









正则表达式基础
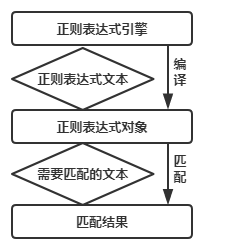
正则表达式用于处理字符串,拥有自己独立的语法以及一个独立的处理引擎。
不同提供正则表达式的语言里正则表达式的语法都式一样。
. 和 * +
. 匹配任意一个字符
*匹配0或多次前面出现的字符
.* 表示0或无限次的"."
+匹配的字符至少要出现一次
^ 和$
^表示以某字符开头的匹配
$ 表示以某字符结尾的匹配
^a.* 表示匹配任何以a开头的字符串
.*k$表示匹配任何以k结尾的字符串
?
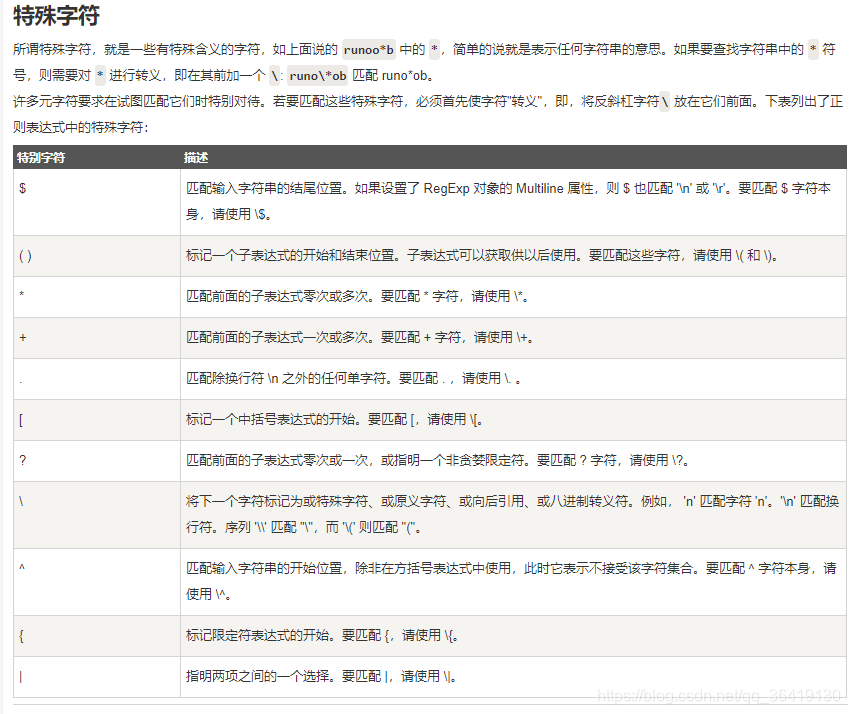

python爬虫中正则的使用
比如用一爬虫爬取一个网页中的全部图片,用正则表达式匹配图片链接
#coding=utf-8
import urllib.request
import re
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
def getImg(html):
html = html.decode(‘utf-8’)
reg = r’src="(.+?.jpg)" pic_ext’
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,’%s.jpg’ % x)
x+=1
print(‘Getting the %s picture’ % x)
html = getHtml(“https://tieba.baidu.com/p/2460150866?pn=3”)
getImg(html)
网络爬虫
所谓网络爬虫就是,抓取特定网站网页的html数据。
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都F可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
所谓网络爬虫就是,抓取特定网站网页的HTML数据。抓取网页的一般方法是,定义一个入口页面,然后一般一个页面会有其他页面的URL,于是从当前页面获取到这些URL加入到爬虫的抓取队列中,然后进入到新页面后再递归的进行上述的操作,其实说来就跟深度遍历或广度遍历一样。
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。

Scrapy整体架构
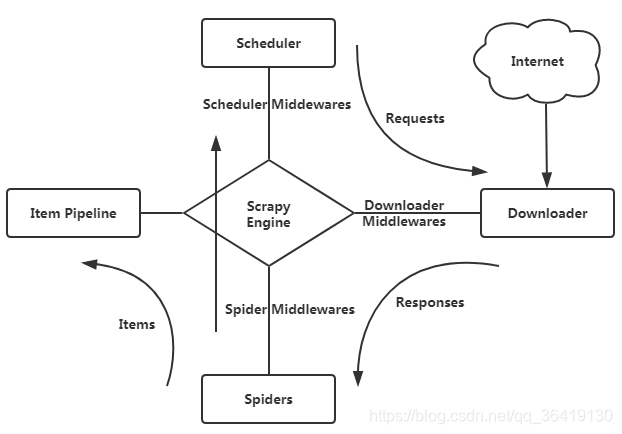
1.引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
2.调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
3.下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
4.蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站
5.项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6.下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7.蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
8.调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
爬取流程:
首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,抓取到的东西会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
scrapy在windows下安装及遇到的问题
重新安装了pycharm,下载的最新版本,python环境也重新安装成了python3.7,于是在安装scrapy包时就遇到了很多问题,比如scrapy包无法正常安装,无法找到命令等等,现在我将说出在windows下使用它的正确方法
安装python
我这里直接安装的是python3.7的版本,然后安装的时候忘记了add to path,结果就是命令行里无法直接使用python,然后有了下面这篇文章
Windows下Python的 Path问题解决
如果你在安装python,一定要记得把add to path勾上
安装scrapy
首先你需要找到python的安装目录,如图

然后在cmd中,切换到
C:\Users\hp\AppData\Local\Programs\Python\Python37-32\Scripts
目录下,然后
pip install scrapy
接着就可以新建爬虫项目了。
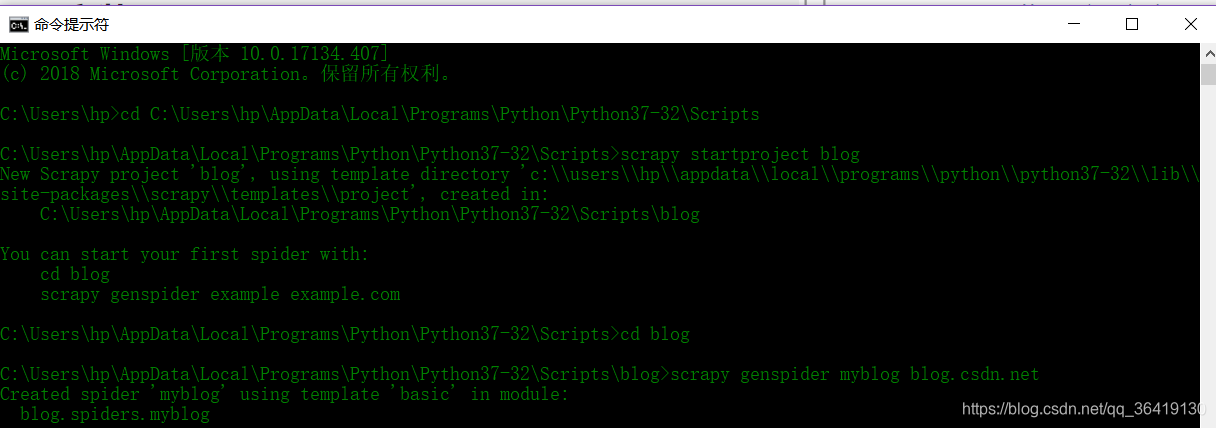
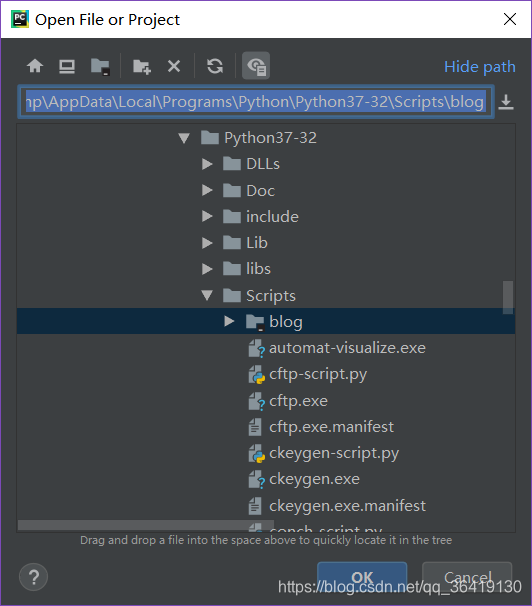
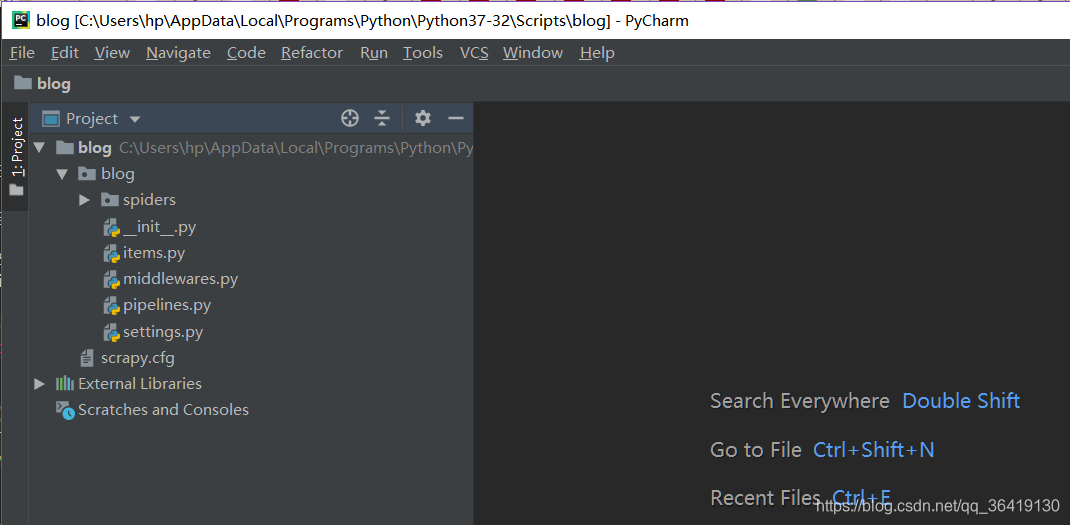
项目就建立完成了。接着就可以写自己的爬虫了。
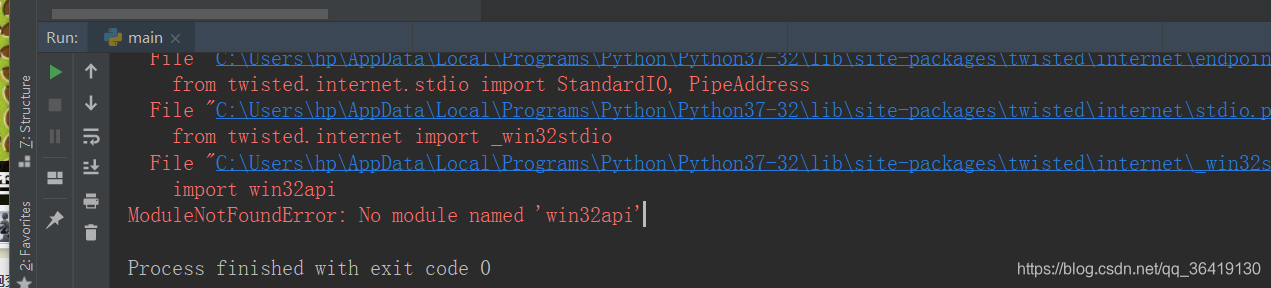
No module named 'win32api’问题解决















 3306
3306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









