




前言
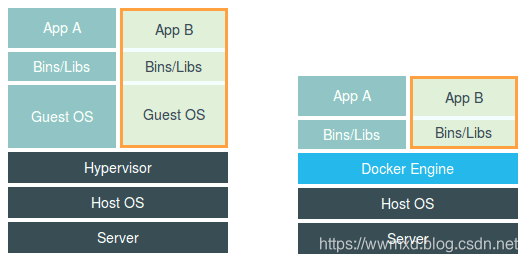
上图分别画出了虚拟机和docker的工作原理(docker部分是不准确的),其中名为Hypervisor的软件是虚拟机最重要的部分,他通过硬件的虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,然后,它在这些虚拟硬件上安装了一个新的操作系统。
而右边的图,则用一个名为Docker Engine的软件替换了Hypervisor,这样看起来Docker更像一个轻量级的虚拟化技术,然而实际上这种说法是不准确的。下面我会浅析下docker是如何实现的
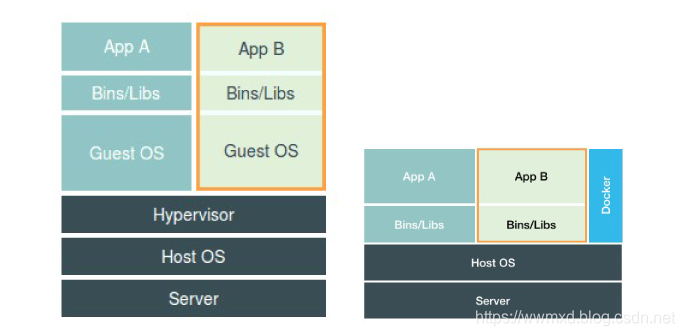
上图是docker engine更为准确的位置,毕竟它并不像Hypervisor那样对应用进程的隔离环境负责(真正负责的是宿主机操作系统本身),它所起的作用更像是旁路式的辅助和管理工作。
从进程说起
容器技术的核心功能就是通过约束和修改进程的动态表现,从而为其创造出一个边界。
而对于docker来说,则是用过Cgroup技术来约束,namespace技术来修改进程视图
当我们在容器内执行ps指令时,会发现有趣的事情,进程的pid是从1开始的,仿佛docker容器和宿主机是完全不同的世界。而做到这种效果的技术就是linux里面的namespace机制,通过创建一个全新进程空间,就可以让这个新创建的进程在这个空间里的pid为1,当然这只是障眼法,在宿主机中的pid还是真实的数值。
当然容器空间的创建不仅仅是pid namespace,linux还提供了了mount,uts,ipc,network和user这些namcespace,同来对各种不同的进程上下文进行障眼法操作,而这就是linux容器最基本的实现原理(即容器其实是一种特殊侧进程而已)
隔离与限制
对于虚拟机来说,比如一个kvm虚拟机启动,自身就需要占用100~200MB内存。以及用户应用运行在虚拟机里时,它对宿主机操作系统的调用不可避免要被虚拟化软件拦截处理造成损耗。而容器化的应用,本质上还是宿主机的普通进程,意味着不会有上面的损耗
虽然容器的敏捷和高性能是相较于虚拟机的最大优势,但基于linux namespcae的隔离机制相比于虚拟化技术隔离是不彻底的(存在相应的加固方案),毕竟容器内虽然挂载了自己的操作系统文件,但缺不能改变共用宿主机内核的事实(linux内核中,很多资源是不能namespace化的)。
对于容器来说,除了隔离之外,对容器资源的占用进行限制也至关重要,而linux cgroups就是用来设置资源限制的技术。通过相应的配置可以对一个进程组能够使用的资源上限进行限制。(由于我也并没有深入了解过cgroup,所以这里不会讲到如何使用cgroup),简单粗暴的理解就是,它就是一个子系统目录加上一组资源限制文件的组合
容器文件系统挂载
容器文件系统的挂载实际上是使用mount namespace来实现的,而这个挂载在容器的根目录上,用来为容器进程提供隔离后执行环境的文件系统,就是所谓的容器镜像。它还有一个更为专业的名字,为rootfs(根文件系统)。但是rootfs并不包括操作系统内核,即它只是一个没有灵魂的躯壳。
相信玩过docker的都会听说过分层的说法,而Docker引入的层的概念是通过联合文件系统(Union File System)来实现的,简单的说就是可以把两个目录A和B挂载到一个公共的目录C上,当对C目录文件修改时,对目录A.B也会生效
分层结构
- 只读层
容器中最下面的几层一般都是只读层,挂载的方式是ro+wh(readonly+whiteout)
- 可读写层
容器的最上层一般是可读写层,挂在方式为rw(read write).当要对只读层的文件进行修改时,会在读写层创建一个whiteout文件,把只读层的文件遮挡起来。这样的设置保证了可以增量更新镜像
- init层
在只读层和读写层之间,专门用来存放/etc/hosts,/etc/resolv.conf等信息
总计
上述的讲解,其实可以归纳为docker最核心的原理:
- 启用linux namespace配置
- 设置指定的Cgroups参数
- 切换进程的根目录

















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









