







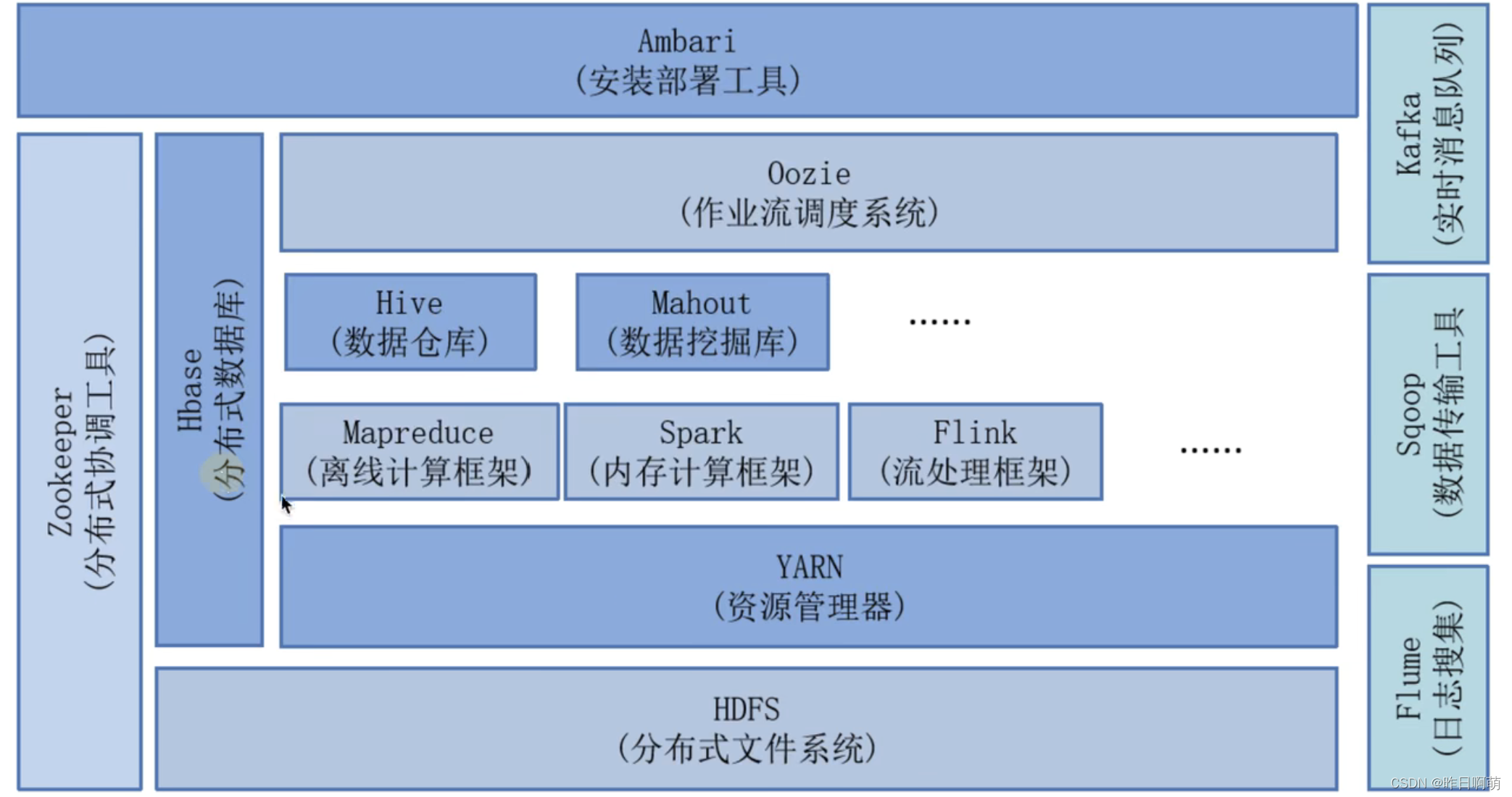
Hadoop,hive,spark在大数据生态圈的位置
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
这篇文章写的通俗易懂,很适合对Hadoop形成一个初步的认识
1、Hadoop
Storm / Flink
缘起:
谷歌的三篇论文:GFS(大数据的存储),MapReduce(数据分析),BigTable(存储非结构化数据)
结构化数据:是高度组织和整齐格式化的数据。它是可以放入表格和电子表格中的数据类型,存储与关系型数据库中
关系型数据库:表名,字段,比如Mysql(SQL是一种用于操作数据库的语言,而MYSQL是数据库软件)
非关系型数据库:Nosql
Hadoop:HDFS(分布式文件系统),YARN(作业调度和资源管理框架),MapReduce(并行计算处理框架)
底层HDFS,上面跑MapReduce/Tez/Spark,再上面跑Hive,Pig。基本就是一个数据仓库的构架了。
接下来根据我短暂的实习经历,整理一下我遇到的模块内容
2、HDFS
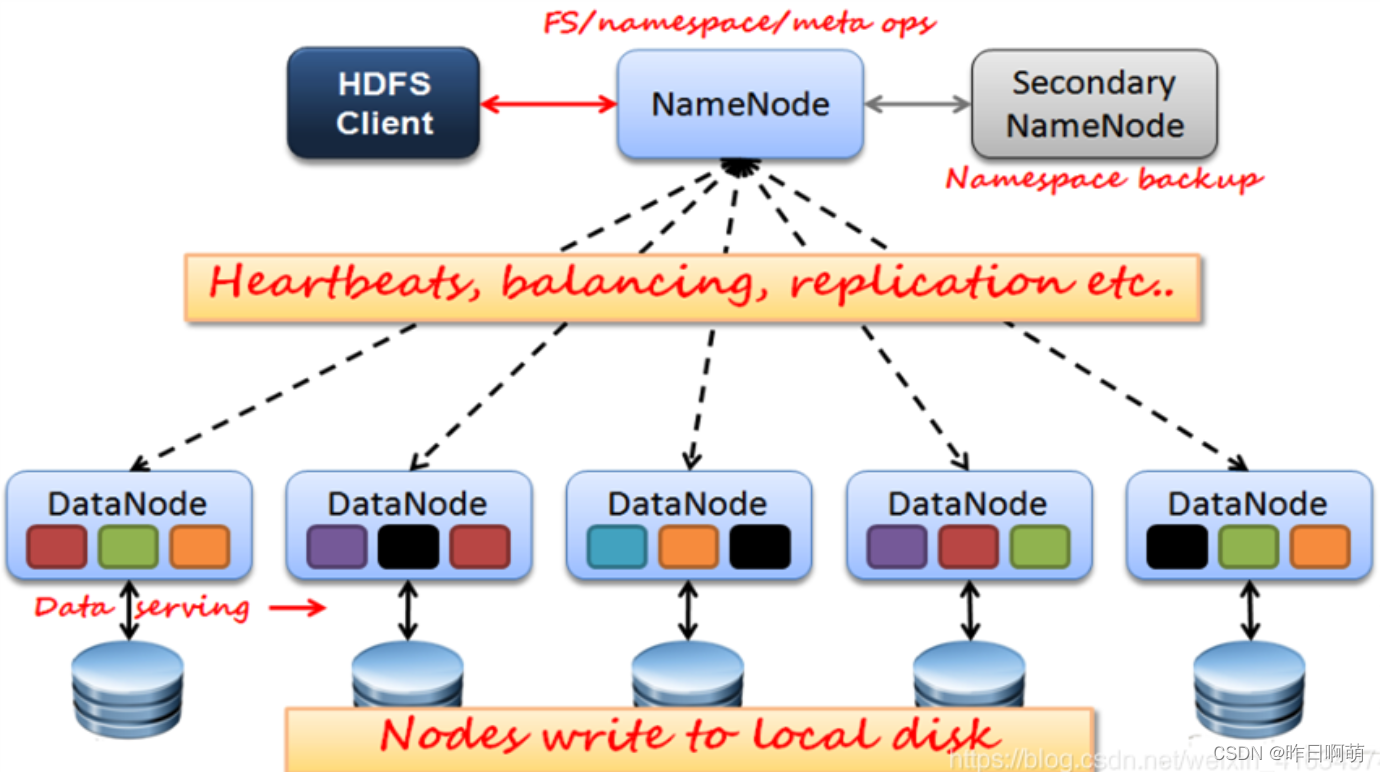
传统分布式系统缺点:1、负载不均衡 2、网络瓶颈问题
NameNode: 维护集群的目录树结构,对外提供服务
DataNode: 存储数据
Hadoop2中,没个block128m,Hadoop3中256m,在存储数据时,会把同一个block存储在不同的Datanode中,以此形成备份
由于采用的是这种类似目录索引的结构,也就造成了HDFS不适合存储大量小文件。因为每个文件都会在Namenode中生存对应的索引,从而塞满内存
3、MapReduce,Spark
如果要用很多台机器处理,我就面临了如何分配工作,如果一台机器挂了如何重新启动相应的任务,机器之间如何互相通信交换数据以完成复杂的计算等等。这就是MapReduce / Tez / Spark的功能。MapReduce是第一代计算引擎,Tez和Spark是第二代。
Map(映射)阶段,几百台机器同时读取这个文件的各个部分,分别把各自读到的部分分别统计出词频,产生类似(hello, 12100次),(world,15214次)等等这样的Pair(我这里把Map和Combine放在一起说以便简化);这几百台机器各自都产生了如上的集合,然后又有几百台机器启动Reduce处理。Reducer(归约)机器A将从Mapper机器收到所有以A开头的统计结果,机器B将收到B开头的词汇统计结果(当然实际上不会真的以字母开头做依据,而是用函数产生Hash值以避免数据串化。因为类似X开头的词肯定比其他要少得多,而你不希望数据处理各个机器的工作量相差悬殊)。然后这些Reducer将再次汇总,(hello,12100)+(hello,12311)+(hello,345881)= (hello,370292)。每个Reducer都如上处理,你就得到了整个文件的词频结果。
Spark与Mapreduce有什么不同?
1、Spark的速度比MapReduce快,Spark把运算的中间数据存放在内存,迭代计算效率更高;mapreduce的中间结果需要落地,需要保存到磁盘,比较影响性能;
2、spark容错性高,它通过弹性分布式数据集RDD来实现高效容错;mapreduce容错可能只能重新计算了,成本较高;
4、Spark
https://blog.csdn.net/u013013024/article/details/72876427
Spark可以说是圈内最流行的几个大数据处理框架之一了,类似地位的可能还有storm之类的。其最大的优点就是能够几乎底层透明的完成分布式的计算,非常方便开发。
Spark是可以搭建在很多平台上的,比较常见的Spark+Hadoop(作为文件系统)+Hive(作为分布式数据库)的配置。
Spark核心数据结构:RDD
RDD是spark 的核心数据结构,spark 之所以能够做到把分布式做成近乎底层透明,正是依靠了RDD.RDD全称弹性分布式数据集(Resilient Distributed Datasets).
Spark.sql
Spark.RDD
Spark.Dataframe
直接去官网看吧
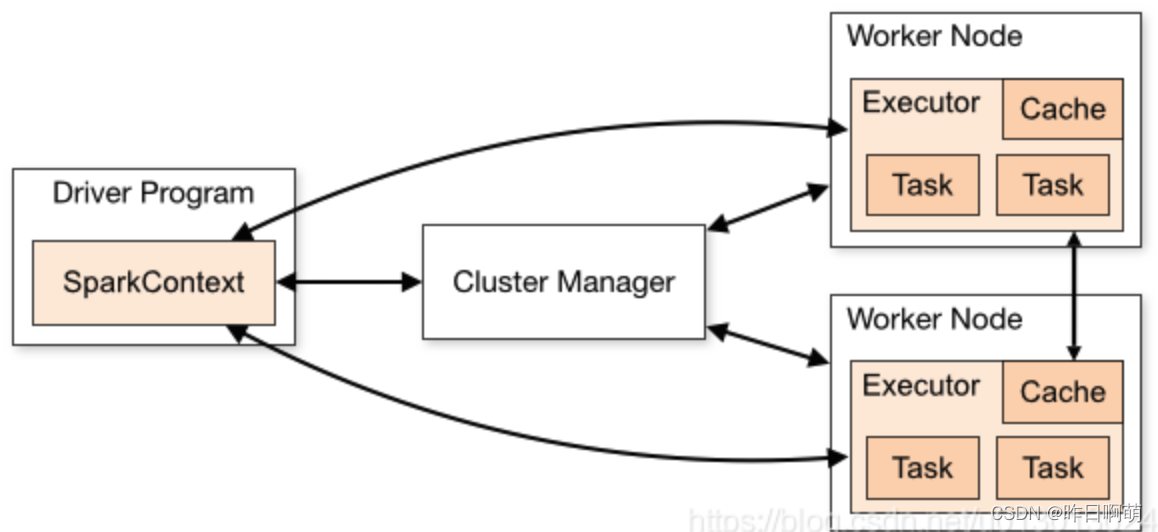
Spark中的driver主要完成任务的调度以及和executor和cluster manager(集群管理器)进行协调。有client和cluster联众模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择机器中的一台机器启动driver。
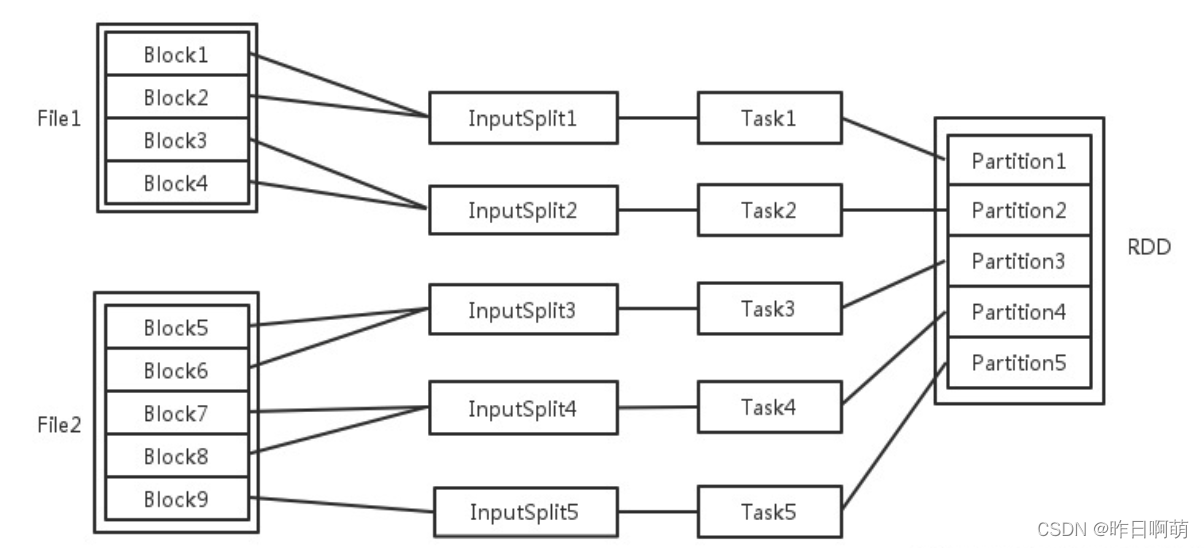
输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。每个节点可以起一个或多个Executor。每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。每个Task执行的结果就是生成了目标RDD的一个partiton。
至于partition的数目:
对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
在Map阶段partition数目保持不变。
在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
5、Hive
支持SQL!不用多说了吧
MapReduce的程序写起来真麻烦。他们希望简化这个过程。这就好比你有了汇编语言,虽然你几乎什么都能干了,但是你还是觉得繁琐。你希望有个更高层更抽象的语言层来描述算法和数据处理流程。于是就有了Pig和Hive。Pig是接近脚本方式去描述MapReduce,Hive则用的是SQL。它们把脚本和SQL语言翻译成MapReduce程序,丢给计算引擎去计算,而你就从繁琐的MapReduce程序中解脱出来,用更简单更直观的语言去写程序了。
还有流式计算flink,实时消息队列Kafka等等














 4125
4125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









