







文章目录
多模态技术基础
参考论文:https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.19678/j.issn.1000-3428.0057370
参考文章:https://zhuanlan.zhihu.com/p/133990245
深度学习多模态融合指机器从文本、图像、语音、视频等多个领域获取信息,实现信息转换和融合,从而提升模型性能的技术,是一个典型的多学科交叉领域。人们生活在一个多领域相互交融的环境中,听到的声音、看到的实物、闻到的味道等都是各领域的模态形式,为了使深度学习算法更加全面和高效地了解周围的世界,需要给机器赋予学习和融合这些多领域信号的能力。因此,研究者们开始关注如何将来自多领域的数据进行融合,以实现多种异质信息的互补。例如,对语音识别的研究表明,视觉模态提供了嘴的唇部运动和发音的信息,包括张开和关闭,从而有助于提高语音识别性能。因此,利用多种模式提供的综合语义对深度学习非常有价值。
在机器学习中,我们已经知道模型学习的特征越多,种类越多效果越好。所以融合多模态的特征可以使得模型学到的特征越完整,也是符合人类进化的表现,人类在多种行动与决策都会综合多个模态信息,比如视觉、听觉、嗅觉等。
多模态技术主要要素:表示(Representation),融合(Fusion)、转换(Translation)、对齐(Alignment)。由于不同模态的特征向量最初位于不同子空间中,即异质性差距,这将阻碍多模态数据在随后的深度学习模型中综合利用[3]。解决这一问题可将异构特征投影到公共子空间,其中具有相似语义的多模态数据将由相似向量表示。多模态融合技术的主要目标是缩小语义子空间中的分布差距,同时保持模态特定语义的完整性。
1,多模态融合架构(神经网络模型的基本结构形式)
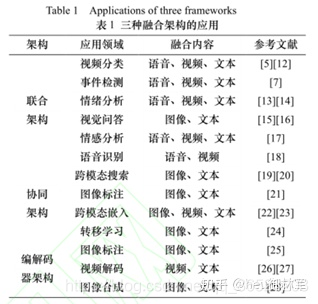
多模态融合的主要目标是缩小模态间的异质性差异,同时保持各模态特定语义的完整性,并在深度学习模型中取得最优的性能。分为三类联合(Joint)架构、协作(Coordinated)架构和编解码(Encode-Decode)架构。三种融合架构在视频分类、情感分析、语音识别等许多领域得到广泛应用,且涉及图像、视频、语音、文本等融合内容,具体应用情况如下表 所示。
1.1联合架构
联合架构是将单模态表示投影到一个共享语义子空间中,以便能够融合多模态特征。如下图所示,**每个单一模态通过一个单独的编码后,都将被映射到一个共享子空间中,**遵循这一策略,在视频分类[12]、事件检测[7]、情绪分析[13,14]、视觉问答[15,16]和语音识别[18]等多模态分类或回归任务中都表现出较优的性能。
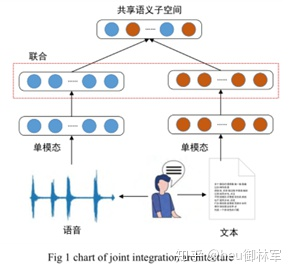
多模态联合架构的关键是实现特征“联合”,最简单方法是直接连接,即“加”联合方法。该方法在不同的隐藏层实现共享语义子空间,将转换后的各个单模态特征向量语义组合在一起,从而实现多模态融合,如公式 z = f ( w 1 T v 1 + . . . + w n T v n ) z=f(w_1^Tv_1+...+w_n^Tv_n) z=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3576
3576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









