







Spark Streaming 动态读取配置
为什么要动态读取配置?
在Spark 流式计算业务中, 比如通常复杂事件处理 (CEP) 的规则或者黑白名单一些配置数据. 当application 在运行期间读取相应的配置文件, 这个时候当这些名单发生改变时, 怎样能让application 动态的获取配置.
目前一般采用采用两种实现方式:
-
轮询拉取方式,即作业算子定时或其他方式检测在外部系统的配置是否有变更,若有则同步配置。
-
控制流方式,即作业除了用于计算的一个或多个普通数据流以外,还有提供一个用于改变作业算子状态的元数据流,也就是控制流。
目前一般Sparkstreaming 使用类似轮询的方式来实现, Flink使用控制流的方式
Sparkstreaming 实现的几种具体方式
Spark Streaming 为用户提供了 Broadcast Varialbe,可以用于节点算子状态的初始化和后续更新。
- 通过广播变量, 并通过设置 TTL 来定时更新.
- 通过在每一个batch计算前 get 配置变量来实现.
- 通过一种方式使当配置数据改变时再去通过广播变量更新. 比如: 启动一个线程监听 或 其他方式
在程序什么地方获取配置数据 — 通过执行过程
1. 执行流程 — spark on yarn client

- Client 向Resource Manager 申请启动 Application Master, 同时并初始化SparkContext
- RM 根据 NM 节点资源情况分配一个Container 并在该Container中启动 Application Master
- SparkContext 初始化完成之后会与AM 通信, 告诉AM 所需资源情况, AM从RM 去申请资源.
- AM 得到RM 回复后, 通知在相应的NM Container 中启动executor
- SparkContext将taskSet 分配给executor 执行worker
2. 程序的执行过程
在Spark Streaming 中, 只有当遇到 Output Operator 操作 才是DStream上所有transformation的真正触发计算点, 类似于RDD中的action操作.
一个用户在编写的应用提交给Spark 集群执行分为两部分:
- 驱动: Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、计算任务分发到各个计算节点(Worker)、计算资源的分配等。
- 计算逻辑本身: 当计算任务在Worker执行时,执行计算逻辑完成application的计算任务
在执行的过程可分为三部分来分析: mian方法, Dtream处理方法, RDD处理方法
执行的JVM虚拟机可以分为两部分: driver端, worker端
main方法 与 Dtream处理方法
在测试代码中我们可以看到每部分在 Driver or Worker执行 :

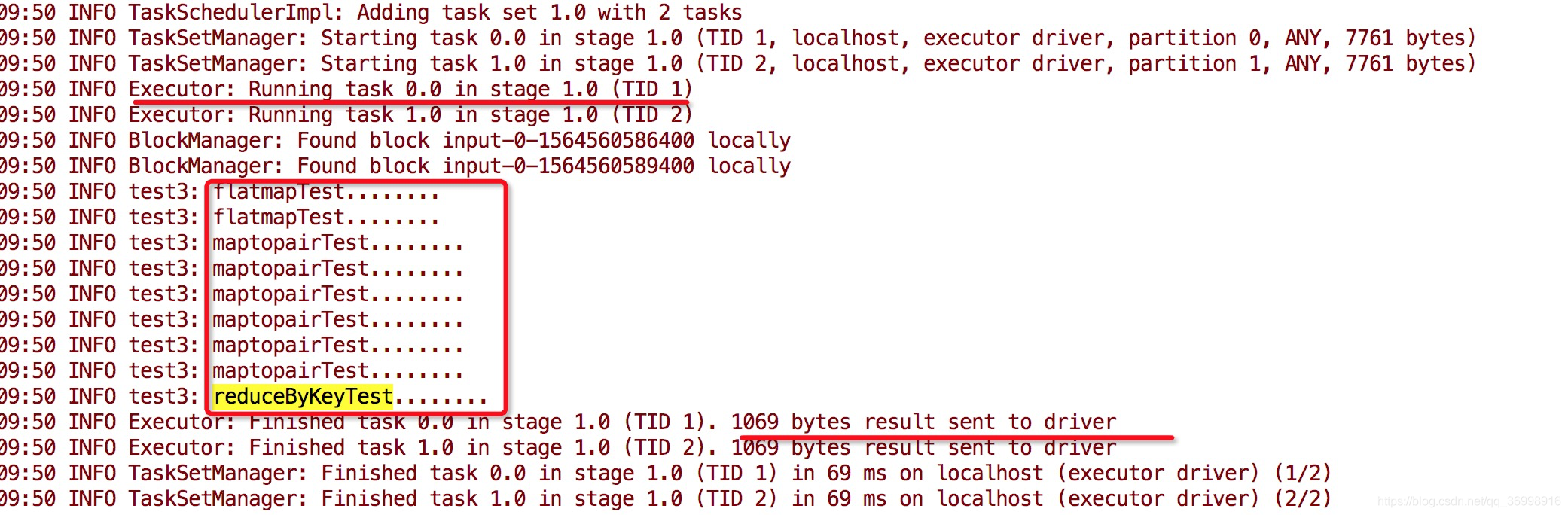
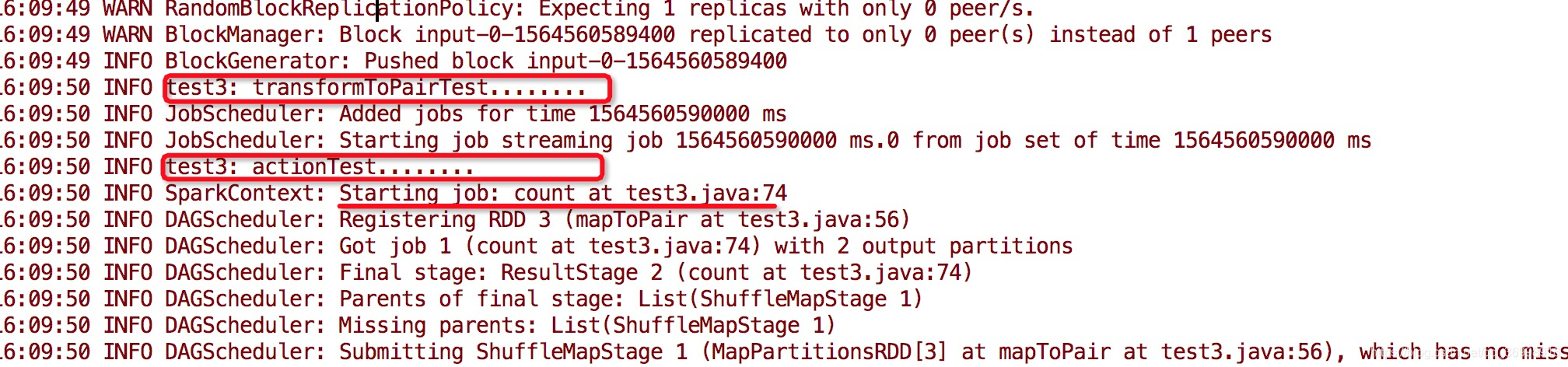
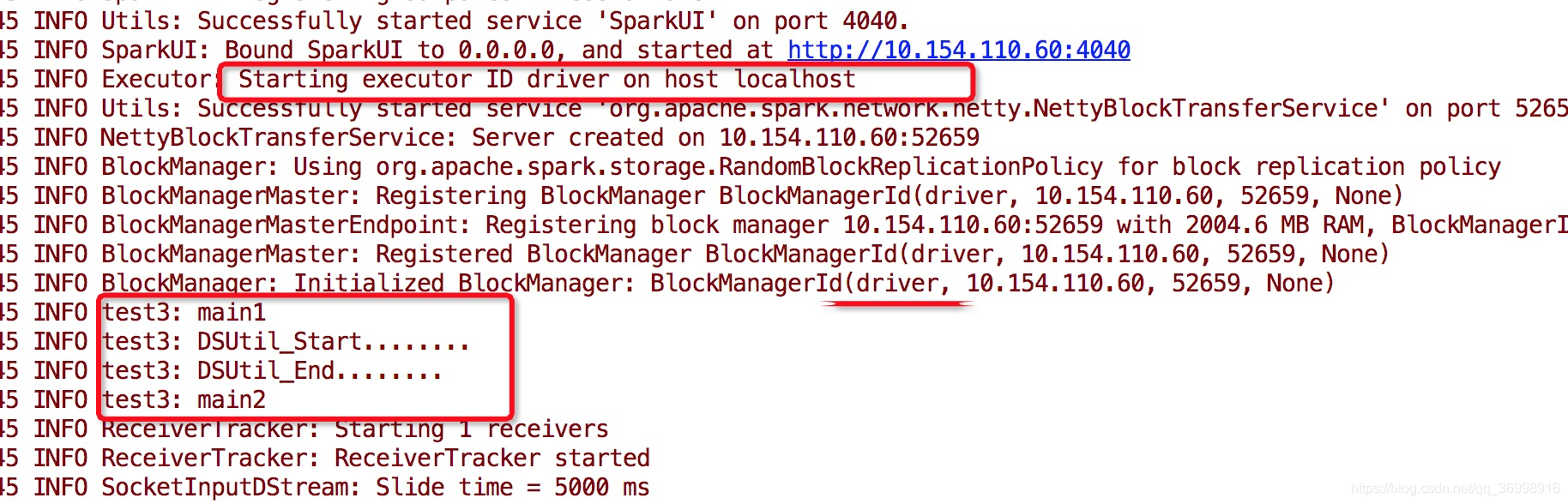
从日志中, 我们可以看出在main 方法中, 除了算子的代码, 其他的都是在Driver端执行, 且只执行一次.
在DSUtil的DStream中, 其中一部分代码是driver, 一部分是worker端的.
日志中发现, transformToPair算子 与foreachRDD算子(spark Streaming 的outpot operator)每一个batch会被Driver触发一次, 因此, 我们可以考虑在这两个地方加上读取外部配置, 这样每一个batch就会被触发一次.
因此 : 采用pull
- 从外部系统同步变量 — 在每一个Worker的Executor 执行进程里, 每次计算调用一次
- 在transformation 算子 或者 状态算子
- 从外部系统同步变量 — 在每一个会调用Driver的Executor 进程里, 每个batch调用一次
- 在Transform Operation 或 TransformToPair Operation
- 在output 算子
每个batch 会调用一次.
1. 每一个batch计算前 get 配置变量
在transformToPair or transform 实现动态读取配置
- 如下图代码所示:
这样在每一个batch 数据操作之前都会与数据数据库交互一次,读取一次名单, 会随着数据库名单的改变, 过滤条件发生改变.

- 改进之后— 读取的数据进行广播变量, 然后在 这里每个batch 触发一次, 进行重新广播, 代码如下:

这种方式的优点在于一致性更有保证。因为 Broadcast Variable 是统一由 Driver 更新并推到 Executor 的,这就保证不同节点的更新时间是一致的。然而相对地,缺点是会给 Driver 带来比较大的负担,因为需要不断分发全量的 Broadcast Variable (试想下一个巨大的 Map,每次只会更新少数 Entry,却要整个 Map 重新分发)。在 Spark 2.0 版本以后,Broadcast Variable 的分发已经从 Driver 单点改为基于 BitTorrent 的 P2P 分发,这一定程度上缓解了随着集群规模提升 Driver 分发变量的压力,但这种方式能支持到多大规模的部署还是持怀疑态度。另外一点是重新分发 Broadcast Variable 需要阻塞作业进行,这也会使作业的吞吐量和延迟受到比较大的影响。
每个batch取一次数据, 会造成很大压力.
2. 广播变量TTL定时

这样每5min重新进行一次广播变量, 在一定程度程度上减小了一直广播带来的性能压力, 但缺点也很明显, 就是会导致更新延迟, 不会及时更新.
3. 通过利用redis的订阅发布, 当配置改变 立刻进行广播一次
/**
* @Author: chenshitong
* @Date: 2019/8/4 下午4:52
* @Desription: test for 当每一次收到redis的订阅之后, 进行一次变量广播, 否则不进行广播
*/
public class test5{
private static Broadcast<List<String>> BlackList = null;
private static Map<Boolean,List<String>> mapData = new HashMap<>();
//这里内部类利用的是redis的订阅发布, 每一次发布我们就可以得到最新的数据
static class RedisMsgSubListener extends JedisPubSub {
@Override
public void onMessage(String channel, String message) {
mapData.put(true, Arrays.asList(message.split(",")));
}
}
private static void run() throws IllegalAccessException, SQLException, InstantiationException, InterruptedException {
SparkConf conf = new SparkConf().setMaster("local[5]").setAppName("test var");
JavaStreamingContext jsc = new JavaStreamingContext(conf, new Duration(5000));
JavaSparkContext sparkContext = jsc.sparkContext();
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("127.0.0.1", 9999);
lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator())
.transformToPair(new Function2<JavaRDD<String>, Time, JavaPairRDD<String, Integer>>() {
@Override
public JavaPairRDD<String, Integer> call(JavaRDD<String> li, Time time) throws Exception {
if(mapData.containsKey(true)){
System.out.println("更新一次广播变量值");
if(BlackList != null){
BlackList.unpersist(true);
}
BlackList = JavaSparkContext.fromSparkContext(li.context()).broadcast(mapData.get(true));
mapData.remove(true);
}
JavaPairRDD<String, Integer> outData= li.mapToPair(word -> new Tuple2<String,Integer>(word,1))
.filter(tuple -> {
if(BlackList != null && BlackList.getValue().contains(tuple._1)){
return false;
}else{
return true;
}
}).reduceByKey((num1,num2) -> num1+num2);
return outData;
}
}).print();
try {
jsc.start();
jsc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException, SQLException, InstantiationException, IllegalAccessException {
RedisMsgSubListener subscriber = new RedisMsgSubListener();
new Thread(new Runnable() {
public void run() {
try {
System.out.println("Subscribing to mychannel,this thread will be block");
redisUtil.getJedis().subscribe(subscriber, "blackword");
System.out.println("subscription ended");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
run();
}
}
通过这种方式, 当每一次更新redis数据的同时把数据广播, 当我们订阅该频道之后就可以及时拿到数据, 当每次拿到数据就进行一次广播, 这样可以极大提高效率.
这种方式同时也避免了上面两种方式的缺点, 利用了两种方式的优点.
END














 3532
3532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









