







废话不说上代码
# -!- coding: utf-8 -!-
import os #调用cmd命令行
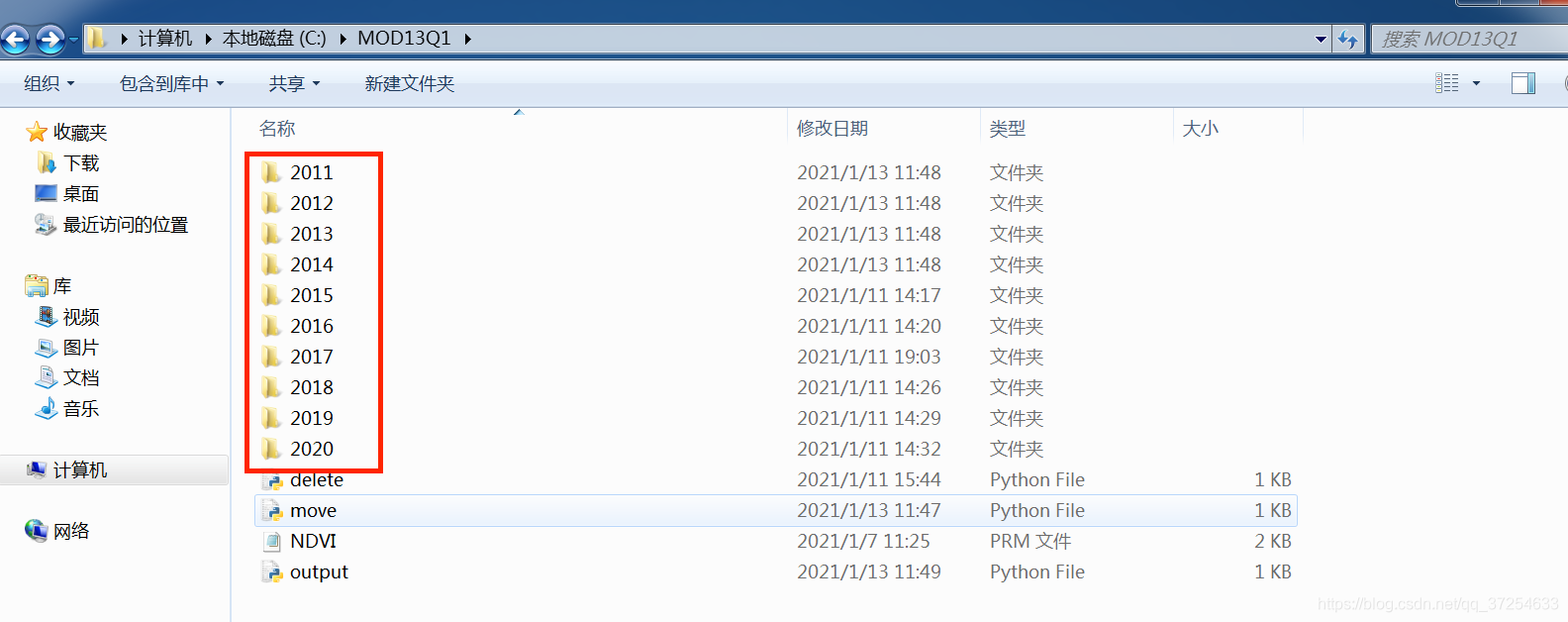
for i in range(2011,2021): #时间可更改(我用了十年的数据,见图1)
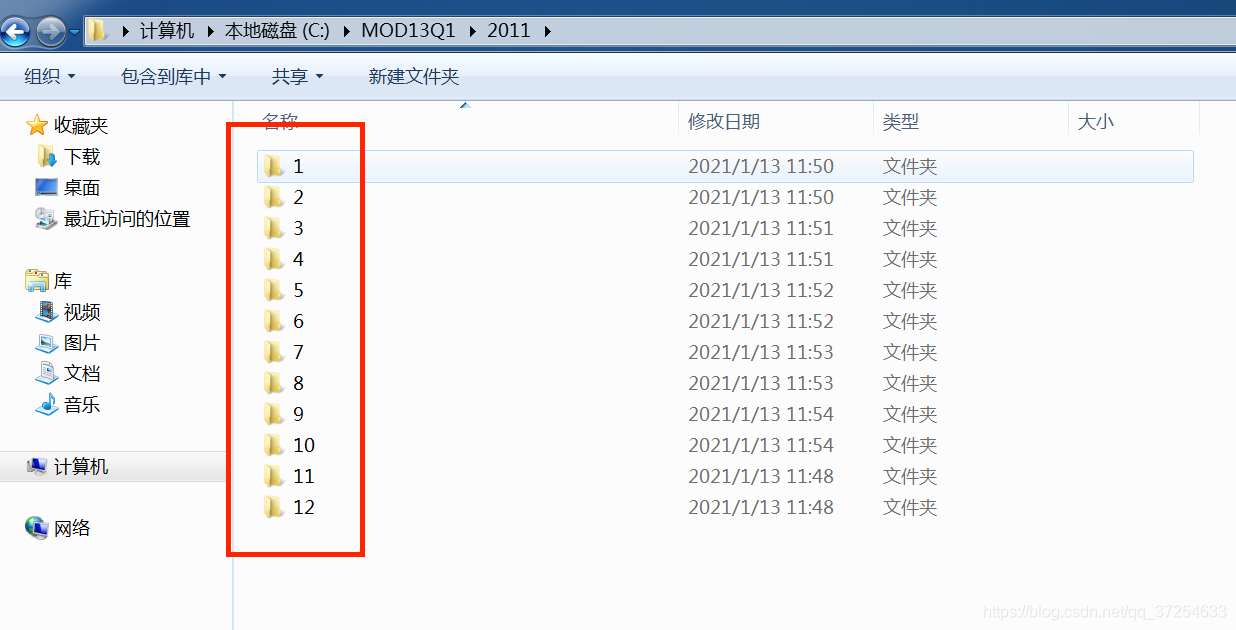
for j in range(1,13): #每月的数据放到单独文件夹(见图2、3)
os.chdir('C:/MRT/bin') #安装MRT的bin目录
os.system('java -jar MRTBatch.jar -d C:/MOD13Q1/%d/%d -p C:/MOD13Q1/NDVI.prm -o C:/MOD13Q1/%d/%d && MRTBatch.bat' % (i,j,i,j)) #C:/MOD13Q1/%d/%d 我分类好的数据路径(图1、2、3)
#C:/MOD13Q1/NDVI.prm 先用MRT手动拼接一次,保存一份 .prm 文件,不会的看下面教程
#C:/MOD13Q1/%d/%d 输出路径
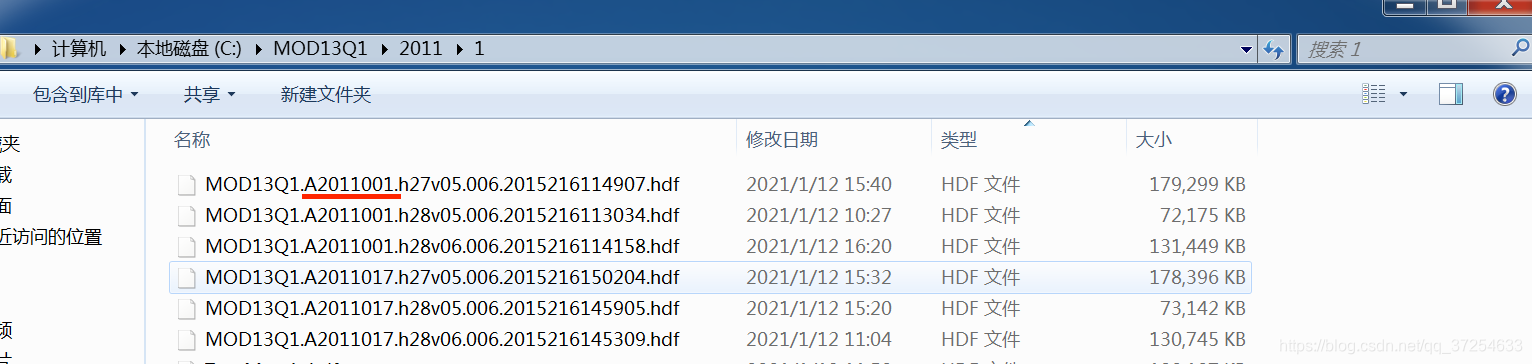
图三中的数据:一个月有两次数据,每次的数据有三个相邻区域(三景),等下就把每三景拼接成一景。
教程:
创建一个txt文件,代码复制进去,另存为 .py 文件。双击 .py 文件会调用cmd命令行自动执行。
一、下载好的数据应该都在一个文件夹里,需要按日期分类一下,python调用cmd可以快速完成,以下代码路径需要自己作相应修改
# -!- coding: utf-8 -!-
import os
k = 2011001 #图三红线,用这个来区分不同的.hdf文件
os.chdir('C:/MOD13Q1') #我下载的数据原始路径
for i in range(2011,2021):
os.system('mkdir %d' % i) #创建年份文件夹(图一所示)
for j in range(1,13):
os.system('cd %d && mkdir %d && cd ..' % (i,j)) #创建月份文件夹(图二所示)
for n in range(2):
os.system('move MOD13Q1.A%d.*.006.*.hdf %d/%d' % (k,i,j)) #移动操作
k = k + 16 #每16天一次数据
k = k - 368 - 16 + 1000 #复原k值,下次变成2012001,以此类推...
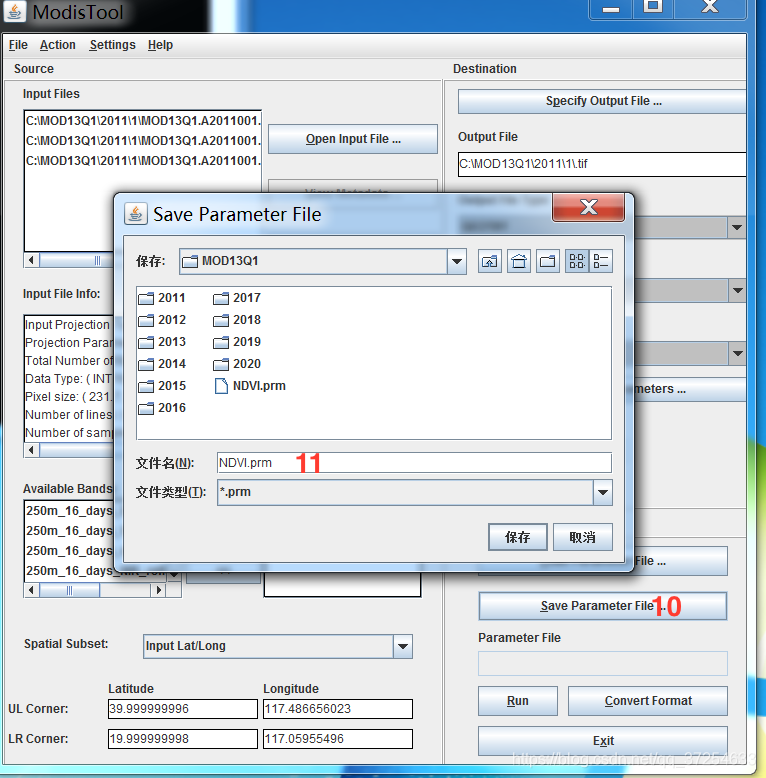
二、NDVI.prm文件的生成
MRT下载:链接:https://pan.baidu.com/s/1dToSzdgCbVX5J2R58jieMQ 密码:br3s
MRT处理的文件必须是全英文路径,不然容易报错!
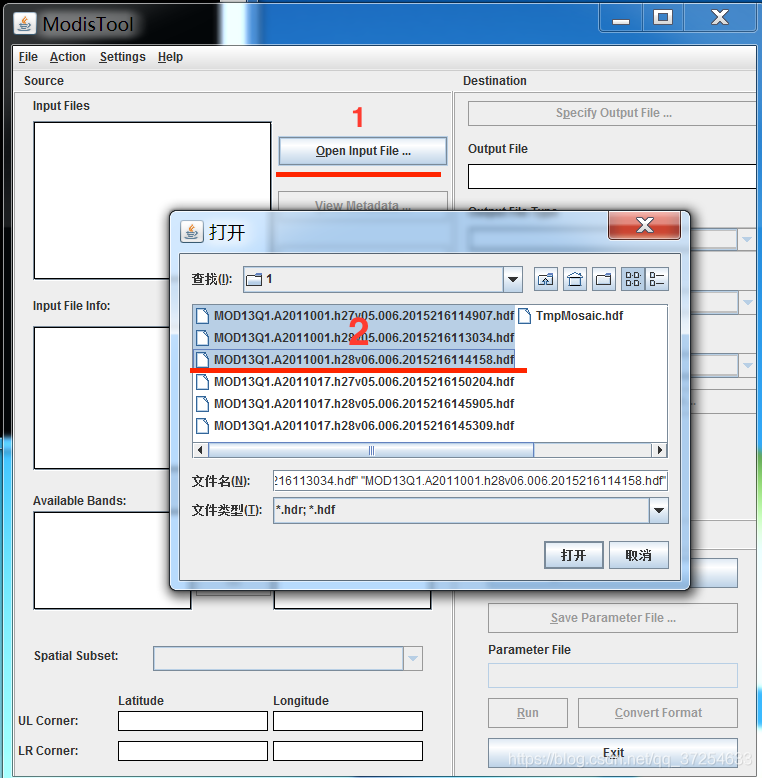
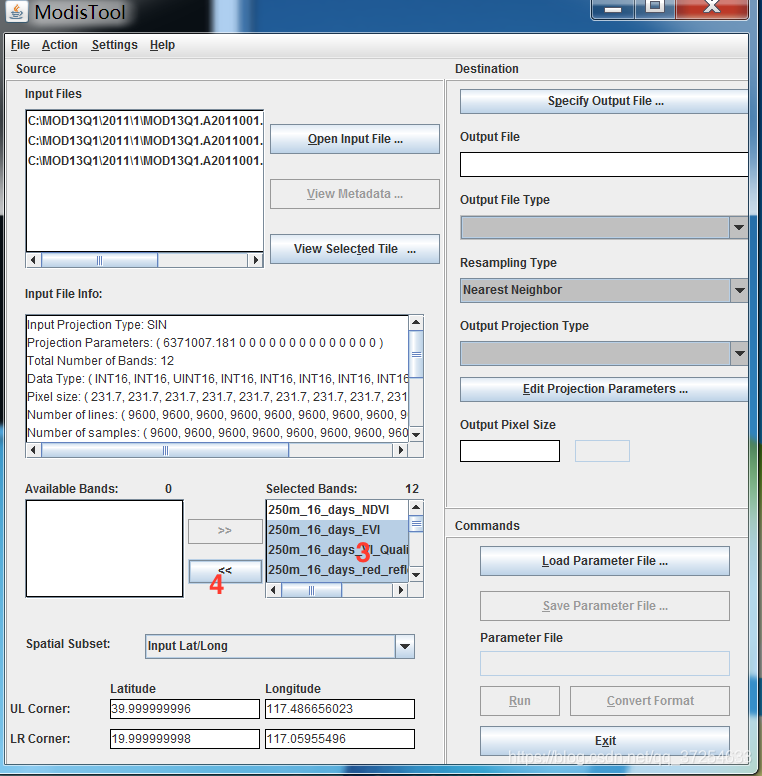
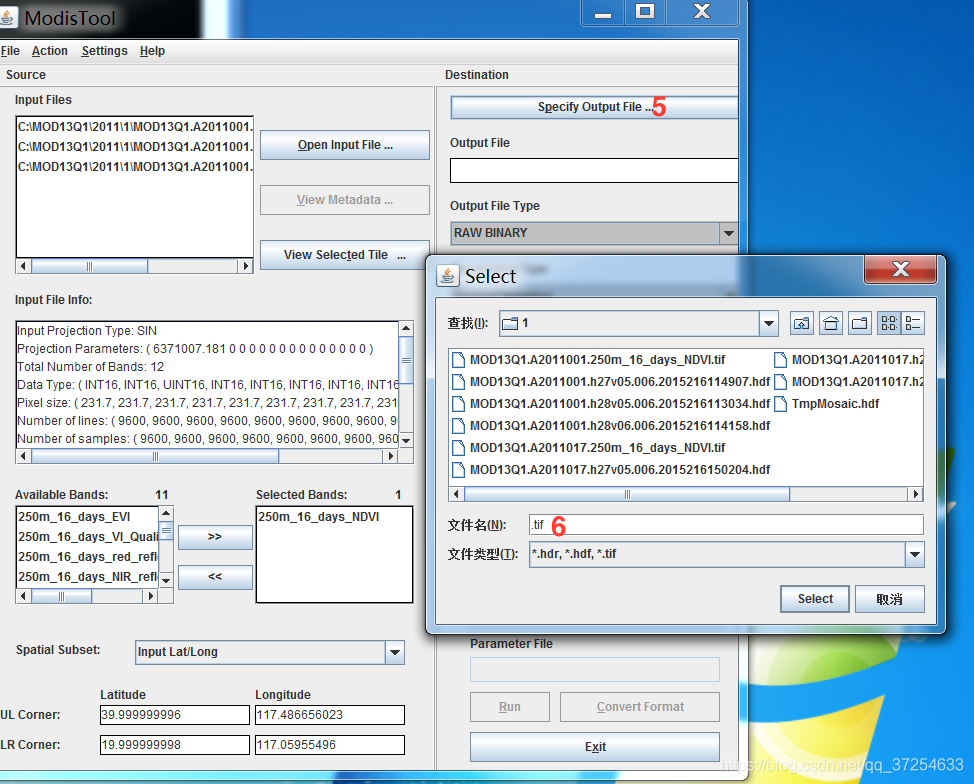
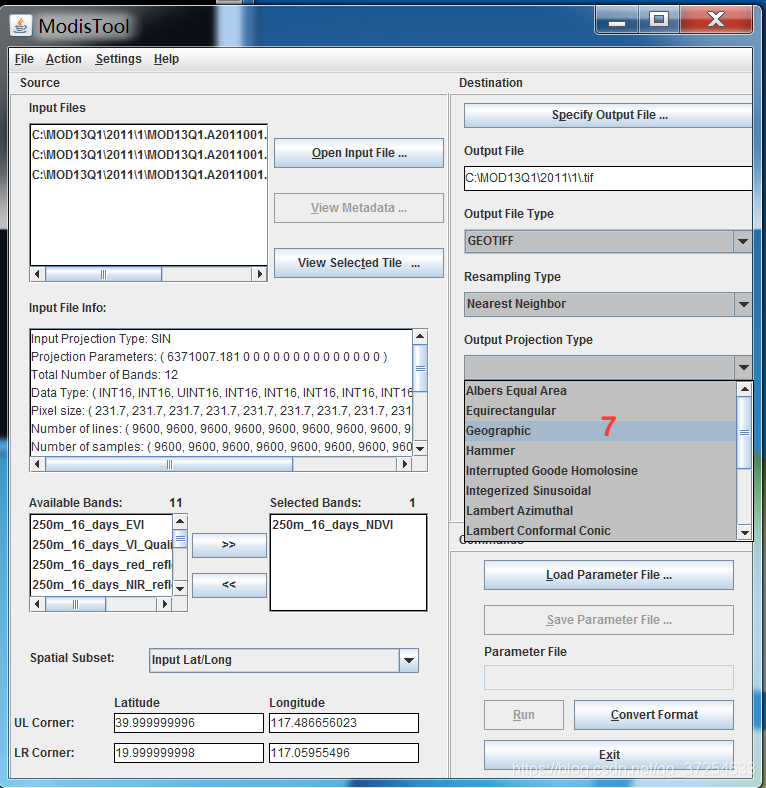
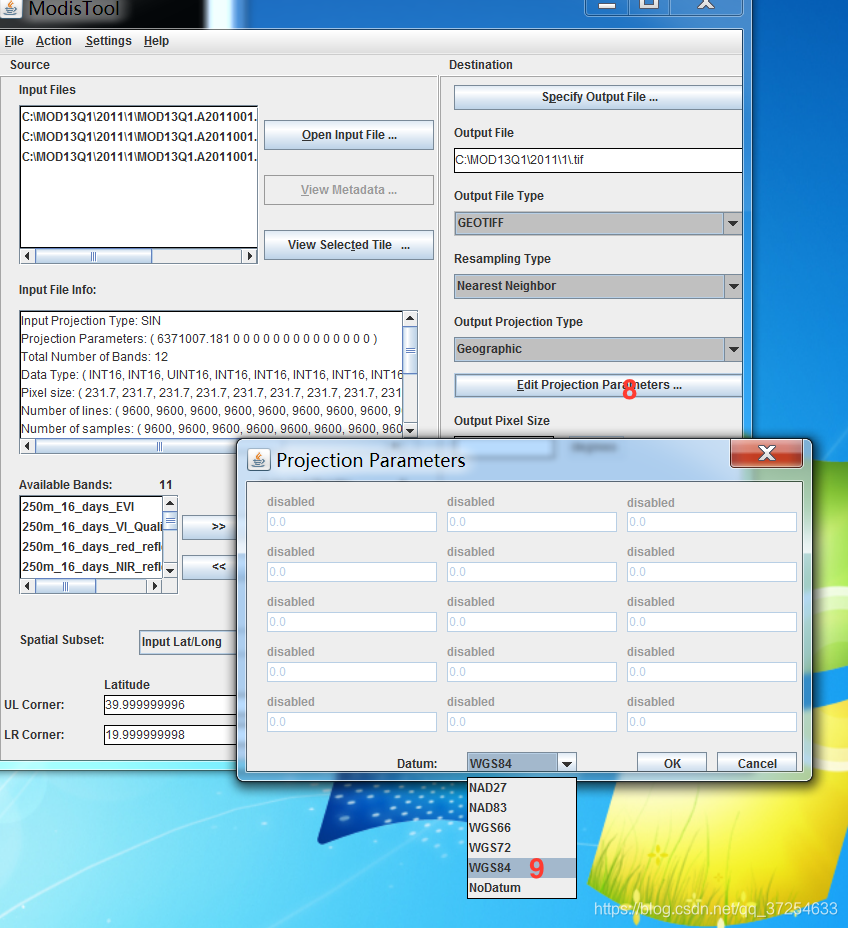
三、python批量拼接、投影、转换、提取NDVI
运行文章开头处的代码即可
成功界面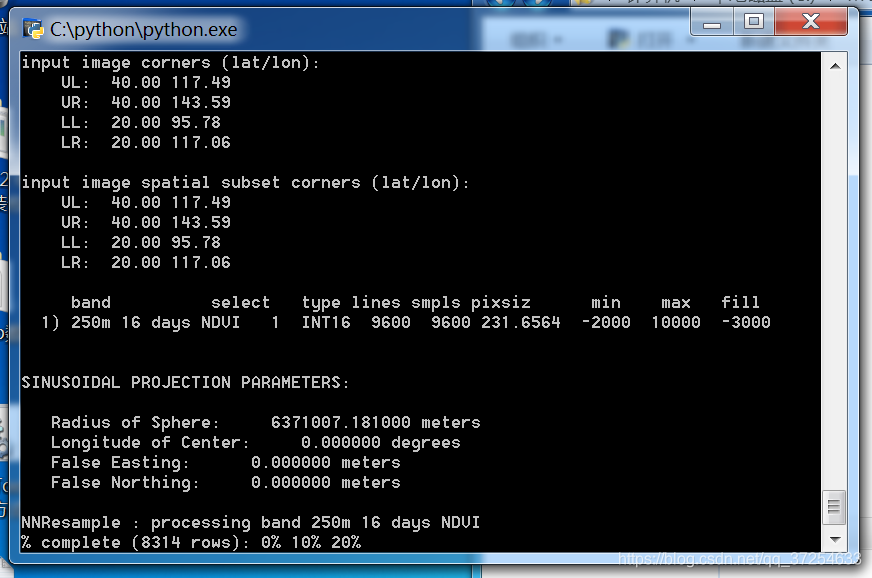
四、删除原来的 .hdf 文件,以及拼接过程生成的 .prm 文件(电脑内存大的直接忽略,咱只有可怜的500G…)
import os
for i in range(2011,2021):
for j in range(1,13):
os.system('cd C:/MOD13Q1/%d/%d/ && del *.hdf && del *.prm' % (i,j))














 6646
6646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









