










论文解读:Denoising Distant Supervision for Relation Extraction via Instance-Level Adversarial Training
本文是一篇以生成对抗网络为出发点的远程监督关系抽取文章,其使用GAN来完成噪声数据的过滤,其相比普通的multi-instance能够更有效的过滤出噪声,避免multi-instance的at-least-once过强的假设。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | CNN+AN/RNN+AN |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 远程监督关系抽取 |
| 4 | 核心内容 | Relation Extraction,GAN |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://arxiv.org/pdf/1805.10959.pdf |
二、全文摘要翻译
现有的神经关系抽取模型都依赖于远程监督,其遭受错误标签的问题。本文,我们提出以示例为主的一个新的对抗训练机制用于关系抽取和降噪。相比其他一些降噪模型,我们提出的方法能够更好的从噪声中判别出富有信息的示例。我们的方法也有效的灵活的应用各种不同的关系抽取模型。在大尺度基准数据集进行实验表明,我们的降噪方法相比现有的最优模型能够有效的过滤掉噪声。
三、相关工作与介绍
关系抽取的任务是给定目标的两个实体,根据对应的句子表达来提取出两者之间的语义关系。现如今的关系抽取绝大多数视为一种分类任务。传统的关系抽取是基于监督学习,但其需要大量的人工标注语料,费时费力。远程监督学习被提出,其根据现有的知识库与现有的语料进行对齐,其认为所有句子中如果都出现目标实体对,其都能表达知识库中所标注的关系,这显然会造成许多错误标签。多示例学习被提出,其结合句子级别的注意力加权提取每个包中各个句子的语义,权重高的则暗示句子不是噪声,权重低的则句子为噪声,该方法效果得以提升,但仍然建立在一个较强的假设——每个包都至少包含一个正样本,对于有一些实体对包含的句子非常少,因此这种方法也有弊端。为了解决这个问题,作者受到生成对抗网络训练的启发,提出一个在句子级别上进行对抗训练的方法。这种对抗训练并非是添加对抗扰动,而是以GAN为架构的对抗学习。
首先将原始的数据集划分为两个子集,非常小的confident集合保存positive(也就是没有噪声的)句子、unconfident保存未知的句子(可能包含positive、negative)。模型主要包括两个部分:
(1)判别器(Discriminator):判别器用来判断给定的句子是true positive还是negative。即需要正确的划分给定的句子是来自confident还是unconfident。如果来自confident,则给与高分,否则给与低分;
(2)采样器(Sampler):采样器也就相当于生成器,其目标是从unconfident中采样出一些认为是confusing的句子,企图骗过Discriminator给高分。
整个对抗训练的过程就是:Sampler根据一种采样机制,在unconfident集合中选择confusing score最高的句子,Discriminator则从confident中采样真实的句子,然后分别对两部分数据进行打分,其尽可能的为来自confident的句子打高分,为Sampler采样的句子低分;Sampler则企图提高采样的能力来骗过Discriminator,让Discriminator给高分。仔细思考可知,Sampler的目标就是从unconfident中选出positive的句子,因为当模型训练到一定程度时,Discriminator已经无法区分哪些句子究竟来自哪个集合,同时认为Sampler采样出来的句子是positive,因此此时,Sampler采样的句子就是positive的。
每10论对抗训练,作者便使用Sampler来从unconfident中选择positive的句子更新到confident中,而此时Discriminator可以作为一个分类器。下面将详细描述这个模型:
四、提出的方法
模型的框架如图所示。首先使用预训练的分类器,将数据集划分confident集合
I
c
I_{c}
Ic和unconfident集合
I
u
I_{u}
Iu。其中confident是少量的,但全部包含真实数据。
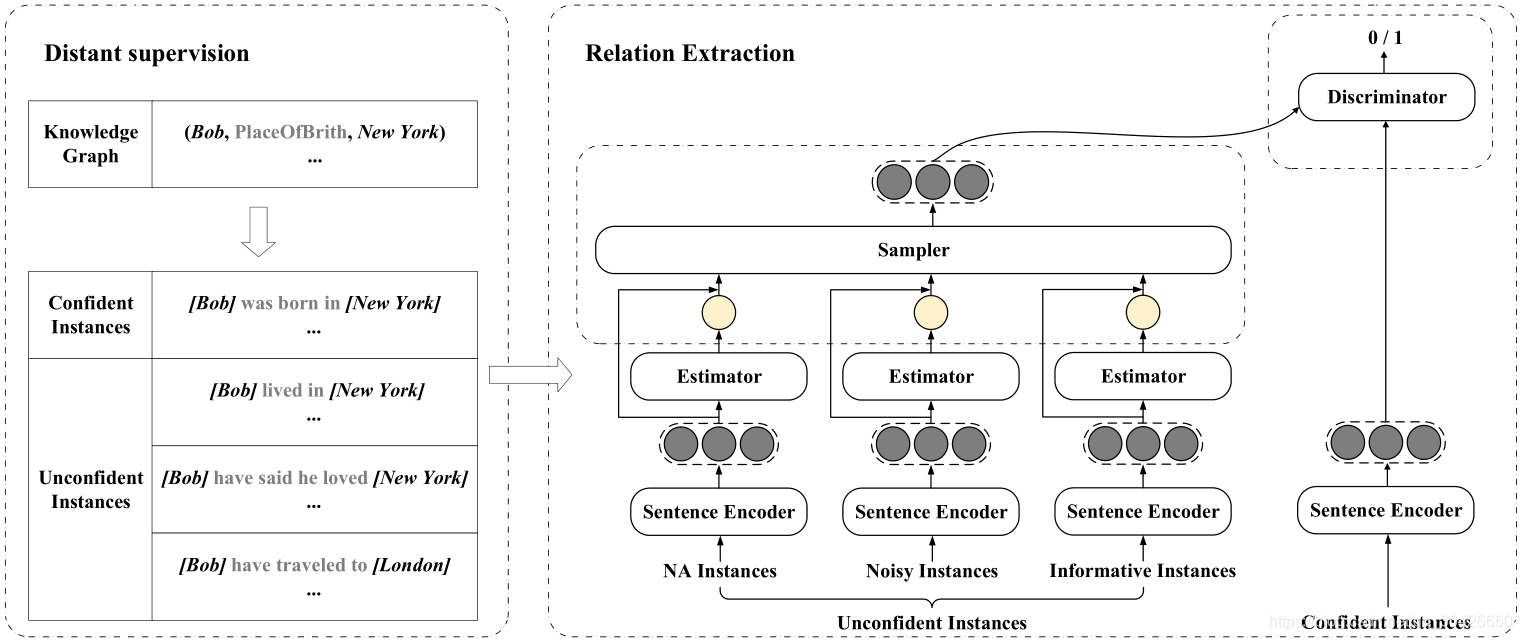
4.1 Sentence Encoder
对于给定一个句子,首先使用SkipGram模型表示为词向量,同时引入位置表示,形成Input Embedding,记为
S
=
{
[
w
1
,
p
1
]
,
[
w
2
,
p
2
]
,
.
.
.
[
w
n
,
p
n
]
}
\mathbf{S}=\{[w_1,p_1],[w_2,p_2],...[w_n,p_n]\}
S={[w1,p1],[w2,p2],...[wn,pn]}。
作者分别使用现有的一些句子编码器,例如CNN、PCNN、RNN、BiGRU等,相关模型可参阅文章基于深度学习的命名实体识别与关系抽取和基于监督学习和远程监督的神经关系抽取。最终编码器生成的句子向量记为
y
\mathbf{y}
y 。
4.2 Sampler
采样器的目标是尽可能选择一些confusing的句子来骗过判别器给它高分。因此首先作者给出了confusing score:
C ( S ) = W ⋅ y C(S)=\mathbf{W·y} C(S)=W⋅y
其中 W \mathbf{W} W 是权重参数,类似于超空间的超平面,其与同空间的句子向量点乘后可得到对应的得分。作者基于此使用一层softmax归一化,即得到集合中每个句子的confusing概率分布 P u ( s ) = s o f t m a x ( C ( s ) ) P_u(s)=softmax(C(s)) Pu(s)=softmax(C(s))。
设判别器的打分函数为 D ( s , r s ) D(s,r_s) D(s,rs) (4.3细讲),则一个优秀的Sampler目标即是其选出的样本能够得到较高的 D ( S , r s ) D(S,r_s) D(S,rs)。根据GAN原理,即最小化Sampler的损失函数:
L s = − ∑ s ∈ I u P u ( s ) l o g ( D ( s , r s ) ) L_s=-\sum_{s\in I_u}P_u(s)log(D(s,r_s)) Ls=−s∈Iu∑Pu(s)log(D(s,rs))
这里需要注意这个损失函数中,概率分布 P u ( s ) P_u(s) Pu(s)表示采样器认为的分布,因此从实验角度来看,Sampler并非是从集合中挑选句子,而是针对每个句子在这个概率分布上的期望,Sampler即是希望这个期望值越大越好。
4.3 Discriminator
作者定义了Discriminator的打分函数 D ( s , r s ) = σ ( r s ⋅ y ) D(s,r_s)=\sigma(\mathbf{r}_s·\mathbf{y}) D(s,rs)=σ(rs⋅y),其中 σ \sigma σ是sigmod函数。该函数表达的意思即给定当前的句子(可能是confident中的,也可能是Sampler采样的)来判断其是否能够表达对应的关系 r s r_s rs,其中点乘通常被认为是一种相似度计算,sigmod函数则将这个得分映射到一个0-1之间。作者还考虑到了关于NA的句子,因为NA的句子有可能会被预测为其他关系,因此为了避免Discriminator判断错误,作者特定设计了NA标签的得分函数: D ( s , N A ) = 1 ∣ R ∣ − 1 ∑ r ∈ R , r ≠ N A D ( s , r ) D(s,NA)=\frac{1}{|R|-1}\sum_{r\in R,r\neq NA}D(s,r) D(s,NA)=∣R∣−11∑r∈R,r=NAD(s,r),其表达的意思是分别计算这个句子与除NA以外其他所有关系的得分并取平均,为什么这么计算,作者没有给出解释,但直观理解可知,如果当前句子是NA,则它一定与其他所有关系对应的得分都很低,因此是一种类似排除法,遍历所有关系,只有每个关系都与之相似度很低时,则被认为是无关。
再来看看如何训练Discriminator,作者定义了损失函数:
L D = − ∑ s ∈ I c 1 ∣ I c ∣ l o g ( D ( s , r s ) ) − ∑ s ∈ I u P u ( s ) l o g ( 1 − D ( s , r s ) ) L_D=-\sum_{s\in I_c}\frac{1}{|I_c|}log(D(s,r_s)) - \sum_{s\in I_u}P_u(s)log(1-D(s,r_s)) LD=−s∈Ic∑∣Ic∣1log(D(s,rs))−s∈Iu∑Pu(s)log(1−D(s,rs))
一个训练优秀的Discriminator的目标是能够很好的区分给定的句子是来自哪个集合,其尽可能给来自confident的句子高分,即最小化前一项;给来自unconfident的句子低分,即最小化后一项。我们可以发现,前一项中 P d ( s ) = 1 ∣ I c ∣ P_d(s)=\frac{1}{|I_c|} Pd(s)=∣Ic∣1也是一个概率分布,因为confident中每一个句子都是真实的,因此其confusing score应该是完全一样,因此对应的概率分布也是相等的。
将Sampler与Discriminator结合起来,便是一个min max任务:
min P u max D − ∑ s ∈ I c P d ( s ) l o g ( D ( s , r s ) ) − ∑ s ∈ I u P u ( s ) l o g ( 1 − D ( s , r s ) ) \min_{P_u} \max_{D} -\sum_{s\in I_c}P_d(s)log(D(s,r_s)) - \sum_{s\in I_u}P_u(s)log(1-D(s,r_s)) PuminDmax−s∈Ic∑Pd(s)log(D(s,rs))−s∈Iu∑Pu(s)log(1−D(s,rs))
对GAN比较了解的可以知道,其即是最小化 P u P_u Pu和 P d P_d Pd之间的JS散度。
在具体的训练时,因为unconfident集合很大(几十万级别),因此作者每次从中随机采样一批,并分别计算 Q u ( s ) = s o f t m a x ( C ( s ) α ) Q_u(s)=softmax(C(s)^{\alpha}) Qu(s)=softmax(C(s)α),其中 α \alpha α是一个超参数,用来对概率分布进行微调,因为随机采样的子集合与原先的集合概率分布会有很大差异,因此使用这个超参数作为一种调和。 Q u ( s ) Q_u(s) Qu(s)与 P u ( s ) P_u(s) Pu(s)都是概率分布,后续计算则使用 Q u ( s ) Q_u(s) Qu(s)。
4.4 Filter & Classifier
究竟如何降噪呢?作者指定每10论迭代训练后,Sampler则充当Filter。因为其能够比较准确的挑选一些confusing句子使得Discriminator认为是positive,因此将这些confusing score较高的且 D ( s , r s ) D(s,r_s) D(s,rs)较高的句子转移到confident中。作者并没有给出较高究竟是多少。Discriminator则充当分类器,对给定的句子对每个类分别计算相似度,并将得分最高的作为预测的关系。这里面需要注意的是Discriminator应该不计算NA,因为NA也被当做是noisy,所以NA关系的句子一定不会被Sampler采样,也不会出现在confident集合中。
作者并没有给出在测试阶段模型如何运行,在此我做一个推论。给定测试集中的句子,使用训练好的Sampler为其计算confusing score,并得到概率分布,其次分别通过Discriminator打分,因为目标是预测关系,所以Discriminator会分别对包括NA在内的每个关系计算得分,并取最高得分的作为预测的关系。
五、实验
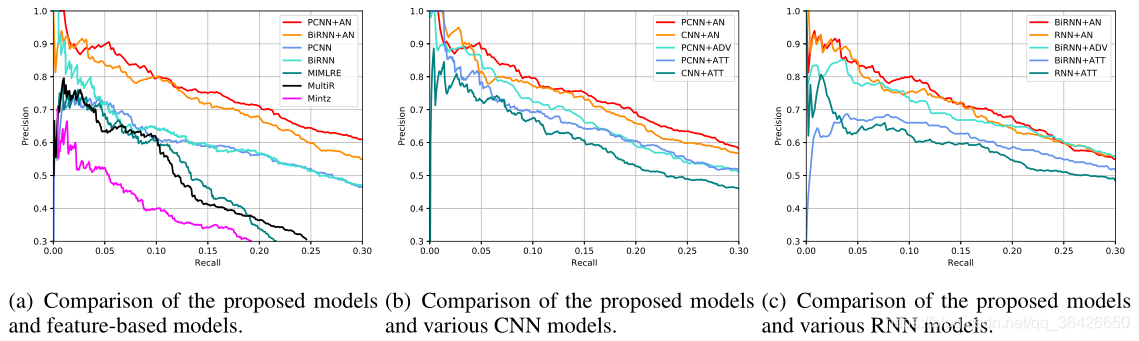
作者选择NYT数据集进行实验,可知这个数据集富含大量的噪声,且非均衡,能够比较有效的验证模型能力。
作者分别与现有的baseline进行对比(左图)PCNN+AN是本文模型,其次对Sentence Encoder进行对比,全部使用CNN时(中图)和RNN时(右图)PR曲线对比。
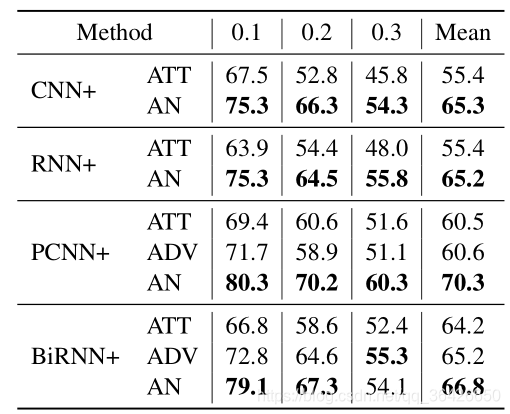
在训练过程中,相同召回率下的精度如下所示:
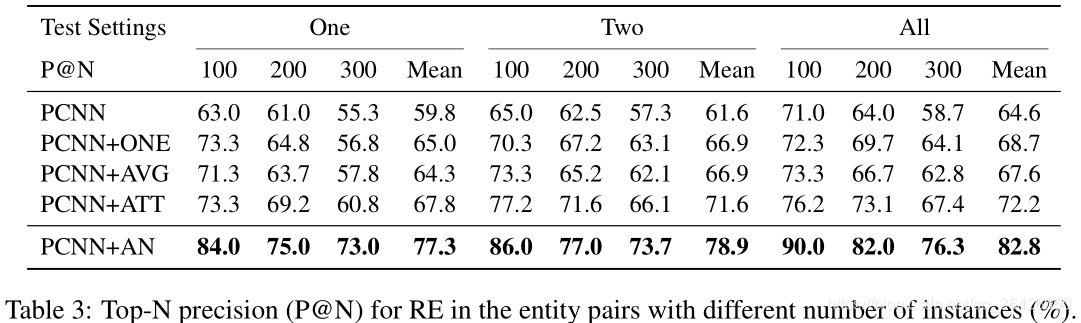
作者也对TOP@N进行了对比:
作者在case study中,给出了样例,可知,模型可以很好的过滤出噪声。

六、总结
这篇文章在思路上很新颖,打破了以multi-instance的套路,试图在训练之前就将噪声过滤掉,提升样本的纯度。但其有一些潜在未知的问题:
(1)作者使用预训练的分类器先对数据集划分,这个预训练的分类器是什么?怎么能够保证初始化的confident完全是纯的?
(2)作者在为NA标签设计打分函数存在一个问题。例如在训练阶段,unconfident中存有NA标签的句子,判别器应该目标是给低分,sampler也应该尽可能不把它作为confusing数据去欺骗,因为NA标签的数据本身作为一个噪声,不可能会是positive。而打分函数是对其他关系的得分均值,那一定落在最大值最小值之间,如果在预测标签时,如何预测出NA的句子呢?同时我们还知道,NA标签的句子占整个数据集的97%,将其与所有关系分别计算相似度会带消耗巨大的计算资源和时间。
(3)作者认为confusing score对应的概率分布应该尽可能与confident的均匀分布JS距离尽可能的小,但事实上是不可能的;
(4)confusing score只有一个
W
\mathbf{W}
W来学习,打分函数也过于简单,虽然sentence encoder可以提升模型的复杂度,但仍然会存在collapse mode问题,感觉训练后的结果要么是采样器训练崩了,要么是判别器判别能力太高,使得采样器无论如何学习都学不好,这也是GAN自身存在的问题。一种改进方法就是适当提升采样器和判别器的模型参数,同时可以采用WGAN替代GAN。
(5)作者没有详细给出测试阶段是如何实现的,也并没有开源代码,这一部分很难去复现。
(6)作者在conclusion中还提到他们的方法可以解决long-tail问题,但是文章中并没有提出解决这个问题的方案,因此本人觉得可能仅仅是凑巧,或者在句子很少的实体对中表现效果还可以,还有需验证。
作者最后给出两个研究目标,一个是引入额外知识库对模型进行增强,这一个想法也是现如今在NRE中很常用的策略;另一个作者将其扩展到entity-pair级别进行对抗,说白了就是multi-instance + 对抗。















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











