










一个好朋友要爬个app排行网页,我就以一杯星巴克卖出去啦。
网页链接:http://qianfan.analysys.cn/view/rank/app.html
我们使用Python3,主要用到re,requests模块。
一般来说爬虫的流程是这样:先看网页源代码,再找到要爬的字段出现的区域,用正则表达式找到这个字段,再打印或者导出结果。
我们先看这个网页,需要爬的是排行、app和UV:
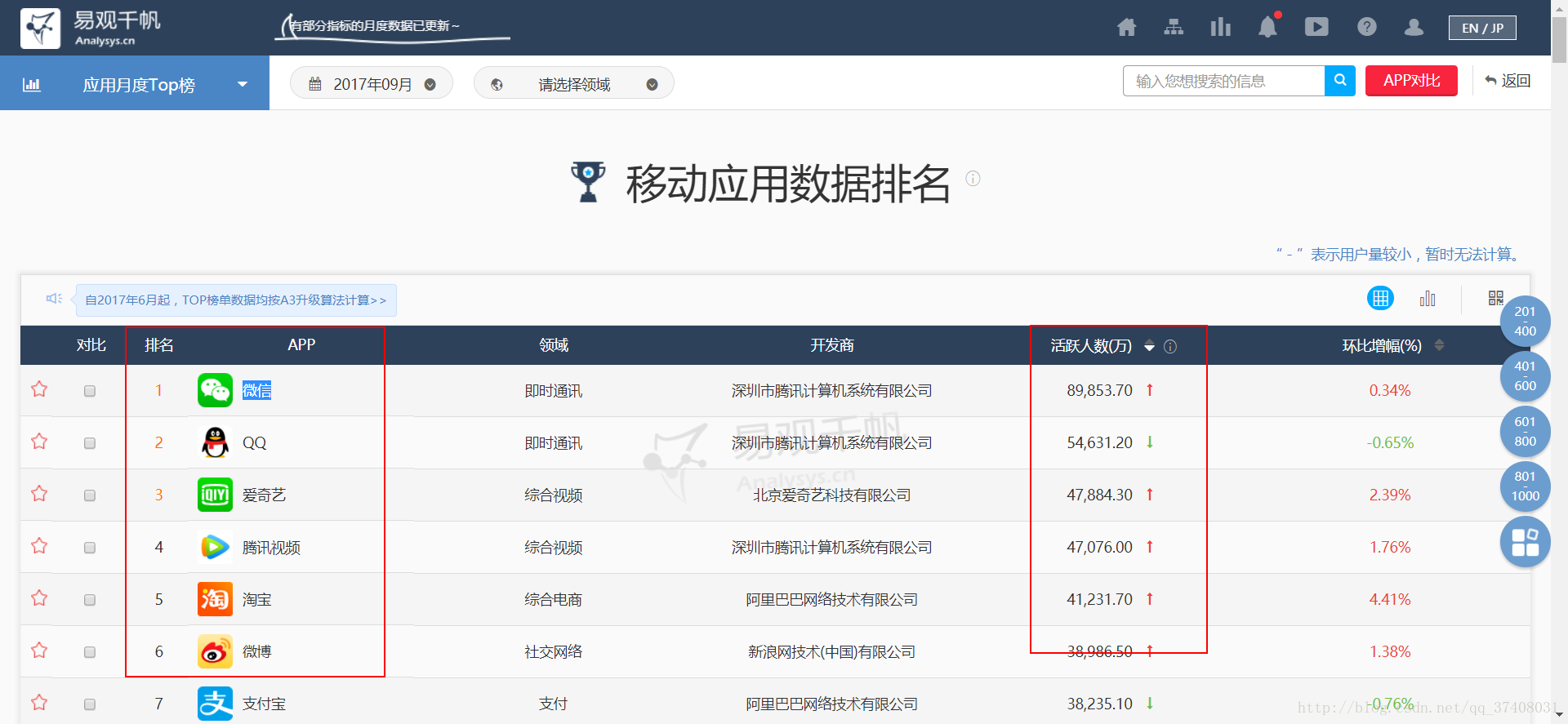
用python看下源代码(浏览器也可以,右键:查看网页源代码)
# -*- coding:utf-8 -*-
import re
import urllib.request
with urllib.request.urlopen('http://qianfan.analysys.cn/view/rank/app.html') as response:
html = response.read().decode('utf-8')
print(html)看到搜索微信并没有内容,判断为动态网页。
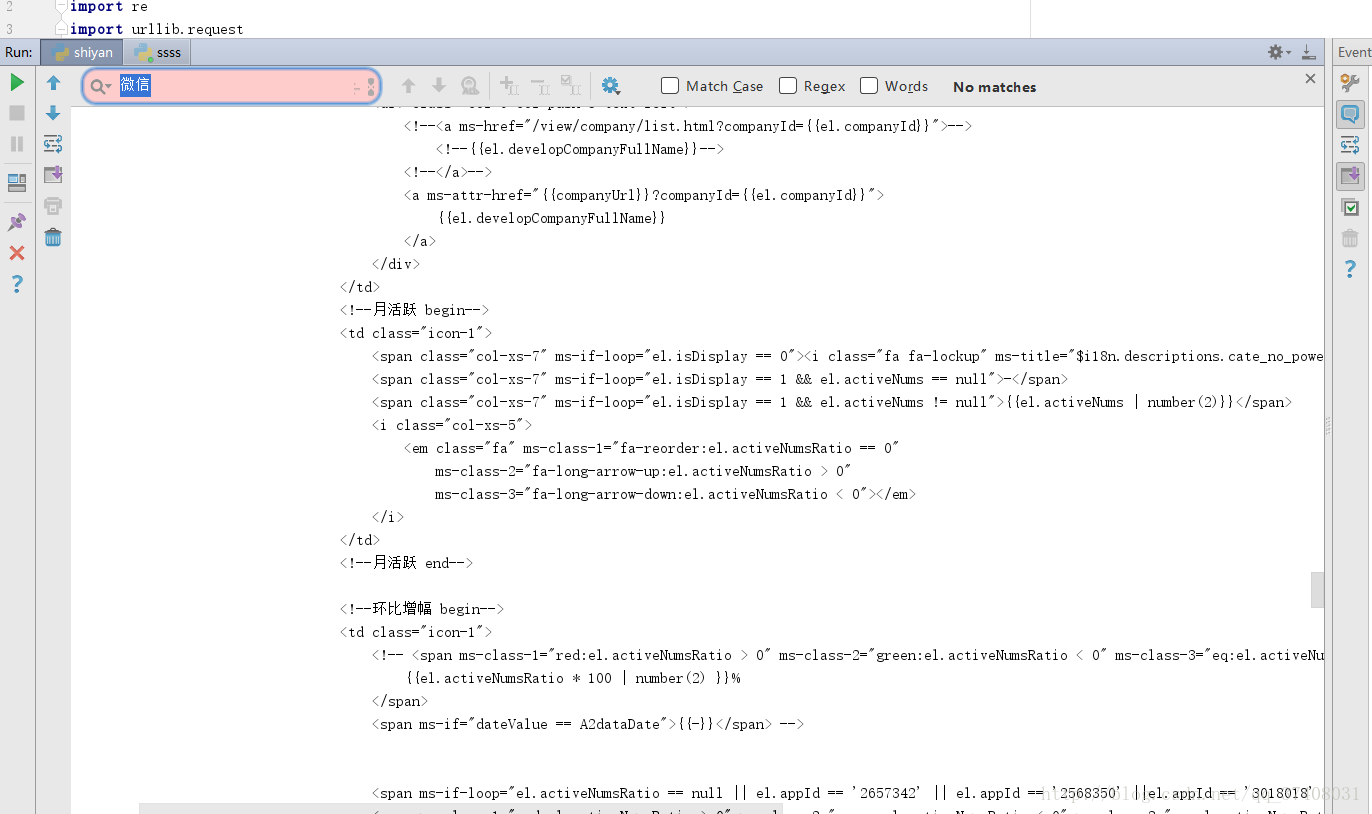
因此,得先找到这个网页填充数据的源文件。
Chrome为例,F12找到Network,找一下传送方式为POST的数据页(表单数据)
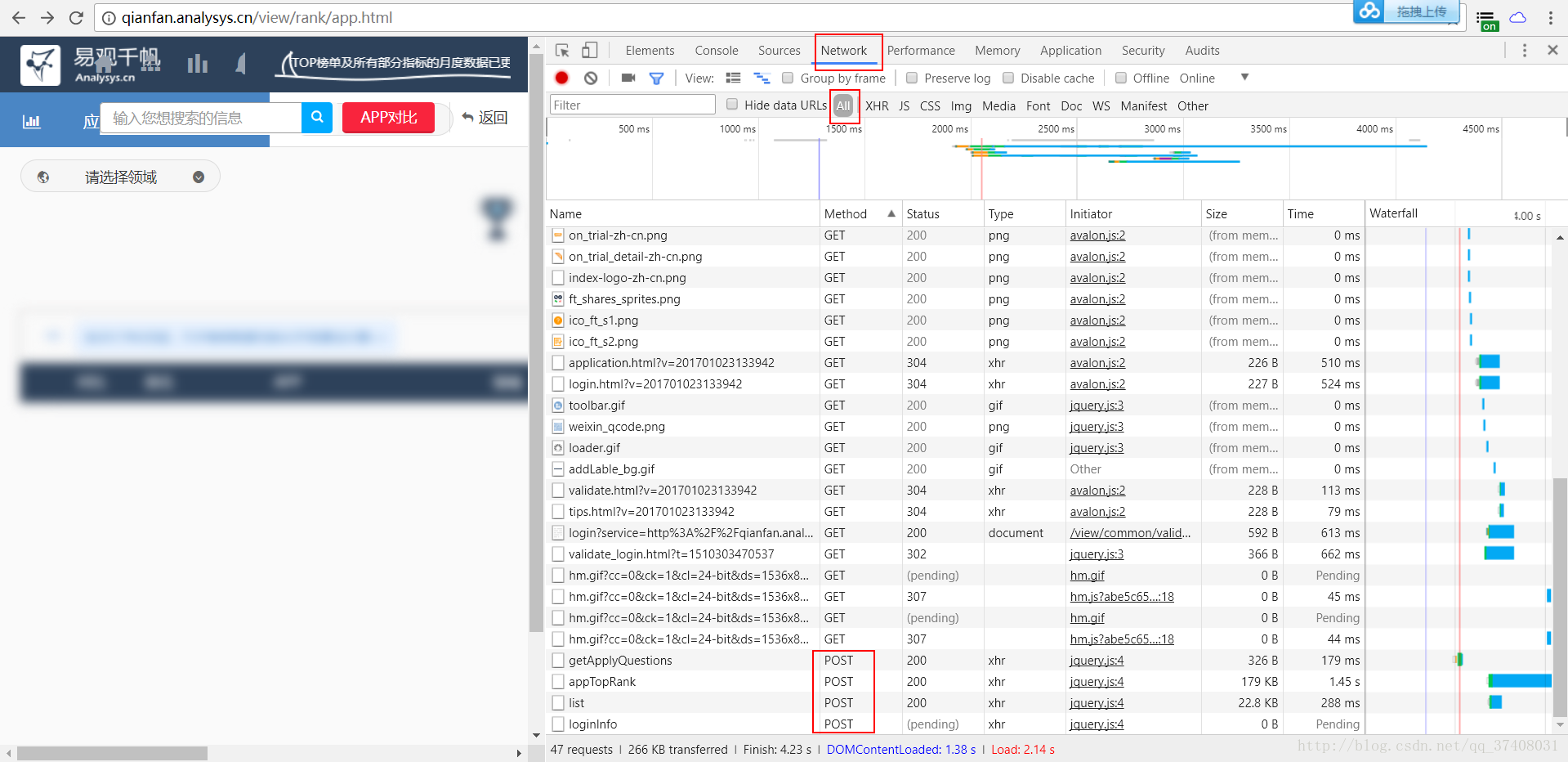
有四个POST,感觉那个appTOPRank比较靠谱。
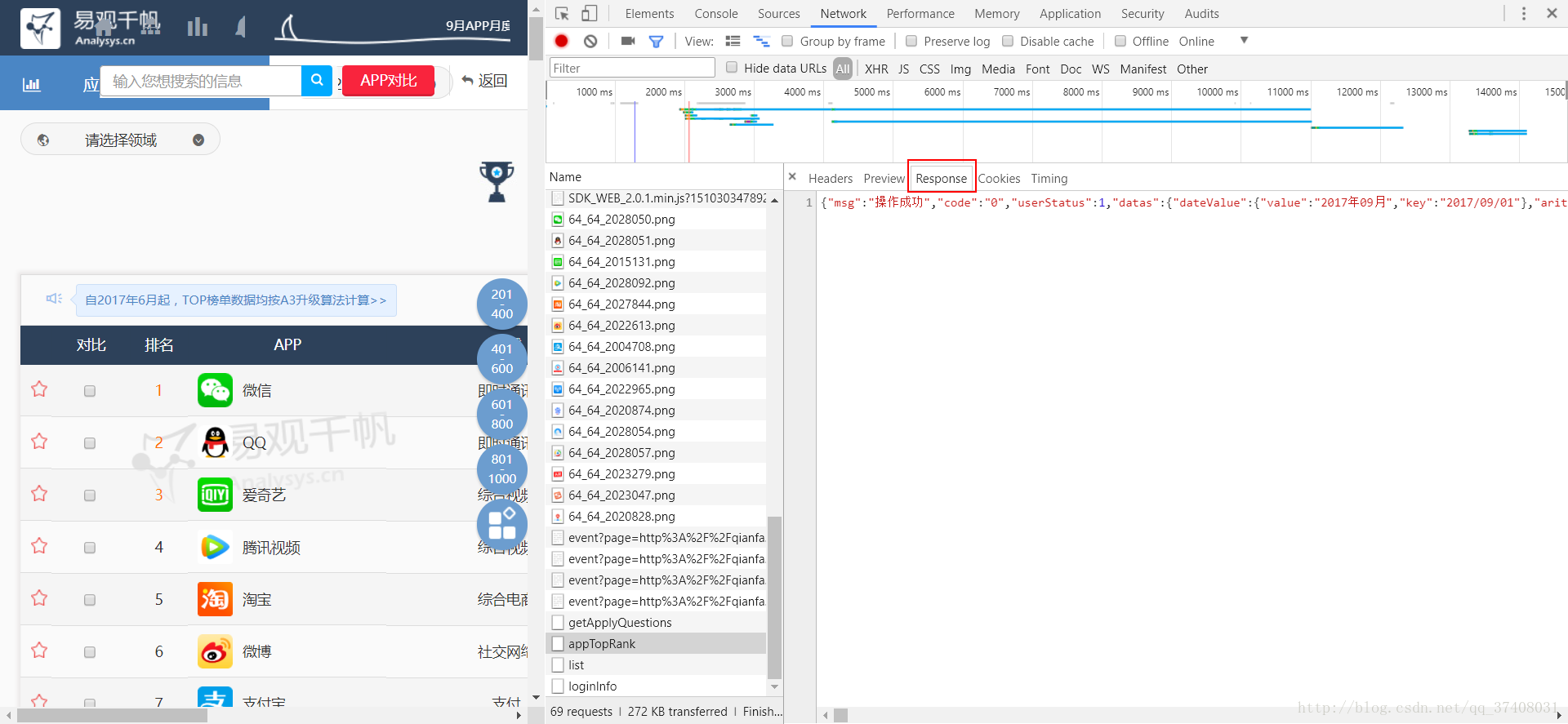
我们看看返回的数据,发现里面有许多app的信息:类别、介绍等。
很愉快的点开表头Headers找找它的url:
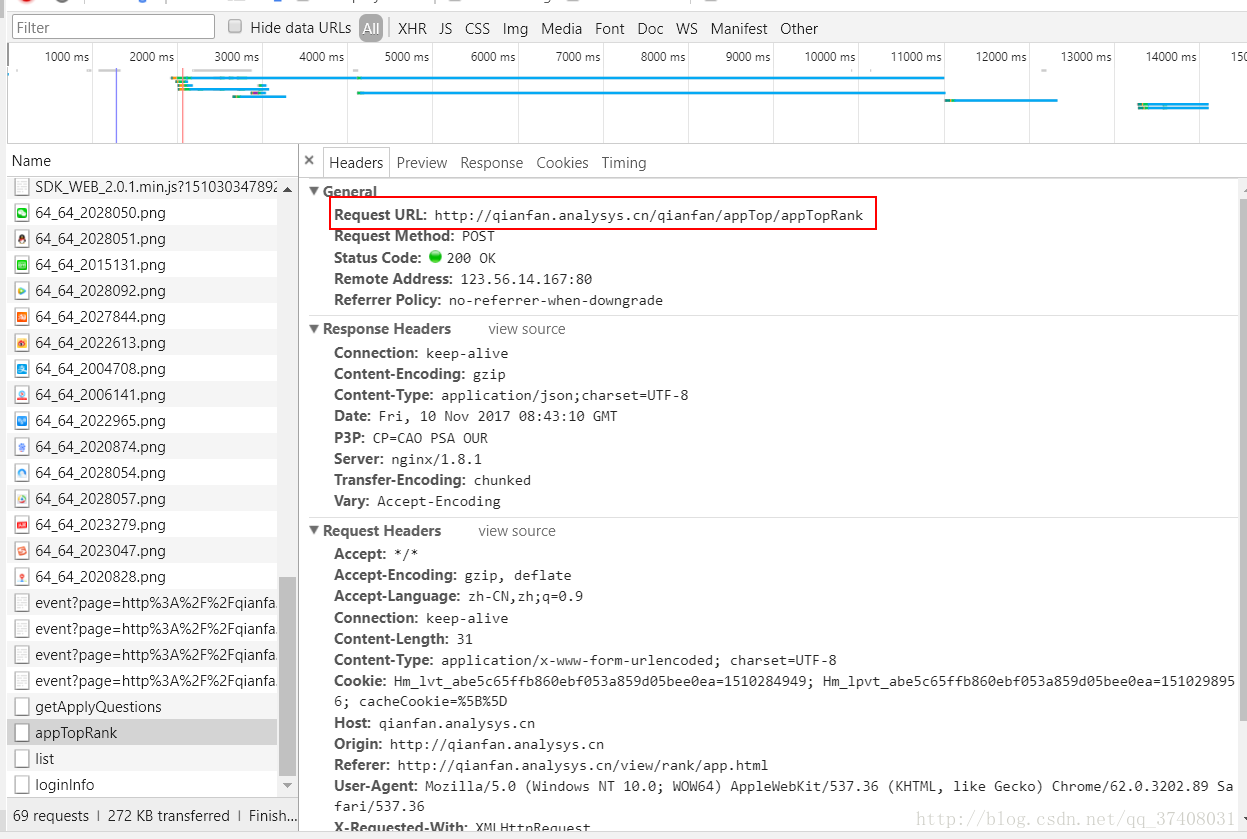
复制到浏览器里看看:
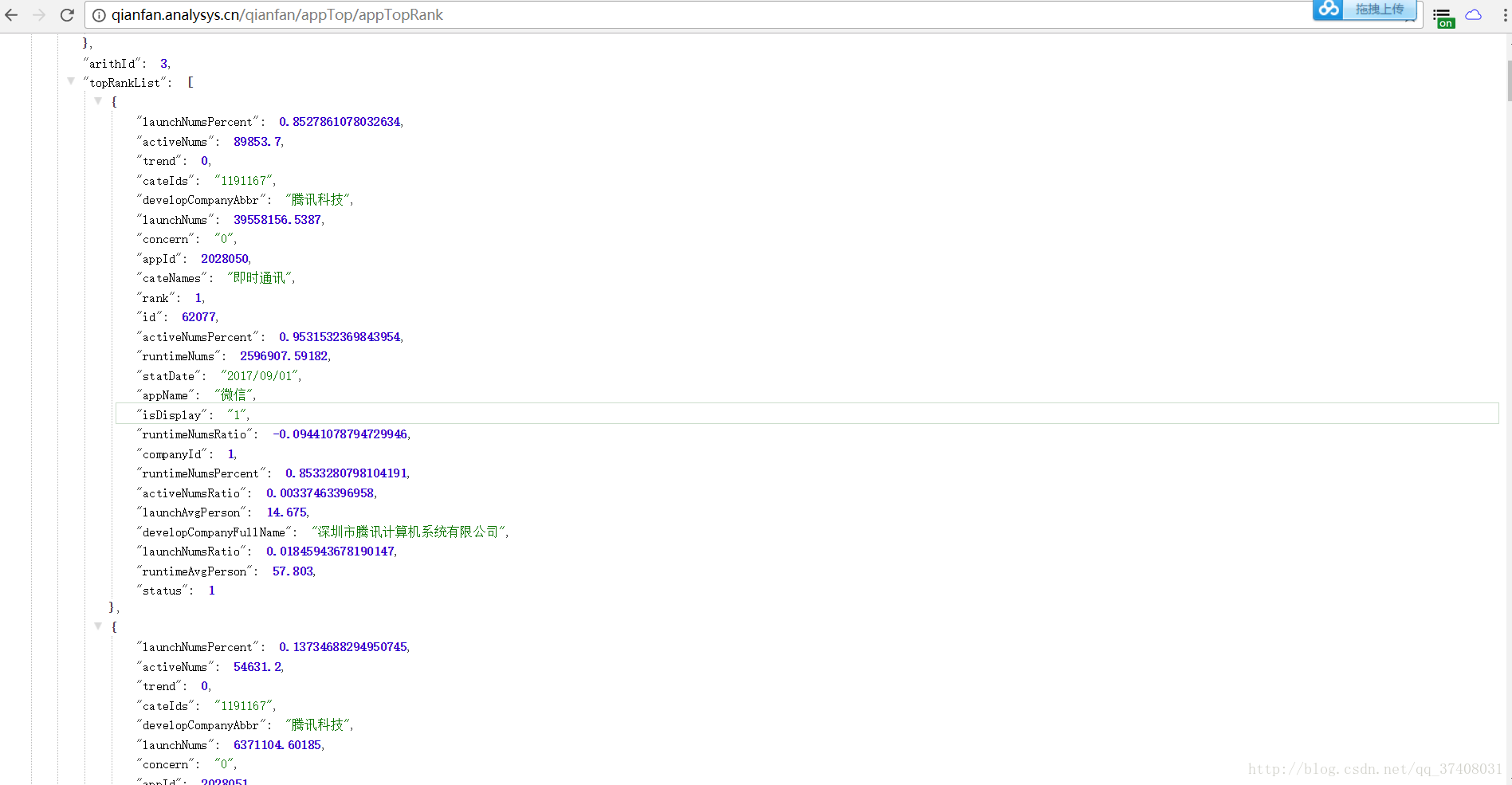
chrome直接为我们建了格式,发现这与排行榜是一致的。但是只有20个。
经过多次查找,发现这个是数量的要求,在data里,请求访问网站时需要加上这个datas:
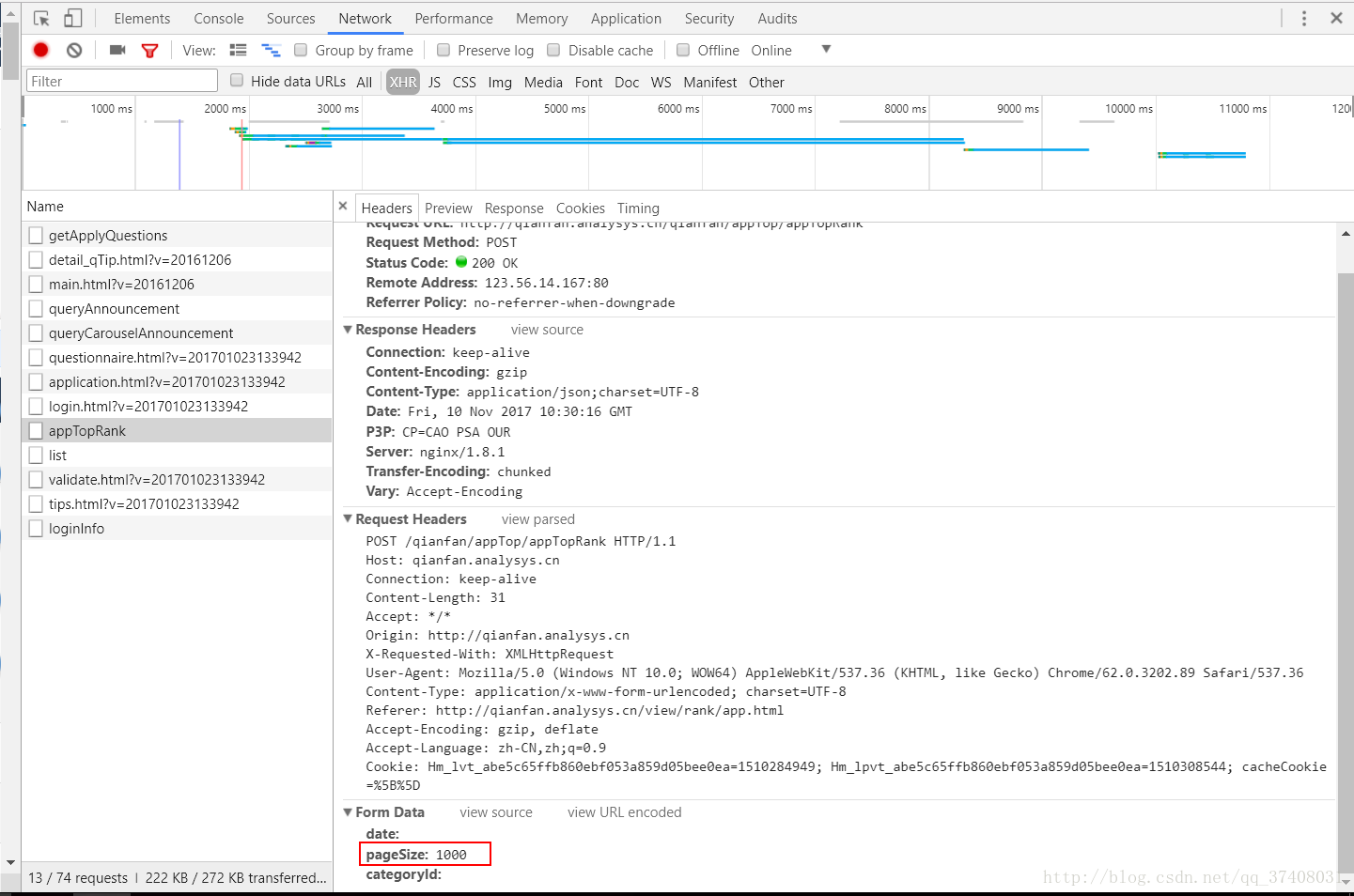
datas={'pageSize':'1000'}这个1000可以修改,你想抓几个就填几个。
接下来就是python实现爬虫(可以直接使用):
# -*- coding:utf-8 -*-
import re
import requests
datas={'pageSize':'1000'}
html=requests.post('http://qianfan.analysys.cn/qianfan/appTop/appTopRank',data = datas).content.decode('utf-8') #用post的方式访问。网页解码成中文
reg_rank=r'"rank":(.*?),"id"' #找到排名所在的代码区域,复制前后内容,把需要爬的内容替换为(.*?)
reg_app = r'"appName":"(.*?)","isDisplay"' #app名称
reg_UV=r'"activeNums":(.*?),"trend"' #活跃
outcome_rank= re.findall(reg_rank, html) #利用正则模块找到需要的内容
outcome_app = re.findall(reg_app , html)
outcome_UV = re.findall(reg_UV, html)
for i in range(0,len(outcome_rank)): #以排行数量为准
print (outcome_rank[i],outcome_app[i],outcome_UV[i]) #打印出结果,结果是个list,我们用for语句将里面的里面的内容一个一个输出。(这里就不追求格式了)














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









