







-
一、引入
目标检测定位出一张图片中某个类别都在哪里,
模型在预测是会出现很多候选框,同时每个框都会有很多自己的一个置信度得分score,
那么如何选出最后的那几个框呢?参见下图!
-
二、概念:
NMS: non maximum suppression,中文解释为“非极大值抑制”,听得非常不好理解,以我的认识可以理解在一定范围内选择最好的框,重叠过大的被舍弃。
但是它的思路还是很好简单的,借用其他博主的图片方便解释。
-
三、举例说明
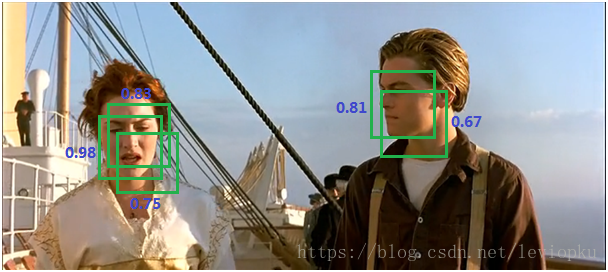
图上是检测人脸的一个项目,通过模型训练,得到了一些预测框,每个框都会有它的分数score 。
我们看到这个女孩的脸的部位就有三个框,男孩的脸部上有两个框。那接下来就会介绍一下NMS怎么用。
首选对所有框进行排序,则有0.98、0.83、0.81、0.75、0.67.一共5个框。
取出score值最大的框0.98,与剩下的4个框【0.83、0.81、0.75、0.67.】计算一个重叠面积,
也就是IOU ,面积的交集/面积的并集,当IOU值大于设定的阈值thres则被比较的框将会被丢掉。(假如设定的阈值为0.5)
因此第一轮下来,与0.98框重叠部分过大的0.83和0.75就被舍弃了,剩下2个框【0.81和0.67】。
第二次取出【0.81、0.67】最大值的框0.81,与剩下的框【0.67】计算IOU值,当重叠部分占面积(理解为IOU)大于阈值0.5,0.67的框被丢掉了。
经过两轮极大值抑制 最终留下了0.98和0.81的框。就是我们最后的输出框。如下图。
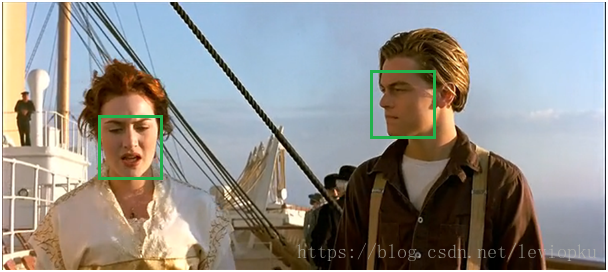
当为多个类别目标检测时,每次计算都是同类别的一起进行比较,得出每个类别的最好的那几个框。
不知是否理解了呢?
欢迎一起探讨,v: ai_hellohello














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









