







分析MapReduce执行过程
MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到HDFS的文件中。整个流程如图:

Mapper任务的执行过程详解
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper任务的处理过程又可以分为以下几个阶段,如图所示。

在上图中,把Mapper任务的运行过程分为六个阶段。
-
第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。
-
第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
-
第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。
-
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
-
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。
-
第六阶段是对数据进行归约处理,也就是reduce处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
Reducer任务的执行过程详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。

-
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
-
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
-
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
在整个MapReduce程序的开发过程中,我们最大的工作量是覆盖map函数和覆盖reduce函数。
键值对的编号
在对Mapper任务、Reducer任务的分析过程中,会看到很多阶段都出现了键值对,读者容易混淆,所以这里对键值对进行编号,方便大家理解键值对的变化情况,如下图所示。

在上图中,对于Mapper任务输入的键值对,定义为key1和value1。在map方法中处理后,输出的键值对,定义为key2和value2。reduce方法接收key2和value2,处理后,输出key3和value3。在下文讨论键值对时,可能把key1和value1简写为<k1,v1>,key2和value2简写为<k2,v2>,key3和value3简写为<k3,v3>。
以上内容来自:http://www.superwu.cn/2013/08/21/530/
-----------------------分------------------割----------------线-------------------------
例子:求每年最高气温
在HDFS中的根目录下有以下文件格式: /input.txt
2014010114
2014010216
2014010317
2014010410
2014010506
2012010609
2012010732
2012010812
2012010919
2012011023
2001010116
2001010212
2001010310
2001010411
2001010529
2013010619
2013010722
2013010812
2013010929
2013011023
2008010105
2008010216
2008010337
2008010414
2008010516
2007010619
2007010712
2007010812
2007010999
2007011023
2010010114
2010010216
2010010317
2010010410
2010010506
2015010649
2015010722
2015010812
2015010999
2015011023 比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用MapReduce,计算每一年出现过的最大气温。
在写代码之前,先确保正确的导入了相关的jar包。我使用的是maven,可以到http://mvnrepository.com去搜索这几个artifactId。
此程序需要以Hadoop文件作为输入文件,以Hadoop文件作为输出文件,因此需要用到文件系统,于是需要引入hadoop-hdfs包;我们需要向Map-Reduce集群提交任务,需要用到Map-Reduce的客户端,于是需要导入hadoop-mapreduce-client-jobclient包;另外,在处理数据的时候会用到一些hadoop的数据类型例如IntWritable和Text等,因此需要导入hadoop-common包。于是运行此程序所需要的相关依赖有以下几个:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.4.0</version>
</dependency>包导好了后, 设计代码如下:
package com.abc.yarn;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Temperature {
/**
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份”
* ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温”
*/
static class TempMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 打印样本: Before Mapper: 0, 2000010115
System.out.print("Before Mapper: " + key + ", " + value);
String line = value.toString();
String year = line.substring(0, 4);
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
// 打印样本: After Mapper:2000, 15
System.out.println(
"======" +
"After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
}
/**
* 四个泛型类型分别代表:
* KeyIn Reducer的输入数据的Key,这里是每行文字中的“年份”
* ValueIn Reducer的输入数据的Value,这里是每行文字中的“气温”
* KeyOut Reducer的输出数据的Key,这里是不重复的“年份”
* ValueOut Reducer的输出数据的Value,这里是这一年中的“最高气温”
*/
static class TempReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
//取values的最大值
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
sb.append(value).append(", ");
}
// 打印样本: Before Reduce: 2000, 15, 23, 99, 12, 22,
System.out.print("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
// 打印样本: After Reduce: 2000, 99
System.out.println(
"======" +
"After Reduce: " + key + ", " + maxValue);
}
}
public static void main(String[] args) throws Exception {
//输入路径
String dst = "hdfs://localhost:9000/intput.txt";
//输出路径,必须是不存在的,空文件加也不行。
String dstOut = "hdfs://localhost:9000/output";
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
);
hadoopConfig.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem.class.getName()
);
Job job = new Job(hadoopConfig);
//如果需要打成jar运行,需要下面这句
//job.setJarByClass(NewMaxTemperature.class);
//job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
//指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
//设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//执行job,直到完成
job.waitForCompletion(true);
System.out.println("Finished");
}
}上面代码中,注意Mapper类的泛型不是java的基本类型,而是Hadoop的数据类型Text、IntWritable。我们可以简单的等价为java的类String、int。
代码中Mapper类的泛型依次是<k1,v1,k2,v2>。map方法的第二个形参是行文本内容,是我们关心的。核心代码是把行文本内容按照空格拆分,把每行数据中“年”和“气温”提取出来,其中“年”作为新的键,“温度”作为新的值,写入到上下文context中。在这里,因为每一年有多行数据,因此每一行都会输出一个<年份, 气温>键值对。
下面是控制台打印结果:
Before Mapper: 0, 2014010114======After Mapper:2014, 14
Before Mapper: 11, 2014010216======After Mapper:2014, 16
Before Mapper: 22, 2014010317======After Mapper:2014, 17
Before Mapper: 33, 2014010410======After Mapper:2014, 10
Before Mapper: 44, 2014010506======After Mapper:2014, 6
Before Mapper: 55, 2012010609======After Mapper:2012, 9
Before Mapper: 66, 2012010732======After Mapper:2012, 32
Before Mapper: 77, 2012010812======After Mapper:2012, 12
Before Mapper: 88, 2012010919======After Mapper:2012, 19
Before Mapper: 99, 2012011023======After Mapper:2012, 23
Before Mapper: 110, 2001010116======After Mapper:2001, 16
Before Mapper: 121, 2001010212======After Mapper:2001, 12
Before Mapper: 132, 2001010310======After Mapper:2001, 10
Before Mapper: 143, 2001010411======After Mapper:2001, 11
Before Mapper: 154, 2001010529======After Mapper:2001, 29
Before Mapper: 165, 2013010619======After Mapper:2013, 19
Before Mapper: 176, 2013010722======After Mapper:2013, 22
Before Mapper: 187, 2013010812======After Mapper:2013, 12
Before Mapper: 198, 2013010929======After Mapper:2013, 29
Before Mapper: 209, 2013011023======After Mapper:2013, 23
Before Mapper: 220, 2008010105======After Mapper:2008, 5
Before Mapper: 231, 2008010216======After Mapper:2008, 16
Before Mapper: 242, 2008010337======After Mapper:2008, 37
Before Mapper: 253, 2008010414======After Mapper:2008, 14
Before Mapper: 264, 2008010516======After Mapper:2008, 16
Before Mapper: 275, 2007010619======After Mapper:2007, 19
Before Mapper: 286, 2007010712======After Mapper:2007, 12
Before Mapper: 297, 2007010812======After Mapper:2007, 12
Before Mapper: 308, 2007010999======After Mapper:2007, 99
Before Mapper: 319, 2007011023======After Mapper:2007, 23
Before Mapper: 330, 2010010114======After Mapper:2010, 14
Before Mapper: 341, 2010010216======After Mapper:2010, 16
Before Mapper: 352, 2010010317======After Mapper:2010, 17
Before Mapper: 363, 2010010410======After Mapper:2010, 10
Before Mapper: 374, 2010010506======After Mapper:2010, 6
Before Mapper: 385, 2015010649======After Mapper:2015, 49
Before Mapper: 396, 2015010722======After Mapper:2015, 22
Before Mapper: 407, 2015010812======After Mapper:2015, 12
Before Mapper: 418, 2015010999======After Mapper:2015, 99
Before Mapper: 429, 2015011023======After Mapper:2015, 23
Before Reduce: 2001, 12, 10, 11, 29, 16, ======After Reduce: 2001, 29
Before Reduce: 2007, 23, 19, 12, 12, 99, ======After Reduce: 2007, 99
Before Reduce: 2008, 16, 14, 37, 16, 5, ======After Reduce: 2008, 37
Before Reduce: 2010, 10, 6, 14, 16, 17, ======After Reduce: 2010, 17
Before Reduce: 2012, 19, 12, 32, 9, 23, ======After Reduce: 2012, 32
Before Reduce: 2013, 23, 29, 12, 22, 19, ======After Reduce: 2013, 29
Before Reduce: 2014, 14, 6, 10, 17, 16, ======After Reduce: 2014, 17
Before Reduce: 2015, 23, 49, 22, 12, 99, ======After Reduce: 2015, 99
Finished 执行结果:

对分析的验证
从打印的日志中可以看出:
-
Mapper的输入数据(k1,v1)格式是:默认的按行分的键值对<0, 2010012325>,<11, 2012010123>...
-
Reducer的输入数据格式是:把相同的键合并后的键值对:<2001, [12, 32, 25...]>,<2007, [20, 34, 30...]>...
-
Reducer的输出数(k3,v3)据格式是:经自己在Reducer中写出的格式:<2001, 32>,<2007, 34>...
其中,由于输入数据太小,Map过程的第1阶段这里不能证明。但事实上是这样的。
结论中第一点验证了Map过程的第2阶段:“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
另外,通过Reduce的几行
Before Reduce: 2001, 12, 10, 11, 29, 16, ======After Reduce: 2001, 29
Before Reduce: 2007, 23, 19, 12, 12, 99, ======After Reduce: 2007, 99
Before Reduce: 2008, 16, 14, 37, 16, 5, ======After Reduce: 2008, 37
Before Reduce: 2010, 10, 6, 14, 16, 17, ======After Reduce: 2010, 17
Before Reduce: 2012, 19, 12, 32, 9, 23, ======After Reduce: 2012, 32
Before Reduce: 2013, 23, 29, 12, 22, 19, ======After Reduce: 2013, 29
Before Reduce: 2014, 14, 6, 10, 17, 16, ======After Reduce: 2014, 17
Before Reduce: 2015, 23, 49, 22, 12, 99, ======After Reduce: 2015, 99 可以证实Map过程的第4阶段:先分区,然后对每个分区都执行一次Reduce(Map过程第6阶段)。
对于Mapper的输出,前文中提到:如果没有Reduce过程,Mapper的输出会直接写入文件。于是我们把Reduce方法去掉(注释掉第95行即可)。
再执行,下面是控制台打印结果:
Before Mapper: 0, 2014010114======After Mapper:2014, 14
Before Mapper: 11, 2014010216======After Mapper:2014, 16
Before Mapper: 22, 2014010317======After Mapper:2014, 17
Before Mapper: 33, 2014010410======After Mapper:2014, 10
Before Mapper: 44, 2014010506======After Mapper:2014, 6
Before Mapper: 55, 2012010609======After Mapper:2012, 9
Before Mapper: 66, 2012010732======After Mapper:2012, 32
Before Mapper: 77, 2012010812======After Mapper:2012, 12
Before Mapper: 88, 2012010919======After Mapper:2012, 19
Before Mapper: 99, 2012011023======After Mapper:2012, 23
Before Mapper: 110, 2001010116======After Mapper:2001, 16
Before Mapper: 121, 2001010212======After Mapper:2001, 12
Before Mapper: 132, 2001010310======After Mapper:2001, 10
Before Mapper: 143, 2001010411======After Mapper:2001, 11
Before Mapper: 154, 2001010529======After Mapper:2001, 29
Before Mapper: 165, 2013010619======After Mapper:2013, 19
Before Mapper: 176, 2013010722======After Mapper:2013, 22
Before Mapper: 187, 2013010812======After Mapper:2013, 12
Before Mapper: 198, 2013010929======After Mapper:2013, 29
Before Mapper: 209, 2013011023======After Mapper:2013, 23
Before Mapper: 220, 2008010105======After Mapper:2008, 5
Before Mapper: 231, 2008010216======After Mapper:2008, 16
Before Mapper: 242, 2008010337======After Mapper:2008, 37
Before Mapper: 253, 2008010414======After Mapper:2008, 14
Before Mapper: 264, 2008010516======After Mapper:2008, 16
Before Mapper: 275, 2007010619======After Mapper:2007, 19
Before Mapper: 286, 2007010712======After Mapper:2007, 12
Before Mapper: 297, 2007010812======After Mapper:2007, 12
Before Mapper: 308, 2007010999======After Mapper:2007, 99
Before Mapper: 319, 2007011023======After Mapper:2007, 23
Before Mapper: 330, 2010010114======After Mapper:2010, 14
Before Mapper: 341, 2010010216======After Mapper:2010, 16
Before Mapper: 352, 2010010317======After Mapper:2010, 17
Before Mapper: 363, 2010010410======After Mapper:2010, 10
Before Mapper: 374, 2010010506======After Mapper:2010, 6
Before Mapper: 385, 2015010649======After Mapper:2015, 49
Before Mapper: 396, 2015010722======After Mapper:2015, 22
Before Mapper: 407, 2015010812======After Mapper:2015, 12
Before Mapper: 418, 2015010999======After Mapper:2015, 99
Before Mapper: 429, 2015011023======After Mapper:2015, 23
Finished 再来看看执行结果:

结果还有很多行,没有截图了。
由于没有执行Reduce操作,因此这个就是Mapper输出的中间文件的内容了。
从打印的日志可以看出:
-
Mapper的输出数据(k2, v2)格式是:经自己在Mapper中写出的格式:<2010, 25>,<2012, 23>...
从这个结果中可以看出,原数据文件中的每一行确实都有一行输出,那么Map过程的第3阶段就证实了。
从这个结果中还可以看出,“年份”已经不是输入给Mapper的顺序了,这也说明了在Map过程中也按照Key执行了排序操作,即Map过程的第5阶段。
下面对上面出现的一些名词进行介绍
ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
NodeManager:简称NM,NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager提供这些资源使用报告。
ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动container,并告诉container做什么事情。
Container:资源容器。YARN中所有的应用都是在container之上运行的。AM也是在container上运行的,不过AM的container是RM申请的。
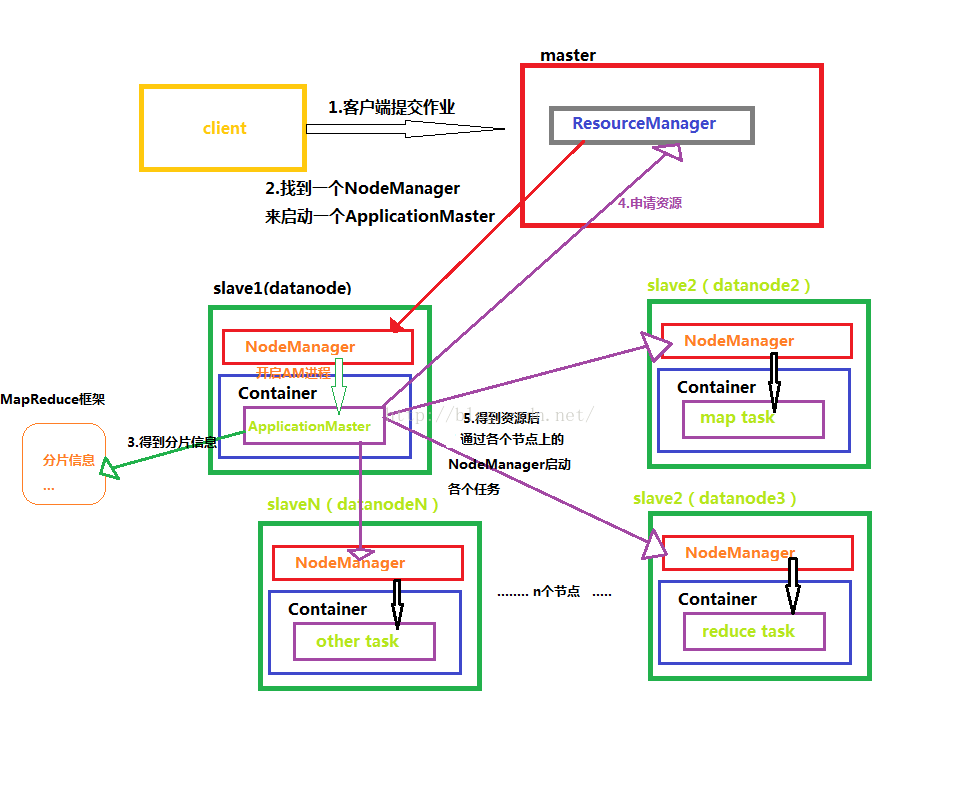
1. Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。
2. Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster;3. Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
整个MapReduce的过程大致分为 Map-->Shuffle(排序)-->Combine(组合)-->Reduce
下面通过一个单词计数案例来理解各个过程
1)将文件拆分成splits(片),并将每个split按行分割形成<key,value>对,如图所示。这一步由MapReduce框架自动完成,其中偏移量即key值
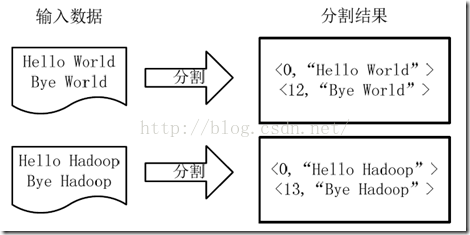
分割过程
将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示。
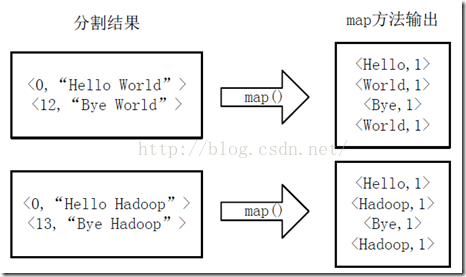
执行map方法
得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行Shuffle(排序),并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如下图所示。
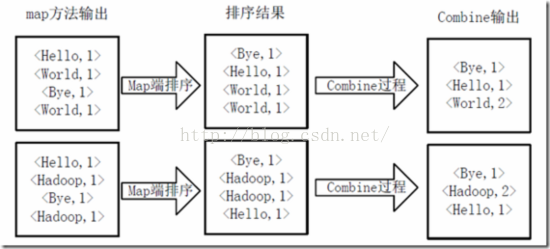
Map端排序及Combine过程
Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图所示。
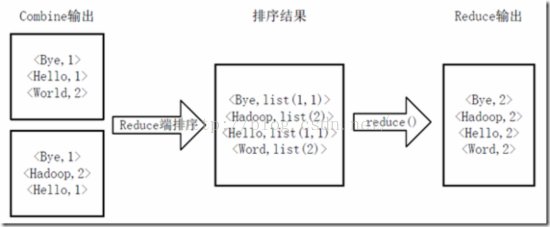
Reduce端排序及输出结果
下面看怎么用Java来实现WordCount单词计数的功能
首先看Map过程
Map过程需要继承org.apache.hadoop.mapreduce.Mapper包中 Mapper 类,并重写其map方法。
Reduce过程
Reduce过程需要继承org.apache.hadoop.mapreduce包中 Reducer 类,并 重写 其reduce方法。Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
最后执行MapReduce任务
即可求得每个单词的个数
下面把整个过程的源码附上,有需要的朋友可以拿去测试
mapreduce的原理
MapReduce借鉴了函数式程序设计语言Lisp中的思想,Lisp(List processing)是一种列表处理语言,可对列表元素进行整体处理。
如:(add #(1 2 3 4) #(4 3 2 1)) 将产生结果:#(5 5 5 5)
mapreduce之所以和lisp类似,是因为mapreduce在最后的 reduce阶段也是以key为分组进行列的运算。
下面这幅图就是mapreduce的工作原理
1)首先文档的数据记录(如文本中的行,或数据表格中的行)是以“键值对”的形式传入map 函数,然后map函数对这些键值对进行处理(如统计词频),然后输出到中间结果。
2)在键值对进入reduce进行处理之前,必须等到所有的map函数都做完,所以既为了达到这种同步又提高运行效率,在mapreduce中间的过程引入了barrier(同步障)
在负责同步的同时完成对map的中间结果的统计,包括 a. 对同一个map节点的相同key的value值进行合并,b. 之后将来自不同map的具有相同的key的键值对送到同一个reduce进行处理。
3)在reduce阶段,每个reduce节点得到的是从所有map节点传过来的具有相同的key的键值对。reduce节点对这些键值进行合并。
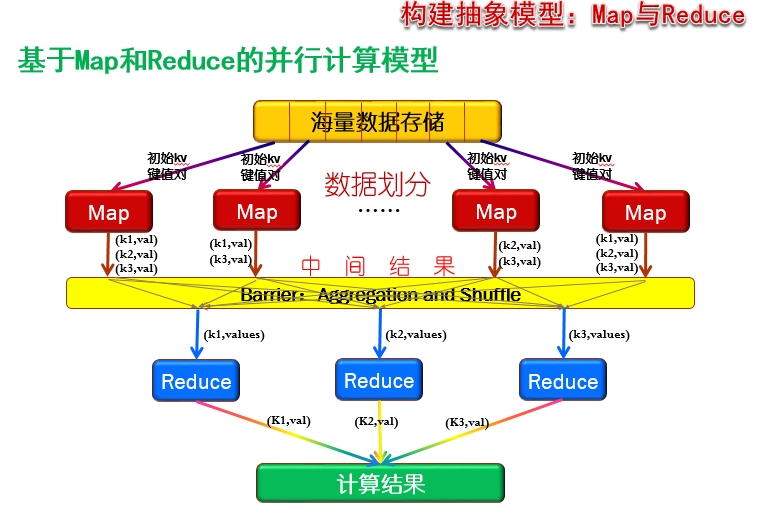
以词频统计为例。
词频统计就是统计一个单词在所有文本中出现的次数,在hadoop中的事例程序就是wordcount,俗称hadoop编程的"hello world".
因为我们有多个文本,所以可以并行的统计每个文本中单词出现的个数,然后最后进行合计。
所以这个可以很好地体现map,reduce的过程。
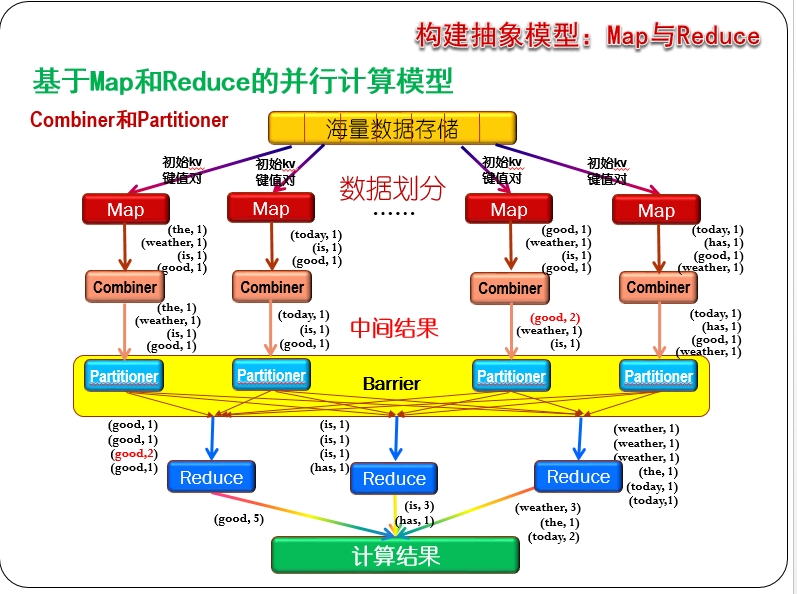
可以发现,这张图是上面那张图的进一步细化,主要体现在:
1)Combiner 节点负责完成上面提到的将同一个map中相同的key进行合并,避免重复传输,从而减少传输中的通信开销。
2)Partitioner节点负责将map产生的中间结果进行划分,确保相同的key到达同一个reduce节点.
1、向client端提交MapReduce job.
2、随后yarn的ResourceManager进行资源的分配.
3、由NodeManager进行加载与监控containers.
4、通过applicationMaster与ResourceManager进行资源的申请及状态的交互,由NodeManagers进行MapReduce运行时job的管理.
5、通过hdfs进行job配置文件、jar包的各节点分发。

Job 提交过程
job的提交通过调用submit()方法创建一个JobSubmitter实例,并调用submitJobInternal()方法。整个job的运行过程如下:
1、向ResourceManager申请application ID,此ID为该MapReduce的jobId。
2、检查output的路径是否正确,是否已经被创建。
3、计算input的splits。
4、拷贝运行job 需要的jar包、配置文件以及计算input的split 到各个节点。
5、在ResourceManager中调用submitAppliction()方法,执行job
Job 初始化过程
1、当resourceManager收到了submitApplication()方法的调用通知后,scheduler开始分配container,随之ResouceManager发送applicationMaster进程,告知每个nodeManager管理器。
2、由applicationMaster决定如何运行tasks,如果job数据量比较小,applicationMaster便选择将tasks运行在一个JVM中。那么如何判别这个job是大是小呢?当一个job的mappers数量小于10个,只有一个reducer或者读取的文件大小要小于一个HDFS block时,(可通过修改配置项mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces以及mapreduce.job.ubertask.maxbytes 进行调整)
3、在运行tasks之前,applicationMaster将会调用setupJob()方法,随之创建output的输出路径(这就能够解释,不管你的mapreduce一开始是否报错,输出路径都会创建)
Task 任务分配
1、接下来applicationMaster向ResourceManager请求containers用于执行map与reduce的tasks(step 8),这里map task的优先级要高于reduce task,当所有的map tasks结束后,随之进行sort(这里是shuffle过程后面再说),最后进行reduce task的开始。(这里有一点,当map tasks执行了百分之5%的时候,将会请求reduce,具体下面再总结)
2、运行tasks的是需要消耗内存与CPU资源的,默认情况下,map和reduce的task资源分配为1024MB与一个核,(可修改运行的最小与最大参数配置,mapreduce.map.memory.mb,mapreduce.reduce.memory.mb,mapreduce.map.cpu.vcores,mapreduce.reduce.reduce.cpu.vcores.)
Task 任务执行
1、这时一个task已经被ResourceManager分配到一个container中,由applicationMaster告知nodemanager启动container,这个task将会被一个主函数为YarnChild的java application运行,但在运行task之前,首先定位task需要的jar包、配置文件以及加载在缓存中的文件。
2、YarnChild运行于一个专属的JVM中,所以任何一个map或reduce任务出现问题,都不会影响整个nodemanager的crash或者hang。
3、每个task都可以在相同的JVM task中完成,随之将完成的处理数据写入临时文件中。
Mapreduce数据流
运行进度与状态更新
1、MapReduce是一个较长运行时间的批处理过程,可以是一小时、几小时甚至几天,那么Job的运行状态监控就非常重要。每个job以及每个task都有一个包含job(running,successfully completed,failed)的状态,以及value的计数器,状态信息及描述信息(描述信息一般都是在代码中加的打印信息),那么,这些信息是如何与客户端进行通信的呢?
2、当一个task开始执行,它将会保持运行记录,记录task完成的比例,对于map的任务,将会记录其运行的百分比,对于reduce来说可能复杂点,但系统依旧会估计reduce的完成比例。当一个map或reduce任务执行时,子进程会持续每三秒钟与applicationMaster进行交互。
Job 完成
最终,applicationMaster会收到一个job完成的通知,随后改变job的状态为successful。最终,applicationMaster与task containers被清空。
Shuffle与Sort
从map到reduce的过程,被称之为shuffle过程,MapReduce使到reduce的数据一定是经过key的排序的,那么shuffle是如何运作的呢?
当map任务将数据output时,不仅仅是将结果输出到磁盘,它是将其写入内存缓冲区域,并进行一些预分类。

1、The Map Side
首先map任务的output过程是一个环状的内存缓冲区,缓冲区的大小默认为100MB(可通过修改配置项mpareduce.task.io.sort.mb进行修改),当写入内存的大小到达一定比例,默认为80%(可通过mapreduce.map.sort.spill.percent配置项修改),便开始写入磁盘。
在写入磁盘之前,线程将会指定数据写入与reduce相应的patitions中,最终传送给reduce.在每个partition中,后台线程将会在内存中进行Key的排序,(如果代码中有combiner方法,则会在output时就进行sort排序,这里,如果只有少于3个写入磁盘的文件,combiner将会在outputfile前启动,如果只有一个或两个,那么将不会调用)
这里将map输出的结果进行压缩会大大减少磁盘IO与网络传输的开销(配置参数mapreduce.map .output.compress 设置为true,如果使用第三方压缩jar,可通过mapreduce.map.output.compress.codec进行设置)
随后这些paritions输出文件将会通过HTTP发送至reducers,传送的最大启动线程通过mapreduce.shuffle.max.threads进行配置。
2、The Reduce Side
首先上面每个节点的map都将结果写入了本地磁盘中,现在reduce需要将map的结果通过集群拉取过来,这里要注意的是,需要等到所有map任务结束后,reduce才会对map的结果进行拷贝,由于reduce函数有少数几个复制线程,以至于它可以同时拉取多个map的输出结果。默认的为5个线程(可通过修改配置mapreduce.reduce.shuffle.parallelcopies来修改其个数)
这里有个问题,那么reducers怎么知道从哪些机器拉取数据呢?
当所有map的任务结束后,applicationMaster通过心跳机制(heartbeat mechanism),由它知道mapping的输出结果与机器host,所以reducer会定时的通过一个线程访问applicationmaster请求map的输出结果。
Map的结果将会被拷贝到reduce task的JVM的内存中(内存大小可在mapreduce.reduce.shuffle.input.buffer.percent中设置)如果不够用,则会写入磁盘。当内存缓冲区的大小到达一定比例时(可通过mapreduce.reduce.shuffle.merge.percent设置)或map的输出结果文件过多时(可通过配置mapreduce.reduce.merge.inmen.threshold),将会除法合并(merged)随之写入磁盘。















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









