






目标: 一台Master 两台Slave
一、修改主机名,配置/etc/hosts文件
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名对应的IP地址。在/etc/hosts文件里面添加如下:

可以ping 一下,看是否可以正常通信。所有机器都要修改。
二、三台机器都实现ssh免密登陆。
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到 NameNode。
需要注意的是,也需要将本机的公钥添加到authorized_keys里面,通过ssh localhost验证
三、安装java环境
所有的机器上都要安装JDK,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装JDK以及配置环境变量,需要以"root"的身份进行。
用java -version来验证是否安装成功。注意,master和slave机器必须安装同一个版本的JDK,不然会有问题。
四、 安装HADOOP集群
1、 首先在Master机器上安装HADOOP,解压下载的tar.gz包就可以了。修改目录名称为hadoop
2、 在hadoop目录下创建文件夹tmp。并把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件,将以下语句添加到末尾,并使其生效(. /etc/profile):
下面是 JDK 和 Hadoop 环境变量配置:
-
# Java Env -
export JAVA_HOME=/opt/java/jdk1.7.0_80 -
export JRE_HOME=/opt/java/jdk1.7.0_80/jre -
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JRE_HOME/lib -
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin -
# Hadoop Env -
export HADOOP_HOME=/opt/hadoop-2.6.4 -
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3、 配置hadoop,配置文件在hadoop/etc/hadoop/目录下面。
首先,修改 master 机器上 Hadoop 配置
(1) hadoop-env.sh
增加如下两行配置:
-
export JAVA_HOME=/opt/java/jdk1.7.0_80 -
export HADOOP_PREFIX=/opt/hadoop-2.6.4
(2) core-site.xml
-
<configuration> -
<property> -
<name>fs.defaultFS</name> -
<value>hdfs://master:9000</value> -
</property> -
<property> -
<name>hadoop.tmp.dir</name> -
<value>/opt/hadoop-2.6.4/tmp</value> -
</property> -
</configuration>
注意:tmp目录需提前创建
(3) hdfs-site.xml
-
<configuration> -
<property> -
<name>dfs.replication</name> -
<value>3</value> -
</property> -
</configuration>
数据有三个副本
(4) mapred-site.xml
-
<configuration> -
<property> -
<name>mapreduce.framework.name</name> -
<value>yarn</value> -
</property> -
</configuration>
(5) yarn-env.sh
增加 JAVA_HOME 配置
export JAVA_HOME=/opt/java/jdk1.7.0_80(6) yarn-site.xml
-
<configuration> -
<!-- Site specific YARN configuration properties --> -
<property> -
<name>yarn.nodemanager.aux-services</name> -
<value>mapreduce_shuffle</value> -
</property> -
<property> -
<name>yarn.resourcemanager.hostname</name> -
<value>master</value> -
</property> -
</configuration>
(7) slaves
-
master -
slave01 -
slave02
master 即作为 NameNode 也作为 DataNode。
4、在 slave01 和 slave02 上做同样的配置
直接将hadoop文件夹拷贝到slave机器上。
五、启动Hadoop集群
1、格式化文件系统
在 master 上执行以下命令:
$ hadoop/bin/hdfs namenode -format
执行后控制台输出如下所示,看到Exiting with status 0表示格式化成功。
2、启动 NameNode 和 DateNode
在 master 机器上执行 start-dfs.sh, 如下:
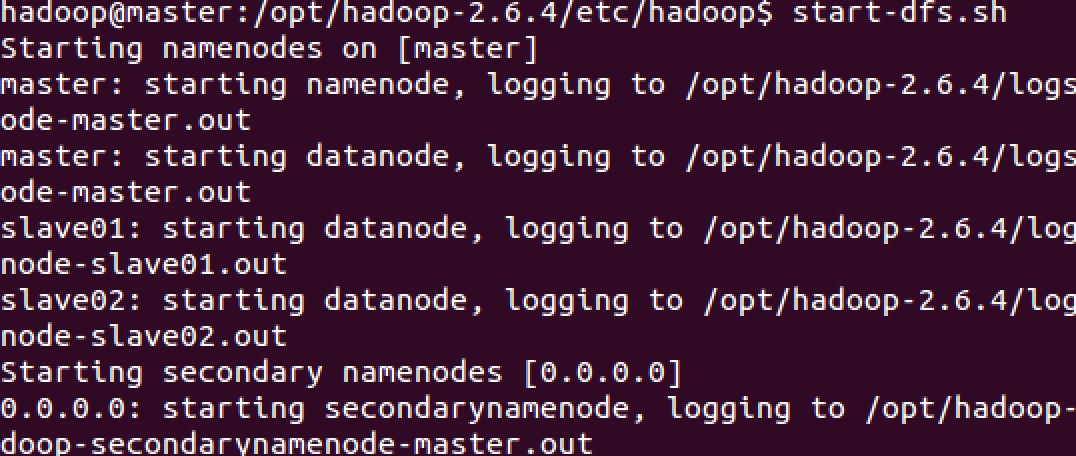
使用 jps 命令查看 master 上的Java进程:

使用 jps 命令分别查看 slave01 和 slave02 上的 Java 进程:


可以看到 NameNode 和 DataNode 均启动成功。
3、查看 NameNode 和 NameNode 信息
浏览器输入地址: http://master:50070/ 可以查看 NameNode 信息。



4、启动 ResourceManager 和 NodeManager
运行 start-yarn.sh, 如下:

使用 jps 查看 master 上的 Java 进程

可以看到 master 上 ResourceManager 和 NodeManager 均启动成功。

可以看到 slave01 上 NodeManager 也启动成功。

同样可以看到 slave02 上 NodeManager 也已经启动成功了。
至此,整个 Hadoop 集群就已经启动了。















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









