







原文地址
https://arxiv.org/abs/2006.10645
论文阅读方法
初识
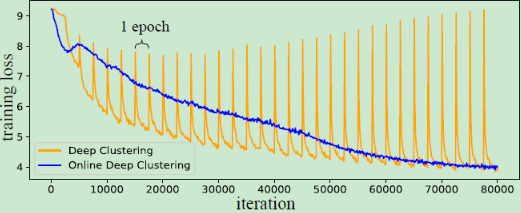
这主要是由于DC的离线学习机制,在不同的epoch中样本标签发生改变,导致网络学习不稳定。
关于Deep Cluster这篇文章可参照我另一篇博客
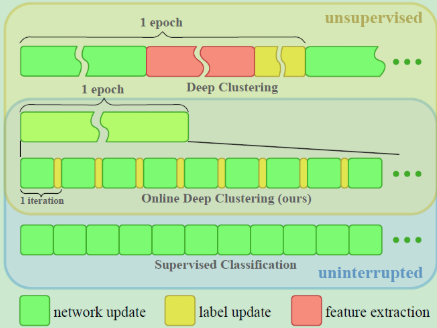
为了解决这个问题,本文提出了ODC(Online Deep Clustering)的在线学习机制,同步执行“聚类”与“学习”而不是交替,这能保证分类器稳定更新的同时,簇心也稳步演变。通过使用两个存储器memory来实现,一个sample memory存储样本特征与标签,另一个centroids存储簇中心特征。ODC与DC的区别如下图所示:
相知
2. related work
① 无监督表示学习:包括重构的方法(GAN,VAE等),自监督学习的方法;② “聚类”与特征学习结合:Deep Clustering以及Deeper Clustering等;③ 提升自监督学习的机制:这也是本文的目的。
3. Methodology
两个Memory:① Sample Memory存储整个数据集的特征以及标签;② Centroids Memory存储每类簇心的特征。
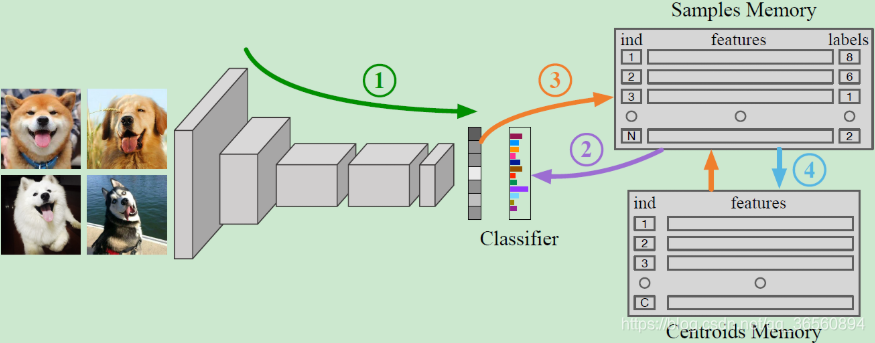
整体流程:
准备工作:网络随机初始化,两个Memory通过一次全局的聚类过程进行初始化,例如
K-Means.
① 每个batch,网络前向传播得到样本特征;
② 根据Sample Memory中的伪标签进行反向传播,更新参数:
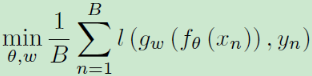
B为batch size,就是执行分类任务中的loss function
③ 同时对Sample Memory中特征与标签进行更新:
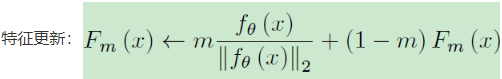
m∈(0,1],为momentum系数
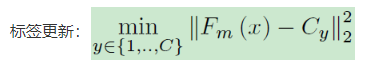
执行最近邻,最近的簇为其新的标签
④ 对之前涉及到的Cluster,更新Centroids Memory中的特征,即平均属于该簇的所有特征作为新的簇心特征。
所谓涉及到的特征,就是在网络更新过程中有新点加入/旧点移除的簇,每k个iteration执行一次。(本文实验设置为k=10)
技巧:
① loss weighting:对于分类网络的loss function赋予权重,每个cluster的权重与当前所拥有的数量相关,这可以缓解类别不平衡影响。
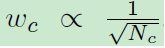
每个类别所对应的权重w
正比于对各类别数目N开根号后取倒数)
② dealing with small clusters:设置一个阈值,如果存在某个cluster中的数量小于当前阈值,即删除这个类,并将其cluster中的点送到其他类别(最近的正常类)中;其次,对于那些数量很多的类,会将其拆分为两个子类。
本文实验阈值设置为20
③ Dimensionality Reduction:DC执行PCA降维,而ODC额外增加一个非线性head layer,使用{fc-bn-relu-dropout-fc-relu}的方法进行降维处理,而在执行下游任务时去掉该层head layer。
实现细节:
具体参见原文,这里提出与DC的几个主要不同点:
① 数据增广增加随机旋转; ② 不使用sobel滤波来去除颜色,而是使用强色彩抖动(strong color jittering)来避免颜色影响; ③ 以0.2的概率随机将图片转为灰度。
4. Experiments
关于具体实验设置与结果,请参照原文。
回顾
本文发表于CVPR 2020,基于Deep Clustering的基础之上改进(在线学习的训练方式),效果提升地很明显。相比于之前主要关注于图像内语义信息的自监督学习,OC与ODC这两种深度聚类方法更着重地关注于图像间的信息,这也就说明它们与之前的自监督学习方法是天然互补的关系,ODC/DC可对先前经过自监督学习的网络进行微调并改善其性能。
代码地址
https://github.com/open-mmlab/OpenSelfSup














 2997
2997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









