRC16(key) mod 16384
跳转重定位机制:客户端与服务端发送槽位信息不一致时,向错误节点发出了指令,将得到一个重定向结果,指向正确的操作目标节点信息,并同步纠正客户端本地信息。
- 思考:此时,部分功能还是可能出现访问瞬断问题
- 小集群可水平扩展,官方称:支持上W数量,建议在1000以内,超出后性能会出现大幅下降
- 小集群推荐至少3个以上(也不一定要基数,只是推荐基数,为什么请思考?)
3个节点以上是为了能正常选举,4个节点与3个其实可用性一样,4个节点仍然只能容忍挂一个节点
- 搭建集群:5.0版本+,可用一条redis-cli命令完成,早期版本需要使用ruby脚本实现
- 16384个槽位会均匀分配到多个小集群组
- 查看:执行 cluster info 命令
cluster info // 查看集群基本信息
cluster nodes // 查看节点信息

- 集群搭建好了后,若服务都停掉了,再次重启,不要执行创建集群的命令,只需将集群中的各个节点启动,即可再次自动组合成集群
- 测试集群效果
set key value // 会自动计算key的槽位,然后自动给对应的master节点保存数据
get key // 其他master节点上get不到数据
- 集群的选举,相比哨兵模式要快
- 原理:可查看JedisCluster.java源码
// 核心就是对key进行hash,调用getCRC16(),然后对16384取模
// 集群的信息在客户端启动时,就缓存到了本地
// 若集群信息有变化,客户端执行命令时,将返回一个重定向信息给到客户端
// 客户端根据重定向信息,向重定向服务器发起命令执行,同时更新本地缓存槽位表
// 对客户端实现原理感兴趣,自行深入学习
-
Redis集群内部通过gossip协议,实现集群内部元信息变化的更新,C语言实现,可作为扩展了解下
- 常见维护集群元数据方式有两种:集中式与gossip
- 集中式:时效性好,但存储压力集中,zk就属于此模式
- gossip协议: 包括多种消息,有ping pong meet fail...
- gossip感兴趣可拓展学习,个人认为其实很类似广播,或区块链中的传播数据机制
-
注意集群内部通信端口是以server服务端口+10000,不要问为什么,代码写死的
-
网络抖动处理:通过参数
cluster-node-timeout进行配置合适的超时时间 -
集群脑裂问题如何处理?
- 由于网络原因,可能出现多主节点情况
- 网络再次恢复时,两个主节点其中一个会变为从节点
- 老主节点数据将从最新主节点同步最新数据
- 故此时可能出现数据丢失
- 可配置
min-slaves-to-write=1,意为至少需存在1个slave时才让写数据 - 一定程度牺牲了可用性:因为两个slave挂了后,master将不可用
- 一般情况下,不建议这么干,因为缓存丢数据可以一定程度容忍,可用性比数据一致性更重要
- 而且也不是能100%避免数据丢失
-
集群选举原理:
- slave发现自己master fail时
- 会将信息发给另外两个master
- master回给slave一个ack
- slave收到超过集群半数的ack,将会把自己改为master
- slave通过广播ping消息通知其他所有节点最新的集群元信息
-
若存在两个salve,出现票数一样,此时将重新选举
-
为防止多次选举票数一致,底层通过了延迟计算公式规避,延迟计算中带有一个随机数及slave_rank
DELAY = 500ms + random(0~500ms) + SLAVE_RANK * 1000ms
- slave_rank表示从master复制数据总量的rank,rank越小,代表数据越新,0代表最新,1代表其次...,所以理论上持有最新数据的slave会先发起选举
redis是AP架构设计,保证的是可用性,牺牲的是一致性,zk是CP
- 默认某一个小集群都挂了,整个集群不可用,但可通过配置修改
- 集群对批量操作命令的支持
- mset qinchen1 1 qingchen2 2 可能报错,执行失败
- 因为要保证操作的原子性,二两个key对应的槽位可能不一致
- 可通过 mset {user}:1:name qinchen {user}:1:sex 1
- 此时计算hash时,只会针对大括号内容这个前缀进行
集群运维
- 如何对集群进行扩容?
// 新的主节点加入
redis-cli -a xxx --cluster add-node new-node-IP node-IP
// 分槽位,数据也会同步迁移
redis-cli -a xxx --cluster reshard IP
// 新的从节点加入
cluster replicate node-id
- 推荐扩展学习,Redis高并发分布式锁

















 5457
5457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









