







1、什么是知识图谱?
互联网时代,搜索引擎是人们在线获取信息和知识的重要工具。当用户输入一个查询词,搜索引擎就会返回它认为与这个关键词最相关的网页。
直到2012年5月,搜索引擎巨头谷歌在搜索页面中首次引入了“知识图谱”的概念:用户除了得到搜索网页链接,还将看到与查询词有关的更加智能化的答案。
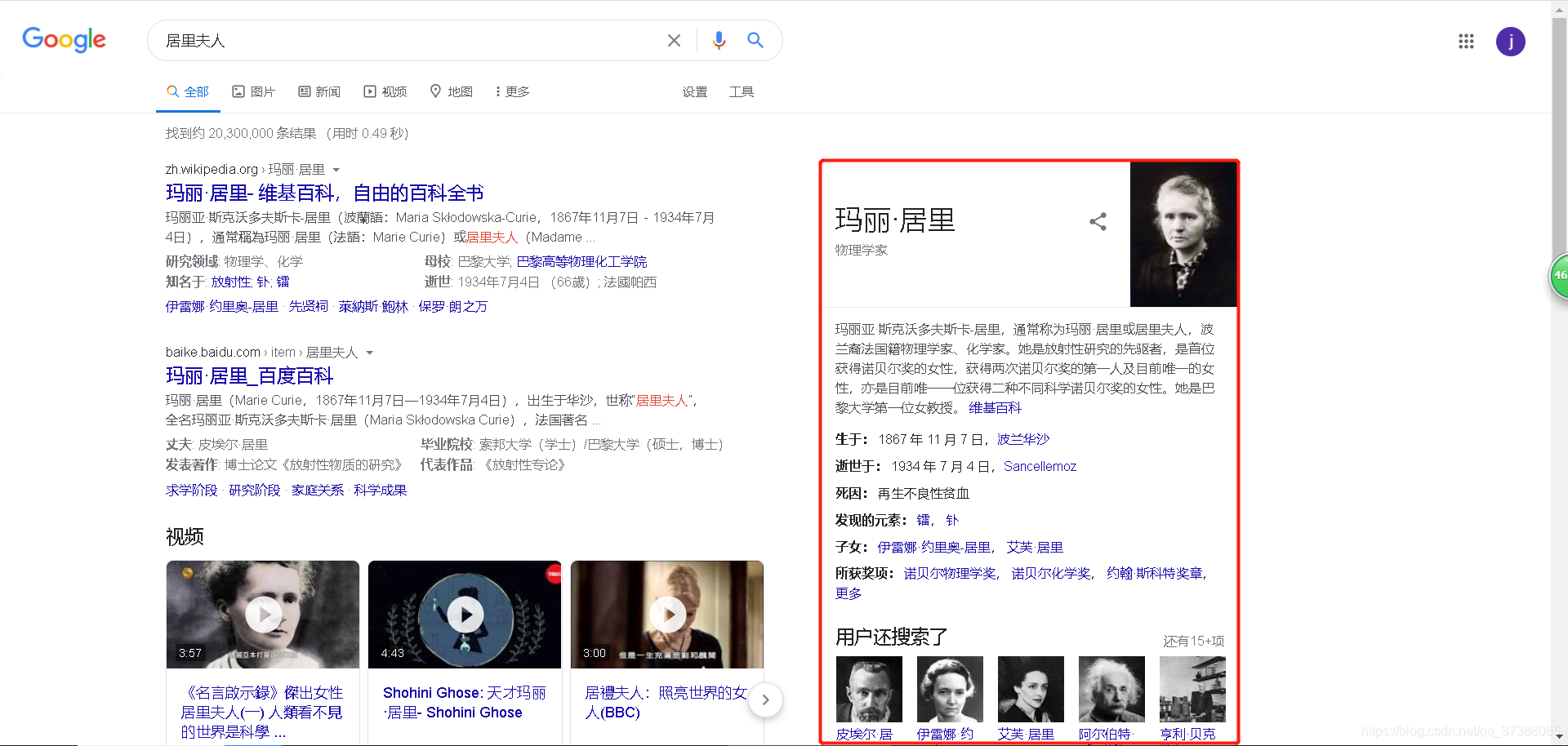
如下图,当用户输入居里夫人这个查询词时,谷歌会在页面右侧提供居里夫人的详细信息,如个人简介、出生时间等等。
知识图谱里通常用“实体(Entitiy)”来表达图的节点,用“关系(Relation)”来表达图里的边。

上图是一个汽车的知识图谱的例子,汽车可以基于品牌,结构,能源和级别进行划分,品牌等又可以进行细分。
从杂乱的网页到结构化的实体知识,搜索引擎利用知识图谱为用户提供更具条理的信息,甚至顺着知识图谱可以探索更深入、广泛和完整的知识体系,让用户发现意想不到的知识。
传统搜索引擎,以百度为例,在过去,当我们想知道“泰山”的相关信息时,我们会在百度上搜索“泰山”,它会尝试将这个字符串与百度抓取的大规模网页做对比,根据网页与这个查询词的相关程度,以及网页本身的重要性,对网页进行排序,作为搜索结果返回给用户。而用户所需的与“泰山”相关的信息,就还要自己动手,访问这些网页寻找。
传统搜索引擎的工作方式表明,它只是机械地对比查询词和网页之间的匹配关系,并没有真正地理解用户要查询的到底是什么,远远不够聪明。
知识图谱会将“泰山”理解为一个“实体”,也就是现实世界中的事物。这样搜索引擎会在页面搜索结果的右侧显示其基本资料,例如地理位置、海拔高度等。此外,还会告诉我们一些相关的“实体”,如嵩山等。
2、什么是信息提取?
对于结构化与半结构化数据需要复杂表数据的处理与定义抽取的包装器等方式将数据映射成知识图谱数据。
对于非结构化的纯文本数据需要借助自然语言处理等技术来自动提取出结构化信息。这个过程一般称为信息抽取。

3、自然语言理解
自然语言理解本质是结构预测,自然语言理解的众多人物,包括并不限于中文分词、词性标注、命名实体识别、共指消解、句法分析、词义角色标注等,都是在对文本序列背后特定语义结构进行预测。
3.1 信息抽取的主要任务
- 命名实体识别;
- 关系抽取;
- 实体统一;
- 指代消解;















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









