









 本文介绍一种利用机器学习预测股票价格趋势的方法。通过对股票价格序列进行模式识别,并采用随机森林模型进行预测,该方法在真实股票数据上的表现优于SVM、ANN等常见机器学习模型。
本文介绍一种利用机器学习预测股票价格趋势的方法。通过对股票价格序列进行模式识别,并采用随机森林模型进行预测,该方法在真实股票数据上的表现优于SVM、ANN等常见机器学习模型。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着准备考研,考公,考教资或者实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯构建高效的股票价格预测模型:基于机器学习的数据分析
背景与意义
在金融市场中,股票价格预测一直是投资者和研究者关注的热点问题。准确预测股票价格不仅能为投资决策提供重要依据,还能帮助投资者规避风险,获取更高收益。传统的股票价格预测方法多依赖于技术分析和基本面分析,然而这些方法在处理复杂的市场动态时,往往面临局限性。随着机器学习技术的快速发展,它为股票价格预测提供了新的解决方案。通过对历史数据的深入分析
技术思路
在监督性学习中,模型训练依赖大量标注数据,然而在股票趋势分类这个具体场景里,要对股票数据进行标注是一项极为庞大且繁琐的工作。因为股票价格受到众多复杂因素影响,人工去准确标注其趋势类别耗时费力,而且很难保证标注的准确性和一致性。鉴于此,采用启发式非监督算法来划分价格模式就成为了一个更合适的选择。这种方式不需要事先的标注信息,而是依据数据自身的内在结构和特征来自动发现价格数据中潜在的模式,从而为后续进一步分析股票趋势等工作打下基础。
启发式非监督算法旨在探索数据的自然分组或模式,它主要基于数据的相似性、距离等特征来进行聚类或者划分。比如常见的 K-Means 聚类算法(这里只是举例方便理解原理,不一定就是实际采用的算法),它会将数据集里的数据点根据距离的远近划分到不同的簇中,认为同一个簇内的数据点具有较高的相似性,属于同一种模式。对于股票价格数据来说,通过计算不同时间点价格数据之间的某种距离度量(例如欧式距离等),把相似价格波动情况的时间段归为一类,这样就可以挖掘出不同的价格模式,像股价持续上涨的模式、震荡调整的模式或者下跌的模式等等。
利用启发式非监督算法划分股票价格模式的步骤:
1. 数据准备
首先需要获取股票价格数据,通常可以从金融数据接口或者本地存储的历史数据文件中读取,数据一般包含日期、开盘价、收盘价、最高价、最低价等字段。以下是简单读取数据的示例代码(假设数据存储在 CSV 文件中):
import pandas as pd
stock_data = pd.read_csv('stock_price.csv')
2. 数据预处理
对读取到的股票价格数据进行必要的预处理,比如归一化处理,使得不同价格范围的数据能在同一尺度下进行分析,避免因数值量级差异影响算法对模式的划分。示例代码如下(采用简单的归一化方法):
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(stock_data[['Close']]) # 以收盘价为例进行归一化
3. 选择并应用启发式非监督算法
选择合适的启发式非监督算法,比如这里假设采用密度的空间聚类算法,它能发现任意形状的簇且可以识别出噪声点)来划分价格模式。示例代码如下:
from sklearn.cluster import DBSCAN
model = DBSCAN(eps=0.5, min_samples=5) # 参数可根据实际调整
clusters = model.fit_predict(scaled_data)
4. 分析划分结果
根据得到的聚类结果(不同的价格模式类别),可以进一步分析每种模式下股票价格的特征、持续时间、出现频率等情况,以此来洞察股票价格变化的规律,为后续的股票趋势判断、投资决策等提供参考依据。通过这种利用启发式非监督算法划分价格模式的方式,巧妙地避开了繁琐的人工标注过程,利用数据自身的特点挖掘出有价值的价格模式信息,助力股票相关分析工作的开展。
🚀海浪学长的作品示例:
大数据算法项目

机器视觉算法项目


实验的验证部分用到了真实的股票数据,来自深市科创板的495支股票,时间是从2010年1月25到2016年1月26日,并与常见的机器学习模型,如SVM、ANN以及KNN算法进行了预测准确率和收益率的比较。比较的效果如下面的表所示:
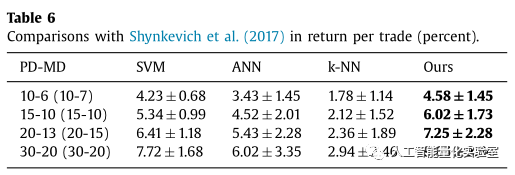
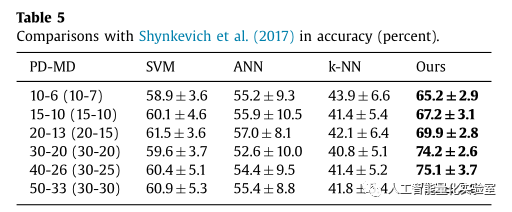
在不考虑各种滑点、手续费等因素的前提下,可以看出,论文中提出的方法的效果还是很客观的。
微信小程序项目

Unity3D游戏项目

最后💯
🏆为帮助大家节省时间,如果对开题选题,或者相关的技术有不理解,不知道毕设如何下手,都可以随时来问学长,我将根据你的具体情况,提供帮助。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









