







目录
📝论文下载地址
👨🎓论文作者
📦模型讲解
[背景介绍]
下图是作者展示的针对行人检测使用多光谱数据的重要性。作者使用的是KAIST数据集,这是一个行人检测数据集,共4类行人,每张图片都有配准对齐的可见光数据和红外图像数据。如下图所示,左侧和中间的两对图中由于光照条件较差,在可将光图像中的行人不明显,而红外图像中的行人比较明显。最右侧的一对图像中,可见光相对与红外图像中的人是更明显的。图中的框是检测结果,绿色为检测成功的框,黄色标识未检测出的真实框。可以看出,不同的数据上网络的性能是有很大的影响,这也是为什么要做多光谱数据的目标检测的原因。

[论文解读]
作者深入分析了用于多光谱行人检测任务的Faster R-CNN,然后将其建模为卷积网络(ConvNet)融合问题,设计了四种卷积网络融合结构。
[Vanilla-ConvNet]
论文中相关工作部分提到许多适用于多光谱行人检测的ConvNet架构。作者受目标检测的启发,考虑从Faster R-CNN入手,在Caltech行人基准测试中验证其性能。
Faster R-CNN模型由区域生成网络(RPN)和Fast R-CNN检测网络组成。RPN是一个全卷积网络,与目标检测网络共同使用相同的目标特征。与R-CNN和Fast R-CNN相比,Faster R-CNN可以通过RPN产生高质量的候选框。 这与其他基于ConvNet的行人检测器不同。此外,Faster R-CNN使用兴趣区域池化层(RoI Pooling)将每个候选区域的特征图池化为固定大小,即7×7,从而可以处理任意大小的行人。
[实施细节]
作者利用了原始的Faster R-CNN模型,并将其改编为Vanilla ConvNet,删除了VGG-16的第四个最大池化层。较大的特征图有利于检测图像尺寸较小的行人。Faster R-CNN使用多尺度(×3)和多比例(×3)的anchors来预测区域生成的位置。考虑到行人的典型长宽比,作者放弃长宽比为0.5的anchors来加快RPN的训练和测试。
使用Caltech×10训练集进行微调。排除了遮挡,截断和小的(<50像素)行人目标,从而获得了大约7000个训练图像。检测的行人与真实框IoU大于0.5的视为正样本,否则作为负样本。根据Faster R-CNN的训练过程,通过预训练的VGG-16初始化网络,然后使用随机梯度下降(SGD)进行微调约6个epochs。学习率(LR)设置为0.001,并在4个周期后降低为0.0001。使用单个图像尺寸为600像素,不使用特征金字塔。
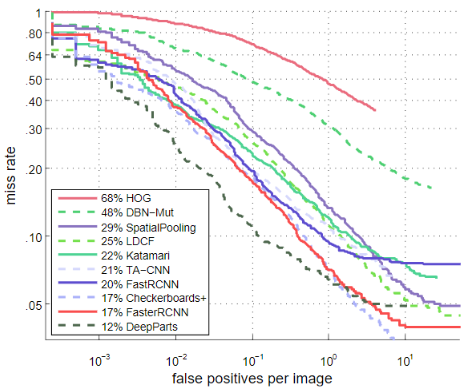
[结果对比]
指标:MR/Miss Rate丢失率,越小越好,也就是1-Recall,或者
M
R
=
F
P
T
P
+
F
P
MR=\frac{FP}{TP+FP}
MR=TP+FPFP。
作者将Vanilla ConvNet(Faster R-CNN)与Caltech上的其他方法进行了比较,包括HOG,DBN-Mut,SpatioPooling,LDCF,Katamari,TA-CNN,Fast R-CNN,Checkerboards+和DeepParts。对于Fast R-CNN,作者使用ACF行人检测器获得候选区域,然后将该候选区域用于训练和测试Fast R-CNN检测网络。为ACF检测器设置了一个低阈值(-50),以便产生足够的候选区域。作者使用IoU@0.5验证检测结果。在合理配置下,通过在
[
1
0
−
1
,
1
0
0
]
[10^{-1},10^0]
[10−1,100](MR,越低越好)范围内的对数平均丢失率来测量检测性能。如下图所示,Vanilla ConvNet击败了大多数的最新方法,实现了17%的MR,低于某些基于DNN的方法,例如DBN-Mut(48%),TA-CNN(21%)和Fast R-CNN(20%)。仅使用一个ConvNet,vanilla ConvNet的性能就接近由45个ConvNet组成的DeepParts(12%)。
[Multispectral-ConvNet]
作者的目的是RGB和红外图像在描绘行人物体时会相互提供辅助的视觉信息。如果一种图像检测失败,即误检或漏检,则另一种图像仍可以输出出正确的结果。作者回答以下问题:当涉及基于ConvNet的目标检测时,RGB图像和红外图像是否仍提供补充信息?通过将它们融合在一起,可以期望得到多大的改进?
[它们真的互补吗?]
为了研究RGB图像和红外图像之间的互补潜力,作者首先基于Vanilla ConvNet,即Faster R-CNN-C和Faster RCNN-T,训练了两个单独的仅使用RGB图像(Faster R-CNN-C)或红外图像(Faster RCNN-T)的行人检测网络。使用KAIST数据集用于神经网络的微调和测试。作者将检测到的BoundingBox与真实框的IoU大于0.5视为真阳性( T P TP TP),否则视为假阳性( F P FP FP)。同一真实框上的多次检测被视为 F P FP FP。在下表中,作者按全天,白天和夜间图像列举了Faster R-CNN-C和Faster R-CNN-T的真实框、 T P TP TP和 F P FP FP的数量。 T P ( C , T ) TP_{(C,T)} TP(C,T)表示两个检测器都检测到的行人。 T P ( C ) TP_{(C)} TP(C)和 T P ( T ) TP_{(T)} TP(T)代表由Faster R-CNN-C或Faster R-CNN-T单独检测到的结果,同样 F P ( C , T ) FP_{(C,T)} FP(C,T), F P ( C ) FP_{(C)} FP(C)和 F P ( T ) FP_{(T)} FP(T)用于虚警。

显然,Faster R-CNN-C和Faster R-CNN-T总共拥有924个
T
P
(
C
,
T
)
TP_{(C,T)}
TP(C,T),而Faster R-CNN-T则将被Faster R-CNN-C捕获的390名步行者视为背景。 在白天,Faster R-CNN-C(
720
+
36
=
1066
720+36=1066
720+36=1066)的
T
P
TP
TP值比Faster R-CNN-T(
720
+
176
=
896
720+176=896
720+176=896)更多,而夜间图像则相反(Faster R-CNN-C:248,Faster R-CNN-T:425)。作者的解释是,白天大多数行人都处于良好的照明条件下,除了一些拐角处和阴影的情况,红外图像易于受到阳光的影响。相反,红外图像可以更好地捕获夜间行人的视觉特征。此外,Faster R-CNN-C和Faster R-CNN-T的
F
P
(
C
,
T
)
FP_{(C,T)}
FP(C,T)相对较少(345),而它们总共获得
F
P
=
2672
FP=2672
FP=2672。
毫无疑问,RGB和红外图像提供了关于行人检测的补充信息。根据2252张测试图像,如果极端假设保留了来自Faster R-CNN-C或Faster R-CNN-T的所有真实检测,并且仅保留了共享的虚警,那么可以将检测率从47.9%(
(
924
+
390
)
2757
=
47.9
%
\frac{(924+390)}{2757}=47.9%
2757(924+390)=47.9%)提高到62.1%(
(
924
+
390
+
397
)
2757
=
62.1
%
\frac{(924+390+397)}{2757}=62.1%
2757(924+390+397)=62.1%),每个图片的虚警率从0.549(
(
345
+
1169
)
2757
=
0.549
\frac{(345+1169)}{2757}=0.549
2757(345+1169)=0.549)降低到0.125(
(
345
)
2757
=
0.125
\frac{(345)}{2757}=0.125
2757(345)=0.125)。
[卷积融合模型]

现在的问题是,如何才能实现一种很好的RGB-红外图像的多光谱行人检测模型。如上图所示,基于ConvNet的检测器由三个阶段组成:卷积层,全连接层和决策层。不同层的特征分别对应于语义和空间的各个级别。作者认为不同阶段的融合会导致不同的检测结果,因此,多光谱行人检测任务成为一个ConvNet融合问题,即哪种融合模型的结构可以获得最佳的检测协同作用。为此,作者对基于草Vanilla ConvNet设计的四种融合模型进行了全面的对比。基本上,它们是在不同层进行融合的两分支ConvNet模型,分别表示为早期融合,中期融合,晚期融合和置信度融合。它们中的三个实现了特征级融合,而最后一个采用决策级融合,如下图所示。

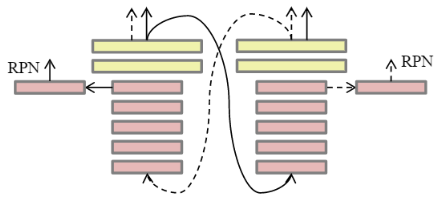
上图中第一行从左到右分别是早期融合,中期融合和后期融合,下一行是置信度融合。红色和黄色框代表卷积层和全连接层,蓝框表示concat层,绿色框表示用于减少尺寸的网中网(NIN)。
①早期融合
在第一个卷积层(C1)之后将从RGB和红外分支会获得的特征图通道叠加。然后,在特征级联后引入网中网(NIN),它实际上是一个1×1卷积层。NIN将级联的特征尺寸减小到128,从而使backbone中其他参数从预先训练的VGG-16中可以加载,NIN从RGB和红外分支输出局部特征的线性组合。由于C1捕获浅层的特征,例如角,线段等,因此早期融合模型是一种浅层特征融合。
②中期融合
还可以在卷积层实现融合。与早期融合不同,它将融合模块置于第四卷积层(C4)之后。NIN也用于连接层之后,其原因与前面讨论的相同。C4层中的特征比C1具有更多的语义,同时保留了一些细节,因此中期融合模型是一种深层特征融合。
③后期融合
通道相连最后一个全连接层(F7),在全连接层执行特征融合。后期融合执行深层特征融合,这里的RPN利用这两个分支的C5特征来预测候选框。
④置信度融合
置信度融合可视为两个ConvNet的级联。作者首先从RGB的ConvNet中获取检测信息,然后将其送到另一个ConvNet中,以基于红外图像获得检测置信度,反之亦然。实际上,这可以通过使用RoI池化层来实现。来自两个分支的检测置信度以相等的权重求和。
[结果分析]
[数据集]
KAIST多光谱行人数据集(KAIST)包含95328个对齐的RGB红外对,在1182个行人上具有103128个标记框。作者使用每2帧从训练视频中采样了图像,最终获得了7095个训练图像。KAIST的测试集包含2252张从测试视频中采样的图像,每30振采样一次,其中白天捕获了1455幅图像,夜间捕获了797幅图像。训练的VGG-16,除了新引入的图层外。例如,在早期融合和中期融合中,通过高斯分布初始化NIN的权重。四个融合模型中的并行分支不共享权重。同时对早期融合,中期融合和晚期融合中的两个分支进行了训练,而对置信度融合中的两个ConvNet分别进行了训练。所有模型均使用SGD进行了学习率为0.001的4个epochs和学习率为0.0001的2个epochs的微调。此外,非最大抑制(NMS)应用于置信度融合模型的检测,以避免RGB和红外图像出现重检测。
[检测评估]
具有单一模态的检测器获得的结果要低于融合模型。Faster R-CNN-C在白天的图像上获得了42.5%的MR,而在夜间图像上的性能却比ACF-C-T检测器差(64.4%vs61.2%)。另一方面,Faster R-CNN-T在白天的图像上会受到影响,尽管它的MR与夜间图像上的某些融合模型相似。因此,Faster R-CNN-C和Faster R-CNN-T都不适合全天候应用。与Faster R-CNN-C和Faster R-CNN-T相比,ConvNet融合模型产生明显更好的结果,从而将整体MR从48%降低到40%左右。

在这四个ConvNet融合模型中,中期融合的整体MR最低(36.99%),比其他融合模型低3.5%,显示出行人检测最有效的多光谱协同效应。由于四种DNN架构在不同的ConvNet级别上对应于信息融合,因此作者推测,来自RGB和红外分支的中层卷积特征在融合中兼容更好,它们包含一些语义,同时并不能完全抛出所有细节。然而,早期融合结合了浅层特征,使得一些与任务无关的浅层特征融合,这会影响融合效果。后期融合在深层语义特征上进行融合,而置信度融合会结合置信度得分。在某些情况下,这两个模型很难消除语义噪声或改善一个图像的决策错误。与Faster R-CNN-C或Faster R-CNN-T相比,给定整个测试集,中期融合将整体MR降低了约11%。上图展示了一些检测样本,显示了置信度大于0.5的检测结果。显然,与基于RGB图像的检测器相比,作者的多光谱行人检测器可实现更准确的检测,尤其是当某些行人的外部照明不良时。同时,还消除了一些虚警。

[候选区域评估]
关于召回率,作者还评估了RPN在中期融合中候选区域。比较了Faster R-CNN-C和Faster R-CNN-T的RPN,以及ACF-C-T行人检测器。在KAIST的测试集上生成行人候选框的比较结果如下图所示。
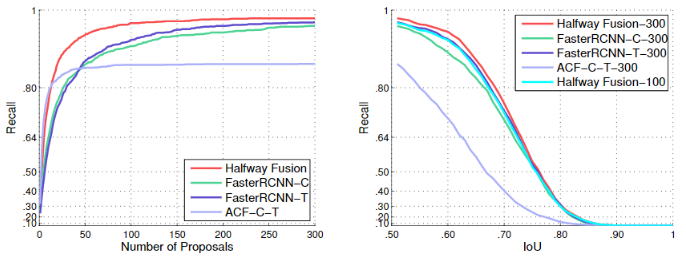
召回率与候选区域数量:鉴于IoU@0.5,中期融合模型在候选区域数量相同的情况下获得了最高的召回率。与其他约87%的召回方法相比,该模型可通过50个候选区域实现94%的召回率。 换句话说,中期融合可以用更少的候选区域达到相同的召回率。这在实践中非常有用,因为较少的候选区域可以使DNN节省分类时间。中期融合通过30个候选区域获得了90%的召回率,而Faster R-CNN-C和Faster R-CNN-T需要大约80个候选区域才能实现相同的召回数目。














 9845
9845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









