




目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于视频监控的濒危动物目标跟踪算法优化
课题背景和意义
随着生态环境的恶化和人类活动的影响,许多动物种类面临灭绝的威胁。对濒危动物的保护工作亟需依赖科学技术手段,特别是在目标跟踪和监测方面。通过对濒危动物的实时跟踪,可以获取其活动轨迹、栖息地使用情况以及行为特征,从而为保护措施的制定提供数据支持。
实现技术思路
一、算法理论基础
1.1 多尺度特征融合
深度网络的多尺度概念涵盖了特征提取网络生成的具有不同语义和尺度的特征图。研究表明,不同尺度的特征图在检测不同尺寸的目标时,具有各自的优势。低层特征图虽然具有较高的分辨率,但其语义可能不足以检测目标,仍会导致小目标的丢失。因此,许多在线目标跟踪算法倾向于通过融合多尺度特征图的方式,生成综合了不同尺度优势的特征图,以简化处理多余检测框的步骤,同时提高运算效率。由于深度网络中不同层次的特征图具有不同的分辨率和抽象程度的语义信息,FPN通过设计网络结构来融合这些特征图,形成多尺度的特征金字塔,使检测器能够在多个尺度上进行有效的目标检测。
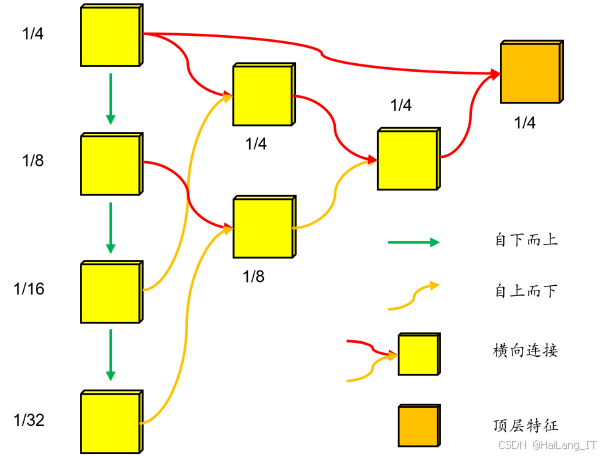
FPN结构是一种特征融合手段,不同模型可以根据需要设计合适的FPN网络结构。横向连接可以使用直接加法或通道拼接等形式。DCN通过学习偏移量来动态调整卷积核的采样位置,这种动态调整可以帮助网络适应目标物体的形状变化,使网络在处理具有不规则形状或变形的目标时更加灵活。在深度目标检测和跟踪领域,DCN发挥关键作用,比如运用DCN提升FPN特征融合中的上采样和横向连接性能,以适应目标形状和外观变化,从而实现更优质的顶层特征提取,降低特征冗余和其他噪声信息的引入,提高检测能力和ReID特征性能。
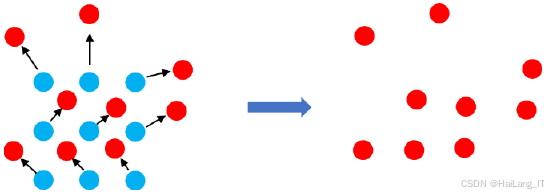
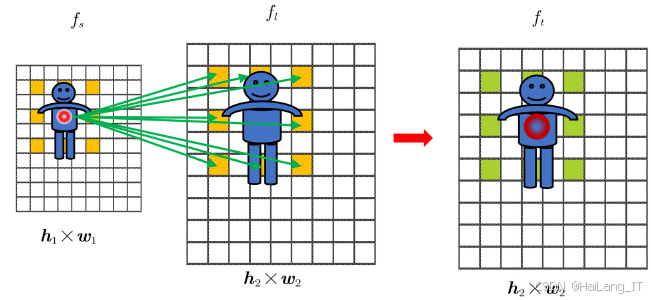
Attention用于构建序列的长距离相关,能够让模型关注序列不同位置的信息,在处理自然语言等序列方面取得了优异的成果。局部Attention机制是一种等效的局部交叉注意力机制,展示了和变换成相同尺寸的特征图之前的局部Attention的对应关系。通过计算目标中心点的特征向量与其邻域内点的特征向量之间的Attention值,可以生成多个Attention值,并将这些值作为邻域点的权重,经过加权和得到一个融合向量,该向量包含了邻域点的所有信息,从而增强检测能力。对所有点执行此操作后,可以输出一个经过局部Attention加强的特征图,目标中心将获得显著的检测能力提升,因为目标中心与周围点的平均相关性最高。从中心越往外,距离中心越远,检测能力的增强同样越少。
门控循环单元(GRU)是一种用于处理时间序列数据的神经网络结构,其设计目的是为了有效捕捉序列中的长期依赖关系。GRU主要由更新门和重置门组成,其中更新门决定了当前状态应保留多少历史信息和加入多少新信息。这种灵活的信息整合能力使得GRU能够有效捕捉序列中的长期依赖关系,避免了传统循环神经网络在处理长序列时可能遇到的梯度消失问题。GRU的门控结构不仅简化了传统LSTM的复杂性,还在处理时间序列数据时表现出了优越的性能。通过这种门控机制,GRU能够有效地捕捉到序列中存在的复杂关系。
1.2 目标检测算法
YOLOv5是一种先进的目标检测算法,旨在高效、快速地识别图像中的目标。作为YOLO系列的最新版本,YOLOv5在保持实时检测速度的同时,进一步提高了检测的精度。其核心思想是通过单次前向传递来实现目标的检测,避免了传统方法中需要多次处理图像的复杂过程,从而显著提高了处理速度。YOLOv5的结构设计灵活,能够支持多种输入尺寸,适应不同应用场景下的需求,既可以处理简单的图像任务,也能够应对复杂的视觉识别问题。
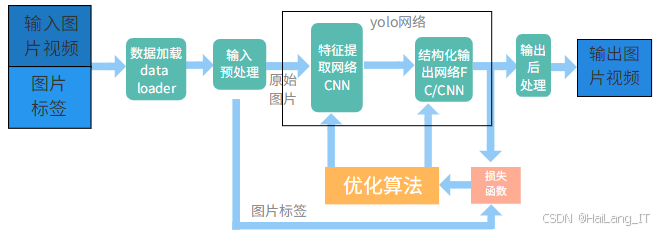
YOLOv5的结构主要包括特征提取、检测头和后处理三个部分。特征提取部分采用了一种轻量级的卷积神经网络,通过多层卷积操作提取输入图像的特征。这一过程能够有效地捕捉图像中的重要信息,使得后续的检测更加精准。检测头则根据提取的特征生成目标的边界框和类别概率。YOLOv5采用了锚框的方法来预测目标的位置和类型,从而提高了对不同目标尺寸的检测能力。在后处理阶段,YOLOv5使用非极大值抑制等技术来去除冗余的检测框,确保最终输出的目标信息更加准确,避免重复检测同一目标。
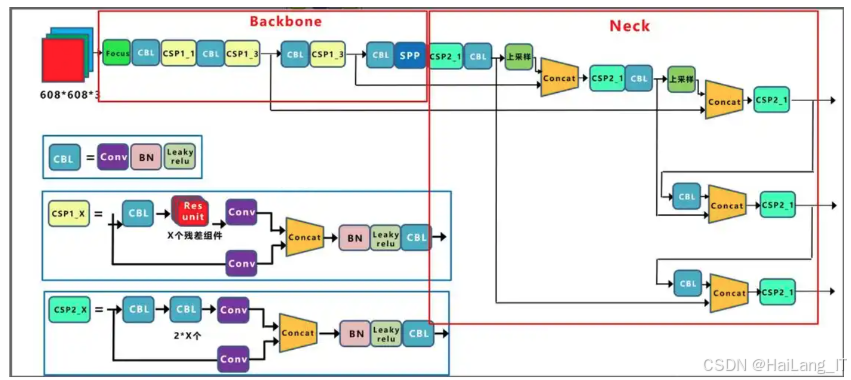
YOLOv5在濒危动物目标跟踪算法中的优势显著。高效的实时检测能力快速识别和定位目标,适用于动态环境中的动物监测。小目标检测方面表现优异,有效识别体型较小或隐蔽的濒危动物。模型结构灵活,支持多尺度输入,适应不同场景和背景的变化。
二、 数据集
2.1 数据集
濒危动物图像采集可以选择自主拍摄和互联网采集。自主拍摄通常在特定的保护区或栖息地进行,通过相机捕捉濒危动物的真实行为和状态。通过搜索公开的图像库和社交媒体平台,获取已经存在的相关图像资源,以丰富数据集的多样性和覆盖面。使用Labeling工具为每张图像中的濒危动物添加边界框和类别标签。

2.2 数据扩充
将数据集划分为训练集、验证集和测试集,以便于模型的训练和性能评估。同时,通过数据扩展技术,如旋转、缩放、翻转及颜色变换等,可以增加数据集的多样性,提升模型对不同环境和条件的适应性。
三、实验及结果分析
3.1 实验环境搭建

3.2 模型训练
图像采集可以通过自主拍摄或者互联网获取。自主拍摄的图像能够反映真实的动物行为,而互联网采集的图像则可以增加数据的多样性。数据标注使用Labeling工具,为每个目标添加边界框和类别信息。最后,数据集应划分为训练集、验证集和测试集,以便在模型训练和评估时使用。
# 示例:加载数据集
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
data_transform = transforms.Compose([
transforms.Resize((640, 640)),
transforms.ToTensor(),
])
train_dataset = ImageFolder(root='data/train', transform=data_transform)
val_dataset = ImageFolder(root='data/val', transform=data_transform)构建目标跟踪模型时,选择YOLOv5作为基础架构,并添加多尺度特征融合和局部Attention机制。多尺度特征融合可以有效增强模型对不同大小目标的检测能力,而局部Attention机制则能够使模型更关注图像中的重要区域。这一组合能够提升模型的整体表现,尤其是在处理复杂背景和小目标时。设置合适的损失函数和优化器,以提高模型的学习效果。通常使用交叉熵损失函数和Adam优化器,能够有效提升训练的收敛速度。在训练过程中,可以通过调整学习率和批大小等超参数来优化模型的性能。
# 示例:构建YOLOv5模型
import torch
from models.yolo import Model
# 加载YOLOv5模型
model = Model(cfg='models/yolov5s.yaml') # 选择合适的配置文件
# 添加局部Attention模块
class LocalAttention(torch.nn.Module):
def __init__(self):
super(LocalAttention, self).__init__()
# 定义Attention层
def forward(self, x):
# 实现Attention机制
return x
# 将Attention模块添加到YOLOv5模型中
model.add_module('local_attention', LocalAttention())对模型进行评估,使用测试集对模型进行性能测试,计算准确率、召回率和F1分数等指标。这些指标将帮助判断模型在实际应用中的有效性。根据评估结果,可以进一步调整模型结构和训练参数,以优化模型性能。同时,可以利用数据扩展和迁移学习等技术,提升模型在新环境中的适应能力。
# 示例:评估模型
def evaluate_model(model, test_loader):
model.eval()
total = 0
correct = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f'Accuracy: {accuracy:.2f}')
# 评估模型
evaluate_model(model, test_loader)海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









