









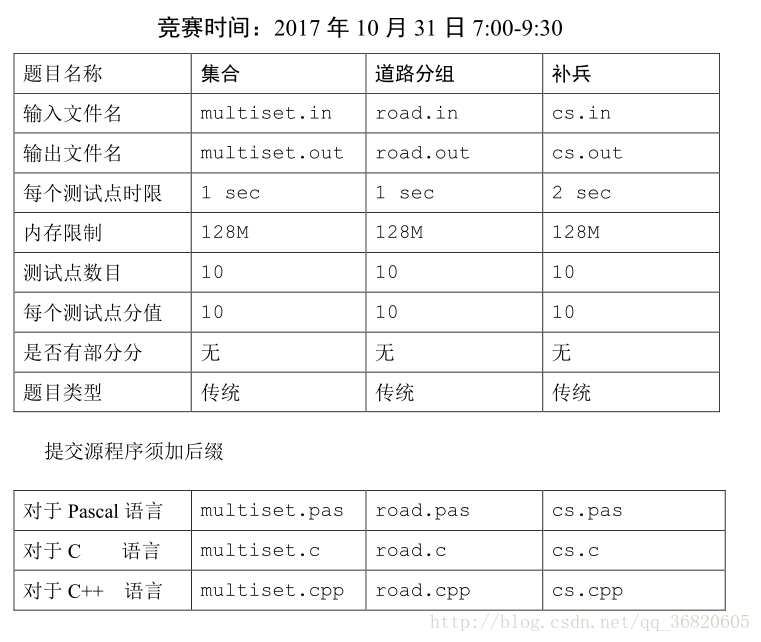
【问题描述】
给定一个可重集合,一开始只有一个元素 0 。然后你可以操作若干轮,每一
轮,你需要对于集合中的每个元素 x 进行如下三种操作之一:
1 、将 x 变为 1 + x 。
2 、将 x 分裂为两个非负整数 z y, ,且满足 z y x + = 。
3 、什么都不做。
每一轮,集合中的每个元素都必须进行上面三个操作之一。
对于一个最终的集合,你的任务是判断至少进行了多少轮。
【输入文件】
第一行为一个正整数 n ,表示集合的最终大小。
第二行为 n 个非负整数,描述集合中的元素。
【输出文件】
输出一个非负整数,为最少的轮数。
【输入输出样例】
multiset.in multiset.out
5
0 0 0 3 3
5
【数据规模和约定】
设集合中最大的元素为 m 。
对于 % 10 的数据,满足 10 ≤ n , 10 ≤ m 。
对于 % 30 的数据,满足 50 ≤ n , 100 ≤ m 。
对于 % 50 的数据,满足 1000 ≤ n , 10000 ≤ m 。
对于 % 100 的数据,满足 1000000 1 ≤ ≤ n , 1000000 0 ≤ ≤ m 。
【问题描述】
!国是一个由”个城市构成的国家。这”个城市从1到”进行编号。其中,城
市1是!国中资源产出最多的城市,而城市”是!国唯一的港口的所在地。由于这
两个城市之间距离很远,所以!国没有直接从城市1向城市”修建道路。不过,
很多城市之间修建了一些单向通行的道路。从城市1经过若干条道路,是可以到
达城市”的。
城市中的单向道路总共有m条,从1到m进行编号。为了方便管理,国家的
统治者希望能把这些道路分成若干组,每组道路的编号都是连续的。同时,出
于一些奇怪的原因,一种合法的分组方式还需要满足:不存在一条从城市1到城
市”的路径,使得路径上的每条道路都属于同一组。
你需要计算:在上述条件的限制下,!国中的道路至少要被分成多少组?
【输入文件】
输入文件为 road. in。
输入文件第一行为两个正整数n,m,分别表示城市数及道路数。
接下来m行,每行两个正整数x,y,表示一条x到y的单向道路。
【输出文件】
输入文件为 road.out。
输出一个正整数,为最少的道路组数.
【输入输出样例】
road.in road.out
3 4
1 2
2 3
1 2
2 3
4
【数据规模和约定】
对于30%的数据,满足N≤ 100,M≤ 100。
对于50%的数据,满足N≤ 2000,M≤ 10000。
对于100%的数据,满足1 ≤N≤ 200000,1 ≤M≤ 500000。
【问题描述】
对于一名DotA玩家,补兵的个数是衡量一名选手的能力的一
项重要指标。特别是在打路人局的时候,补兵的能力就更加关键,因为常常会
有队友和你抢补刀。比如,队友操控的老鹿开着大在收一波兵,你操作的英雄
如果是幽鬼,就需要在老鹿的AOE中偷偷补上几刀来保证自己的发育。
我们可以建立如下模型来大致模拟这种状况:现在有”个小兵,每个小兵都
有自己的血量(血量一定是正整数)。你和老鹿轮流对小兵进行攻击。每次,
你可以选择对某个小兵造成1点伤害(或者你可以选择不造成任何伤害);接
着,老鹿会对所有小兵都造成1点伤害。如此往复,直到所有小兵都死亡(血量
达到0)。在这一过程中,如果你对某个小兵造成了致命伤害(使它的血量由1
变为0),那么你就算成功补到这个兵。
对于给定的情形,你需要计算你的最大补兵数。
【输入文件】
输入文件为 cs.in。
本题含有多组数据,第一行为数据组数T。
对于每组数据,第一行为一个正整数”,第二行为”个正整数,表示每个小
兵的初始血量。
【输出文件】
输入文件为 cs.out。
对于每组数据,输出一行一个整数,表示你的最大补兵数。
【输入输出样例】
cs.in cs.out
1
5
5 5 5 5 5
2
【数据规模和约定】
对于30%的数据,满足N ≤ 100。
对于50%的数据,满足N≤ 500,T≤ 30,每个小兵的血量不超过500。
对于100%的数据,满足1 ≤ N ≤ 1000,1 ≤ T ≤ 70。每个小兵的血量不超
过1000。数据规模有一定的梯度。
T1
我们可以把这个过程倒着模拟。
那么就要用尽量少的操作轮数来得到一个0的序列。
我们可以先把所有的数降序排一下序,然后把0尽量合并,把非零的数都减一。
这里需要说明一下,把非零数都减为零后在合并一定比先把非零数合并后再减更优。
因为非零数越多,每次可减下去的和就越多。
还有一点,把一个非零数和0合并后再减为0,和先把非零数减为0再合并是一样的。
举个例子:
3 3 3 1 1 0 0
演变:
2 2 2 0 0 0
1 1 1 0 0
0 0 0 0
0 0
0
共五次
如此模拟即可。
至于把前面的都减一,我们可以找一个标准,每一轮把这个标准加一。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#define LL long long
using namespace std;
const int N=1000009;
int n,m,a[N],ans,num;
bool cmp(int x,int y)
{
return x>y;
}
int main()
{
freopen("multiset.in","r",stdin);
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
sort(a+1,a+n+1,cmp);
int l=n,r=n;
while(a[l]==0) l--;
int t=1;
//l=min(l,r);
while(r>1)
{
r-=(r-l)/2;
while(a[l]==t) l--;
ans++;t++;
}
printf("%d",ans);
return 0;
}T2
60分可暴力得到。
每次先把新的边加进当前集合,然后bfs一遍,如果1能够到达n,那就把当前集合清空,然后把这条边当做新集合的第一条边。(真的好暴力)
在测试时先打了个并查集,后来找出反例证明出不正确,又重新打的暴力;
评测时,竟然发现,错误的并查集比正确的暴力多得了10分qaq.
100分:在60分的基础上加的优化;
我们可以用倍增的方法来找当前这一段(这个集合)最多能加到哪条边,然后再如此求下一个集合。
还是T了两个点;
看别人有跑得很快的而且也不是倍增的方法,但是看不太懂。
60分
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
#define LL long long
using namespace std;
const int N=200009;
const int M=500009;
int n,m,f[N],ans;
int L,R,mid;
struct H{
int s,t;
}q[M];
int head[N],nxt[M],to[M],tot;
bool vis[N];
void add(int x,int y)
{
to[++tot]=y;
nxt[tot]=head[x];
head[x]=tot;
}
int bfs(int s)
{
queue <int> qu;
memset(vis,0,sizeof(vis));
qu.push(s);
vis[s]=1;
while(!qu.empty())
{
int x=qu.front();
qu.pop();
if(x==n) return 1;
for(int i=head[x];i;i=nxt[i])
{
if(!vis[to[i]])
{
qu.push(to[i]);
vis[to[i]]=1;
}
if(to[i]==n) return 1;
}
}
return 0;
}
int get()
{
int cnt=1;
for(int i=1;i<=m;i++)
{
add(q[i].s,q[i].t);
int can=bfs(1);
if(can)
{
tot=0;
memset(head,0,sizeof(head));
memset(to,0,sizeof(to));
memset(nxt,0,sizeof(nxt));
add(q[i].s,q[i].t);
cnt++;
}
}
return cnt;
}
int main()
{
freopen("road.in","r",stdin);
freopen("road.out","w",stdout);
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++) scanf("%d%d",&q[i].s,&q[i].t);
ans=get();
printf("%d\n",ans);
return 0;
}80分
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
#define LL long long
using namespace std;
const int N=200009;
const int M=500009;
int n,m,ans;
struct H{
int s,t;
}q[M];
int head[N],nxt[M],to[M],tot,tt;
bool vis[N];
void add(int x,int y)
{
to[++tot]=y;
nxt[tot]=head[x];
head[x]=tot;
}
bool bfs(int s)//1能否到达n
{
queue <int> qu;
memset(vis,0,sizeof(vis));
qu.push(s);
vis[s]=1;
while(!qu.empty())
{
int x=qu.front();
qu.pop();
if(x==n) return 1;
for(int i=head[x];i;i=nxt[i])
if(i>tt&&i<=tot)
{
if(!vis[to[i]])
{
qu.push(to[i]);
vis[to[i]]=1;
}
if(to[i]==n) return 1;
}
}
return 0;
}
bool check(int start,int last)
{
//tot=0;
//memset(head,0,sizeof(head));
//memset(to,0,sizeof(to));
//memset(nxt,0,sizeof(nxt));
for(int i=1;i<=n;i++) head[i]=0;
for(int i=1;i<=tot;i++) nxt[i]=to[i]=0;
tot=0;
//tt=tot;
for(int i=start;i<=last;i++)
add(q[i].s,q[i].t);
return bfs(1);
}
int get()
{
int now=1,cnt=0;
while(now<=m)
{
int i;
for(i=1;now+i<=m;i<<=1)//倍增找最远的
if(check(now,now+i)) break;
i>>=1;
int nowx=now+i;
for(;i>0;i>>=1)
{
if(nowx+i<=m&&(!check(now,nowx+i)))
nowx+=i;
}
cnt++;
now=nowx+1;
}
return cnt;
}
int main()
{
freopen("road.in","r",stdin);
freopen("road.out","w",stdout);
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++) scanf("%d%d",&q[i].s,&q[i].t);
ans=get();
printf("%d\n",ans);
return 0;
}根本就是错的并查集(70分)
后面附有反例
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#define LL long long
using namespace std;
const int N=200009;
const int M=500009;
int n,m,f[N],ans;
int L,R,mid;
struct H{
int s,t;
}q[M];
int find(int x)
{
return f[x]==x?x:f[x]=find(f[x]);
}
int get()
{
for(int i=1;i<=n;i++) f[i]=i;
int cnt=1;
for(int i=1;i<=m;i++)
{
int fs=find(q[i].s);
int ft=find(q[i].t);
int ff=find(1);
int fn=find(n);
if(fs==ff&&ft==fn)
{
cnt++;
for(int j=1;j<=n;j++) f[j]=j;
f[q[i].t]=q[i].s;
}
else f[ft]=fs;
}
return cnt;
}
int main()
{
freopen("road.in","r",stdin);
freopen("road.out","w",stdout);
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++) scanf("%d%d",&q[i].s,&q[i].t);
ans=get();
printf("%d\n",ans);
return 0;
}
/*
5
4
1 5
3 5
3 6
4 3
1
*/
//反例T3
正解:dp
测试提交的时候没做到这个题呢qwq.
总结:
T1 搞了近一个小时,终于开始写,别人都写好长时间了;还好最后搞出了正解;noip的时候这样好害怕。
T2 又搞了一个半小时,发现想的不对,匆匆花10分钟打了暴力,辛亏暴力比较好写。
很让我哭笑不得的是,一开始认为想了一个半小时是错的并查集,竟然比暴力多10分。
T3 由于前两个题花去了所有的时间,连暴力也没有打啊。
期望得分:100+60+0
实际得分:100+60+0
还算可以,但是策略还是有风险,继续加油。














 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









