







1.时间复杂度
首先我们要知道什么是大O,教科书中有非常严谨的定义,但对于面试的我们并不需要去专文字游戏,我们需要理解它:
n表示数据规模 ; O( f(n) )表示运行算法所需要执行的指令数,和f(n)成正比。 比如下面例子

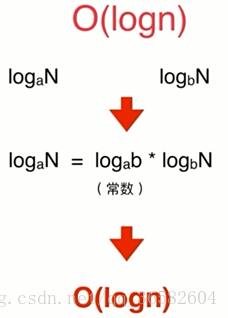
其中abcd都是常数,是固定不变的,换句话说,随着n的增大,比如二分查找法是被logn所控制的,和a没有关系,所以大O里面一般都把常数省去,我们再看看下面例子:
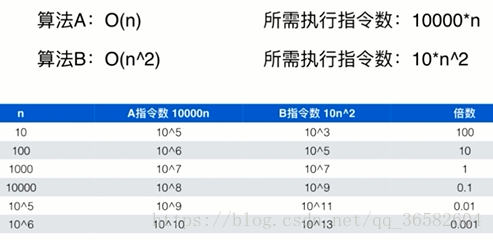
可以看出时间复杂度是衡量一个量级上的差距,这个量级上的差距表现在当n突破到一个点的时候,时间复杂度低的算法就一定要比时间复杂度高的算法快,而且n越大,这个优势越明显。而我们研究算法就是要处理大规模的数据,如果数据比较小的话,时间总是够用的。
不过我们可以看到,复杂度高的算法可能它会有前面常数小的优势,所以在我们数据规模比较小的时候,它是有意义的,比如所有的高级排序算法,当数据规模小到一定程度时,我们都可以转而使用插入排序法,来进行优化,而这个优化一般有百分之十到十五的,在一些情况下还是很有意义的,但是这是细节上的优化,但整体上我们还是要追求复杂度低的算法

对此,我们设计了一个算法,这个算法有两部分的话,那么这个算法要以其中量级最高的那个部分作为时间复杂度
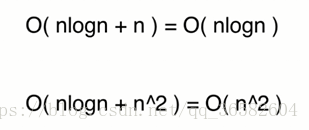
但是需要特别注意,取量级大的一部分的前提一定是我们这个算法它所处理的这两部分所对应的规模n是一样的

比如下面这个例子

上面犯的错误:错误的将字符串长度和数组中字符串的数量(数组长度)混淆在了一起,这两个变量是没有关系的

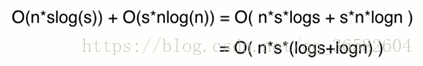
注意:为什么我们要计算最长的字符串长度呢,前面说了,大O是表示上界
最后,我们要知道算法复杂度在有些情况是用例相关的

虽然是用例相关,但通常情况下我们关注的还是平均的情况,特殊情况我们只要心里有数就行
2 数据规模的概念
对于我们现在的家用计算机,我们不同时间时间复杂度的算法可以处理的数据量级如下:

对于空间复杂度:


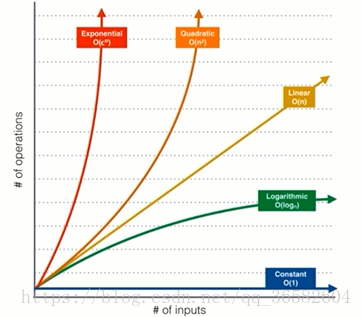
3. 常见的复杂度分析
O(n)级别有个非常显著的特征就,它会存在一个循环,循环的次数是和n相关的

O(n2)级别的有双重循环

但不是所有双重循环都是O(n2)的

下面这个其实是O(nlogn)

接下来我们看看O(logn)---二分搜索法



最后看一个O(sqrt(n))

4 测试时间复杂度
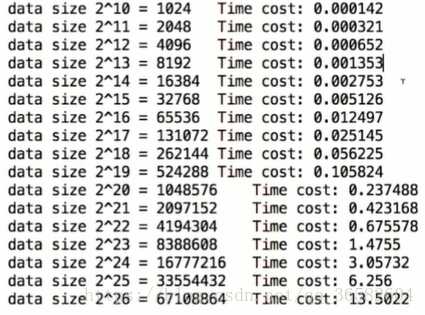
现在我们测试一个O(n)时间复杂度的算法,数据量以2倍的趋势上升,测试结果如下
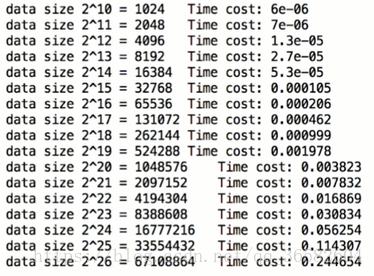
可以看到下排的时间是上排时间的两倍,所以确实是O(n)级别的
现在我们看下O(n^2)级别的
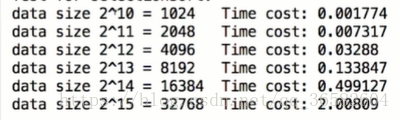
可以看到下排时间是上排时间的4倍,是O(n^2)级别的
现在我们看下O(logn)级别的
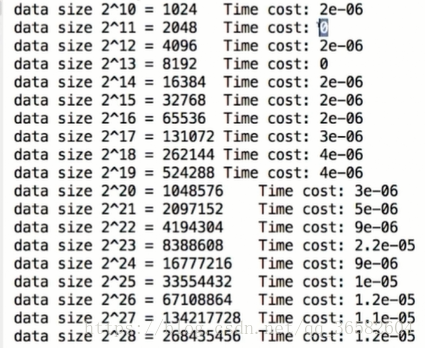
可能看数据看不出,所以我们理论推导一下

可以看到,但数据规模扩大两倍,运行效率将是1.log2/logN,如果N足够大的话,结果将是1,运行效率将不变,很恐怖的
最后现在我们看下O(nlogn)级别的,结果可以看出来,和O(n)的差不多,数据扩大两倍,时间增加1.几倍
5, 递归算法的时间复杂度
1)一次递归调用(关注递归深度---递归深度就是调用的次数)

像二分搜索法的递归深度是logn(每次都是对半分),则复杂度O(Tlogn)
2)两次递归调用(关注递归调用次数)
我们先看下面这个例子

怎样才能知道它的递归次数呢,我们可以画一棵递归树,再把树的节点数出来
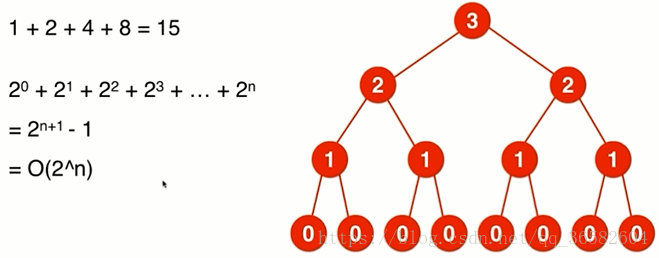
可以看到,这是指数级的算法,很慢很慢的!但这在我们的搜索领域是有很大的意义的。
但是我们的高级排序算法如,归并,快排也是2次递归调用,但时间复杂度只有O(nlogn)级别,那是因为
1)上面的深度为n,而高级排序的深度都只有logn
2)在高级排序算法中我们在每个节点处理的数据规模是组件缩小的,而上面的例子都是一样的














 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









