







Kruskal算法
步骤:
第一步:给所有边按照从小到大顺序排列(直接使用库函数qsort / sort)。
第二步:从小到大依次考察每条边(u,v),在执行第二步时会出现以下两种情况:
情况1:u和v在同一连通分量中,加入(u,v)会形成环,因此不能选择。
情况2:u和v在不同的连通分量中,加入(u,v)就一定是最优的。
伪代码:
(1) 把所有的程序排序,记第i小的边为e[i] (1<=i<m)
(2) 初始化MST为空
(3) 初始化连通分量,让每个点自成一个独立的连通分量
for ( int i = 0; i<m; i++)
if(e[i].u和e[i].v不在一个连通分量)
{
把e[i] 加入MST中
合并e[i].u和e[i].v所在的连通分量
}
分析:
该算法关键点在于“连通分量的查询与合并”——需要知道任意两个点是否在同一个连通分量中,还需要合并两个连通分量。
解决方法:
(1) 暴力求解法:
(2) 使用并查集(Union-Find Set)
代码:(使用并查集方法)
//Kruskal算法
//假设第i条边的两个端点序号和权值分别保存在u[i],v[i]和w[i]中
//排序后第i小的边的序号保存在r[i]中
int cmp(const int i,const int j) //间接排序函数
{
return w[i]<w[j];
}
int find(int x) //并查集的find
{
return p[x] == x ? x : p[x] = find(p[x]);//如果 p[x] = x,说明x本身是树根,因此返回x;否则返回p[x]的父节点所在树的树根
}
int Kruskal()
{
int ans = 0;
for(int i = 0;i < n;i++)//初始化并查集
p[i]=i;
for(int i = 0;i < m;i++)//初始化边序号
r[i]=i;
sort(r ,r+m ,cmp);//给边排序
for(int i = 0; i<m; i++)
{
int e = r[i]; int x = find(u[e]); //找出当前边两个端点所在的集合编号
int y = find(v[e]);
if(x !=y)//如果在不同集合合并
{
ans += w[e];
p[x] = y;
}
}
}并查集:(Union-Find Set)
原理:
使用树来表示集合,树的每个节点就表示集合中的一个元素,树根对应的元素就是该集合的代表元(representative).
特点:
每个连通分量看作是一个集合,该集合包含了连通分量的所有点。这些点两两相通,具体的连接方式无关紧要。
基本操作:
- makeSet(s):建立一个新的并查集,其中包含 s 个单元素集合。
- unionSet(x, y):把元素 x 和元素 y 所在的集合合并,要求 x 和 y 所在的集合不相交,如果相交则不合并。
- find(x):找到元素 x 所在的集合的代表元(即父节点),该操作也可以用于判断两个元素是否位于同一个集合,只要将它们各自的代表比较一下就可以了。
int find(int x)
{ p[x] == x ? x : p[x] = find(p[x]);}如果 p[x] = x,说明x本身是树根,因此返回x;否则返回p[x]的父节点所在树的树根。
特殊情况下:一棵树是一个长长的链,链的最后一个节点为x。
在执行find函数时:每次执行find(x)都会遍历整条链,效率低下。
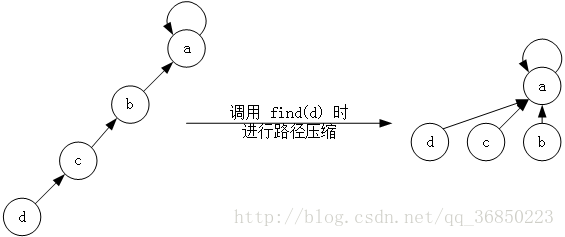
根据并查集的特点:连通分量中点两两相通,具体的连接方式无关紧要。即树的形态无关紧要。可以做出优化---并查集中的路径压缩
路径压缩:
并查集在每次查找时,令查找路径上的每个节点都直接指向根节点。














 5029
5029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









