









一、HDFS HA概述
在hadoop2.x之前,hadoop集群只有一个namenode,存在单点故障【SPOF】,因此在一个namenode宕机或者该namenode所在的机器需要升级进行处理的时候,就需要停掉服务器,所有的服务都不能工作。因此,在hadoop2.x之后就提出了HDFS HA【High Availability】,HDFS HA通过配置Active/Standby两个namenode对集群中的namenode进行热备,当一台namenode出现故障时就可以切换到另外一台namenode上,不影响工作的正常运行。
下面,来看看HA架构图:
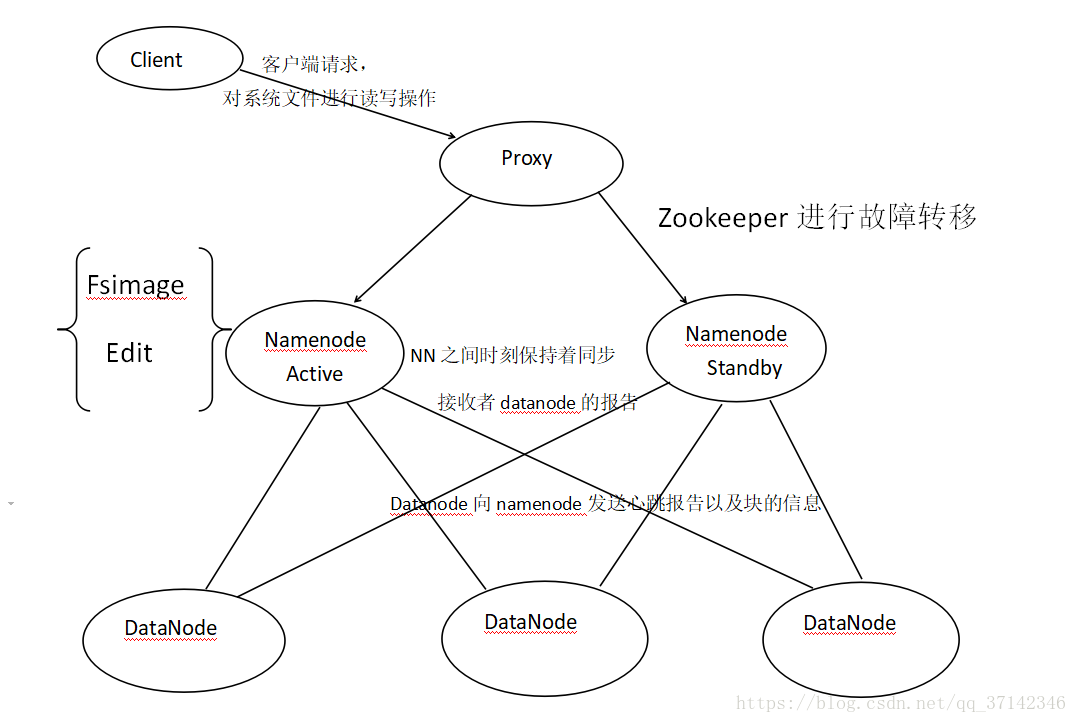
简单来说明一下上面的架构图,首先在只有一个namenode的集群中,client会直接向namenode发送请求进行操作,但是在HA架构中,会在两个namenode中产生一个代理,client首先会发送请求到proxy中,通过代理来访问namenode,当active namenode出故障之后就通过zookeeper进行快速切换保证工作的正常运行。在两个namenode之间也时刻保持着同步,同时都接收着来自datanode的报告。
HDFS HA集群的搭建有两种方式(具体查看官方文档http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html),这里我们使用QJM【Quorum Journal Manager】(分布式的日志管理方式)方式来搭建HA,下面是QJM HA架构图:
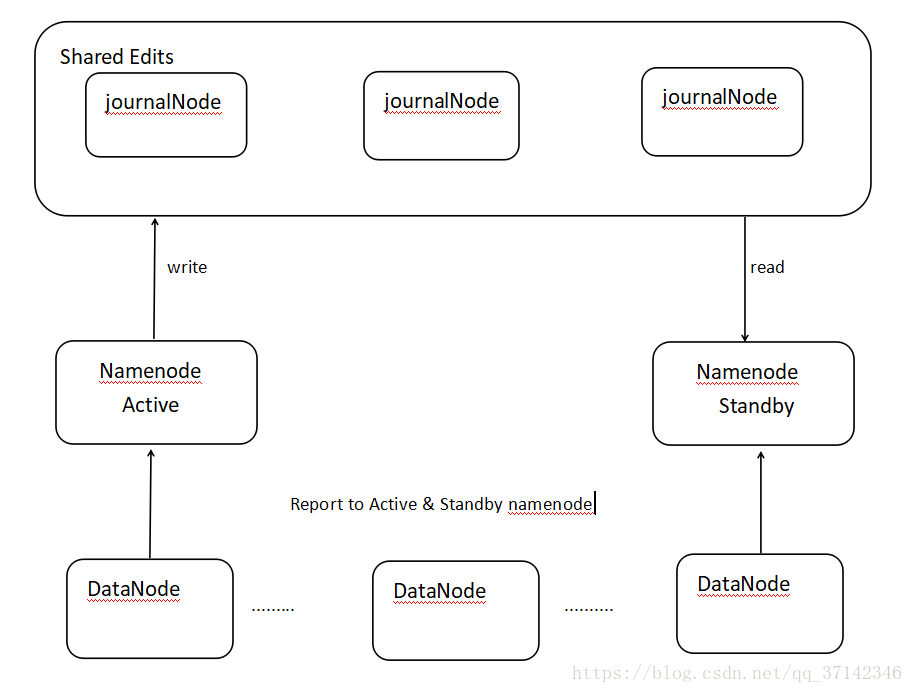
简单概述一下上面的架构图:采用QJM方式来搭建HA集群,它会有一组共享日志节点【注意必须是奇数个】,Active NameNode 在每一次操作后会想journalNode写日志,Standby NameNode则会时刻通过journalNode来同步日志,因此两台NameNode保持了同步。
二、搭建HDFS HA集群并启动
先看看集群的规划:
| hadoop-senior.shinelon.com | hadoop-senior02.shinelon.com | hadoop-senior03.shinelon.com |
|---|---|---|
| NameNode【nn1】 | NameNode【nn2】 | |
| journalNode | journalNode | journalNode |
| DataNode | DataNode | DataNode |
HA的搭建主要在core-site.xml和hdfs-site.xml文件中进行配置,分为下面几步:
1.Active NameNode 和Standby NameNode的路径配置
2.NameNode和DateNode本地存储路径的配置
3.HDFS namespace访问配置
4.journalNode配置
5.namenode之间的隔离配置(使用SSH Fence的方式,两台机器之间必须进行SSH无密匙登录配置)
6.QJM管理编辑日志
7.编辑日志存储目录
首先来看看core-site.xml文件中的配置(读者也可参考官方文档配置,有具体的步骤说明):
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!--Hadoop的数据临时存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.5.0/data/tmp</value>
</property>
<!--垃圾回收 -->
<property>
<name>fs.trash.interval</name>
<value>420</value>
</property>接着就是hdfs-site.xml文件中的配置:
<!-- namespace -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!--##################namenode rpc address####################### -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop-senior.shinelon.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop-senior02.shinelon.com:8020</value>
</property>
<!--##################namenode http web address####################### -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop-senior.shinelon.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop-senior02.shinelon.com:50070</value>
</property>
<!--##################namenode share edit address####################### -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-senior.shinelon.com:8485;hadoop-senior02.shinelon.com:8485;hadoop-senior03.shinelon.com:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.5.0/data/dfs/jn</value>
</property>
<!--##################hdfs proxy client####################### -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--##################namenode fence####################### -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/shinelon/.ssh/id_rsa</value>
</property>最后,需要注意的是还要在slaves文件中添加各个节点的主机名。这里就不赘述了,只要添加三台机器的主机名即可。
经过上面的配置,已经配置好QJM HA的搭建,下面我们来启动。
启动QJM HA集群
1.先在每一个journalNode节点上,输入以下命令启动journalNode服务:
sbin/hadoop-daemon.sh start journalnode2.在nn1上对namenode进行格式化并且启动:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode3.在nn2上同步nn1上的元数据信息:
[shinelon@hadoop-senior02 hadoop-2.5.0]$ bin/hdfs namenode -bootstrapStandby4.启动nn2上的namenode:
sbin/hadoop-daemon.sh start namenode5.在nn1上启动所有的datanode:
[shinelon@hadoop-senior hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode6.手动将nn1切换为active:
[shinelon@hadoop-senior hadoop-2.5.0]$ bin/hdfs haadmin -transitionToActive nn1经过上面的命令我们就可以启动HA了,启动之后我们可以进行简单的测试,使用HDFS命令上传文件,读写文件试试,如果成功说明HA集群搭建完成。也可以通过web页面来观察namenode的状态。
在上面的HA集群中,我们会发现一个问题,如果发现单点故障,我们就需要手动来切换,而且切换也会有时间间隔。因此我们可以使用zookeeper分布式协作框架来进行自动故障转移。
三、HA自动故障转移
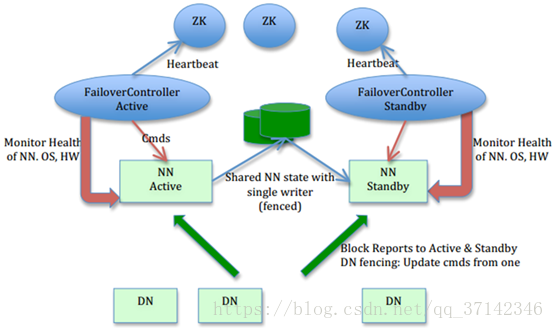
从上面的架构图上可以看到zookeeper会有两个控制器来监控两个namenode的状态,如果其中一台发生故障就会自动转移到另外一台上。
下面我们看看怎么来配置自动故障转移(前提是必须在集群上安装zookeeper分布式集群):
先停掉所有的服务:
sbin/stop-dfs.sh 根据官方文档,我们需要在core-site.xml和hdfs-site.xml文件中进行配置。
core-site,xml文件中添加如下配置:
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-senior.shinelon.com:2181,hadoop-senior02.shinelon.com:2181,hadoop-senior03.shinelon.com:2181</value>
</property>hdfs-site.xml配置:
<!--##################automic failover####################### -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>配置好上面两个文件之后就可以启动zookeeper集群了。切换到zookeeper的安装目录:
(需要在每一个节点上都执行下面命令进行启动)
[shinelon@hadoop-senior02 zookeeper-3.4.10]$ bin/zkServer.sh start然后初始化HA在中的状态:
[shinelon@hadoop-senior hadoop-2.5.0]$ bin/hdfs zkfc -formatZK接着我们来启动hdfs,先在哪台机器上启动,哪台就是Active NameNode:
[shinelon@hadoop-senior hadoop-2.5.0]$ sbin/start-dfs.sh启动之后我们可以使用jps命令进行查看,会比之前多出DFSZKFailoverController进程:
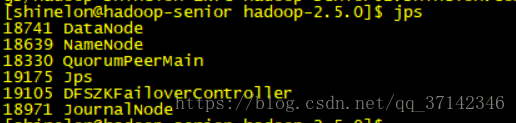
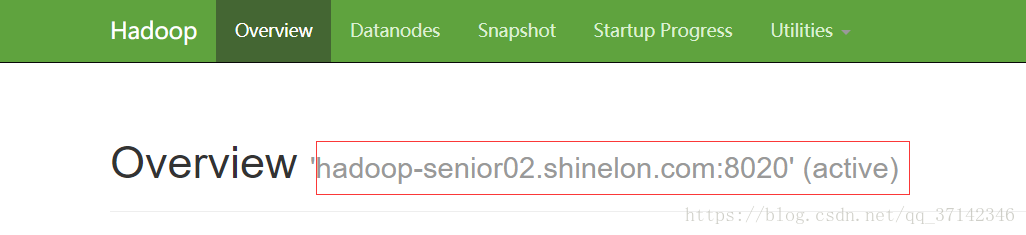
这时我们可以测试一下自动故障转移是否成功,使用kill命令杀死active namenode进程,然后会看到之前的standby namenode自动转换为active状态,则说明自动故障转移配置成功。














 2732
2732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









