







 本文介绍了变分法在概率推理中的应用,特别是朴素平均场理论如何将复杂问题转化为低自由度问题进行近似处理。详细阐述了朴素平均场算法的变分优化过程,包括目标函数、迭代优化和平均场方程。此外,还讨论了循环传播算法(Loopy Belief Propagation)在贝叶斯网络中的应用,即使在存在环的网络中也能提供近似解。最后,提到了因子图和sum-product算法在边缘概率计算中的角色。
本文介绍了变分法在概率推理中的应用,特别是朴素平均场理论如何将复杂问题转化为低自由度问题进行近似处理。详细阐述了朴素平均场算法的变分优化过程,包括目标函数、迭代优化和平均场方程。此外,还讨论了循环传播算法(Loopy Belief Propagation)在贝叶斯网络中的应用,即使在存在环的网络中也能提供近似解。最后,提到了因子图和sum-product算法在边缘概率计算中的角色。
变分法
Introduction
对解的精度进行优化的近似推理算法
基本思想: 通过变分转换(variational transformation),将概率推理问题转换为变分优化(variational optimization)问题来处理。
但是对于比较困难的概率推理问题,变分法也难以获得精确的结果,此时可以对变分优化问题进行适当的放松,如对其目标函数和约束条件集进行简化,之后通过迭代的方法期望获取一个近似解。
变分法例
朴素平均场
朴素平均场理论( naive mean field theory)是统计力学常用的近似方法.它关心的是在一个包含众多粒子的系统中,其它粒子对某个特定粒子的作用.它的基本思想是用一个“平均了的场”来 代替 原来的系统,并在其中对上述作用进行
估计。这样,它把一个高自由度的复杂问题转化为一个低自由度的简单问题来近似处理。把朴素平均场的基本思想应用于贝叶斯网推理,可以在拥有众多变量且连接稠密的网络中,近似计算后验概率。
计算: P ( E = e ) 和 P ( Z ∣ E = e ) P(E=e) 和 P(Z | E=e) P(E=e)和P(Z∣E=e) ,所有变量集合:X,证据:E,所有非证据变量:Z = X - E = { Z 1 , Z 2 , . . . , Z n } \{ Z_1,Z_2,...,Z_n \} {Z1,Z2,...,Zn}
- 转换概率推理问题为变分优化问题
J ( Q ) = l o g P ( E = e ) − K L [ Q [ Z ] , P ( Z ∣ E = e ) ] J(Q) = log P(E=e) - KL[ Q[Z], P(Z|E=e)] J(Q)=logP(E=e)−KL[Q[Z],P(Z∣E=e)]
Q ( Z ) Q(Z) Q(Z) :作为一族用于近似 P ( Z ∣ E = e ) P(Z|E=e) P(Z∣E=e) 的参数化分布,被称为 变分分布(variational distribution)。
K L [ Q [ Z ] , P ( Z ∣ E = e ) ] KL[ Q[Z], P(Z|E=e)] KL[Q[Z],P(Z∣E=e)] :变分分布 Q ( Z ) Q(Z) Q(Z)和待求后验分布 P ( Z ∣ E = e ) P(Z|E=e) P(Z∣E=e) 之间的KL距离。
-
考虑目标函数 J ( Q ) J(Q) J(Q)的最大值点 Q ∗ Q^* Q∗,由于
KL距离非负,且只有当它涉及的两个分布相同时候才取最小值0,所以令 J ( Q ) J(Q) J(Q) 取最大值的最优变分分布就是后验概率分布:
Q ∗ ( Z ) = P ( Z ∣ E = e ) Q^*(Z) = P( Z | E=e ) Q∗(Z)=P(Z∣E=e)
此时:
J ( Q ∗ ) = log P ( E = e ) J(Q^*) = \log P(E=e) J(Q∗)=logP(E=e) -
展开 1 中公式:
- 通过KL散度:
J ( Q ) = l o g P ( E = e ) − ∑ Z Q ( Z ) log Q ( Z ) P ( Z ∣ E = e ) J(Q) = log P(E=e) - \sum_ZQ(Z)\log{\frac{Q(Z)}{P(Z|E=e)}} J(Q)=logP(E=e)−Z∑Q(Z)logP(Z∣E=e)Q(Z)
- 通过条件概率公式 P ( Z ∣ E = e ) = P ( Z , E = e ) P ( E = e ) P(Z|E=e) = \frac{P(Z, E=e)}{P(E=e)} P(Z∣E=e)=P(E=e)P(Z,E=e) :
= l o g P ( E = e ) − ∑ Z Q ( Z ) log Q ( Z ) P ( E = e ) P ( Z ∣ E = e ) = log P(E=e) - \sum_ZQ(Z)\log{\frac{Q(Z)P(E=e)}{P(Z|E=e)}} =logP(E=e)−Z∑Q(Z)logP(Z∣E=e)Q(Z)P(E=e)
- log展开 : log a ( M N W ) = log a N + log a M − log a W \log_a(\frac{MN}{W}) = \log_aN + \log_aM - \log_aW loga(WMN)=logaN+logaM−logaW:
= l o g P ( E = e ) − ∑ Z Q ( Z ) [ log Q ( Z ) + log P ( E = e ) − log P ( Z ∣ E = e ) ] = log P(E=e) - \sum_ZQ(Z)[ \log Q(Z) + \log P(E=e) - \log P(Z|E=e) ] =logP(E=e)−Z∑Q(Z)[logQ(Z)+logP(E=e)−logP(Z∣E=e)]
- 清除 log P ( E = e ) \log P(E=e) logP(E=e):
= − ∑ Z Q ( Z ) log Q ( Z ) + ∑ Z Q ( Z ) log P ( Z ∣ E = e ) = - \sum_ZQ(Z)\log Q(Z) + \sum_ZQ(Z)\log{P(Z|E=e)} =−Z∑Q(Z)logQ(Z)+Z∑Q(Z)logP(Z∣E=e)
- 通过Entropy的公式:
= H Q ( Z ) + ∑ Z Q ( Z ) l o g P ( Z , E = e ) = H_Q(Z) + \sum_ZQ(Z)logP(Z,E=e) =HQ(Z)+Z∑Q(Z)logP(Z,E=e)
H Q ( Z ) H_Q(Z) HQ(Z) 是 Z Z Z相对于变分分布的 Q ( Z ) Q(Z) Q(Z)的熵。
- 此时,只要解决变分优化问题,就得到了原推理问题的 精确解 精确解 精确解。
BUT,上述精确解并不容易得到,一个根本原因是变分分布
Q
(
Z
)
Q(Z)
Q(Z)的空间难以显示表达。
因此,为了简化计算,朴素平均场根据平均场理论思想,将变分分布限制中一类最简单的分布上,即使用所有变量都相互独立的分布来近似后验分布:
Q
(
Z
)
=
∏
i
=
i
n
Q
i
(
Z
i
)
Q(Z) = \prod_{i=i}^n{Q_i(Z_i)}
Q(Z)=i=i∏nQi(Zi)
由此通过第 3 步推出的公式 结合 变量都独立同分布的假设(或者说 限制):
J
(
Q
)
=
H
Q
(
Z
)
+
∑
Z
Q
(
Z
)
l
o
g
P
(
Z
,
E
=
e
)
J(Q) = H_Q(Z) + \sum_ZQ(Z)logP(Z,E=e)
J(Q)=HQ(Z)+Z∑Q(Z)logP(Z,E=e)
=
∑
i
=
1
n
H
Q
i
(
Z
i
)
−
∑
Z
[
∏
i
=
i
n
Q
i
(
Z
i
)
]
P
(
Z
,
E
=
e
)
= \sum_{i=1}^n{H_{Q_i}(Z_i)}- \sum_Z[ \prod_{i=i}^n{Q_i(Z_i)}] P(Z, E=e)
=i=1∑nHQi(Zi)−Z∑[i=i∏nQi(Zi)]P(Z,E=e)
由于上式最大值和最大值点一般没有闭公式解。变分分布 Q ( Z ) Q(Z) Q(Z)的边缘分布可以独立的变化。因此,利用如下迭代法来优化目标函数 J ( Q ) J(Q) J(Q)。
从某个初始分布 Q^0(Z)
while 直到收敛
for i=1 : n
以J(Q)为目标函数,对变分边缘分布Qi(Zi)进行优化。
其中,优化 Q i ( Z i ) Q_i(Z_i) Qi(Zi)的过程中,其他各个变分边缘分布 { Q j ( Z j ) ∣ j ≠ i } \{Q_j(Z_j) | j \neq i\} {Qj(Zj)∣j=i}均被作为常数(表示其中变量相互独立),因此每次优化 J ( Q ) J(Q) J(Q) 过程中, J ( Q ) J(Q) J(Q)仅为 Q i ( Z i ) Q_i(Z_i) Qi(Zi)的函数:
J ( Q i ) = θ + H ( Q i ) + ∑ Z i Q i ( Z i ) E Q [ log P ( Z , E = e ) ∣ Z i ] J(Q_i)=\theta + H(Q_i) + \sum_{Z_i} Q_i(Z_i) E_Q[\log P(Z, E=e) | Z_i] J(Qi)=θ+H(Qi)+Zi∑Qi(Zi)EQ[logP(Z,E=e)∣Zi]
其中,
θ
\theta
θ是与
Q
i
(
Z
i
)
Q_i(Z_i)
Qi(Zi)无关的常数,而
E
Q
[
log
P
(
Z
,
E
=
e
)
∣
Z
i
]
=
∑
Z
−
Z
i
[
∏
j
=
1
,
j
≠
i
n
Q
j
(
Z
j
)
]
log
P
(
Z
,
E
=
e
)
E_Q[\log P(Z, E=e) | Z_i] = \sum_{Z - {Z_i}}[\prod^n_{j=1,j\neq i}Q_j(Z_j)]\log P(Z,E=e)
EQ[logP(Z,E=e)∣Zi]=Z−Zi∑[j=1,j=i∏nQj(Zj)]logP(Z,E=e)
是 log P ( Z , E = e ) \log{P(Z, E= e)} logP(Z,E=e)在分布 Q ( Z − Z i ∣ Z i ) Q(Z-Z_i | Z_i) Q(Z−Zi∣Zi)下的期望值。
Notice: ∑ Z i Q ( Z i ) = 1 \sum_{Z_i}Q(Z_i) = 1 ∑ZiQ(Zi)=1。
为了对 J ( Q i ) J(Q_i) J(Qi)进行优化,引入拉格朗日乘数( Lagrange multiplier) : λ \lambda λ,并且求解如下方程组:
∂ ∂ Q i ( Z i = z ) [ J ( Q i ) + λ ( ∑ Z i Q ( Z i ) − 1 ) ] = 0 , ∀ z ∈ Ω Z i \frac{\partial}{\partial Q_i(Z_i =z)}[J(Q_i) + \lambda(\sum_{Z_i}Q(Z_i)-1)] = 0, \forall z \in \Omega_{Z_i} ∂Qi(Zi=z)∂[J(Qi)+λ(Zi∑Q(Zi)−1)]=0,∀z∈ΩZi
===>
−
log
[
Q
i
(
Z
i
=
z
)
]
+
1
+
E
Q
[
l
o
g
P
(
Z
,
E
=
e
)
∣
Z
i
]
+
λ
=
0
-\log{ [Q_i(Z_i = z)]} +1 + E_Q[log P(Z, E=e) | Z_i] + \lambda = 0
−log[Qi(Zi=z)]+1+EQ[logP(Z,E=e)∣Zi]+λ=0
由上式可得到如下更新
Q
i
(
Z
i
)
Q_i(Z_i)
Qi(Zi)的平均场方程( mean field equation):
Q
i
(
Z
i
)
=
1
a
i
e
E
q
[
log
P
(
Z
,
E
=
e
)
∣
Z
i
]
Q_i(Z_i) = \frac{1}{a_i}e^{E_q[\log P(Z, E=e) | Z_i]}
Qi(Zi)=ai1eEq[logP(Z,E=e)∣Zi]
其中
a
i
a_i
ai是一个归一化常数:
∑
Z
i
e
E
q
[
log
P
(
Z
,
E
=
e
)
∣
Z
i
]
\sum_{Z_i} e^{E_q[\log P(Z, E=e) | Z_i]}
Zi∑eEq[logP(Z,E=e)∣Zi]
上述迭代过程的每一步都将使 J ( Q ) J(Q) J(Q)增大,因此它最终会收敛.但是不一定会收敛到全局最优,初始点的选取和迭代更新的顺序都会影响到解的质量。
朴素平均场法直接对所求的后验概率分布的精度进行优化,概念清晰,算法的收敛速度比随机抽样法快。当网络中变量数目多、连接稠密,但变量之间的依赖关系却比较弱的时候,它可以给出一个较好的结果。
但是,实际中变分 平均场分布 ∏ i = 1 n Q i ( Z i ) \prod_{i=1}^nQ_i(Z_i) ∏i=1nQi(Zi) 往往过于简单,不能很好地近似真实的后验分布。
循环传播算法(loopy belief propagation)
在贝叶斯网发展初期,Pearl (1986)提出了一个仅适用于底图而不含环的网络的精确推理算法(消息传递算法 )。后来人们发现,如果把该算法在底图含环的BN网络上强制运行,往往也可以得到一个较好的近似解,这就是循环传播(loopy belief propagation)算法,又称为迭代信度传播(iterative belief propagation)算法。
底图:贝叶斯网络,马尔可夫网络。
这儿说的底图不含环表示的是贝叶斯网络去掉方向之后的无向图不存在环。另一种解释是:BN网络中不存在两条或多条 A节点到 B节点的路径。
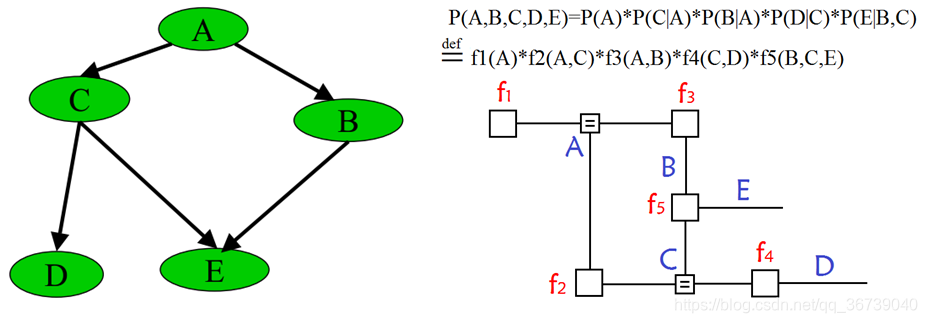
在概率图中,求某个 变量的边缘分布 是常见的问题。这问题有很多求解方法,其中之一就是把贝叶斯网络或马尔科夫随机场转换成因子图,然后使用Belief propagation (如:sum-product算法,max-product算法)。
引入:sum-product算法(LBP的基础:如何计算边缘分布)
注:本小节借鉴文章: 从贝叶斯方法谈到贝叶斯网络
- 如何由联合概率分布求边缘概率分布?
Answer: 对 x k x_k xk外的其它变量的概率求和,最终剩下 x k x_k xk的概率。
f ( x k ) = ∑ { x 1 , . . . , x n } − x k f ( x 1 , . . . , x n ) f(x_k) = \sum_{\{x_1,...,x_n\} - x_k}f(x_1,...,x_n) f(xk)={x1,...,xn}−xk∑f(x1,...,xn)
- BN的联合分布表示?
P ( x 1 , x 2 , . . . , x n ) = ∑ i = 1 n P ( x i ∣ P a ( x i ) ) P(x_1,x_2,...,x_n) = \sum^n_{i=1} P(x_i|Pa(x_i)) P(x1,x2,...,xn)=i=1∑nP(xi∣Pa(xi))
- 转换为因子表示?
f ( x 1 , x 2 , . . . , x n ) = ∑ i = 1 n f ( x i , P a ( x i ) ) f(x_1,x_2,...,x_n) = \sum^n_{i=1} f(x_i , Pa(x_i)) f(x1,x2,...,xn)=i=1∑nf(xi,Pa(xi))
一个因子图表示(示例):
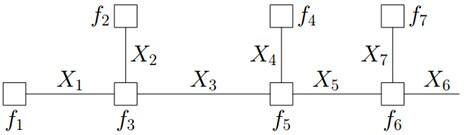
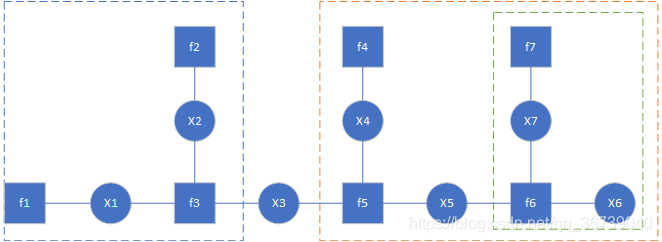
- 提取公因子
f ( x 3 ) = ( ∑ x 1 , x 2 f 1 ( x 1 ) f 2 ( x 2 ) f 3 ( x 1 , x 2 , x 3 ) ) f(x_3) = \left( \sum_{x_1,x_2}f_1(x_1)f_2(x_2)f_3(x_1,x_2,x_3)\right) f(x3)=(x1,x2∑f1(x1)f2(x2)f3(x1,x2,x3))
∗ ( ∑ x 4 , x 5 f 4 ( x 4 ) f 5 ( x 5 ) f 5 ( x 3 , x 4 , x 5 ) ( ∑ x 6 , x 7 f 6 ( x 5 , x 6 , x 7 ) f 7 ( x 7 ) ) ) *\left( \sum_{x_4,x_5}f_4(x_4)f_5(x_5)f_5(x_3,x_4,x_5) \left( \sum_{x_6,x_7}f_6(x_5,x_6,x_7) f_7(x_7) \right) \right) ∗(x4,x5∑f4(x4)f5(x5)f5(x3,x4,x5)(x6,x7∑f6(x5,x6,x7)f7(x7)))
图片来自于:贝叶斯网络
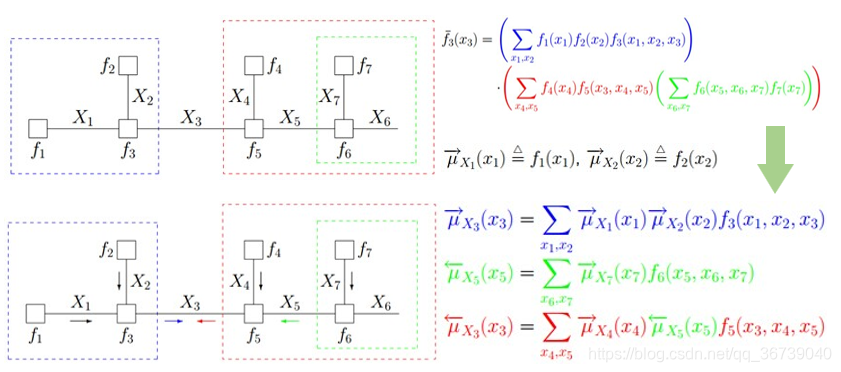
注: 感觉和变量消元法很像,仔细思考之后。变量消元法与1990年Zhang和Poole提出,而消息传播由1986年pearl提出。消息传播方法是为了解决边缘概率问题 P ( X ) P(X) P(X),而变量消元法是计算后验概率 P ( Q ∣ E ) P(Q|E) P(Q∣E)问题。
但实际上,变量消元法是先将 P ( Q ∣ E ) P(Q|E) P(Q∣E)转换为 P ( Q , E ) P(Q,E) P(Q,E)来计算,然后又转换回去得出结果。在计算 P ( Q , E ) P(Q,E) P(Q,E)过程中计算步骤和消息传播是感觉差不多。变量消元法需要一个消元节点顺序作为输入。感觉 sum-product、belief propagation和 Variable elimination 其实说的是一个东西。
(2020-12-10:学习BN inference的第一周)
当计算 X 3 X_3 X3的边缘分布时,其他所有信息通过连接 X 3 X_3 X3的因子节点传播过来。
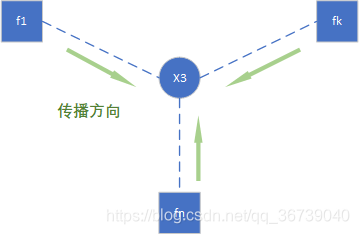
如果因子图是无环的,则sum-product一定可以准确的求出任意一个变量的边缘分布,如果是有环的,则无法用sum-product算法准确求出来边缘分布。
但是,如果贝叶斯网络中存在环(这儿的环是 去掉所有方向后存在无向环,而不是说有向的环),那么消息可能会永远的传递下去。如下图:
解决存在无向环时候的方法:
- 删除若干边,使其不存在环
- 重新构造没有环的BN
除了sum-product算法,还有一个max-product 算法。
唯一的区别: max-product 算法就在上面sum-product 算法的基础上把求和 ∑ \sum ∑ 符号换成求最大值 max \max max的符号即可!
LBP
上一部分对LBP的基础方法,消息传递进行了介绍。
注 : 本小节认为 BP = sum-product = Variable elimination
基本步骤:先在网络中各个节点之间迭代的进行信息传播,然后利用网络中的信息近似计算任一节点的信度(后验概率分布)。
上一部分说了,sum-product一般在底图无环的BN中可以很好的运行,但是在底图有环的BN中,可能会陷入无限循环。但是 《贝叶斯网络引论》一书6.2.2 循环传播算法 这一章节中,将BP算法强制在底图有环的BN上强制运行,往往可以得到一个较好的近似解,然后将这种方法称为:循环传播算法(Loopy belief propagation)和 迭代信度传播(Iterative belief propagation)。
在这里我有点迷糊,所以去查询了 Loopy belief propagation 的文献[3],文献中对 信念传播算法 强制在存在环的网络中运行进行了研究。文献解答了我的疑惑。
【参考文献】
[1] 厉海涛,金光,周经伦,周忠宝,李大庆.贝叶斯网络推理算法综述[J].系统工程与电子技术,2008(05):935-939.
[2] 张连文, 郭海鹏. 贝叶斯网引论, 科学出版社, 2006.
[3] Murphy K P, Weiss Y, Jordan M. Loopy belief propagation for approximate inference : an empirical study[C].Proceedings of Uncertain ty in Artificial Intelligence, 1999 :467-475.

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









