







背景
项目使用了阿里druid jdbc连接池。某天环境出现网络波动,持续20分钟后,网络恢复,单服务一直无法连接数据库。重启之后正常运行
druid 版本:1.1.21
项目配置
spring.datasource.druid.game.driver-class-name = com.mysql.cj.jdbc.Driver
spring.datasource.druid.game.initial-size = 5
spring.datasource.druid.game.min-idle = 5
spring.datasource.druid.game.max-active = 100
spring.datasource.druid.game.max-wait = 30000
spring.datasource.druid.game.time-between-eviction-runs-millis = 60000
spring.datasource.druid.game.min-evictable-idle-time-millis = 300000
spring.datasource.druid.game.validationQuery = SELECT 'x'
spring.datasource.druid.game.test-while-idle = true
spring.datasource.druid.game.test-on-borrow = false
spring.datasource.druid.game.test-on-return = false
spring.datasource.druid.game.poolPreparedStatements = true
spring.datasource.druid.game.maxPoolPreparedStatementPerConnectionSize = 20
spring.datasource.druid.game.maxOpenPreparedStatements = 20
Druid的Bug现场
翻看当时日志,发现大量CannotGetJdbcConnectionException异常日:
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 100, creating 1, createElapseMillis 686180, createErrorCount 3
Caused by: org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 100, creating 1, createElapseMillis 686180, createErrorCount 3
### The error may exist in class path resource [mapper/SysDictMapper.xml]
### The error may involve com.stnts.suileyoo.game.api.dao.SysDictDao.select
### The error occurred while executing a query
### Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 100, creating 1, createElapseMillis 686180, createErrorCount 3
at org.apache.ibatis.exceptions.ExceptionFactory.wrapException(ExceptionFactory.java:30)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:149)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:140)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectOne(DefaultSqlSession.java:76)
at sun.reflect.GeneratedMethodAccessor135.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:426)
... 95 common frames omitted
Caused by: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 100, creating 1, createElapseMillis 686180, createErrorCount 3
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:82)
at org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:80)
at org.mybatis.spring.transaction.SpringManagedTransaction.getConnection(SpringManagedTransaction.java:67)
at org.apache.ibatis.executor.BaseExecutor.getConnection(BaseExecutor.java:336)
at org.apache.ibatis.executor.SimpleExecutor.prepareStatement(SimpleExecutor.java:86)
at org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:62)
at org.apache.ibatis.executor.BaseExecutor.queryFromDatabase(BaseExecutor.java:324)
at org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:156)
at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:109)
at org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:83)
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectList(DefaultSqlSession.java:147)
... 101 common frames omitted
Caused by: com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 100, creating 1, createElapseMillis 686180, createErrorCount 3
at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1722)
at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1402)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1382)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1372)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:109)
at org.springframework.jdbc.datasource.DataSourceUtils.fetchConnection(DataSourceUtils.java:158)
at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:116)
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:79)
... 111 common frames omittedBug定位
系统是通过Druid连接
获取连接超时(GetConnectionTimeoutException)此错误的出现,只有两种可能:
1.业务系统本身Druid获取连接失败。
2.网络有问题或者数据库不可用。
在这个Bug里面很明显是Druid创建连接失败,原因如下:
1.之前网络的确有问题,单已恢复,另外还有另外一个服务也是访问这个数据库的。但是那个访问正常。
2.重启服务之后一切正常。
如果说还是网络连接异常,那么并不能解释重启后正常这一现象。
Druid获取连接的过程
在分析这个问题之前,先得看下Druid是如何创建连接的,下面是本人在上网查找到的,示意图:
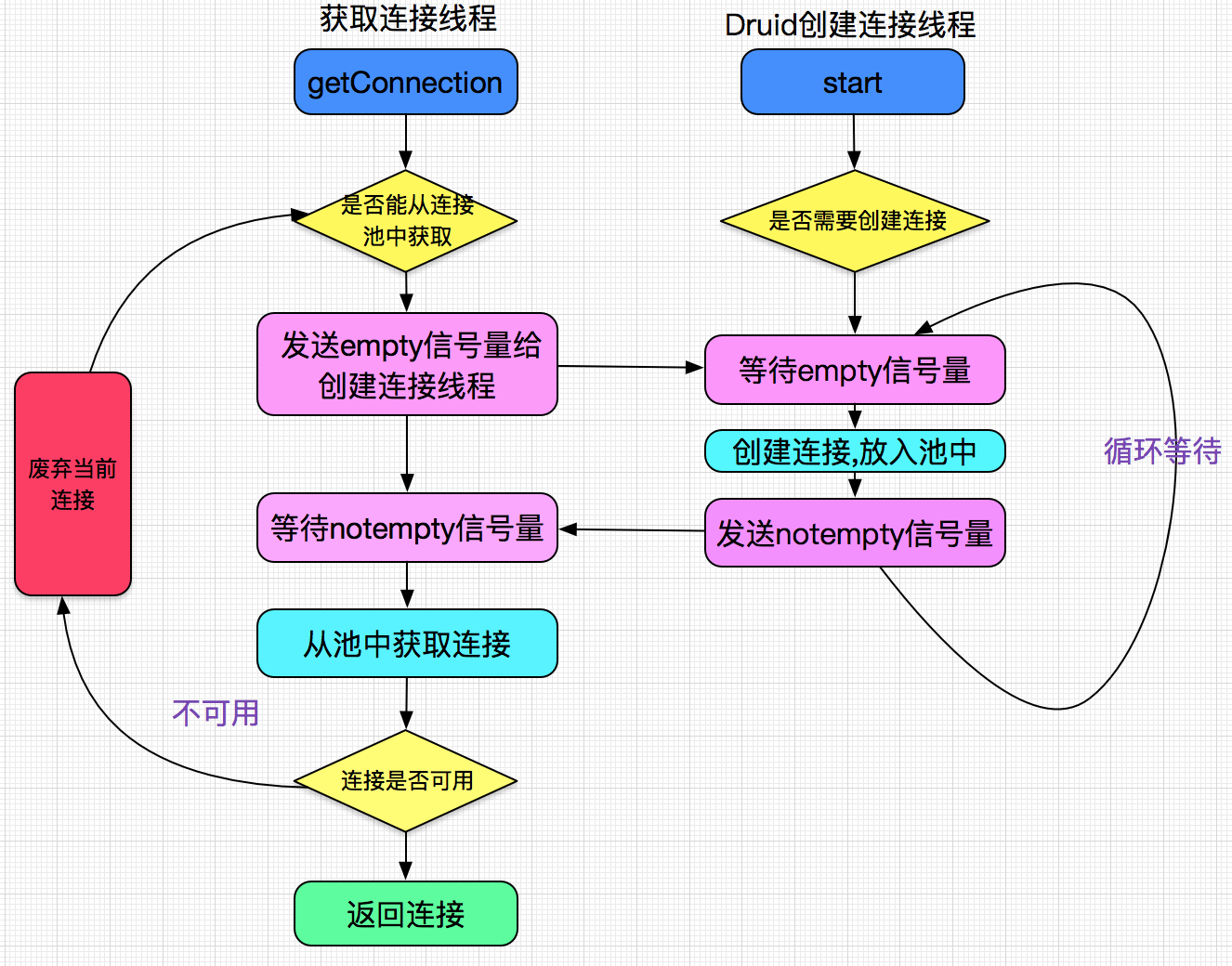
(备注:来源 https://my.oschina.net/alchemystar/blog/899987)
可见druid创建连接都是通过一个专门的线程来进行的,此图省略了大量的源码细节。
然后对比DruidDataSource源码,验证了的确是上图所示的流程。
定位源码
根据日志“
Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 0, maxActive 100, creating 1, createElapseMillis 686180, createErrorCount 3
”,发现日志打印位置,如下图:
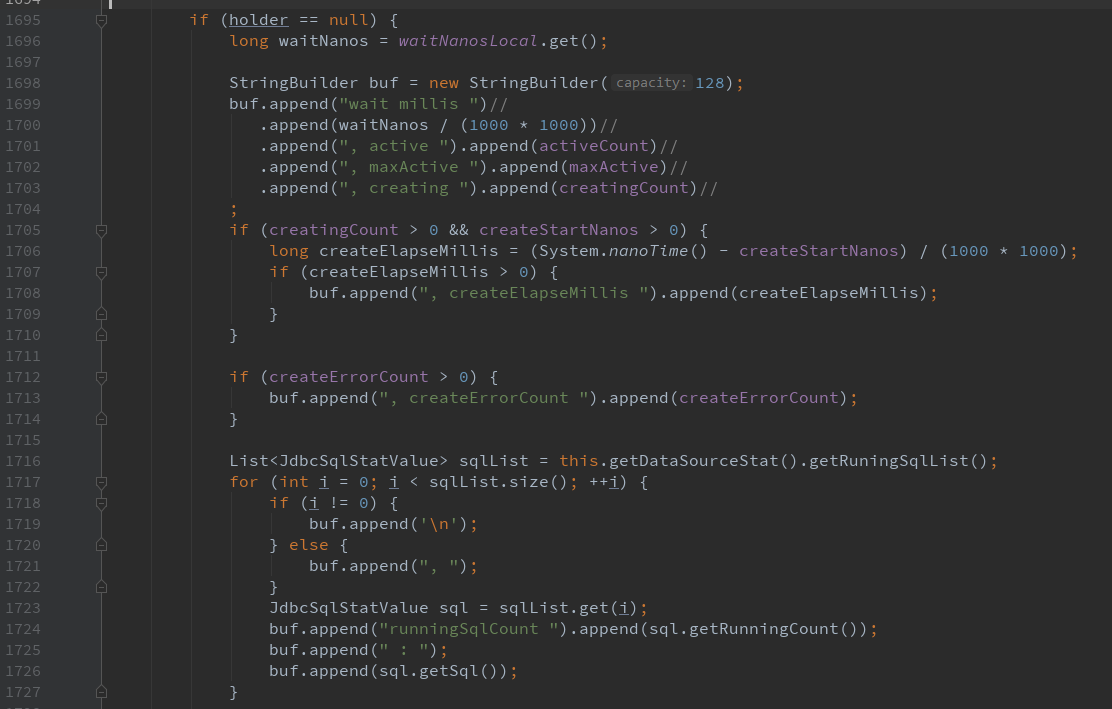
holder == null 是关键。然后查找holder是如果被赋值的,经查找源码,发现其如下图:
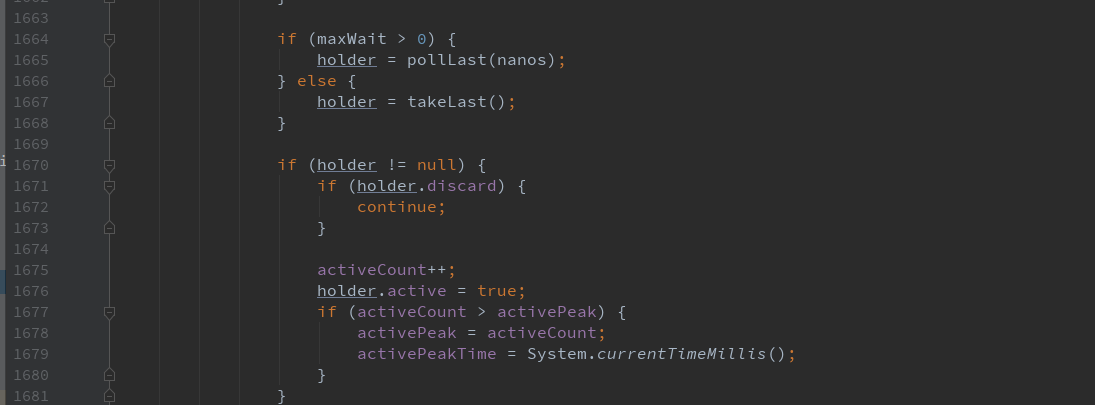
因为已经配置过maxWait属性,故定位到pollLast方法中,再结合druid连接流程,找到CreateConnectionTask的runInternal方法。仔细阅读发现如下逻辑

经过比对日志输出,最终发现创建连接时,没有创建就直接返回了。真相了,原来是未设置keepAlive属性导致的。。。。。泪奔
起伏
已经定位到了问题,但是在查找资料的过程中,发现有人说在1.1.21版本中配置了keepAlive也是出现类似的情况
详见https://github.com/alibaba/druid/issues/3889
后查找druid发版日志,找到如下日志:
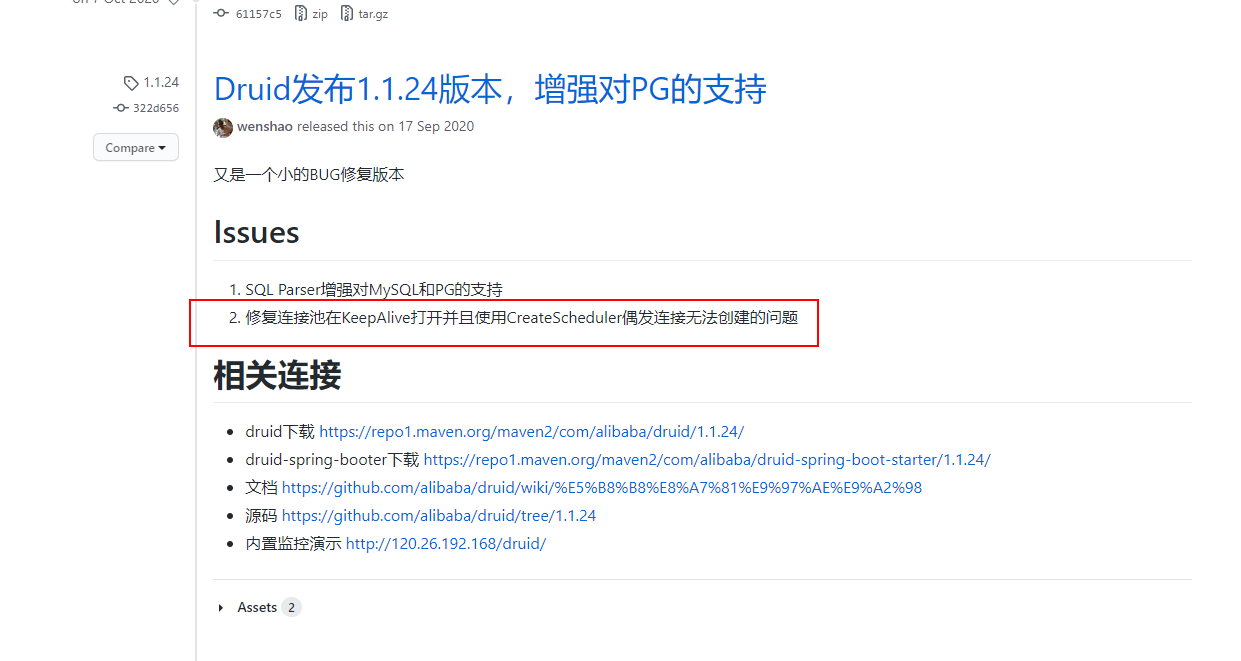
随将druid版本到1.1.24版本,但是发现日志中会频繁出现“discard long time none received connection”的错误日志。然后进一步查找相关问题,找到下面的一篇文章https://gitee.com/y_project/RuoYi-Vue/issues/I1XWZE?_from=gitee_search
此错误不影响链接数据库,去除需要设置System.setProperty("druid.mysql.usePingMethod", "false"); 因为采用的spring-boot,随将这行代码加入到Application的main方法中,经测试之后,已无此错误日志频繁出现的问题。
解决
最终,升级druid版本到1.1.24版本,另外在配置中增加了keepAlive属性,并在Application的main方法中加入System.setProperty("druid.mysql.usePingMethod", "false");
题外
不配置maxWait可能带了的BUG https://zhuanlan.zhihu.com/p/144446516














 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









